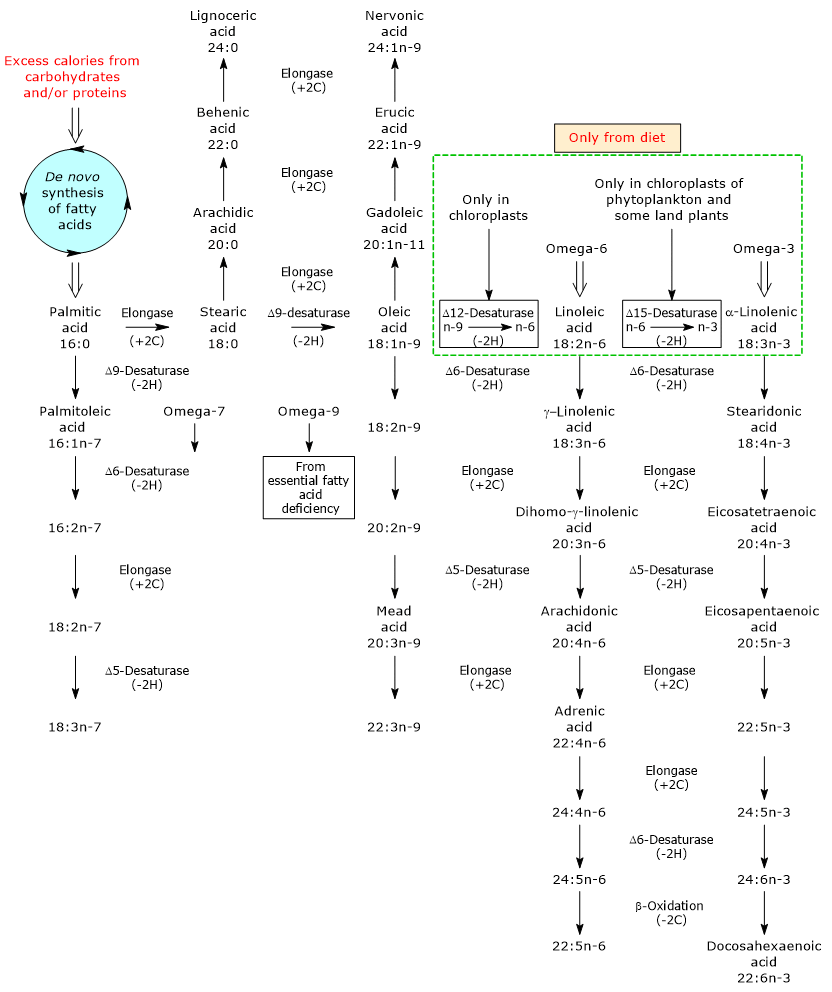
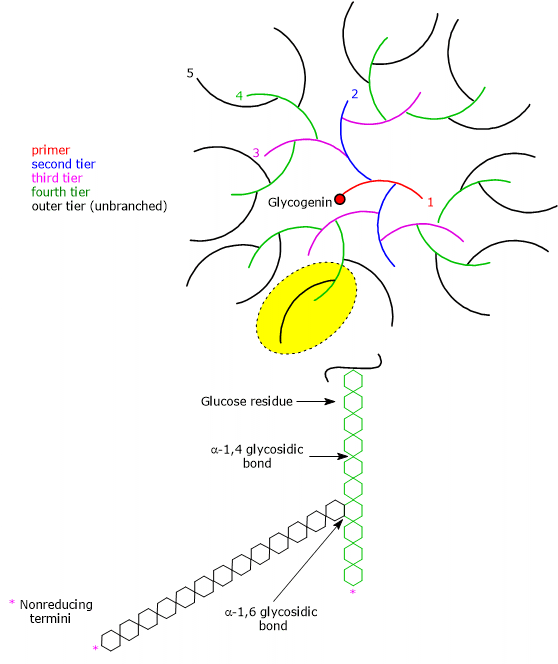
Glucose 6-phosphate (G6P) is a key metabolite in carbohydrate metabolism and, more broadly, in cellular metabolism.[1]
In animal and bacterial cells, it mainly derives from the reaction catalyzed by the enzyme hexokinase, which catalyzes the first step of the glycolytic pathway. Alternatively, it can be produced through glycogenolysis, a catabolic process in which glycogen is degraded to provide glucose in response to specific metabolic needs.[2] A third, although quantitatively less significant, synthesis pathway involves the conversion of galactose via the Leloir pathway.[3]
Glucose 6-phosphate represents a crucial cellular metabolic hub. Depending on the cell’s needs, it can proceed through glycolysis, be diverted into the hexose monophosphate shunt, or be used for glycogen synthesis and macromolecular glycosylation.[4] Furthermore, in the liver, it can be converted into free glucose or participate in detoxification processes via glucuronidation.[5]
Summary: Key Points
Central metabolic hub: glucose 6-phosphate is a crucial intermediate that sits at the intersection of major metabolic pathways.
Cellular trapping: the phosphorylation of glucose to G6P adds a negative charge to the molecule, trapping it inside the cell.
Primary sources: it is synthesized through three main routes: the hexokinase/glucokinase reaction (from glucose), glycogenolysis (from glycogen stores), or the Leloir pathway (from galactose).
Metabolic fates: depending on energy needs, it can be oxidized for ATP, used to generate NADPH and ribose-5-phosphate, stored as glycogen, or used as a precursor for glucuronidation.
Glucose 6-phosphate has a molecular weight of 260.14 g/mol and a molecular formula of C6H13O9P.
According to IUPAC nomenclature, its systematic name is [(2R,3R,4S,5R)-2,3,4,5-tetrahydroxy-6-oxohexyl] dihydrogen phosphate.
Its pKa1 and pKa2, at 25 °C are 1.65 and 6.11, respectively. Therefore, at physiological pH, it exists almost exclusively in its ionized form and carries a charge of −2.[6]
How glucose 6-phosphate is formed
In animal and bacterial cells (excluding photosynthesis), glucose 6-phosphate is primarily produced through two pathways: the direct phosphorylation of glucose and, in animal cells, glycogenolysis. It can also be synthesized from galactose.[2]
Glucose 6-phosphate as a Central Metabolic Hub
Hexokinase
Once glucose enters the cell, its main metabolic fate is to be phosphorylated to glucose 6-phosphate.
This reaction is the first of the ten steps of glycolysis and also the first of the two phosphorylation steps that the monosaccharide undergoes during this metabolic pathway.
Hexokinase (EC 2.7.1.1), an enzyme found in the cells of all organisms and present in four isoforms in humans, catalyzes this irreversible reaction, phosphorylating glucose at the C-6 position using one ATP molecule.
Glucose + ATP → Glucose 6-phosphate + ADP
This glucose 6-phosphate synthesis pathway is particularly important when the monosaccharide is available from external sources, such as after a meal.[1]
Glycogenolysis
Glucose 6-phosphate can also be derived from glycogenolysis, the metabolic pathway by which glucose molecules stored in glycogen, a polysaccharide, are released when needed.
During fasting, for example, at night or between meals, but also during physical activity, glycogenolysis, through the intervention of three enzymatic activities, namely, glycogen phosphorylase (EC 2.4.1.1), alpha-(1,4)-glucan-6-glycosyltransferase (EC 2.4.1.25), and amylo-alpha-(1,6)-glucosidase, or debranching enzyme (EC 3.2.1.33), leads to the release of glucose: approximately 90% in the form of glucose 1-phosphate (G1P), and the remaining 10% directly as glucose.
Glucose 1-phosphate is then isomerized to glucose 6-phosphate in the reversible reaction catalyzed by phosphoglucomutase (EC 5.4.2.2).[2]
Galactose
Galactose is a monosaccharide present in milk and dairy products, where it is mainly found as a component, along with glucose, of lactose. Through the Leloir pathway, it can be converted into glucose 1-phosphate, which in turn can be isomerized to glucose 6-phosphate.[7]
The Leloir pathway allows the formation of metabolites that can enter various metabolic routes, both anabolic and catabolic, depending on the tissue and the metabolic conditions of the cell. Among the possible fates of galactose along this pathway is its conversion into glucose 1-phosphate, which can then be isomerized to glucose 6-phosphate.[3]
Why the phosphorylation of glucose to glucose 6-phosphate is important
The phosphorylation of glucose to glucose 6-phosphate is metabolically important for several reasons.
Glucose is a neutral molecule whose passage through the plasma membrane occurs via facilitated diffusion, mediated by specific protein transporters belonging to the GLUT or SLC2A family of membrane transport proteins.[8]
Phosphorylation at C-6 gives glucose a negative charge, preventing it from crossing the membrane, partly because of the absence of specific transporters for phosphorylated sugars. Therefore, phosphorylation traps the sugar inside the cell.[4]
Thanks to the phosphorylation at C-6 and the lack of transporters for phosphorylated sugars, it is no longer necessary to expend energy to retain glucose 6-phosphate inside the cell, despite the large difference between its intracellular and extracellular concentrations.[9]
The rapid conversion of glucose into glucose 6-phosphate also helps maintain a low intracellular concentration of free glucose, thereby facilitating its entry by facilitated diffusion.[4]
The addition of a phosphate group increases the energy content of glucose, that is, it begins to destabilize the molecule, facilitating its subsequent metabolism.[9]
Metabolic fate of glucose 6-phosphate
Glucose 6-phosphate is a central hub in carbohydrate metabolism. As a common intermediate in various metabolic pathways, its fate depends on the metabolic needs of the cell. It can participate in several metabolic routes, both anabolic and catabolic, such as glycolysis, gluconeogenesis, the pentose phosphate pathway, glycogen synthesis, and hexosamine pathway. Finally, it is also involved in detoxification processes through the glucuronidation of molecules destined for excretion.[10]
Key enzymes and regulatory parameters of glucose 6-phosphate metabolism
Category
Enzyme/Pathway
EC Number
Specification
Synthesis
Hexokinase/Glucokinase
EC 2.7.1.1
Catalyzes the irreversible phosphorylation of glucose to G6P (first step of glycolysis)
Phosphoglucomutase
EC 5.4.2.2
Reversibly interconverts G6P and Glucose 1-phosphate (glycogen synthesis and glycogenolysis)
Subsequent metabolism
Glucose 6-phosphate dehydrogenase (G6PD)
EC 1.1.1.49
Diverts G6P into the pentose phosphate pathway, producing NADPH and ribose 5-phosphate
Phosphoglucose Isomerase (PGI)
EC 5.3.1.9
Catalyzes the reversible isomerization of G6P to fructose 6-phosphate during glycolysis
GFAT
EC 2.6.1.16
Enters the hexosamine pathway via Fructose 6-phosphate for macromolecular glycosylation
Glycolysis
Glycolysis is a fundamental metabolic pathway, not only for energy production but also as a source of intermediates for other metabolic pathways.[11]
Glucose 6-phosphate can continue along the pathway, becoming a substrate for the reaction catalyzed by phosphoglucose isomerase (PGI; EC 5.3.1.9). This enzyme catalyzes its reversible isomerization to fructose 6-phosphate, an example of functional group isomerism. However, fructose 6-phosphate is not an exclusive metabolite of glycolysis.
In the third step of the glycolytic pathway, fructose 6-phosphate undergoes a second phosphorylation to form fructose 1,6-bisphosphate. This reaction, catalyzed by phosphofructokinase-1 (PFK-1; EC 2.7.1.11), is irreversible and leads to the formation of a metabolite that is exclusive to glycolysis, and, in the reverse direction, to gluconeogenesis.[9]
Hexosamine pathway
Fructose 6-phosphate, produced by the isomerization of glucose 6-phosphate, is one of the key substrates of the hexosamine pathway. This metabolic pathway accounts for approximately 2–5% of glucose metabolism and is essential for the glycosylation of macromolecules.[10]
In the first step, fructose 6-phosphate is converted to glucosamine 6-phosphate in a reaction catalyzed by the enzyme glutamine:fructose-6-phosphate aminotransferase (GFAT; EC 2.6.1.16), which catalyzes the first committed step of the pathway. In this reaction, the amino acid glutamine serves as the donor of the amino group.[12]
The subsequent steps ultimately lead to the synthesis of UDP-N-acetylglucosamine (UDP-GlcNAc), which is used in both N-linked and O-linked glycosylation of proteins, lipids, and nucleic acids.[13]
Pentose phosphate pathway
Glucose 6-phosphate can enter the pentose phosphate pathway, also known as the hexose monophosphate shunt, an alternative to glycolysis for the oxidative metabolism of glucose.[14]
Entry into the pathway occurs at the level of the reaction catalyzed by glucose 6-phosphate dehydrogenase (G6PD; EC 1.1.1.49). In this reaction, G6P is oxidized to 6-phosphoglucono-δ-lactone, which then continues along the metabolic pathway.
The pentose phosphate pathway serves a dual function: the synthesis, in variable ratios depending on the metabolic conditions of the cell, of NADPH and ribose-5-phosphate.
NADPH is a reduced coenzyme essential for biosynthetic reactions such as the synthesis of fatty acids and cholesterol, as well as for antioxidant defense by reducing oxidized glutathione.[1]
Ribose 5-phosphate, a five-carbon sugar, is essential for the synthesis of nucleotides and nucleic acids, and is therefore particularly important during periods of growth.[4]
It is estimated that over 10% of metabolized glucose is channeled through this pathway, which, interestingly, while oxidizing the monosaccharide, neither produces nor directly consumes ATP.[15]
Glycogen synthesis
Glucose 6-phosphate can be used to replenish cellular glycogen reserves. The anabolic pathway leading to polysaccharide biosynthesis occurs when carbohydrates are available, glucose demand is low, and there is an energy surplus. Glycogen synthesis is particularly important in the liver and muscle.[16]
During glycogen synthesis, glucose 6-phosphate is isomerized to glucose 1-phosphate in a reaction catalyzed by phosphoglucomutase. This enzyme also functions in glycogenolysis, catalyzing the reverse reaction. The direction of the reaction is determined by the relative concentrations of the two sugar phosphates.
In the next step, the carbon skeleton is activated by the transfer of a UDP group in a reaction catalyzed by UDP-glucose pyrophosphorylase (EC 2.7.7.9).
The resulting UDP-glucose then serves as the substrate for the reaction catalyzed by glycogen synthase (EC 2.4.1.11) and is used to elongate glycogen chains. UDP-glucose is also used as a sugar donor in the synthesis of glycolipids.[4]
Detoxification processes
Detoxification processes enable the elimination of xenobiotics, drugs, and catabolic by-products such as bilirubin. These metabolic pathways occur primarily in the liver, where glucose 6-phosphate acts as a precursor in the synthesis of glucuronic acid.[17]
G6P, similar to its role in glycogen synthesis, is first activated to UDP-glucose. UDP-glucose is then oxidized to UDP-glucuronate in a reaction catalyzed by UDP-glucose 6-dehydrogenase (EC 1.1.1.22). UDP-glucuronate serves as a glucuronic acid donor in reactions catalyzed by UDP-glucuronosyltransferase (EC 2.4.1.17). This process, known as glucuronidation, increases the hydrophilicity of otherwise lipophilic compounds, thereby facilitating their elimination via bile or urine.[5]
References
^ abc Nelson D.L., Cox M.M. Lehninger. Principles of biochemistry. 8th Edition. W.H. Freeman and Company, 2021.
^ abc Heilman D., Woski S., Voet D., Voet J.G., Pratt C.W. Fundamentals of biochemistry: life at the molecular level. 6th Edition. Wiley, 2023.
^ ab Conte F., van Buuringen N., Voermans N.C., Lefeber D.J. Galactose in human metabolism, glycosylation and congenital metabolic diseases: time for a closer look. Biochim Biophys Acta Gen Subj 2021;1865(8):129898. doi:10.1016/j.bbagen.2021.129898
^ ab Rowland A., Miners J.O., Mackenzie P.I. The UDP-glucuronosyltransferases: their role in drug metabolism and detoxification. Int J Biochem Cell Biol 2013;45(6):1121-32. doi:10.1016/j.biocel.2013.02.019
^ Leloir L.F., de Fekete M.A., Cardini C.E. Starch and oligosaccharide synthesis from uridine diphosphate glucose. J Biol Chem 1961;236:636-41. doi:10.1016/S0021-9258(18)64280-2
^ Thorens B., Mueckler M. Glucose transporters in the 21st Century. Am J Physiol Endocrinol Metab 2010;298(2):E141-5. doi:10.1152/ajpendo.00712.2009
^ abc Berg J.M., Tymoczko J.L., Gatto J.G., Stryer L. Biochemistry. 9th Edition. W.H. Freeman and Company, 2019.
^ ab Rajas F., Gautier-Stein A., Mithieux G. Glucose-6 phosphate, a central hub for liver carbohydrate metabolism. Metabolites 2019;9(12):282. doi:10.3390/metabo9120282
^ Kierans S.J., Taylor C.T. Glycolysis: a multifaceted metabolic pathway and signaling hub. J Biol Chem 2024;300(11):107906. doi:10.1016/j.jbc.2024.107906
^ Michal G., Schomburg D. Biochemical pathways. An atlas of biochemistry and molecular biology. 2nd Edition. John Wiley J. & Sons, Inc. 2012.
^ Adeva-Andany M.M., González-Lucán M., Donapetry-García C., Fernández-Fernández C., Ameneiros-Rodríguez E. Glycogen metabolism in humans. BBA Clin 2016;5:85-100. doi:10.1016/j.bbacli.2016.02.001
^ Yang G., Ge S., Singh R., Basu S., Shatzer K., Zen M., Liu J., Tu Y., Zhang C., Wei J., Shi J., Zhu L., Liu Z., Wang Y., Gao S., Hu M. Glucuronidation: driving factors and their impact on glucuronide disposition. Drug Metab Rev 2017;49(2):105-138. doi:10.1080/03602532.2017.1293682
Substrate-level phosphorylation is defined as the production of ATP or GTP following the transfer of a phosphate group from a substrate to ADP or GDP.[1]
The energy released from the cleavage of a high-energy bond of the substrate facilitates the formation of the phosphoanhydride bond.[2] Part of this energy drives the reaction toward nucleotide triphosphate formation, while the remainder is stored in the newly formed bond.[3]
This process involves soluble enzymes and chemical intermediates, differing from oxidative phosphorylation and photophosphorylation, which rely on membrane-bound enzymes and transmembrane proton gradients.[2]
Examples of substrate-level phosphorylation are found in the glycolytic pathway and the citric acid cycle.[3]
Although under aerobic conditions most ATP is produced by oxidative phosphorylation and by photophosphorylation in photosynthetic organisms, substrate-level phosphorylation remains essential in energy metabolism, particularly under anaerobic conditions.[4][5]
Summary: Key Points
Definition: the direct production of ATP or GTP by transferring a high-energy phosphate group from a metabolic substrate to ADP or GDP.
Mechanism: driven by the cleavage of high-energy chemical bonds; it uses soluble enzymes and occurs independently of proton gradients or membrane-bound complexes.
Metabolic pathways: occurs in glycolysis (reactions catalyzed by phosphoglycerate kinase and pyruvate kinase) and the citric acid cycle (reaction catalyzed by succinyl-CoA synthetase).
Biological significance: essential for energy metabolism, it is the primary mechanism for ATP synthesis under anaerobic conditions.
Two well-known examples of substrate-level phosphorylation occur in glycolysis.
During the energy recovery phase of glycolysis, two of the five reactions directly extract and store chemical energy from metabolic intermediates as ATP.[5]
These reactions are catalyzed by phosphoglycerate kinase (EC 2.7.2.3) and pyruvate kinase (EC 2.7.1.40).
In these reactions, a high-energy phosphate group is transferred to ADP from the following substrates:
1,3-bisphosphoglycerate, resulting in the production of ATP and 3-phosphoglycerate;
phosphoenolpyruvate, resulting in the production of ATP and pyruvate.[6]
These two glycolytic substrate-level phosphorylation reactions enable ATP synthesis even under anaerobic conditions.[3]
The citric acid cycle and GDP phosphorylation
Another example of substrate-level phosphorylation occurs in in the reaction of the citric acid cycle catalyzed by succinyl-CoA synthetase, also known as succinate-CoA ligase (EC 6.2.1.4). This enzyme catalyzes the cleavage of the high-energy thioester bond in succinyl-CoA, similar to that in acetyl-CoA. The energy released drives the formation of a phosphoanhydride bond, leading to the conversion of GDP to GTP.[5]
Key enzymes and reactions of substrate-level phosphorylations
Pathway
Enzyme
EC Number
Reaction Details
Glycolysis
Phosphoglycerate kinase
EC 2.7.2.3
Transfers a high-energy phosphate group from 1,3-bisphosphoglycerate to ADP, producing 3-phosphoglycerate and ATP
Pyruvate kinase
EC 2.7.1.40
Transfers a high-energy phosphate group from phosphoenolpyruvate (PEP) to ADP, producing pyruvate and ATP
Citric acid cycle
Succinyl-CoA synthetase
EC 6.2.1.4
Cleaves the high-energy thioester bond of succinyl-CoA to drive the phosphorylation of GDP to GTP (or ADP to ATP)
References
^ Ha C.E., Bhagavan N.V. Chapter 11 – Carbohydrate metabolism I: glycolysis and the tricarboxylic acid cycle. Editor(s): Chung Eun Ha, N.V. Bhagavan. Essentials of Medical Biochemistry. 3rd Edition. Academic Press, 2023, pages 203-227. doi:10.1016/B978-0-323-88541-6.00030-2
Ketogenic amino acids are amino acids whose carbon skeleton can be fully or partially catabolized into acetoacetyl-CoA or acetyl-CoA, molecules that serve as precursors for the synthesis of ketone bodies, hence the name, or of fatty acids.[1]
Amino acids are the fundamental constituents of proteins.
Since the body lacks specific amino acid reserves comparable to glycogen or triglycerides, excess amino acids are converted into citric acid cycle intermediates to produce energy once protein synthesis demands are met.[2]
When cellular energy requirements are satisfied, the carbon residues from amino acid catabolism are redirected towards the synthesis of glucose, fatty acids, or ketone bodies.[3]
Proteinogenic amino acids are classified as ketogenic amino acids or glucogenic based on the metabolic fate of their carbon skeleton.[4] Ketogenic amino acids yield acetoacetyl-CoA and/or acetyl-CoA, while glucogenic ones are catabolized into five precursor metabolites: pyruvate, oxaloacetate, α-ketoglutarate, succinyl-CoA and fumarate.[5]
However, this classification is not unique, as five amino acids are both ketogenic and glucogenic, originating at least one glucogenic and one ketogenic precursor.[6]
Summary: Key Points
Metabolic fate: ketogenic amino acids are catabolized into acetyl-CoA or acetoacetyl-CoA, serving as direct precursors for ketone bodies and fatty acids synthesis.
Exclusively ketogenic: leucine and lysine are the only two strictly ketogenic amino acids, meaning they cannot contribute to net glucose production in animals.
Biochemical barrier: acetyl-CoA cannot generate glucose due to the loss of two carbon atoms in the citric acid cycle and the irreversibility of the pyruvate dehydrogenase complex reaction.
Fasting dynamics: during prolonged fasting, their role in ketogenesis is minor compared to fatty acid beta-oxidation; the body prioritizes glucogenic amino acids to maintain glucose homeostasis.
Only two of the twenty amino acids that make up proteins are exclusively ketogenic: leucine and lysine. The catabolism of their carbon skeleton results in the production of acetoacetyl-CoA and acetyl-CoA.[6]
Classification of ketogenic and glucogenic amino acids based on their catabolites
Amino acid
Ketogenic
Glucogenic
Acetyl-CoA
Acetoacetyl-CoA
Phenylalanine
✔
Fumarate
Isoleucine
✔
Succinyl-CoA
Leucine *
✔
✔
Lysine *
✔
Tyrosine
✔
Fumarate
Threonine
✔
Succinyl-CoA
Tryptophan
✔
✔
Pyruvate
* Exclusively ketogenic amino acids
Another five amino acids, namely isoleucine, phenylalanine, threonine, tryptophan, and tyrosine, are both ketogenic and glucogenic as their carbon skeleton catabolism leads to the formation of acetyl-CoA and/or acetoacetyl-CoA and a glucogenic precursor.[5]
The utilization of amino acid carbon skeletons is preceded by the removal of the amino group. Alanine and glutamate, glucogenic amino acids, play a key role in the transport of amino groups from extrahepatic tissues to the liver. In particular, alanine is transported from muscle and other peripheral tissues to the liver via the glucose-alanine cycle.[7]
Biochemical basis
Acetyl-CoA and acetoacetyl-CoA are not glucogenic precursors. The explanation lies in the stoichiometry of the citric acid cycle and the inability of animals to convert acetyl-CoA into pyruvate.[8]
Metabolic Map of Ketogenic Amino Acid Entry Points into the Krebs Cycle.
Acetyl-CoA enters the citric acid cycle through the reaction catalyzed by citrate synthase (EC 2.3.3.1). The enzyme catalyzes the condensation of acetyl-CoA with oxaloacetate to form citrate. Thus, a four-carbon compound is converted into a six-carbon compound, with a net gain of two carbon atoms.
However, in the two subsequent oxidative decarboxylations of the cycle, catalyzed respectively by isocitrate dehydrogenase (EC 1.1.1.42) and the α-ketoglutarate dehydrogenase multienzyme complex, two carbon atoms are lost.[4]
Therefore, the entry of acetyl-CoA into the cycle does not involve any net gain in carbon.[6]
The key factor is therefore the entry point of the carbon units, upstream or downstream of the oxidative decarboxylations of the citric acid cycle.[8]
Additionally, in animals, there is no metabolic pathway that allows the production of pyruvate from acetyl-CoA, due to the irreversibility of the reaction catalyzed by the pyruvate dehydrogenase complex, namely, the oxidative decarboxylation of pyruvate to acetyl-CoA.[8]
Ketogenic amino acids during prolonged fasting
Unlike glucogenic amino acids, ketogenic amino acids do not play a crucial role during prolonged fasting or in diets with severe carbohydrate restriction.
During prolonged fasting, the primary source of acetyl-CoA for ketogenesis is the β-oxidation of fatty acids, while the contribution of ketogenic amino acids is marginal. Under these conditions, glucogenic amino acids play a central role, as they ensure the maintenance of glucose homeostasis through gluconeogenesis when hepatic glycogen stores are depleted.[5]
Glyoxylate cycle
Plants, yeasts, and many bacteria can use acetyl-CoA for glucose synthesis because they have the glyoxylate cycle.
This cycle shares several reactions with the citric acid cycle but features two unique steps, catalyzed by isocitrate lyase (EC 4.1.3.1) and malate synthase (EC 2.3.3.9), while lacking any decarboxylation reactions. Consequently, organisms possessing the glyoxylate cycle can convert fatty acids and ketogenic amino acids into glucose.[9]
References
^ D’Andrea G. Classifying amino acids as gluco(glyco)genic, ketogenic, or both. Biochem Educ 2000;28(1):27-28. doi:10.1016/s0307-4412(98)00271-4
^ Brosnan J.T. Interorgan amino acid transport and its regulation. J Nutr 2003;133(6 Suppl 1):2068S-2072S. doi:10.1093/jn/133.6.2068S
^ Litwack G. Human biochemistry. 2nd Edition. Academic Pr, 2021.
^ ab Moran L.A., Horton H.R., Scrimgeour K.G., Perry M.D. Principles of Biochemistry. 5th Edition. Pearson, 2012.
^ abc Rosenthal M.D., Glew R.H. Medical Biochemistry – Human Metabolism in Health and Disease. John Wiley J. & Sons, Inc., 2009.
^ abc Nelson D.L., Cox M.M. Lehninger. Principles of biochemistry. 8th Edition. W.H. Freeman and Company, 2021.
^ Felig P., Pozefsk T., Marlis E., Cahill G.F. Alanine: key role in gluconeogenesis. Science 1970;167(3920):1003-1004. doi:10.1126/science.167.3920.1003
^ abc Heilman D., Woski S., Voet D., Voet J.G., Pratt C.W. Fundamentals of biochemistry: life at the molecular level. 6th Edition. Wiley, 2023.
^ Kondrashov F.A., Koonin E.V., Morgunov I.G., Finogenova T.V., Kondrashova M.N. Evolution of glyoxylate cycle enzymes in Metazoa: evidence of multiple horizontal transfer events and pseudogene formation. Biol Direct 2006;1:31. doi:10.1186/1745-6150-1-31
Glucogenic amino acids are defined as amino acids whose carbon skeletons can be fully or partially catabolized into precursors for gluconeogenesis, hence the name “glucogenic”.[1]
Unlike glycogen or triglycerides, the body does not store excess amino acids.[2]
When cellular protein and energy needs are met, surplus amino acids are catabolized into precursors for the synthesis of fatty acids, ketone bodies, or glucose.[3]
Glucogenic and ketogenic amino acids are classified based on the metabolic fate of their carbon skeletons. However, this classification is not clear-cut because, among the twenty standard amino acids found in proteins, five are both glucogenic and ketogenic.[4]
Glucose synthesis is possible because their carbon skeletons yield pyruvate, oxaloacetate, α-ketoglutarate, succinyl-CoA, or fumarate.[5]
While pyruvate and oxaloacetate directly enter gluconeogenesis, the other intermediates provide a net gain of carbon units within the citric acid cycle, eventually forming oxaloacetate.[6]
Consequently, during prolonged fasting or carbohydrate restriction, glucogenic amino acids play a crucial role, serving as a major source of precursors for gluconeogenesis, second only to glycerol derived from adipose tissue lipolysis.[7]
Summary: Key Points
Definition: amino acids whose carbon skeletons are catabolized into precursors for glucose synthesis (gluconeogenesis).
Classification: out of 20 standard amino acids, 13 are exclusively glucogenic and 5 are mixed (both glucogenic and ketogenic).
Metabolic entry: converted into pyruvate or citric acid cycle intermediates, leading to a net gain of carbon units for gluconeogenesis.
Acetyl-CoA block: Acetyl-CoA cannot serve as a glucose precursor due to the irreversible nature of the pyruvate dehydrogenase reaction in animals.
Prolonged fasting: Alongside glycerol, they are the primary source for maintaining blood glucose once glycogen stores are depleted.
Alanine transport: Alanine serves as the predominant hepatic gluconeogenic substrate, carried from muscles via the glucose-alanine cycle.
Of the twenty amino acids that make up proteins, thirteen are exclusively glucogenic, meaning that the catabolism of their carbon skeletons yields only glucose precursors.[4]
Classification of amino acids based on their catabolites: glucogenic and mixed (glucogenic and ketogenic)
Amino acid
Ketogenic
Glucogenic
Acetyl-CoA
Acetoacetyl-CoA
Alanine
✔ Pyruvate
Arginine
✔ α-Ketoglutarate
Asparagine
✔ Fumarate
Aspartate
✔ Oxaloacetate
Cysteine
✔ Pyruvate
Phenylalanine *
✔
✔ Fumarate
Glycine
✔ Pyruvate
Glutamate
✔ α-Ketoglutarate
Glutamine
✔ α-Ketoglutarate
Isoleucine *
✔
✔ Succinyl-CoA
Histidine
✔ α-Ketoglutarate
Methionine
✔ Succinyl-CoA
Proline
✔ α-Ketoglutarate
Serine
✔ Pyruvate
Tyrosine *
✔
✔ Fumarate
Threonine *
✔
✔ Succinyl-CoA
Tryptophan *
✔
✔
✔ Pyruvate
Valine
✔ Succinyl-CoA
* Amino acids that are both glucogenic and ketogenic.
Five amino acids, namely isoleucine, phenylalanine, threonine, tryptophan, and tyrosine, are both glucogenic and ketogenic, as a portion of their carbon skeleton is catabolized into glucogenic precursors, while another portion is converted into acetyl-CoA and/or acetoacetyl-CoA.[8]
Before amino acid carbon skeletons can be utilized, their amino groups must first be removed. Alanine and glutamate (or glutamine), are two of the primary molecules responsible for transporting amino groups from extrahepatic tissues to the liver, are particularly important glucogenic amino acids in mammals. Alanine is the primary gluconeogenic substrate for the liver, reaching it from muscle and other peripheral tissues via the glucose-alanine cycle.[9]
Biochemical basis
As with ketogenic amino acids, analyzing the stoichiometry of the citric acid cycle helps explain why the carbon skeletons of glucogenic amino acids act as precursors for glucose synthesis. The key factor lies in the specific point at which these carbons enter the cycle.[6]
Metabolic Map of Glucogenic Amino Acid Entry Points into the Krebs Cycle
When carbon atoms derived from amino acids enter the cycle as α-ketoglutarate, succinyl-CoA, or fumarate, they contribute to a net gain of carbon units. Except for α-ketoglutarate, these intermediates enter the cycle downstream of the two oxidative decarboxylation steps catalyzed by isocitrate dehydrogenase (EC 1.1.1.42) and the α-ketoglutarate dehydrogenase multienzyme complex.[5]
This results in a net gain of one carbon unit when entry occurs at α-ketoglutarate, or two when it occurs at succinyl-CoA or fumarate. These carbon atoms can then feed into gluconeogenesis via oxaloacetate.[4]
Furthermore, because the reaction catalyzed by the pyruvate dehydrogenase complex, the oxidative decarboxylation of pyruvate to acetyl-CoA, is irreversible, and since animals lack a pathway to convert acetyl-CoA back to pyruvate, acetyl-CoA cannot serve as a glucogenic substrate.[6]
Glucogenic amino acids during prolonged fasting
Glucogenic amino acids play a crucial role during prolonged fasting and in diets with severe carbohydrate restriction. Under these conditions, they are among the primary precursors for glucose synthesis.[6] The utilization of their carbon skeletons, along with glycerol and propionate, a short-chain fatty acid, helps maintain glycemic homeostasis via gluconeogenesis when liver glycogen stores are depleted.[7]
However, even under physiological conditions, such as during cellular protein turnover or after a protein-rich meal, amino acids exceeding the requirements for protein synthesis are catabolized. Depending on the metabolic state and the specific amino acid, they may be used for energy production or anabolic processes, including glucose synthesis. The glucose produced can subsequently be utilized for glycogen synthesis, converted into ketone bodies or fatty acids.[2]
References
^ D’Andrea G. Classifying amino acids as gluco(glyco)genic, ketogenic, or both. Biochem Educ 2000;28(1):27-28. doi:10.1016/s0307-4412(98)00271-4
^ ab Brosnan J.T. Interorgan amino acid transport and its regulation. J Nutr 2003;133(6 Suppl 1):2068S-2072S. doi:10.1093/jn/133.6.2068S
^ Litwack G. Human biochemistry. 2nd Edition. Academic Pr, 2021.
^ abc Nelson D.L., Cox M.M. Lehninger. Principles of biochemistry. 8th Edition. W.H. Freeman and Company, 2021.
^ ab Moran L.A., Horton H.R., Scrimgeour K.G., Perry M.D. Principles of Biochemistry. 5th Edition. Pearson, 2012.
^ abcd Heilman D., Woski S., Voet D., Voet J.G., Pratt C.W. Fundamentals of biochemistry: life at the molecular level. 6th Edition. Wiley, 2023.
^ ab Kuriyama H., Shimomura I., Kishida K., Kondo H., Furuyama N., Nishizawa H., Maeda N., Matsuda M., Nagaretani H., Kihara S., Nakamura T., Tochino Y., Funahashi T., Matsuzawa Y. Coordinated regulation of fat-specific and liver-specific glycerol channels, aquaporin adipose and aquaporin 9. Diabetes 2002;51(10):2915-2921. 10.2337/diabetes.51.10.2915
^ Rosenthal M.D., Glew R.H. Medical Biochemistry – Human Metabolism in Health and Disease. John Wiley J. & Sons, Inc., 2009.
^ Felig P., Pozefsk T., Marlis E., Cahill G.F. Alanine: key role in gluconeogenesis. Science 1970;167(3920):1003-1004. doi:10.1126/science.167.3920.1003
2,3-Bisphosphoglycerate (2,3-BPG) is the conjugated base of 2,3-bisphosphoglyceric acid.[1]
In red blood cells, at sea level, 2,3-BPG is found in concentrations close to that of hemoglobin (Hb), about 5 mM. In contrast, in other cell types, it is found only in trace amounts.[2]
In erythrocytes, it is synthesized from 1,3-bisphosphoglycerate (1,3-BPG) in the first reaction of the Rapoport-Luebering shunt.[3][4] Since the shunt is a detour from the glycolytic pathway, occurring upstream of the reactions leading to ATP synthesis, the production of 2,3-bisphosphoglycerate incurs an energy cost of one ATP molecule per molecule produced.[5]
2,3-BPG is one of the regulators of the binding affinity of hemoglobin for oxygen.[6] It is also required for the catalytic activity of phosphoglycerate mutase (EC 5.4.2.1), and is an allosteric activator of ribose phosphate pyrophosphokinase (EC 2.7.6.1).[2][7]
By binding to hemoglobin, it lowers its oxygen affinity, thereby facilitating oxygen release in peripheral tissues.[6]
In red blood cells, the concentration of 2,3-bisphosphoglycerate can vary in response to changes in the flow of carbon through the glycolytic pathway. These variations may result from changes in altitude, diseases that impair blood oxygenation, or defects in glycolytic enzymes, and they affect hemoglobin binding affinity for oxygen.[8][9][10]
Summary: Key Points
Hemoglobin modulator: 2,3-BPG is an allosteric effector that lowers hemoglobin’s oxygen affinity, promoting oxygen release to tissues.
Rapoport-Luebering shunt: it is synthesized only in red blood cells via a glycolytic bypass, bypassing one ATP-generating step.
Structural selectivity: it binds tightly to adult hemoglobin (HbA) but less to fetal hemoglobin (HbF), facilitating maternal-fetal oxygen transfer.
Physiological adaptation: erythrocyte levels rise during hypoxia, anemia, and high-altitude exposure to optimize systemic oxygen delivery.
2,3-Bisphosphoglycerate is the conjugate base of 2,3-bisphosphoglyceric acid. It has a molecular weight of 261.00 g/mol, and molecular formula C3H3O10P2-5.[1]
According to the IUPAC nomenclature, its systematic name is (2R)-2,3-bis(phosphonooxy)propanoate.[11]
The pKa of 2,3-bisphosphoglyceric acid is 0.48. Therefore, at physiological pH, it exists almost exclusively in its ionized form, 2,3-BPG.[11]
It is soluble in water, with a solubility of 9.69 g/L.[1]
2,3-Bisphosphoglycerate is an isomer of 1,3-bisphosphoglycerate.
Metabolism
2,3-bisphosphoglycerate is produced from the glycolytic intermediate 1,3-bisphosphoglycerate in the first of the two steps of the Rapoport-Luebering shunt.[3][4]
Both reactions of the shunt are catalyzed by bisphosphoglycerate mutase (EC 5.4.2.4), a multifunctional enzyme with three main activities, 2,3-BPG synthase, its main activity, 2,3-BPG phosphatase, and 2,3-BPG mutase.[12]
In the first step of the Rapoport-Luebering shunt, bisphosphoglycerate mutase acts as a synthase and catalyzes the isomerization of 1,3-bisphosphoglycerate to 2,3-bisphosphoglycerate. The enzyme catalyzes the intermolecular transfer of a phosphate group from C-1 of 1,3-BPG to C-2 of 3-phosphoglycerate, which means that 3-phosphoglycerate must be present in the active site. During the reaction, 3-phosphoglycerate is converted into 2,3-bisphosphoglycerate, while 1,3-BPG is transformed into 3-phosphoglycerate.[6]
Biosynthetic Pathway and Functions of 2,3-BPG
In the second step, 2,3-bisphosphoglycerate is dephosphorylated into 3-phosphoglycerate. The reaction is catalyzed by the phosphatase activity of bisphosphoglycerate mutase. 3-Phosphoglycerate then re-enters the glycolytic pathway at the eighth step, which is catalyzed by phosphoglycerate mutase (EC 5.4.2.1).[5]
Energy cost of 2,3-bisphosphoglycerate synthesis
2,3-Bisphosphoglycerate synthesis incurs an energy cost for the red blood cell, equivalent to one ATP molecule per molecule produced.[5]
1,3-BPG is the substrate of the seventh reaction of glycolysis, in which phosphoglycerate kinase (EC 2.7.2.3) catalyzes the transfer of the high-energy phosphate group at the C-1 position to ADP, with the formation of 3-phosphoglycerate and ATP. Phosphoglycerate kinase catalyzes the first of two substrate-level phosphorylations that, along the glycolytic pathway, lead to the conservation of part of the chemical energy contained in glucose in the form of ATP, the cell’s energy currency.[6]
Since, under physiological conditions, the Rapoport-Luebering shunt intercepts approximately 20% of glycolytic carbon flux, the energy cost of 2,3-bisphosphoglycerate synthesis requires a finely tuned balance between the cell’s energy needs and the requirement to maintain hemoglobin in an optimal balance between deoxygenation and oxygenation.[13][14]
Role of 2,3-bisphosphoglycerate
2,3-bisphosphoglycerate has at least three biological functions.
It is required for the catalytic activity of phosphoglycerate mutase. Consequently, the molecule also contributes to the regulation of the levels of glycolytic intermediates.[7]
It is one of the allosteric activators of ribose phosphate pyrophosphokinase or PRPP synthase. The enzyme catalyzes the conversion of ribose-5-phosphate, one of the two products of the pentose phosphate pathway, into 5-phosphoribosyl-1-pyrophosphate (PRPP), an intermediate in the de novo synthesis of purines.[2]
2,3-BPG, along with other allosteric effectors, plays a role in the allosteric regulation of hemoglobin-oxygen affinity, facilitating oxygen release in peripheral tissues.[15] In humans, most primates, and many other mammals, 2,3-BPG reduces hemoglobin-oxygen affinity. In this way, 2,3-BPG promotes the dissociation of oxygen from hemoglobin, thus enhancing oxygen delivery to tissues.[6]
The action of 2,3-BPG is an example of heterotropic allosteric regulation, i.e., allosteric regulation in which the effector is different from the normal ligand of the protein.[5]
Hemoglobin
Hemoglobin is found in red blood cells and, in almost all vertebrates, it is responsible for carrying oxygen to tissues.
The protein has a quaternary structure formed by four subunits and contains four heme prosthetic groups, one per subunit, each of which can reversibly bind an oxygen molecule.[13]
Under physiological conditions, two types of hemoglobin are found in humans: hemoglobin A and hemoglobin F, which is found in the fetus.
Hemoglobin A is composed of two α chains of 141 amino acid residues and two β chains of 146 amino acid residues. Therefore, it is an α2β2 tetramer.
In hemoglobin F, the β chains are replaced by γ chains, which are very similar, but not identical, to the β chains. The result is an α2γ2 stoichiometry.[13] This difference has a major influence on the protein’s affinity for oxygen.[5]
Hemoglobin can exist in two conformations known as the T (tense) and R (relaxed) states.
Although oxygen binds to hemoglobin in both the T and R states, it has a greater affinity for the R state, which is stabilized by the binding. The binding of oxygen by hemoglobin is modulated by several factors, some exerting short-term effects and others, such as 2,3-bisphosphoglycerate, exerting long-term effects.[6]
Cooperativity of hemoglobin-oxygen binding
Hemoglobin in the deoxygenated state is in the T conformation. Oxygen binding to hemoglobin in the T state can occur only on the heme group of one α subunit, since the heme groups of the β subunits in the T state are virtually inaccessible.[6]
The binding of the first oxygen molecule triggers a conformational change in the α subunit, causing its conversion to the R state. This change is transmitted to adjacent subunits via subunit-subunit interactions, which then cause the second α subunit to switch to the R state. This triggers sequential conformational changes that lead to the transition of hemoglobin’s quaternary structure, which binds two oxygen molecules, Hb(O2)2, from the T state to the R state. At this point, the β subunits are now able to bind oxygen.[6]
This type of binding is called cooperative binding and is the basis of the sigmoidal shape of the hemoglobin-oxygen binding curve.[16]
Hemoglobin affinity for oxygen
In the lung capillaries, oxygen binds to hemoglobin and through the bloodstream reaches the peripheral tissues, where it is released.
The affinity between hemoglobin and oxygen is mainly determined by the structure of hemoglobin. However, it is modulated by various factors such as:
Changes in the affinity of the Hb-O2 bond that occur in the circulatory system due to the above factors optimize oxygen uptake in the lungs and its release in peripheral tissues.[10]
Graphically, changes in binding affinity induced by allosteric effectors and temperature translate into shifts of the hemoglobin-oxygen binding curve to the right, in the case of a decrease in binding affinity, or to the left, when binding affinity increases.[5]
Temperature, pH, and CO2 exert short-term effects.[10] For example, in skeletal muscle during physical activity, temperature, the concentration of hydrogen ions (H⁺) and partial pressure of CO2 increase. High concentrations of H⁺ and CO2 lower hemoglobin affinity for oxygen, an effect known as the Bohr effect. An increase in temperature also decreases affinity. These factors collectively favor the release of oxygen to the muscle tissue.[17]
Cl⁻ and 2,3-bisphosphoglycerate also decrease hemoglobin affinity for oxygen, but they are involved in long-term modulation.[10]
2,3-Bisphosphoglycerate and hemoglobin A
2,3-Bisphosphoglycerate binds to hemoglobin A through ionic bonds with positively charged residues of the β chains.
The bonds between 2,3-bisphosphoglycerate and hemoglobin involve the side chains of lysine 82, histidine 143, and the N-terminal amino group of each of the two β chains. These residues form an electrostatic pocket that is complementary to both the conformation and the charge distribution of 2,3-BPG.[5]
2,3-BPG binds to deoxygenated hemoglobin and stabilizes the T state. H⁺, Cl–, and CO2 also stabilize the T state.[10]
During the transition from the T to the R state, among the conformational changes occurring in the quaternary structure of hemoglobin, the binding pocket for 2,3-BPG between the β subunits narrows, preventing its binding. Notably, while hemoglobin has four binding sites for molecular oxygen, it has only one for 2,3-BPG.[6]
Furthermore, the binding site for 2,3-BPG is located far from that of oxygen.[5]
2,3-Bisphosphoglycerate and hemoglobin F
The γ chains of hemoglobin F, like the β chains of hemoglobin A, form the binding pocket for 2,3-BPG.[5]
However, there are two fewer positively charged residues in the binding pocket than in hemoglobin A. In fact, at position 143 of the γ chains, a histidine is replaced by a serine.[2]
This small difference in the primary structure means that 2,3-bisphosphoglycerate binds with lower affinity, and consequently, hemoglobin F has a higher oxygen affinity than maternal hemoglobin. This helps ensure the transfer of oxygen from hemoglobin A to hemoglobin F, and thus from the maternal circulation to the fetal circulation.[6]
Changes in 2,3-bisphosphoglycerate concentration
The concentration of 2,3-bisphosphoglycerate in red blood cells can be influenced by various factors, both physiological and pathological.[2]
Physiological conditions include the adaptation to high altitude, while pathological conditions include genetic defects affecting glycolytic enzymes, both downstream and upstream of the reaction catalyzed by glyceraldehyde 3-phosphate dehydrogenase (EC 1.2.1.12), and diseases that cause hypoxia.[18][19]
In all cases, changes are due to variations in the rate of 2,3-BPG synthesis and are reflected in hemoglobin-oxygen affinity.
Adaptation to high altitudes
Adaptation to high altitude is a rather complex process that also involves an increase in the number of red blood cells and their hemoglobin content. These changes require weeks to complete. However, after just one day at high altitude, some degree of adaptation is perceived. This effect is a consequence of the increase in 2,3-bisphosphoglycerate concentration in red blood cells.[2]
What happens is that the low partial pressure of oxygen leads to an increase in blood pH (alkalosis) which stimulates glycolysis. This, in turn, leads to an increased carbon flow through the Rapoport-Luebering shunt. This causes an increase in the synthesis of 2,3-bisphosphoglycerate, whose concentration can reach up to 8 mM. Such increase leads to a decrease in hemoglobin-oxygen affinity, facilitating oxygen release to the peripheral tissues and thus contributing to adaptation to high altitudes.[5]
Anemia
Variations in erythrocyte 2,3-bisphosphoglycerate concentration also occur in two autosomal recessive diseases: non-spherocytic hemolytic anemia due to hexokinase deficiency and hemolytic anemia due to red cell pyruvate kinase deficiency.[18][19]
In hemolytic anemia due to red cell pyruvate kinase (EC 2.7.1.40) deficiency, enzyme deficiency causes an increase in the synthesis of 2,3-BPG and, consequently, a reduction in hemoglobin-oxygen affinity.[8] An increase in 2,3-BPG concentration also occurs in individuals affected by conditions that limit blood oxygenation, such as hypoxia-inducing conditions. An example is cardiopulmonary failure.[2]
In non-spherocytic hemolytic anemia due to hexokinase deficiency (EC 2.7.1.1), the enzyme deficiency reduces 2,3-bisphosphoglycerate concentration in red blood cells, leading to an increase in hemoglobin-oxygen affinity.[9]
^ abcdefg Heilman D., Woski S., Voet D., Voet J.G., Pratt C.W. Fundamentals of biochemistry: life at the molecular level. 6th Edition. Wiley, 2023.
^ ab Rapoport S., Luebering J. Glycerate-2,3-diphosphatase. J Biol Chem 1951;189(2):683-694.
^ ab Rapoport S., Luebering J. The formation of 2,3-diphosphoglycerate in rabbit erythrocytes: the existence of a diphosphoglycerate mutase. J Biol Chem 1950;183(2):507-516.
^ abcdefghij Nelson D.L., Cox M.M. Lehninger. Principles of biochemistry. 8th Edition. W.H. Freeman and Company, 2021.
^ ab Oslund R.C., Su X., Haugbro M., Kee J-M., Esposito M., David Y., Wang B., Ge E., Perlman D.H., Kang Y., Muir T.W., Rabinowitz J.D. Bisphosphoglycerate mutase controls serine pathway flux via 3-phosphoglycerate. Nat Chem Biol 2017;13:1081-1087. doi:10.1038/nchembio.2453
^ ab Enegela O.A., Anjum F. Pyruvate Kinase Deficiency. [Updated 2023 Apr 27]. In: StatPearls [Internet]. Treasure Island (FL): StatPearls Publishing; 2025 Jan-. Available from: https://www.ncbi.nlm.nih.gov/books/NBK560581/
^ ab Paglia D.E., Shende A., Lanzkowsky P., Valentine W.N. Hexokinase “New Hyde Park”: a low activity erythrocyte isozyme in a Chinese kindred. Am J Hematol 1981;10(2):107-17. doi:10.1002/ajh.2830100202
^ abcde Webb K.L., Dominelli P.B., Baker S.E., Klassen S.A., Joyner M.J., Senefeld J.W., Wiggins C.C. Influence of high hemoglobin-oxygen affinity on humans during hypoxia. Front Physiol 2022;12:763933. doi:10.3389/fphys.2021.763933
^ Aljahdali A.S., Musayev F.N., Burgner J.W. 2nd, Ghatge M.S., Shekar V., Zhang Y., Omar A.M., Safo M.K. Molecular insight into 2-phosphoglycolate activation of the phosphatase activity of bisphosphoglycerate mutase. Acta Crystallogr D Struct Biol 2022;78(Pt 4):472-482. doi:10.1107/S2059798322001802
^ abc Moran L.A., Horton H.R., Scrimgeour K.G., Perry M.D. Principles of Biochemistry. 5th Edition. Pearson, 2012.
^ Hodgkins S.R. 6 – Erythrocyte metabolism and membrane structure and function. Editor(s): Keohane E.M., Otto C.N., Walenga J.M. Rodak’s Hematology (Sixth Edition), Elsevier. 2020:78-90. doi:10.1016/B978-0-323-53045-3.00015-5
^ ab Mairbäurl H., Oelz O., Bärtsch P. Interactions between Hb, Mg, DPG, ATP, and Cl determine the change in Hb-O2 affinity at high altitude. J Appl Physiol 1993;74(1):40-8. doi:10.1152/jappl.1993.74.1.40
^ Henry E.R., Bettati S., Hofrichter J., Eaton W.A. A tertiary two-state allosteric model for hemoglobin. Biophys Chem 2002;98(1-2):149-64. doi:10.1016/s0301-4622(02)00091-1
^ Böning D., Schwiegart U., Tibes U., Hemmer B. Influences of exercise and endurance training on the oxygen dissociation curve of blood under in vivo and in vitro conditions. Eur J Appl Physiol Occup Physiol 1975;34(1):1-10. doi:10.1007/BF00999910
The Rapoport-Luebering shunt is a metabolic pathway predominantly present in red blood cells and is a side glycolytic pathway that branches off at the level of 1,3-bisphosphoglycerate (1,3-BPG).[1][2]
The two reactions of the shunt are catalyzed by a multifunctional enzyme, bisphosphoglycerate mutase (EC 5.4.2.4). However, a second enzyme involved in the shunt, 2,3-bisphosphoglycerate 3-phosphatase (EC 3.1.3.80), has recently been identified.[3]
The most important product is 2,3-bisphosphoglycerate (2,3-BPG), an allosteric effector of hemoglobin that reduces its affinity for molecular oxygen, thereby facilitating its release at the tissue level.[4][5]
As it branches off from glycolysis upstream of the reactions leading to ATP synthesis, the Rapoport-Luebering shunt imposes an energy cost on the cell.[3]
Defects in glycolytic enzymes in red blood cells lead to abnormalities in 2,3-BPG synthesis and, consequently, in the affinity of hemoglobin for molecular oxygen.[6]
In Summary: Key Points
Biological function: the Rapoport-Luebering shunt is a side pathway of glycolysis exclusive to erythrocytes, essential for regulating oxygen delivery to body tissues.
Crucial metabolite: it produces 2,3-bisphosphoglycerate, an allosteric effector that binds to deoxyhemoglobin, stabilizing it and thereby promoting oxygen release to peripheral tissues.
Enzymatic control: metabolic flux is primarily governed by the trifunctional enzyme bisphosphoglycerate mutase, alongside the phosphatase activity of MIPP1.
Energy trade-off and pathology: Bypassing glycolysis costs the cell 2 ATP per glucose molecule; imbalances caused by enzyme defects (e.g., pyruvate kinase or hexokinase deficiency) lead to hemolytic anemia.
Schematic Representation of the Rapoport-Luebering Shunt
Bisphosphoglycerate mutase is a central enzyme in the Rapoport-Luebering shunt, and is found in red blood cells.[4]
It is a multifunctional enzyme, as it functions as a 2,3-bisphosphoglycerate synthase and a 2,3-bisphosphoglycerate phosphatase. It is also a 2,3-bisphosphoglycerate mutase, an activity similar to that of glycolytic phosphoglycerate mutase (EC 5.4.2.1), but does not participate in the shunt. All three catalytic activities take place at the same active site, with synthase being the primary activity, which is inhibited by free 2,3-bisphosphoglycerate.[7][8]
The phosphatase activity is low, approximately 1000 times lower than the synthase activity, and is stimulated by various anions, including chloride, phosphate, sulfite, and, more markedly, 2-phosphoglycolate.[9]
Finally, it appears that the mutase activity is physiologically insignificant, catalyzing about 5 percent of the reversible conversion of 3-phosphoglycerate to 2-phosphoglycerate.[10][11]
Bisphosphoglycerate mutase is one of the three isoforms of phosphoglycerate mutase found in mammals. The other two isoforms are phosphoglycerate mutase 1 or type M, present in muscle, and phosphoglycerate mutase 2 or type B, present in all other tissues. These two isoforms are also trifunctional enzymes.[4]
Reactions
The Rapoport-Luebering shunt involves two reactions.
In the first reaction, bisphosphoglycerate mutase acts as a synthase, catalyzing the isomerization of 1,3-BPG to 2,3-bisphosphoglycerate. The enzyme requires 3-phosphoglycerate, as it catalyzes the intermolecular transfer of a phosphate group from C-1 of 1,3-bisphosphoglycerate to C-2 of 3-phosphoglycerate. In the reaction, therefore, the starting 3-phosphoglycerate becomes 2,3-BPG, while 1,3-BPG becomes the new 3-phosphoglycerate.[12]
In the second step, the phosphatase activity of bisphosphoglycerate mutase catalyzes the synthesis of 3-phosphoglycerate, a glycolytic intermediate, following the hydrolysis of the phosphate group at position C-2 of 2,3-BPG. The 3-phosphoglycerate produced can then re-enter the glycolytic pathway at the reaction catalyzed by phosphoglycerate mutase, i.e., the eighth step of the pathway.[5]
2,3-Bisphosphoglycerate 3-phosphatase
A study has identifying a second enzyme involved in the Rapoport-Luebering shunt. In addition to bisphosphoglycerate mutase, researchers have discovered a distinct 2,3-bisphosphoglycerate 3-phosphatase activity catalyzed by an evolutionarily conserved multiple inositol polyphosphate phosphatase, known as MIPP1, which has been found in Dictyostelium, birds, and mammals.
This discovery reveals that the formation of 3-phosphoglycerate, a precursor for serine biosynthesis and an activator of AMP-activated protein kinase, can be bypassed. By genetically manipulating MIPP1 expression in Dictyostelium, scientists demonstrated the enzyme’s physiologically relevant role in regulating cellular 2,3-BPG content.[3]
Role of the Rapoport-Luebering shunt
The Rapoport-Luebering shunt leads to the formation of 2,3-BPG, an allosteric effector of hemoglobin, along with carbon dioxide and hydrogen ions.[5]
2,3-Bisphosphoglycerate is found in high concentrations in human red blood cells, whereas in other cells, it is present only in trace amounts.[6] In most primates and many other mammals, it decreases hemoglobin’s affinity for molecular oxygen, thereby facilitating its release to the tissues.[3]
2,3-BPG binds to deoxyhemoglobin by means of ionic bonds with the β chains in the T state, a state in which these subunits form an electrostatic pocket complementary to both the conformation and the charge distribution of the molecule. The bond stabilizes the T state, hence deoxyhemoglobin, and is primarily responsible for hemoglobin’s cooperative binding of molecular oxygen.[12]
In trace amounts, 2,3-BPG is also required for the catalytic activity of phosphoglycerate mutase. It follows that another function of bisphosphoglycerate mutase, and hence of the Rapoport-Luebering shunt, is to control the level of glycolytic intermediates.[13]
Energy cost of the Rapoport-Luebering shunt
1,3-bisphosphoglycerate is an intermediate of the glycolytic pathway. In the seventh step of glycolysis, phosphoglycerate kinase (EC 2.7.2.3) catalyzes the transfer of the high-energy phosphoryl group at the C-1 position of 1,3-BPG to ADP, with the formation of ATP and 3-phosphoglycerate. The reaction, a substrate-level phosphorylation, is the first of two reactions in the glycolytic pathway in which part of the chemical energy contained in glucose is conserved in the form of ATP.[5]
Therefore, the entry of 1,3-BPG into the Rapoport-Luebering cycle incurs an energy cost equivalent to two ATP molecules per 1,3-bisphosphoglycerate molecule diverted from glycolysis.[3] As a result, a delicate balance exists between the energy demands of red blood cells and the requirement to maintain hemoglobin in an optimal state of oxygenation and deoxygenation.[14]
Relationship between glycolysis and the Rapoport-Luebering shunt
Under physiological conditions, the Rapoport-Luebering shunt intercepts approximately 20% of the glycolytic flux in red blood cells.[8] It follows that defects in erythrocyte glycolytic enzymes influence the shunt and, consequently, the affinity of hemoglobin for molecular oxygen.[6]
Two conditions that illustrate this connection are nonspherocytic hemolytic anemia due to hexokinase deficiency and hemolytic anemia due to pyruvate kinase deficiency in erythrocytes, both of which are autosomal recessive diseases.[15][16]
In nonspherocytic hemolytic anemia due to hexokinase deficiency there is a deficiency of erythrocyte hexokinase (EC 2.7.1.1).[17] The enzyme catalyzes the phosphorylation of glucose to glucose-6-phosphate. Its deficiency leads to a decrease in the erythrocyte concentration of 2,3-BPG and, consequently, an increase in the affinity of hemoglobin for molecular oxygen.[6]
In contrast, hemolytic anemia due to pyruvate kinase deficiency in erythrocytes is characterized by a deficiency of pyruvate kinase (EC 2.7.1.40), leading to increased synthesis of 2,3-BPG and a decreased affinity of hemoglobin for molecular oxygen.[18]
Reference
^ Rapoport S., Luebering J. Glycerate-2,3-diphosphatase. J Biol Chem 1951;189(2):683-694.
^ Rapoport S., Luebering J. The formation of 2,3-diphosphoglycerate in rabbit erythrocytes: the existence of a diphosphoglycerate mutase. J Biol Chem 1950;183(2):507-516.
^ abcde Cho J., King J.S., Qian X., Harwood A.J., Shears S.B. Dephosphorylation of 2,3-bisphosphoglycerate by MIPP expands the regulatory capacity of the Rapoport-Luebering glycolytic shunt. Proc Natl Acad Sci U S A 2008;105(16):5998-6003. doi:10.1073/pnas.0710980105
^ abc DiMauro S., Miranda A.F., Khan S., Gitlin K., Friedman R. Human muscle phosphoglycerate mutase deficiency: newly discovered metabolic myopathy. Science 1981;212(4500):1277-9. doi:10.1126/science.6262916
^ abcd Nelson D.L., Cox M.M. Lehninger. Principles of biochemistry. 8th Edition. W.H. Freeman and Company, 2021.
^ abcd Voet D. and Voet J.D. Biochemistry. 4th Edition. John Wiley J. & Sons, Inc. 2011.
^ Aljahdali A.S., Musayev F.N., Burgner J.W. 2nd, Ghatge M.S., Shekar V., Zhang Y., Omar A.M., Safo M.K. Molecular insight into 2-phosphoglycolate activation of the phosphatase activity of bisphosphoglycerate mutase. Acta Crystallogr D Struct Biol 2022;78(Pt 4):472-482. doi:10.1107/S2059798322001802
^ ab Moran L.A., Horton H.R., Scrimgeour K.G., Perry M.D. Principles of Biochemistry. 5th Edition. Pearson, 2012.
^ Reynolds C.H. Activation of human erythrocyte 2,3-bisphosphoglycerate phosphatase at physiological concentrations of substrate. Arch Biochem Biophys 1986;250(1):106-11. doi:10.1016/0003-9861(86)90706-x
^ Lemarchandel V., Joulin V., Valentin C., Rosa R., Galactéros F., Rosa J., Cohen-Solal M. Compound heterozygosity in a complete erythrocyte bisphosphoglycerate mutase deficiency. Blood 1992;80(10):2643-9. doi:10.1182/blood.V80.10.2643.2643
^ Sasaki R., Chiba H. Role and induction of 2,3-bisphosphoglycerate synthase. Mol Cell Biochem 1983;53-54(1-2):247-56. doi:10.1007/BF00225257
^ Oslund R.C., Su X., Haugbro M., Kee J-M., Esposito M., David Y., Wang B., Ge E., Perlman D.H., Kang Y., Muir T.W., Rabinowitz J.D. Bisphosphoglycerate mutase controls serine pathway flux via 3-phosphoglycerate. Nat Chem Biol 2017;13:1081-1087. doi:10.1038/nchembio.2453
^ Hodgkins S.R. 6 – Erythrocyte metabolism and membrane structure and function. Editor(s): Keohane E.M., Otto C.N., Walenga J.M. Rodak’s Hematology (Sixth Edition), Elsevier. 2020:78-90. doi:10.1016/B978-0-323-53045-3.00015-5
^ Paglia D.E., Shende A., Lanzkowsky P., Valentine W.N. Hexokinase “New Hyde Park”: a low activity erythrocyte isozyme in a Chinese kindred. Am J Hematol 1981;10(2):107-17. doi:10.1002/ajh.2830100202
^ Enegela O.A., Anjum F. Pyruvate Kinase Deficiency. [Updated 2023 Apr 27]. In: StatPearls [Internet]. Treasure Island (FL): StatPearls Publishing; 2025 Jan-. Available from: https://www.ncbi.nlm.nih.gov/books/NBK560581/
Pyruvic acid, an alpha-ketoacid, is a molecule with a central role in cellular metabolism.[1][2]
It can be produced through various metabolic pathways, mostly cytosolic, among which glycolysis is usually the most important pathway, while its fate depends on the cell type and the availability of oxygen, as it can be used for energy, biosynthetic, and anaplerotic purposes.[3]
Given its central role in cellular metabolism, mutations in the genes that encode the proteins involved in its metabolism cause, in humans, mild to severe diseases.[4]
Summary: Key Points
Metabolic hub: pyruvic acid is a central molecule in cellular metabolism; at physiological pH, it exists almost entirely in its anionic form as pyruvate.
Cytosolic origin: under physiological conditions, it is mainly derived from glycolysis, but it can also be generated via lactate oxidation, alanine transamination, or the malic enzyme.
Oxygen crossroads: under hypoxic conditions (or in cells without mitochondria), it is reduced to lactate to regenerate NAD+; in the presence of oxygen, it enters the mitochondrion via MPC transporters.
Mitochondrial fates: once in the matrix, it is converted into acetyl-CoA by the pyruvate dehydrogenase complex for energy production, or carboxylated into oxaloacetate for anaplerotic purposes.
Pyruvic acid or, according to the IUPAC nomenclature, 2-oxopropanoic acid, has a molecular formula C3H4O3, condensed formula CH3COCOOH, and molecular weight of 88.06 g/mol.
It belongs to the group of alpha-ketoacids, meaning keto acids that have the carbonyl group adjacent to the carboxylic acid. It has the simplest chemical structure among the alpha-ketoacids.[1]
In purified form it appears as a colorless liquid, with a smell similar to that of acetic acid.
Its acid dissociation constant (pKa), at 25 °C, is equal to 2.45. It is therefore a very strong acid, and, at physiological pH, both in cells and in extracellular fluids, is present almost entirely in its anionic form, pyruvate.
Its melting point is 13.8 °C (56.84 °F; 286.95 K), while its boiling point is 163.5 °C (329 °F; 438 K).[1]
Pyruvate metabolism
The biosynthetic pathways leading to pyruvic acid production, as well as its subsequent utilization, depend on the cell type and/or the availability of oxygen.[3]
Cytosolic and Mitochondrial Metabolic Pathways of Pyruvic Acid
In cells with mitochondria, pyruvate metabolism consists of a cytosolic and a mitochondrial phase.
In the cytosol, several metabolic pathways lead to its formation, namely, glycolysis, the oxidation of lactate, the reaction catalyzed by the cytosolic malic enzyme, and the catabolism of at least six amino acids, the most important of which is alanine.
Pyruvic acid production from alanine and lactate can also occur in the mitochondrial matrix.[5]
The pyruvic acid produced in the cytosol, by means of specific transporters, enters the mitochondrion where it can be used for energy, entering the citric acid cycle, and/or biosynthetic/anaplerotic purposes, depending on the needs of the cell.[6]
If, instead, we consider cells without mitochondria, such as red blood cells, and, under hypoxic conditions, cells with mitochondria too, pyruvate is reduced to lactate and/or leaves the cell as such to be metabolized in other tissues, for example cardiac muscle.[7]
Glycolysis
Under physiological conditions, in most cells pyruvic acid is mainly derived from glycolysis, of which it is one of the three products, with ATP and NADH.
In the last step of the glycolytic pathway, pyruvate kinase (EC 2.7.1.40) catalyzes a substrate-level phosphorylation that leads to the transfer of the phosphoryl group from phosphoenolpyruvate to ADP. The reaction, essentially irreversible, produces one molecule of ATP and one of pyruvate.
Phosphoenolpyruvate + ADP + H+ → Pyruvate + ATP
Therefore, during the glycolytic pathway, two molecules of pyruvate are produced from a glucose molecule.[2][8]
Lactate dehydrogenase
In the cytosol, pyruvic acid can be produced from lactic acid.
The enzyme lactate dehydrogenase (LDH) (EC 1.1.1.27) catalyzes the reversible conversion of pyruvate to lactate and of NADH to NAD+.
Pyruvate + NADH + H+ ⇄ Lactate + NAD+
The direction of the reaction depends on lactate dehydrogenase isozymes present and the NADH/NAD+ ratio in the cytosol.[3][5]
Isoenzymes in which the H subunit predominates, such as LDH-1, predominate in cardiac muscle, an exclusively aerobic tissue, where they catalyze the oxidation of lactate (formed in other tissues) to pyruvate, which is then used for energy.
The oxidation of lactate produced for example by red blood cells or skeletal muscle under hypoxic conditions, can also occur in hepatocytes, favored by the low NADH/NAD+ ratio in the cytosol, although LDH-5 is the main isoenzyme. In the hepatocyte, pyruvic acid can be enter gluconeogenesis, which in this case is part of the Cori cycle, or be oxidized for energy.[9]
Conversely, in skeletal muscle fiber under hypoxic conditions, in which the pyruvate dehydrogenase complex is inhibited and oxidative phosphorylation is blocked, in order for glycolysis to proceed pyruvate is reduced to lactate with the concomitant oxidation of NADH to NAD+.[10] Note that the conversion of glucose into lactate is defined as lactic fermentation. This reduction is favored by the fact that in skeletal muscle fiber isoenzymes with a prevalence of the M subunit predominate, such as LDH-4 and LDH-5.[11]
Alanine aminotransferase
Another source of pyruvic acid is alanine, an amino acid particularly abundant in muscle proteins.
The utilization of the carbon skeleton of amino acids for energy and/or anabolic purposes involves the removal of the basic amino group, which occurs in reactions catalyzed by enzymes called transaminases (EC 2.6.1-), and the subsequent disposal of nitrogen in a non-toxic form through the urea cycle.[2][8]
The removal of the amino group of alanine is catalyzed by alanine aminotransferase (ALT; EC 2.6.1.2). The reaction, reversible, leads to the formation of pyruvate and glutamate.
Two forms of ALT have been identified: ALT1, localized in the cytosol, and ALT2, localized in the mitochondrial matrix.[4] Hence, pyruvic acid can be produced by transamination of alanine also in the mitochondrial matrix.
Alanine is one of the main gluconeogenic precursors, and, through the glucose-alanine cycle, represents a link between the metabolism of carbohydrates and amino acids.[12]
In the cytosol, the carbon skeletons of five other amino acids, namely cysteine, glycine, serine, threonine and tryptophan, can be converted partly or entirely to pyruvate.[2]
Malic enzyme
Pyruvate can also be produced from malate.
In the reaction catalyzed by the cytosolic malic enzyme (EC 1.1.1.40), malate undergoes an oxidative decarboxylation to yield pyruvate.[3]
Malate + NADP+ → Pyruvate + CO2 + NADPH + H+
Malic enzyme plays an important role in the transport of intermediates of the citric acid cycle, such as, in addition to malate, oxaloacetate and citrate, between the cytosol and the mitochondrial matrix.[7]
Mitochondrial pyruvate carriers
In cells with mitochondria, most of the pyruvate produced in the cytosol enters the mitochondrial matrix passing through the outer and the inner mitochondrial membranes. In the mitochondrial matrix pyruvate can then be used for both anabolic and catabolic purposes.
The passage through the outer mitochondrial membrane occurs by free diffusion through non-specific voltage-dependent anion channels (VDACs) or porins, the most abundant proteins of the outer mitochondrial membrane, whose function is to mediate the exchange of ions and small molecules, including, in addition to pyruvate, also ATP, NADH and others, between the cytosol and the intermembrane space of mitochondria.[13][14]
Conversely, the inner mitochondrial membrane is impermeable to charged molecules, which allows the maintenance of the proton gradient needed for oxidative phosphorylation to occur. The passage of pyruvate therefore occurs through specific transporters, the mitochondrial pyruvate carriers (MPC), a hetero-oligomeric complex of two subunits, indicated as MPC1 and MPC2. This transport is coupled to a symport of protons. MPC therefore links the cytosolic and mitochondrial metabolism of pyruvate.[15][16]
Pyruvate dehydrogenase complex
Once in the mitochondrial matrix, pyruvate is mostly oxidized to carbon dioxide in order to support ATP production.
The first step in this oxidation process involves the pyruvate dehydrogenase complex (PDC), one of the most important multienzyme complexes present in cells. The complex catalyzes the irreversible oxidative decarboxylation of pyruvate to form acetyl-coenzyme A (acetyl-CoA) and a carbon dioxide molecule, with the release of two electrons, which are carried by NAD.
Pyruvate + CoA + NAD+ → Acetyl-CoA + NADH + H+ + CO2
The acetyl group can enter the citric acid cycle to be completely oxidized to carbon dioxide, with the production of a molecule of GTP, 3 molecules of NADH, one of FADH2. The two reduced coenzymes, through oxidative phosphorylation, will allow the production of further ATP molecules.[2]
Alternatively, the acetyl group derived from pyruvic acid can be used for anabolic purposes, among which the synthesis of some lipids, such as of fatty acids, phospholipids and cholesterol, or for regulatory purposes through histone acetylation.
Since lipid biosynthesis occurs in the cytosol and histone acetylation in the nucleus, acetyl-CoA must leave the mitochondrial matrix, a process that requires the formation of citrate through the condensation between the acetyl group and carbonyl of oxaloacetate, reaction catalyzed by citrate synthase (EC 2.3.3.1).
Once citrate has reached the cytosol, through a citrate carrier, an integral protein of the inner mitochondrial membrane, it is cleaved to acetyl-CoA and oxaloacetate in the reaction catalyzed by citrate lyase (EC 4.1.3.6).[17]
Pyruvate carboxylase
In the mitochondrial matrix, pyruvic acid can be carboxylated to oxaloacetate in an irreversible reaction catalyzed by pyruvate carboxylase (PC) (EC 6.4.1.1).[8]
Pyruvate + HCO3– + ATP → Oxaloacetate + ADP + Pi
Several intermediates of the citric acid cycle are precursors for the synthesis of various molecules. It follows that each of these intermediates removed from the citric acid cycle must be reintegrated for the cycle to continue. Reactions that reintegrate the cycle are defined as anaplerotic. In this perspective, the reaction catalyzed by pyruvate carboxylase plays an anaplerotic function, catalyzing the formation of oxaloacetate.[6]
^ abcde Nelson D.L., Cox M.M. Lehninger. Principles of biochemistry. 8th Edition. W.H. Freeman and Company, 2021.
^ abcd Berg J.M., Tymoczko J.L., Gregory J.G. Jr, Stryer L. Biochemistry. 9th Edition. W.H. Freeman and Company, 2019.
^ ab Gray L.R., Tompkins S.C., Taylor E.B. Regulation of pyruvate metabolism and human disease. Cell Mol Life Sci 2014;71(14):2577-604. doi:10.1007/s00018-013-1539-2
^ ab Markert C.L., Shaklee J.B., Whitt G.S. Evolution of a gene. Multiple genes for LDH isozymes provide a model of the evolution of gene structure, function and regulation. Science 1975;189(4197):102-14. doi:10.1126/science.1138367
^ ab Owen O.E., Kalhan S.C., Hanson R.W. The key role of anaplerosis and cataplerosis for citric acid cycle function. J Biol Chem 2002;277(34):30409-12. doi:10.1074/jbc.R200006200
^ ab McCommis K.S. and Finck B.N. Mitochondrial pyruvate transport: a historical perspective and future research directions. Biochem J 2015;466(3):443-454. doi:10.1042/BJ20141171
^ abc Moran L.A., Horton H.R., Scrimgeour K.G., Perry M.D. Principles of Biochemistry. 5th Edition. Pearson, 2012.
^ Gleeson T.T. Post-exercise lactate metabolism: a comparative review of sites, pathways, and regulation. Annu Rev Physiol 1996;58:565-81. doi:10.1146/annurev.ph.58.030196.003025
^ Li X., Yang Y., Zhang B., Lin X., Fu X., An Y., Zou Y., Wang J.X., Wang Z., Yu T. Lactate metabolism in human health and disease. Signal Transduct Target Ther 2022;7(1):305. doi:10.1038/s41392-022-01151-3
^ Farhana A., Lappin S.L. Biochemistry, lactate dehydrogenase. [Updated 2023 May 1]. In: StatPearls [Internet]. Treasure Island (FL): StatPearls Publishing; 2024 Jan-. Available from: https://www.ncbi.nlm.nih.gov/books/NBK557536/
^ Felig P., Pozefsk T., Marlis E., Cahill G.F. Alanine: key role in gluconeogenesis. Science 1970;167(3920):1003-1004. doi:10.1126/science.167.3920.1003
^ Colombini M. The VDAC channel: molecular basis for selectivity. Biochim Biophys Acta 2016;1863(10):2498-502. doi:10.1016/j.bbamcr.2016.01.019
^ Young M.J., Bay D.C., Hausner G., Court D.A. The evolutionary history of mitochondrial porins. BMC Evol Biol 2007;7:31. doi:10.1186/1471-2148-7-31
^ Bricker D.K., Taylor E.B., Schell J.C., Orsak T., Boutron A., Chen Y.C., Cox J.E., Cardon C.M., Van Vranken J.G., Dephoure N., Redin C., Boudina S., Gygi S.P., Brivet M., Thummel C.S., Rutter J. A mitochondrial pyruvate carrier required for pyruvate uptake in yeast, Drosophila, and humans. Science 2012;337(6090):96-100. doi:10.1126/science.1218099
^ Herzig S., Raemy E., Montessuit S., Veuthey J.L., Zamboni N., Westermann B., Kunji E.R., Martinou J.C. Identification and functional expression of the mitochondrial pyruvate carrier. Science 2012;337(6090):93-6. doi:10.1126/science.1218530
^ Zara V., Assalve G., Ferramosca A. Multiple roles played by the mitochondrial citrate carrier in cellular metabolism and physiology. Cell Mol Life Sci 2022;79(8):428. doi:10.1007/s00018-022-04466-0
Lactate dehydrogenase (LDH; EC 1.1.1.27) is a family of oxidoreductases that catalyze the reversible conversion of pyruvate, the conjugate base of pyruvic acid, to lactate, with the concomitant interconversion of NADH and NAD+, which act as cofactors.
They are tetrameric enzymes, where each subunit has catalytic activity. The subunits, encoded by distinct genes, can be assembled in different combination to form isozymes with specific kinetic and regulatory properties.[1]
Lactate dehydrogenase is found in almost all animal tissues, plants, but also in microorganisms. Although it is mostly present in the cytosol, its presence has also been demonstrated in mitochondria, where it catalyzes the oxidation of lactate to pyruvate, and in peroxisomes.[2][3]
In humans, different isoenzymes have preferential tissue localizations, based on the specific metabolic phenotype of the tissue.
Lactate dehydrogenase is a important enzyme in cellular metabolism, as it is involved in energy production from carbohydrates under anaerobic conditions, in the synthesis of glucose from lactate, and utilization of the carbon skeleton of lactate for energy under aerobic conditions.[1][4]
Summary: Key Points
Core reaction: lactate dehydrogenase (LDH) catalyzes the reversible interconversion between pyruvate and lactate, accompanied by the oxidation/reduction of NADH and NAD+.
Isoenzymes: human LDH exists as five main tetrameric isoforms (LDH-1 to LDH-5) formed by combinations of H and M subunits with tissue-specific distribution.
Genetic basis: distinct genes (LDHA, LDHB, LDHC, LDHx) encode L-lactate specific subunits, while the LDHD gene encodes a separate D-lactate dehydrogenase using FAD.
Metabolic role: essential for anaerobic glycolysis, allowing the regeneration of NAD+ to sustain cellular ATP production under hypoxic conditions.
Tissue specificity: heart tissue favors H-rich isoforms adapted for aerobic oxidative metabolism, while skeletal muscle and liver favor M-rich isoforms geared toward glycolysis.
In mammals, several genes encode the subunits of lactate dehydrogenase and are designated LDHA, LDHB, LDHC, LDHx, and LDHD.
The first four genes encode enzymes that recognize as substrate the L-isomers of lactic acid, a molecule with a chirality center, the major enantiomeric form of the molecule present in vertebrates, and have NAD as a cofactor, whereas LDHD encodes an enzyme that recognizes as substrate the D-isomer of lactic acid and has FAD as a cofactor.[5][6]
LDHA, located on chromosome 11p15.4, encodes the M subunit, named for its discovery in muscle, whereas LDHB, located on chromosome 12p12.2-p12.1, encodes the H subunit, named for its discovery in heart tissue.[2][7]
LDHC, located on chromosome 11p15.5-p15.3 and probably derived from the duplication of the LDHA, encodes the C subunit.[8]
Finally, LDHx encodes the peroxisomal form of LDH.[2] LDHx is the readthrough form of the LDHB gene; in fact what happens is that when the ribosome reaches the stop codon of the mRNA for the H subunit, reads it as encoding an amino acid. Then the translation proceeds by adding another seven amino acids that constitute the peroxisomal targeting signal by which the proteins are imported into the peroxisome.[3]
Structure
The enzymes belonging to the lactate dehydrogenase family have an oligomeric structure, specifically they are tetramers resulting from the assembly of subunits, of approximately 35 kD, which can be of the same type or two different types. Each subunit has a catalytic site, hence, the tetramer has four active sites. However, the subunits, taken individually, are catalytically inactive.[7][9]
Considering the H and M subunits, their primary structures are approximately 75% identical, and consequently, their three-dimensional structure is also very similar, but with small differences at the at the substrate binding site that lead to significant differences in the kinetic properties of the proteins.[1][10] Another consequence of the differences in the primary structure concerns the net surface charge, which is -6 for the M subunit and +1 for the H subunit.[11]
The secondary structure is made up of approximately 40 percent alpha-helices and 23% beta sheets, forming beta-alpha-beta structures, with the parallel beta sheets as the main component.[12]
In humans, the prevalent isozymes are those formed by the H and M subunits. The assembly, in different combinations, of the two subunits leads to the formation of five isozymes, namely:
From Gene Expression to the Tetrameric Structure of LDH
The C subunit forms a sixth isoform, a homotetramer, named as LDH-6 or C4.[8]
A seventh isoform derives from the assembly of the LDHx subunit.[3][8]
Reaction
Lactate dehydrogenase catalyzes the reversible conversion of pyruvate to lactate, with the concomitant interconversion of NADH and NAD+. In both cases, the removal of two hydrogen atoms from the reducing agent occurs, followed by the transfer of a hydride ion, namely, a proton and two electrons, to the oxidizing agent, while the remaining proton is released into the aqueous medium as free H+ ion. The enzyme is able to increase the reaction rate by 14 times.[5]
When the reaction proceeds from pyruvate to lactate, the first step is the binding of NADH, the reducing agent, to the enzyme, which is followed by conformational changes that facilitate the formation of hydrogen bonds between specific residues surrounding the active site and the carbonyl carbon of pyruvate, namely C2, and the subsequent interaction between NADH and pyruvate.[13] At this point, a hydride ion is transferred from the nicotinamide ring of NADH to the C2 of pyruvate, which is therefore reduced to lactate. This causes the oxidation of the coenzyme and neutralization of the positive charge carried by the nitrogen of the nicotinamide ring, and reduction of pyruvate to lactate. Therefore, in this case the C2 of pyruvate is reduced from ketone to alcohol.
In the opposite direction, the hydride ion is transferred from the C2 of lactate, which in this case is the reducing agent, to the to the nicotinamide atom C-4. In this case the C2 of lactate is oxidized from alcohol to ketone.[14][15]
Active site
The active site of the H and M subunits has a highly conserved structure in different species, with the same amino acids participating in the reaction.[16]His-193, which is found near the binding site for the coenzyme, is among these, not only for human lactate dehydrogenase, but also for that of many other species.
However, the small differences in their primary structure lead to different biochemical properties. Among the differences, one is crucial for the catalytic properties: an alanine of the M subunit is replaced by a glutamine in the H subunit, namely, a non-polar amino acid is replaced by a polar one.[11] Below is a brief overview of the catalytic differences between the two subunits.
The H subunit binds substrate faster than the M subunit, but has about five times less catalytic activity than the M subunit.
The M subunit has a higher affinity for pyruvate, thus favoring the formation of lactate and NAD+, and is not inhibited by high concentrations of pyruvate. Conversely, the H subunit has a higher affinity for lactate, which favors the formation of pyruvate and NADH, and is inhibited by high concentrations of pyruvate.[17][18]
From all this it follows that the kinetic/catalytic properties of the different isozymes depend on the prevalence of one of the two subunits.[19]
Regulation by pyruvate and lactate
Lactate dehydrogenase isozymes are subject to inhibition by pyruvate and lactate.
The isozymes where the H subunit predominates are inhibited by lower pyruvate concentrations than those where the M subunit predominates. For example, H4 is inhibited by pyruvate concentrations of about 0.2 mM, while M4 is weakly inhibited by pyruvate concentrations up to 5 mM.
Conversely, H4 is inhibited by lactate concentrations greater than 20-40 mM, whereas M4 is inhibited to a lesser extent by high lactate concentrations.[20]
Tissue distribution
In humans, the different lactate dehydrogenase isozymes have preferential tissue localizations, which generally reflect the metabolic phenotype of the tissue.
In fact, tissues with a predominantly or exclusively aerobic metabolic phenotype, such as the heart, produce mainly isozymes in which the H subunit predominate.[21]
By contrast, tissues where anaerobic metabolism is important, such as muscle fibers during vigorous exercise, or hypoxic regions in solid tumors, produce mainly isozymes in which the M subunit predominate.[5]
However, there are exceptions, such as the liver, an organ with an aerobic metabolic phenotype where LDH-5 predominates, but where the oxidation of lactate to pyruvate, which can also be considered as a part of the hepatic branch of the Cori cycle, is favored by the low NADH/NAD+ ratio in the hepatocyte cytosol.[13]
Below is a brief overview.
LDH-1 or H4: cardiac muscle, kidney and red blood cells.
LDH-2 or M1H3 has a distribution similar to LDH-1.
LDH-3 or M2H2: spleen, brain, white blood cells, kidney and lung.
LDH-4 or M3H1: spleen, lung, skeletal muscle, red blood cells and kidney.
LDH-5 or M4: liver, skeletal muscle and lung.
LDH-6: sperm and testis.
In individual organs, LDH-1 and LDH-2 predominates in the heart, kidney and red blood cells, LDH-3 in the lung, LDH-4 and LDH-5 in skeletal muscle and LDH-5 in the liver.
The isozymes present in serum, whose dosage is used for diagnostic purposes, are always of tissue origin.[5]
Finally, in the same tissue/organ, different isozymes can be present in significant quantities in different cell types, as for example occurs in skeletal muscle, in the brain, but also in solid tumors.
Role
Lactate dehydrogenase is involved both in the synthesis and utilization/removal of lactate.[4]
Under hypoxic conditions, the cell obtains ATP from the anaerobic oxidation of glucose. Through the glycolytic pathway, the monosaccharide is oxidized to two molecules of pyruvate, yielding 2 ATP and two NADH. However, for glycolysis to proceed, the NADH produced must be reoxidized to NAD+, as the oxidized coenzyme is involved in the reaction catalyzed by glyceraldehyde-3-phosphate dehydrogenase (EC 1.2.1.12). As the pyruvate dehydrogenase complex is inhibited and oxidative phosphorylation is blocked, the oxidation of NADH occurs in the reaction catalyzed by lactate dehydrogenase, which then allows glycolysis to proceed even in hypoxic conditions. This metabolic pathway produces lactate from glucose, and is known as lactic acid fermentation.[13][22]
Lactic acid is often considered an end product of glucose metabolism, and its accumulation in the body is harmful as it may potentially causelactic acidosis.[22] Therefore, it must be rapidly removed from tissues and circulation. Considering for example the lactose produced by red blood cells or muscle fibers working in under hypoxic conditions, such as during vigorous exercise, or continuously by the red blood cell, through bloodstream, it can reach, among others, the liver and the heart. In the liver, although LDH-5 is the major isozyme, the low cytosolic NADH/NAD+ ratio shifts the equilibrium of the reaction toward pyruvate synthesis, which can be used for energy or enter into gluconeogenesis.[23] In the cardiomyocyte LDH-1 oxidizes lactate to pyruvate, that will be used for energy.
References
^ abc Berg J.M., Tymoczko J.L., Gregory J.G. Jr, Stryer L. Biochemistry. 9th Edition. W.H. Freeman and Company, 2019.
^ abc Markert C.L., Shaklee J.B., Whitt G.S. Evolution of a gene. Multiple genes for LDH isozymes provide a model of the evolution of gene structure, function and regulation. Science 1975;189(4197):102-14. doi:10.1126/science.1138367
^ abc Schueren F., Lingner T., George R., Hofhuis J., Dickel C., Gärtner J., Thoms S. Peroxisomal lactate dehydrogenase is generated by translational readthrough in mammals. Elife 2014;3:e03640. doi:10.7554/eLife.03640
^ abc Laughton J.D., Charnay Y., Belloir B., Pellerin L., Magistretti P.J., Bouras C. Differential messenger RNA distribution of lactate dehydrogenase LDH-1 and LDH-5 isoforms in the rat brain. Neuroscience 2000;96(3):619-25. doi:10.1016/s0306-4522(99)00580-1
^ abcd Farhana A., Lappin S.L. Biochemistry, lactate dehydrogenase. [Updated 2023 May 1]. In: StatPearls [Internet]. Treasure Island (FL): StatPearls Publishing; 2024 Jan-. Available from: https://www.ncbi.nlm.nih.gov/books/NBK557536/
^ Jin S., Chen X., Yang J., Ding J. Lactate dehydrogenase D is a general dehydrogenase for D-2-hydroxyacids and is associated with D-lactic acidosis. Nat Commun 2023;14(1):6638. doi:10.1038/s41467-023-42456-3
^ ab Krieg A.F., Rosenblum L.J., Henry J.B. Lactate dehydrogenase isozymes a comparison of pyruvate-to-lactate and lactate-to-pyruvate assays. Clin Chem 1967;13(3):196-203. doi:10.1093/clinchem/13.3.196
^ abc Zinkham W.H., Blanco A., Clowry L.J. Jr. An unusual isozyme of lactic dehydrogenase in mature testes: localization, ontogeny, and kinetic properties. Ann N Y Acad Sci 1964;121:571-88. doi:10.1111/j.1749-6632.1964.tb14227.x
^ Bellamacina C.R. The nicotinamide dinucleotide binding motif: a comparison of nucleotide binding proteins. FASEB J 1996;10(11):1257-69. doi:10.1096/fasebj.10.11.8836039
^ ab Read J.A., Winter V.J., Eszes C.M., Sessions R.B., Brady R.L. Structural basis for altered activity of M- and H-isozyme forms of human lactate dehydrogenase. Proteins 2001;43(2):175-85.
^ Auerbach G., Ostendorp R., Prade L., Korndörfer I., Dams T., Huber R., Jaenicke R. Lactate dehydrogenase from the hyperthermophilic bacterium thermotoga maritima: the crystal structure at 2.1 A resolution reveals strategies for intrinsic protein stabilization. Structure 1998;6(6):769-81. doi:10.1016/s0969-2126(98)00078-1
^ abc Forkasiewicz A., Dorociak M., Stach K., Szelachowski P., Tabola R., Augoff K. The usefulness of lactate dehydrogenase measurements in current oncological practice. Cell Mol Biol Lett 2020;25:35. doi:10.1186/s11658-020-00228-7
^ Moran L.A., Horton H.R., Scrimgeour K.G., Perry M.D. Principles of Biochemistry. 5th Edition. Pearson, 2012.
^ Nelson D.L., Cox M.M. Lehninger. Principles of biochemistry. 8th Edition. W.H. Freeman and Company, 2021.
^ Holmes R.S., Goldberg E. Computational analyses of mammalian lactate dehydrogenases: human, mouse, opossum and platypus LDHs. Comput Biol Chem 2009;33(5):379-85. doi:10.1016/j.compbiolchem.2009.07.006
^ Feng Y., Xiong Y., Qiao T., Li X., Jia L., Han Y. Lactate dehydrogenase A: a key player in carcinogenesis and potential target in cancer therapy. Cancer Med 2018;7(12):6124-6136. doi:10.1002/cam4.1820
^ Gray L.R., Tompkins S.C., Taylor E.B. Regulation of pyruvate metabolism and human disease. Cell Mol Life Sci 2014;71(14):2577-604. doi:10.1007/s00018-013-1539-2
^ Rogatzki M.J., Ferguson B.S., Goodwin M.L., Gladden L.B. Lactate is always the end product of glycolysis. Front Neurosci 2015;9:22. doi:10.3389/fnins.2015.00022
^ Stambaugh R., Post D. Substrate and product inhibition of rabbit muscle lactic dehydrogenase heart (H4) and muscle (M4) isozymes. J Biol Chem 1966;241(7):1462-7. doi:10.1016/S0021-9258(18)96733-5
^ Wroblewski F., Gregory K.F. Lactic dehydrogenase isozymes and their distribution in normal tissues and plasma and in disease states. Ann N Y Acad Sci 1961;94:912-32. doi:10.1111/j.1749-6632.1961.tb35584.x
^ ab Li X., Yang Y., Zhang B., Lin X., Fu X., An Y., Zou Y., Wang J.X., Wang Z., Yu T. Lactate metabolism in human health and disease. Signal Transduct Target Ther 2022;7(1):305. doi:10.1038/s41392-022-01151-3
^ Gleeson T.T. Post-exercise lactate metabolism: a comparative review of sites, pathways, and regulation. Annu Rev Physiol 1996;58:565-81. doi:10.1146/annurev.ph.58.030196.003025
Carbanions are ions containing a negatively charged carbon atom.
They are formed by the heterolytic cleavage of a covalent bond between a carbon atom and another atom or group.[1]
Having an unshared electron pair, they are powerful nucleophiles, and strong bases, and attack, in order to form a covalent bond, a proton or an electrophilic center, such as a polarized or positively charged center.[2]
Carbanions are extremely reactive. Therefore, they must be stabilized to allow them to attack electrophilic centers.[3] Stabilization may occur by inductive effect, resonance, and may also depend on the hybridization of the carbon atom carrying the negative charge.[1][2]
They are intermediates in many enzyme-catalyzed reactions.
Summary: Key Points
Reactive Intermediates: carbanions are organic ions containing a negatively charged carbon atom with an unshared electron pair, making them powerful nucleophiles and strong bases.
Heterolytic cleavage: they are generated via the non-uniform breaking (heterolysis) of a covalent bond, where the carbon atom retains both bonding electrons from a less electronegative group.
Stabilization mechanisms: as highly transient species, their stability depends on negative inductive effects (-I), resonance delocalization within electron sinks, and an increased s-character of the hybrid orbitals (sp > sp2 > sp3).
Biochemical roles: They serve as vital intermediates in key enzyme-catalyzed pathways, such as 2-oxoacid oxidative decarboxylations, where their formation is actively mediated and stabilized by the cofactor thiamine pyrophosphate.
Considering two atoms or groups, indicated as A and B, joined by a covalent bond, there are two ways to break the bond: heterolysis and homolysis.
Mechanisms of Covalent Bond Cleavage for a Hypothetical C:Z Molecule
In heterolysis, the breaking of the covalent bond leads to the formation of two charged atoms, namely two ions, a cation and an anion, as both bonding electrons are retained by by the more electronegative of the two atoms.[4]
A:B → :A– + B+, if A is more electronegative than B;
A:B → A+ + :B–, if B is more electronegative than A.
In the heterolysis of a covalent bond involving a carbon atom, if both electrons are retained by the carbon atom, it will have a negative charge, therefore it is an anion, and is defined as a carbanion. On the contrary, if the carbon loses both electrons, it will have a positive charge, therefore it is a cation, and is defined as a carbocation.[5]
In homolysis, the breaking of the covalent bond between A and B leads to the formation of two free radicals, as each atom or group takes one of the two bonding electrons.[6] Free radicals, which are electrically neutral, are also very unstable molecules. Note that homolytic cleavage is less common than heterolytic cleavage.[7]
Stabilization of carbanions
Carbanions are extremely reactive chemical species, and, like carbocations and free radicals, they are almost always transient intermediates in organic reactions. In order to allow their attack to the electrophilic centers, they must be stabilized. Their stabilization depends on the dispersion of the negative charge, which may occur by inductive effect, resonance, and may also depend on the s-character of the hybrid orbitals of the negatively charged carbon atom.
The inductive effect is due to the presence in the molecule of one or more permanent dipoles in one or more bonds, dipoles which in turn arise from the difference in electronegativity between two groups. This difference leads to a non-uniform distribution of the bonding electrons. The inductive effect can be positive, also known as +I effect, feature of atoms or groups that tend to repel electrons, or negative, also known as –I effect, which is characteristic of atoms or groups that tend to attract electrons. The atoms or groups with the +I effect tend to decrease the stability of the carbanions, whereas those with the –I effect, therefore more electronegative, tend to stabilize them.[1]
The stability of carbanions increases when they are bound to an electrophilic structure where the unshared electron pair can delocalize by resonance, therefore a structure that acts as an electron trap or electron sink. Aromatic structures, such as the phenyl group, are particularly effective.[2]
Finally, the stability is also a function of the s-character of hybrid orbitals of the negatively charged carbon atom, increasing as the percentage s character increases. Therefore it will increase going from sp3 hybridization, which has 25% s character, to sp2, with 33% s character, to sp, with 50% s-character.[1]
R-CH2– < R1R2C=CH– < RC≡C–
Carbanions in enzymatic reactions
Examples of enzymatic reactions that proceed with the formation of carbanions are those catalyzed by three multienzyme complexes belonging to the family of 2-oxoacid dehydrogenases or alpha-ketoacid dehydrogenases, which are involved in the oxidative decarboxylation of ketoacids, in particular of α-ketoacids, briefly described below.
The pyruvate dehydrogenase complex, which catalyzes the oxidative decarboxylation of pyruvate, the conjugate base of pyruvic acid, into acetyl-CoA, thus acting as a bridge between glycolysis and the citric acid cycle;
The oxoglutarate dehydrogenase or alpha-ketoglutarate dehydrogenase complex, which catalyzes the oxidative decarboxylation of α-ketoglutarate to succinyl-CoA in step 4 of the citric acid cycle;
The branched-chain α-ketoacid dehydrogenase complex, which catalyzes the oxidative decarboxylation of the branched amino acids valine, leucine and isoleucine into acetyl-CoA and succinyl-CoA. The remaining carbon skeleton can then enter the citric acid cycle.[3]
The three multienzyme complexes have very similar structures and reaction mechanisms, and their E1 subunits, which are thiamine pyrophosphate dependent enzymes, catalyze a reaction in which a carbanion intermediate is formed, whose formation and stabilization by resonance involves thiamine.[8]
Transketolase (EC 2.2.1.1) also catalyzes a reaction that involves the formation of a carbanion intermediate. This enzyme, which catalyzes steps 6 and 8 of the pentose phosphate pathway, requires thiamine pyrophosphate as a cofactor, and has a reaction mechanism similar to that of the E1 subunits of multienzyme complexes seen previously.[7]
Acetyl-CoA carboxylase (EC 6.4.1.2) is another enzyme that catalyzes a reaction that involves the formation of a carbanion intermediate. The enzyme catalyzes the committed step of de novo synthesis of fatty acids, namely, the carboxylation of acetyl-CoA to malonyl-CoA.[9]
References
^ abcd Soderberg T. Organic chemistry with a biological emphasis. Volume I. Chemistry Publications. 2019.
^ abc Solomons T.W.G., Fryhle C.B., Snyder S.A. Solomons’ organic chemistry. 12th Edition. John Wiley & Sons Incorporated, 2017.
^ ab Heilman D., Woski S., Voet D., Voet J.G., Pratt C.W. Fundamentals of biochemistry: life at the molecular level. 6th Edition. Wiley, 2023.
^ Heterolysis, in IUPAC Compendium of Chemical Terminology, 3rd ed. International Union of Pure and Applied Chemistry; 2006. Online version 3.0.1, 2019. doi:1351/goldbook.H02809.
^ Moran L.A., Horton H.R., Scrimgeour K.G., Perry M.D. Principles of Biochemistry. 5th Edition. Pearson, 2012.
^ Homolysis, in IUPAC Compendium of Chemical Terminology, 3rd ed. International Union of Pure and Applied Chemistry; 2006. Online version 3.0.1, 2019. doi:1351/goldbook.H02851.
^ ab Nelson D.L., Cox M.M. Lehninger. Principles of biochemistry. 8th Edition. W.H. Freeman and Company, 2021.
^ Berg J.M., Tymoczko J.L., Gatto J.G., Stryer L. Biochemistry. 9th Edition. W.H. Freeman and Company, 2019.
Keto acids or ketoacids are organic compounds containing two functional groups: a carboxyl acid group (−COOH) and a carbonyl group (˂C=O).
Based on the position of the carbonyl group relative to the carboxylic acid group, to which IUPAC nomenclature rules assign the highest priority, ketoacids are classified as α-keto acids, β-keto acids, and γ-keto acids.[1]
General Chemical Structure of Keto Acids (α, β e γ)
Keto acids, and in particular α-keto acids, are very important in biochemistry, being involved in many metabolic pathways.[2]
In Summary: Key Points
Definition and structure: keto acids are organic compounds containing both a carboxylic acid group and a carbonyl group within their molecular structure.
IUPAC classification: they are classified into alpha (α), beta (β), and gamma (γ) keto acids based on the position of the carbonyl group relative to the carboxylic acid.
Role of alpha-keto acids: pyruvic acid (the end product of glycolysis), oxaloacetic acid, and α-ketoglutaric acid are vital metabolic intermediates driving the citric acid cycle, gluconeogenesis, and amino acid metabolism.
Significance of beta and gamma: beta-ketoacids (such as acetoacetic acid) are key to ketone body production and gut microbiota pathways, while gamma-keto acids (such as levulinic acid) originate from cellulose catabolism.
α-Keto acids
They have the carbonyl group adjacent to the carboxylic acid. Many of these compounds, in the form of their conjugate bases, have important biological functions. Below are some examples.[2]
Pyruvic acid, the simplest α-keto acid, is the end metabolic product of glycolysis.
Oxaloacetic acid and α-ketoglutaric acid are intermediates of the citric acid cycle.
α-Ketoacids can arise from transamination and oxidative deamination reactions of amino acids. In transamination reactions, the α amino group of the amino acid is transferred to an α-keto acid, usually α-ketoglutarate, with the formation of a new amino acid and a new α-keto acid. These reactions are catalyzed by enzymes called aminotransferases or transaminases (EC 2.6.1.-).
α-Keto acid + Amino acid ⇄ New amino acid + New α-keto acid
In oxidative deaminations, amino acids are converted into the corresponding α-keto acids by removing the amino group, which is converted to ammonia and replaced by a carbonyl group. Since the reaction is reversible, ketoacids are also precursors of amino acids.
Note: ammonia is a toxic compound, and is converted into the safer compound urea via the urea cycle in the liver.[2]
Pyruvate, oxaloacetate and α-ketoglutarate, the latter via oxaloacetate, are the entry points into gluconeogenesis of the carbon skeleton of many glucogenic amino acids.[3]
It has also been observed that, in vitro, murine and human tumor cell lines secrete 2-keto acids into the tumor microenvironment, such as α-ketoisocaproate, α-keto-β-methylvalerate and α-ketoisovalerate, which are capable to influencing the anti-tumor activity of macrophages.[4]
β-Keto acids
They have the carbonyl group at the second carbon from the carboxylic acid.
Examples of β-ketoacids are acetoacetic acid, the simplest one, and β-hydroxybutyric acid, which are two of the three ketone bodies, together with acetone, produced by the hepatocyte when acetyl-CoA is produced in excess of the capacity of citrate synthase (EC 2.3.3.1), namely, of citric acid cycle to oxidize it fully, as during prolonged fasting or diets very low in carbohydrates.
Note that acetoacetyl-CoA and β-hydroxybutyryl-CoA, namely, the activated forms of these β-keto acids, are also intermediates in the butyric acid synthesis pathway which occurs in most butyrate-producing bacteria of the gut microbiota.[5][6][7]
γ-Keto acids
They have the carbonyl group at the third carbon from the carboxylic acid.
An example is levulinic acid, the simplest one, which arises from the catabolism of cellulose.
^ abc Nelson D.L., Cox M.M. Lehninger. Principles of biochemistry. 8th Edition. W.H. Freeman and Company, 2021.
^ D’Andrea G. Classifying amino acids as gluco(glyco)genic, ketogenic, or both. Biochem Educ 2000;28(1):27-28. doi:10.1016/s0307-4412(98)00271-4
^ Cai Z., Li W., Brenner M., Bahiraii S., Heiss E.H., Weckwerth W. Branched-chain ketoacids derived from cancer cells modulate macrophage polarization and metabolic reprogramming. Front Immunol 2022;13:966158. doi:10.3389/fimmu.2022.966158.
^ Miller T.L., Wolin M.J. Pathways of acetate, propionate, and butyrate formation by the human fecal microbial flora. Appl Environ Microbiol 1996;62(5):1589-92. doi:10.1128/aem.62.5.1589-1592
^ Portincasa P., Bonfrate L.,Vacca M., De Angelis M., Farella I., Lanza E., Khalil M.,Wang D.Q.-H., Sperandio M., Di Ciaula A. Gut microbiota and short chain fatty acids: implications in glucose homeostasis. Int J Mol Sci 2022;23:1105. doi:10.3390/ijms23031105
^ Pryde S.E., Duncan S.H., Hold G.L., Stewart C.S., Flint H.J. The microbiology of butyrate formation in the human colon. FEMS Microbiol Lett 2002;217(2):133-9. doi:10.1111/j.1574-6968.2002.tb11467.x
A futile cycle, or substrate cycle, occurs when two non-equilibrium opposing reactions, catalyzed by different enzymes, or two opposite metabolic pathways run simultaneously with no other overall effect than the dissipation of energy.[1]
The term “futile cycle” was coined because apparently these cycles seemed to confer no benefit to the cell, a sort of metabolic imperfection leading to energy expenditure.[2]
However, recently, they have been recognized as important for the generation of heat, the amplification of metabolic signals, the redistribution of the energy, in the form of triglycerides, between adipocytes and hepatocytes, and the modification of fatty acids stored as triglycerides in adipose tissue.
In order to avoid uncontrolled dissipation of energy, futile cycles are strictly regulated.[3][4][5]
Examples of futile cycles are glycolysis and gluconeogenesis when they proceed simultaneously at a high rate in the same cell, the Cori cycle, and the triglyceride/fatty acid cycle.[6]
Summary: Key Points
Definition and nature: a futile (or substrate) cycle occurs when two opposing, irreversible reactions run simultaneously, resulting only in net ATP consumption and energy dissipation.
Control mechanisms: to prevent uncontrolled energy waste, cells tightly and independently regulate the enzymes of opposing pathways using allosteric mechanisms, covalent modifications, or nuclear compartmentalization.
Biological functions: although initially considered metabolic imperfections, they are now recognized as vital for heat generation (thermogenesis), metabolic signal amplification, and fatty acid remodeling.
Primary examples: the most prominent biological models include the coupling of glycolysis and gluconeogenesis (PFK-1/FBPase), the Cori cycle between muscle and liver, and the triglyceride/fatty acid cycle in adipose tissue.
Let us consider the conversion of A into B, which proceeds at a rate of 100, and B into A, which proceeds at a rate of 90. This results in a net flow of 10. Suppose that an effector increases the rate of conversion of A into B by 30 percent, to 130 percent, and reduces the rate of conversion of B into A by 30 percent, to 63 percent. The resulting net flux is equal to 130 − 63 = 67, namely, a 30 percent change in the rates of the opposing reactions has led to a 570 percent increase in the net flux.
A mechanism of this type could, at least in part, explain the even 1000-fold increase in carbon flux down glycolysis in the initial phase of intense exercise.[2]
Regulation
In the course of evolution, the selection of different enzymes to catalyze irreversible and opposing reactions has made it possible to avoid or put under strict control futile cycles. How? The selection of one enzyme that catalyzes the conversion of A into B, and another enzyme that catalyzes the opposing reaction, whose activities are regulated separately, allows the control of the net flux.[7]
Enzymatic activities are controlled by:
allosteric mechanisms;
covalent modifications;
modifications in the concentration of the enzymes, due to variations in the ratio between their synthesis and/or degradation. A different mechanism regulates hepatic glucokinase (EC 2.7.1.2). During fasting, the enzyme is reversibly bound to GKPR, one of the liver-specific proteins, which anchors it inside the nucleus, separating it from the other glycolytic enzymes, and thus preventing the futile cycle between glycolysis and gluconeogenesis.
In this way, it is possible to obtain a coordinated regulation of the two opposing pathways, thus avoiding an uncontrolled futile cycle. Obviously, such a fine regulation could not be achieved if a single enzyme would operate in both directions.[8]
Glycolysis and gluconeogenesis
If glycolysis, which converts glucose into pyruvate, the conjugate base of pyruvic acid, with the production of ATP, and gluconeogenesis, which converts pyruvate into glucose with the consumption of ATP, run simultaneously at a high rate in the same cell, the net result would be a net consumption of ATP, therefore a futile cycle. This is avoided by the control of the irreversible steps of the two metabolic pathways, in particular the reactions catalyzed by phosphofructokinase-1 (PFK-1; EC 2.7.1.11), and by fructose-1,6-bisphosphatase (FBPase; EC 3.1.3.11), mainly by the allosteric effector fructose 2,6-bisphosphate.[7]
Example of a Futile Cycle Between Glycolysis and Gluconeogenesis.
It should be noted that in glycolysis, the control involves all the irreversible reactions, whereas in gluconeogenesis, the key regulatory points are the reactions catalyzed by pyruvate carboxylase (EC 6.4.1.1) and fructose 1,6-bisphosphatase.[8]
Cori Cycle
In the Cori cycle, lactic acid produced from glucose in the muscle and other extrahepatic tissues reaches the liver, where it is converted back into glucose, which, released into the circulation, returns to the muscle and other extrahepatic tissues, thereby closing the cycle. From an energetic point of view, the Cori cycle can be considered a futile cycle because it results in a net consumption of 4 ATP with no other overall effect. However, it allows many different types of extrahepatic cells to work at the expense of the liver.[6]
Triglyceride/fatty acid cycle
In the triglyceride/fatty acid cycle, triglycerides in adipose tissue are partially or completely hydrolyzed to free fatty acids and glycerol, in a process called lipolysis; the released fatty acids are then used to resynthesize new molecules of triglycerides.[3][6][7] Four moles of ATP are consumed for every mole of triglycerides that completes the cycle.
This futile cycle can take place:
between adipose tissue, which releases fatty acids, and the liver, which re-esterifies them to triglycerides, leading to a redistribution of stored energy;[4]
in adipocytes, where it may contribute to thermogenesis and modifications of the stored fatty acids.
Regarding the modifications, the cycle renders fatty acids accessible for re-arrangements such as elongations and desaturations, which allow saturated fatty acids to be converted to unsaturated fatty acids. However, the efficiency of the process seems to depend on the type of fatty acids.[7] For example, the metabolism of the released medium-chain fatty acids is faster than the conversion of palmitic acid, one of the long-chain fatty acids, to palmitoleic acid, oleic acid, and then, in hepatocytes, to arachidonic acid.
Note that the conversion of medium-chain fatty acids and palmitic acid to long-chain unsaturated fatty acids reduces the health risk associated to their accumulation in stored triglycerides.[5]
Generation of heat
In some cases a futile cycle has the only function of producing heat through the hydrolysis of ATP. This occurs, for example, in the flight muscles of bumblebees, which, in order to fly, must maintain a thoracic temperature of about 30 °C, even when the external temperature is 10 °C. The thoracic temperature is maintained at the optimal levels for flight thanks to the futile cycle between the reactions catalyzed by PFK-1 and FBPase. In fact, flight muscle FBPase is not inhibited by AMP, which suggests that, during evolution, this protein has been selected for the generation of heat.
Unlike bumblebees, flight muscles of honeybees contain almost no FBPase, and therefore these insects cannot fly when the external temperature is low.[2]
References
^ Newsholme E.A. Substrate cycles: their metabolic, energetic and thermic consequences in man. Biochem Soc Symp. 1978;43:183–205.
^ abc Berg J.M., Tymoczko J.L., Gatto J.G., Stryer L. Biochemistry. 9th Edition. W.H. Freeman and Company, 2019.
^ ab Reshef L., Olswang Y., Cassuto H., Blum B., Croniger C.M., Kalhan S.C., Tilghman S.M., Hanson R.W. Glyceroneogenesis and the triglyceride/fatty acid cycle. J Biol Chem 2003;278(33):30413-6. doi:10.1074/jbc.R300017200.
^ ab Sharma A.K., Wolfrum C. Lipid cycling isn’t all futile. Nat Metab 2023;5(4):540-541. doi:10.1038/s42255-023-00779-x.
^ ab Wunderling K., Zurkovic J., Zink F., Kuerschner L., Thiele C. Triglyceride cycling enables modification of stored fatty acids. Nat Metab 2023;5(4):699-709. doi:10.1038/s42255-023-00769-z.
^ abc Brownstein A.J., Veliova M., Acin-Perez R., Liesa M., Shirihai O.S. ATP-consuming futile cycles as energy dissipating mechanisms to counteract obesity. Rev Endocr Metab Disord 2022;23(1):121-131. doi:10.1007/s11154-021-09690-w.
^ abc Nelson D.L., Cox M.M. Lehninger. Principles of biochemistry. 8th Edition. W.H. Freeman and Company, 2021.
Short-chain fatty acids (SCFA) are saturated fatty acids with a straight or branched carbon chain made of 2–5 carbon atoms including acetic, propionic, butyric, isobutyric, valeric, isovaleric, and 2-methylbutyric acids.[1]
In humans, they are, along with secondary bile salts, the main metabolites produced by bacteria in the gut microbiota in the cecum and colon, and derive almost entirely from the anaerobic fermentation of non-digestible carbohydrates.[2] The most abundant are acetic, propionic, and butyric acids, which represent 90–95% of the produced SCFA. The remaining percentage consists of branched SCFA.[3]
They are the major anions present in the colon.[4] Their concentration is higher in the cecum and in the proximal colon, where the substrates for their synthesis are more abundant.[5][6][7] They reduce the colonic pH and thus acidify the stool.
About 90–95% of the SCFA are absorbed in the cecum and colon, whereas 5–10% are excreted with the feces, and are thought to provide about 70% of the energy needs of colonocytes.[8][9]
Short-chain fatty acids modulate the physiology and composition of the gut microbiota. Furthermore, a growing body of research suggests that they play an important role in maintaining human health.[4]
Summary: Key Points
Microbiota origin: short-chain fatty acids derive almost entirely from the anaerobic fermentation of dietary fibers and resistant starches by gut bacteria.
The three pillars: acetic, propionic, and butyric acids are the most abundant metabolites, representing 90–95% of total SCFA in the cecum and colon.
Cellular fuel: butyric acid holds paramount biological importance, providing roughly 70% of the energy needs required by colonocytes.
Regulation and health: they modulate host physiology by inhibiting histone deacetylases and binding to GPR membrane receptors, regulating glucose homeostasis and the gut-brain axis.
Like medium-chain fatty acids and long-chain fatty acids, short-chain fatty acids are present in animal and plant tissues mostly in the form of triglycerides, although in much lower amounts than their long-chain counterparts.[10]
In adults, the main food source is milk and dairy products, where butyric acid is the SCFA present with the highest concentration. Other sources are some vegetable oils, such as palm kernel oil and coconut oil.
In breastfed infants, the main source is breast milk.[11]
However, for humans, and most mammals, the most important source is the anaerobic fermentation of fibers and resistant starch, namely, indigestible carbohydrates, by the bacteria of the gut microbiota.[12] Approximately 500–600 mM of SCFA are produced through this pathway per day. Acetic, propionic, and butyric acids are present in a molar ratio of about 60:20:20, respectively, although the relative proportion of each depends on the microbiota composition, the substrate, and the intestinal transit time.[2][4]
Properties
Short-chain fatty acids have carbon chains made of 2–5 carbon atoms, a characteristic that strongly affects their physical properties.
Acetic, propionic, butyric, and valeric acids are straight-chain fatty acids, whereas isobutyric, isovaleric, and 2-methylbutyric acid are branched-chain fatty acids.[13]
Physicochemical Properties of the Seven Short-Chain Fatty Acids
They are small molecules, and are the smallest among all lipids.
They are liquid at room temperature, and are soluble in polar solvents such as water. Unlike straight-chain saturated fatty acids with longer carbon chains, whose solubility decreases as the chain lengthens, SCFA remain soluble because their hydrophobic carbon chain is short, while the carboxyl group remains highly polar.[11]
Finally, butyric acid and isobutyric acid, which have the molecular formula C4H8O2, are an example of chain isomerism; the same applies to are valeric, isovaleric, and 2-methylbutyric acids, which share the molecular formula C5H10O2.
Health effects
Short-chain fatty acids appear to play a crucial role in maintaining human health.[7] Their activity seems to occur through direct and/or indirect effects on cellular processes such as proliferation, differentiation, and gene expression, thus contributing to the regulation of processes such as glucose homeostasis, intestinal and immune function, and the regulation of the gut-brain axis.[14]
Their health effects seem to be confirmed by studies showing that intestinal dysbiosis appears to be implicated in metabolic pathologies, such as disorders involving glucose homeostasis, and behavioral and neurological pathologies, such as depression, and Alzheimer’s and Parkinson’s.[15]
Synthesis
In humans, the enzyme equipment carrying out carbohydrate digestion lacks the enzymes capable of digesting fiber and resistant starch, the latter being so-called precisely because it resists the action of alpha-amylase.
On the contrary, the bacteria of the gut microbiota encode a large number of different glycoside hydrolases, more than 260, which also hydrolyze fibers and resistant starch, releasing the constituent monosaccharides.[16]
Hexoses and deoxyhexoses enter glycolysis, and pentoses enter the pentose phosphate pathway, to give pyruvate, which is the main precursor for the synthesis of short-chain fatty acids.[17][18][19]
The synthesis of SCFA is affected by several factors; below are some examples.
The fiber content of the diet. For example, a diet rich in fibers, such as the Mediterranean diet, may influence their synthesis.[2]
The pH of the intestinal lumen, as the bacteria that produce butyric acid dominate at a pH value around 5.5, while the bacteria that produce acetic and propionic acids dominate at a pH value around 6.5.[21]
Acetic acid and propionic acid are mainly produced by species of the phylum Bacteroidetes, while butyric acid, for whose synthesis resistant starch is particularly important, by species of the phylum Firmicutes.[23][24]
Synthesis of acetic acid
Acetic acid, the most abundant SCFA in the colon, can be synthesized via the Wood-Ljungdahl pathway in the reductive direction, through the reduction of CO2 to acetate, or from acetyl-CoA, which is the most important metabolic pathway, responsible for the production of about two thirds of the butyric acid present in the intestinal lumen.[25]
Synthesis of propionic acid
Propionic acid can be synthesized through three different metabolic pathways: the acrylate and succinate pathways, which use lactic acid produced by other bacteria, and the propanediol pathway, in which the precursors are deoxyhexoses.[6]
The acrylate pathway converts lactic acid to propionyl-CoA, via lactoyl-CoA. In the final step, propionyl-CoA is hydrolyzed to propionic acid.[26]
In the succinate pathway, lactate is reduced to pyruvate, which is carboxylated to oxaloacetate, which, through a pathway that has malate, fumarate, succinate, and methylmalonyl-CoA as intermediates, is converted to propionyl-CoA, which in turn is hydrolyzed to propionic acid. The succinate pathway is thought to be the dominant pathway for propionic acid synthesis in the gut.[27]
In the propanediol pathway, some deoxyhexoses, such as fucose and rhamnose, are converted via 1,2-propanediol to propionyl-CoA and then propionic acid.[28]
Synthesis of butyric acid
The synthesis of butyric acid can follow two routes.[4][11]
In most butyric acid-producing bacteria, the short-chain fatty acid is synthesized through a pathway that begins with the condensation of two acetyl-CoA molecules to acetoacetyl-CoA, which, through a pathway that has β-hydroxybutyryl-CoA and crotonyl-CoA as intermediates, is converted to butyryl-CoA. The final step is the release of butyric acid from butyryl-CoA.[29]
In a small number of bacterial species, butyryl-CoA is converted to butyryl phosphate, from which butyric acid is released.[6]
Synthesis from amino acids
Acetic acid, propionic acid, and butyric acid can also be produced from amino acids obtained from peptide and protein degradation, although the amount produced by these pathways is small.[24]
These syntheses occur in the distal part of the colon, often by non-commensal bacteria, as in the case of glutamate and lysine fermentation.[27] Different short-chain fatty acids are produced by the metabolism of different amino acids; below are some examples.[30]
Glutamic acid mainly produces acetic acid and butyric acid.
Aspartic acid mainly produces acetic acid and propionic acid.
The basic amino acids lysine, arginine, and histidine produce acetic acid and butyric acid.
Cysteine produces acetic, propionic, and butyric acids.
Methionine mainly produces propionic acid and butyric acid.
Branched-chain fatty acids derive from the branched-chain amino acids leucine, isoleucine, and valine.
The pH of the intestinal lumen influences the metabolism of proteins by the gut microbiota; for example, their breakdown into amino acids is more likely at neutral or weakly alkaline pH.[31]
It should be noted that potentially toxic compounds, such as ammonia, sulfites and phenols, are also produced from the intestinal metabolism of amino acids.[30]
Endogenous synthesis
Mammals, and therefore humans, have the enzymatic equipment for the endogenous synthesis of short-chain fatty acids. The synthesis occurs mainly in the liver, by β-oxidation cycles which lead to the formation of acyl-CoA with a shorter carbon chain than the starting fatty acid. The acyl-CoA is then hydrolyzed to fatty acid and CoA by an acyl-CoA thioesterase (EC 3.1.2.20).[11][32]
Membrane receptors
Short-chain fatty acids can bind to specific receptors on the plasma membrane, namely G protein-coupled receptors, including GPR41, GPR43, and GPR109A.[33]
The effects produced by the binding of SCFA on the receptors depend on the cell type. For example, binding to receptors on intestinal L cells is associated with the release of glucagon-like peptide-1 (GLP-1), and peptide YY, hormones that affect appetite and food intake.[4] Binding to enterochromaffin cells induces the release of serotonin, which may affect intestinal motility.[34] Finally, binding to receptors on pancreatic beta-cells increases insulin release.[35]
The different short-chain fatty acids have different abilities to activate the receptors: GPR43 is more likely to be activated by acetic and propionic acids, GPR41 by propionic and butyric acids, while GPR109A is activated by butyric acid.[36]
Absorption
About 90% of the short-chain fatty acids present in the intestinal lumen are absorbed by colonocytes.[37] The passage across the plasma membrane can occur by passive diffusion or by active transport mediated by two types of membrane transporters: the H+-dependent and Na+-dependent monocarboxylate transporters, or MCTs and SMCTs, respectively.[38]
Passive transport affects protonated forms of SCFA, so it is influenced by the colonic pH value. A weak acidification of the intestinal lumen, which can be due to the metabolic activity of the microorganisms, increases the prevalence of the protonated form and therefore enhances passive transport.[11]
Role in colonocytes
In colonocytes, short-chain fatty acids have both energy and regulatory functions.[33]
When used for energy purposes, acetic acid and butyric acid are converted to acetyl-CoA, and propionic acid to propionyl-CoA. Through the production of ATP, SCFA contribute to the maintenance of cellular homeostasis, but also, for example, to the maintenance of the integrity of the tight junctions at the cell apex, and therefore of the integrity of the intestinal barrier.[39] Of the three major short-chain fatty acids produced by the gut microbiota, butyric acid is the major source of energy for colonocytes, while acetic and propionic acids are poorly metabolized and mostly drained by the portal vein.[27][40]
Considering the regulatory role, SCFA are, for example, capable of inhibiting histone deacetylases (EC 3.5.1.98), enzymes that catalyze the removal of acetyl groups from lysine residues of histone proteins, acetyl groups previously inserted by histone acetyltransferase (EC 2.3.1.48).[41] The R groups of deacetylated lysines have positive charges, which allows histone proteins to wrap the DNA more tightly, making the nucleosome more compact and thereby hindering transcription and gene expression. The different short-chain fatty acids have different abilities to inhibit histone deacetylases:
This mode of action on histone deacetylases has been observed not only in the gut and associated immune tissue, but also in the central and peripheral nervous systems.[42]
Transport
Short-chain fatty acids that have not been utilized by colonocytes leave the cell by passive diffusion and active transport across the basolateral membrane, and enter the portal circulation where acetic acid reaches the highest concentration, about 260 mM/L, while propionic and butyric acids reach concentrations of about 30 mM/L.[4]
In the rectum, a small amount of these lipids can pass directly into the systemic circulation, thus bypassing the liver, via the internal iliac vein.[40]
Unlike long-chain fatty acids, short- and medium-chain fatty acids are present in the circulation in free form, namely, as non-esterified fatty acids, and, bound to albumin, reach the liver. Subsequent cell uptake and intracellular transport do not require fatty acid transport proteins, plasma membrane fatty acid translocases, or cytosolic fatty acid binding proteins. Therefore, their oxidation may be much faster than that of long-chain fatty acids and the longest members of medium-chain fatty acids, namely, fatty acid with carbon chains longer than 8 carbon atoms.[11]
Hepatic and extrahepatic metabolism
The liver is an important site for short-chain fatty acid metabolism.[37]
It can absorb about 40% of the acetic acid and 80% of the propionic acid from the portal vein.[43] Propionic acid is mostly metabolized in the liver, where it can also be used as a substrate for gluconeogenesis.[44]
A small amount of the gut-derived SCFA, about 36% for acetic acid, 9% for propionic acid, and only 2% for butyric acid, reach, through the systemic circulation, the peripheral tissues. In muscle, acetic acid can be used for lipid synthesis or be oxidized for energy production. Furthermore, it is thought that SCFA concentrations in the systemic circulation, even if small, are capable of influencing the metabolism and physiology of peripheral cells and tissues.[4][12]
References
^ Cummings J.H. Short chain fatty acids in the human colon. Gut 1981;22(9):763-79. doi:10.1136/gut.22.9.763
^ abc Silva Y.P., Bernardi A., Frozza R.L. The role of short-chain fatty acids from gut microbiota in gut-brain communication. Front Endocrinol (Lausanne) 2020;11:25. doi:10.3389/fendo.2020.00025
^ abcdefg Portincasa P., Bonfrate L., Vacca M., De Angelis M., Farella I., Lanza E., Khalil M., Wang D.Q.-H., Sperandio M., Di Ciaula A. Gut microbiota and short chain fatty acids: implications in glucose homeostasis. Int J Mol Sci 2022;23:1105. doi:10.3390/ijms23031105
^ Abdul Rahim M.B.H., Chilloux J., Martinez-Gili L., Neves A.L., Myridakis A., Gooderham N., Dumas M.-E. Diet-induced metabolic changes of the human gut microbiome: importance of short-chain fatty acids, methylamines and indoles. Acta Diabetol 2019;56:493-500. doi:10.1007/s00592-019-01312-x
^ abcd Deleu S., Machiels K., Raes J., Verbeke K., Vermeire S. Short chain fatty acids and its producing organisms: an overlooked therapy for IBD? EBioMedicine 2021;66:103293. doi:10.1016/j.ebiom.2021.103293
^ abc Liu X.F., Shao J.H., Liao Y.T., Wang L.N., Jia Y., Dong P.J., Liu Z.Z., He D.D., Li C., Zhang X. Regulation of short-chain fatty acids in the immune system. Front Immunol 2023;14:1186892. doi:10.3389/fimmu.2023.1186892
^ McLoughlin R.F., Berthon B.S., Jensen M.E., Baines K.J., Wood L.G. Short-chain fatty acids, prebiotics, synbiotics, and systemic inflammation: a systematic review and meta-analysis. Am J Clin Nutr 2017;106(3):930-945. doi:10.3945/ajcn.117.156265
^ Brahe L.K., Astrup A., Larsen L.H. Is butyrate the link between diet, intestinal microbiota and obesity-related metabolic diseases? Obes Rev 2013;14(12):950-9. doi:10.1111/obr.12068
^ Marten B., Pfeuffer M., Schrezenmeir J. Medium-chain triglycerides. Int Dairy J 2006;16:11, Pages 1374-1382. doi:10.1016/j.idairyj.2006.06.015
^ abcdef Schönfeld P., Wojtczak L. Short- and medium-chain fatty acids in energy metabolism: the cellular perspective. J Lipid Res 2016;57(6):943-54. doi:10.1194/jlr.R067629
^ ab Cummings J.H., Pomare E.W., Branch W.J., Naylor C.P., Macfarlane G.T. Short chain fatty acids in human large intestine, portal, hepatic and venous blood. Gut 1987;28(10):1221-7. doi:10.1136/gut.28.10.1221
^ Dalile B., Van Oudenhove L., Vervliet B., Verbeke K. The role of short-chain fatty acids in microbiota-gut-brain communication. Nat Rev Gastroenterol Hepatol 2019;16(8):461-478. doi:10.1038/s41575-019-0157-3
^ Borre Y.E., O’Keeffe G.W., Clarke G., Stanton C., Dinan T.G., Cryan J.F. Microbiota and neurodevelopmental windows: implications for brain disorders. Trends Mol Med 2014;20(9):509-18. doi:10.1016/j.molmed.2014.05.002
^ Usuda H., Okamoto T., Wada K. Leaky gut: effect of dietary fiber and fats on microbiome and intestinal barrier. Int J Mol Sci 2021;22(14):7613. doi:10.3390/ijms22147613
^ Hugenholtz F., Mullaney J. A., Kleerebezem M., Smidt H., Rosendale D. I. Modulation of the microbial fermentation in the gut by fermentable carbohydrates. Bioact Carbohydr Diet Fibre 2013;2(2)-133-142. doi:10.1016/j.bcdf.2013.09.008
^ Krautkramer K.A., Fan J., Bäckhed F. Gut microbial metabolites as multi-kingdom intermediates. Nat Rev Microbiol 2021;19(2):77-94. doi:10.1038/s41579-020-0438-4
^ Miller T.L., Wolin M.J. Pathways of acetate, propionate, and butyrate formation by the human fecal microbial flora. Appl Environ Microbiol 1996;62(5):1589-92. doi:10.1128/aem.62.5.1589-1592
^ Bergman E.N. Energy contributions of volatile fatty acids from the gastrointestinal tract in various species. Physiol Rev 1990;70(2):567-90. doi: 10.1152/physrev.1990.70.2.567
^ Topping D.L., Clifton P.M. Short-chain fatty acids and human colonic function: roles of resistant starch and nonstarch polysaccharides. Physiol Rev 2001;81(3):1031-64. doi:10.1152/physrev.2001.81.3.1031
^ Louis P., Flint H.J. Diversity, metabolism and microbial ecology of butyrate-producing bacteria from the human large intestine. FEMS Microbiol Lett 2009;294(1):1-8. doi: 10.1111/j.1574-6968.2009.01514.x
^ ab Louis P., Flint H.J. Formation of propionate and butyrate by the human colonic microbiota. Environ Microbiol 2017;19(1):29-41. doi:10.1111/1462-2920.13589
^ Ragsdale S.W., Pierce E. Acetogenesis and the Wood-Ljungdahl pathway of CO2, fixation. Biochim Biophys Acta 2008;1784(12):1873-98. doi:10.1016/j.bbapap.2008.08.012
^ Hetzel M., Brock M., Selmer T., Pierik A.J., Golding B.T., Buckel W. Acryloyl-CoA reductase from Clostridium propionicum. An enzyme complex of propionyl-CoA dehydrogenase and electron-transferring flavoprotein. Eur J Biochem 2003;270(5):902-10. doi:10.1046/j.1432-1033.2003.03450.x
^ abc Koh A., De Vadder F., Kovatcheva-Datchary P., Bäckhed F. From dietary fiber to host physiology: short-chain fatty acids as key bacterial metabolites. Cell 2016;165(6):1332-1345. doi:10.1016/j.cell.2016.05.041
^ Scott K.P., Martin J.C., Campbell G., Mayer C.D., Flint H.J. Whole-genome transcription profiling reveals genes up-regulated by growth on fucose in the human gut bacterium Roseburia inulinivorans. J Bacteriol 2006;188(12):4340-9. doi:10.1128/JB.00137-06
^ Pryde S.E., Duncan S.H., Hold G.L., Stewart C.S., Flint H.J. The microbiology of butyrate formation in the human colon. FEMS Microbiol Lett 2002;217(2):133-9. doi:10.1111/j.1574-6968.2002.tb11467.x
^ ab Smith E.A., Macfarlane G.T. Dissimilatory amino acid metabolism in human colonic bacteria. Anaerobe 1997;3(5):327-37. doi:
^ Windey K., De Preter V., Verbeke K. Relevance of protein fermentation to gut health. Mol Nutr Food Res 2012;56(1):184-96. doi:10.1002/mnfr.201100542
^ ab Parada Venegas D., De la Fuente M.K., Landskron G., González M.J., Quera R., Dijkstra G., Harmsen H.J.M., Faber K.N., Hermoso M.A. Short chain fatty acids (SCFAs)-mediated gut epithelial and immune regulation and its relevance for inflammatory bowel diseases. Front Immunol 2019;10:1486. doi:10.3389/fimmu.2019.00277
^ Fukumoto S., Tatewaki M., Yamada T., Fujimiya M., Mantyh C., Voss M., Eubanks S., Harris M., Pappas T.N., Takahashi T. Short-chain fatty acids stimulate colonic transit via intraluminal 5-HT release in rats. Am J Physiol Regul Integr Comp Physiol 2003;284(5):R1269-76. doi:10.1152/ajpregu.00442.2002
^ Puddu A., Sanguineti R., Montecucco F., Viviani G.L. Evidence for the gut microbiota short-chain fatty acids as key pathophysiological molecules improving diabetes. Mediators Inflamm 2014;2014:162021. doi:10.1155/2014/162021
^ Brown A.J., Goldsworthy S.M., Barnes A.A., Eilert M.M., Tcheang L., Daniels D., Muir A.I., Wigglesworth M.J., Kinghorn I., Fraser N.J., Pike N.B., Strum J.C., Steplewski K.M., Murdock P.R., Holder J.C., Marshall F.H., Szekeres P.G., Wilson S., Ignar D.M., Foord S.M., Wise A., Dowell S.J. The Orphan G protein-coupled receptors GPR41 and GPR43 are activated by propionate and other short chain carboxylic acids. J Biol Chem 2003;278(13):11312-9. doi:10.1074/jbc.M211609200
^ ab Xiong R.G., Zhou D.D., Wu S.X., Huang S.Y., Saimaiti A., Yang Z.J., Shang A., Zhao C.N., Gan R.Y., Li H.B. Health benefits and side effects of short-chain fatty acids. Foods 2022;11(18):2863. doi:10.3390/foods11182863
^ Kim C.H., Park J., Kim M. Gut microbiota-derived short-chain Fatty acids, T cells, and inflammation. Immune Netw 2014;14(6):277-88. doi:10.4110/in.2014.14.6.277
^ Chambers E.S., Preston T., Frost G., Morrison D.J. Role of gut microbiota-generated short-chain fatty acids in metabolic and cardiovascular health. Curr Nutr Rep 2018;7(4):198-206. doi:10.1007/s13668-018-0248-8
^ ab van der Beek C.M., Dejong C.H.C., Troost F.J., Masclee A.A.M., Lenaerts K. Role of short-chain fatty acids in colonic inflammation, carcinogenesis, and mucosal protection and healing. Nutr Rev 2017;75(4):286-305. doi:10.1093/nutrit/nuw067
^ Marchix J., Goddard G., Helmrath M.A. Host-gut microbiota crosstalk in intestinal adaptation. Cell Mol Gastroenterol Hepatol 2018;6(2):149-162. doi:10.1016/j.jcmgh.2018.01.024
^ Stilling R.M., van de Wouw M., Clarke G., Stanton C., Dinan T.G., Cryan J.F. The neuropharmacology of butyrate: the bread and butter of the microbiota-gut-brain axis? Neurochem Int 2016;99:110-132. doi:10.1016/j.neuint.2016.06.011
^ Chambers E.S. Gut-derived short-chain fatty acids: a friend or foe for hepatic lipid metabolism? Nutr Bull 2019;44:154-159. doi:10.1111/nbu.12377
^ Leung C., Rivera L., Furness J.B., Angus P.W. The role of the gut microbiota in NAFLD. Nat Rev Gastroenterol Hepatol 2016;13(7):412-25. doi:10.1038/nrgastro.2016.85
Starch phosphorylase, also known as α-glucan phosphorylase (EC 2.4.1.1), is a multimeric protein possessing both enzymatic and regulatory activities.
It plays an important role in carbohydrate metabolism in both prokaryotes and eukaryotes.[1]
Reversible Regulation of Starch Phosphorylase
The enzyme catalyzes the transfer of a glucosyl unit from glucose 1-phosphate to the non-reducing end of a nascent α-(1→4)-glucan, forming an α-(1→4) glycosidic linkage.[2] This reaction is reversible, and its direction depends on the phosphate/glucose 1-phosphate ratio present in vivo.[3]
The enzyme belongs to the family of glucosyltransferases (EC 2.4). This family also includes starch synthase (EC 2.4.1.21), which is involved in the synthesis of amylose and amylopectin, the polysaccharides that compose starch granules, glycogen phosphorylase (EC 2.4.1.1), involved in glycogenolysis, and glycogen synthase (EC 2.4.1.11), which participates in glycogen synthesis.[1]
It is important to note that while starch synthase uses ADP-glucose as the glucosyl donor and glycogen synthase uses UDP-glucose, starch phosphorylase utilizes glucose 1-phosphate.[4]
Additionally, starch phosphorylase appears to be involved in both the synthesis and degradation of amylose and amylopectin.[2]
In industrial applications, the phosphorolytic action of starch phosphorylase is employed in the production of glucose 1-phosphate and carbohydrates such as glucans and modified starches.[5]
Summary: Key Points
Dual-function enzyme: starch phosphorylase (EC 2.4.1.1) is a multimeric protein involved in both the synthesis and reversible degradation of starch granules.
Specific substrate: unlike starch and glycogen synthases, which rely on NDP-sugars, this enzyme utilizes glucose 1-phosphate to elongate the nascent glucan chain.
In vivo regulation: the direction of the reaction is fully reversible, depending dynamically on the intracellular phosphate to glucose 1-phosphate ratio.
Isoform division: plants possess two distinct isoforms: Pho1 (located in the plastid stroma, serving an early synthetic and regulatory role) and Pho2 (located in the cytosol, directly mobilizing branched glucans).
At least two isoforms of starch phosphorylase are present in plants: one located in the stroma of plastids, named Pho1, and another with cytosolic localization, known as Pho2. Both isoforms play a critical role in the synthesis and degradation of starch.[6]
Starch degradation
Although α-amylase (EC 3.2.1.1) is the first enzyme to act in the polysaccharide degradation during the early stages of germination, and β-amylase (EC 3.2.1.2) initiates transient starch degradation in chloroplasts, other enzymatic activities are also involved. These include α-glucan water dikinase (EC 2.7.9.4), phospho-glucan water dikinase (EC 2.7.9.5), and debranching enzymes.[7]
Of the two isoenzymes of starch phosphorylase, Pho1 appears to have an indirect or regulatory role, influencing the activity of the other enzymes involved in starch degradation.[6] In contrast, Pho2 is capable of directly degrading starch granules and other branched glucans.[8]
Starch synthesis
During starch biosynthesis, starch phosphorylase, particularly Pho1, appears to play both enzymatic and regulatory roles.
Pho1 seems to be involved in the early stages of starch synthesis, contributing to the elongation of the nascent glucan chain.[4]
Starch synthesis involves at least five classes of enzymes: ADP-glucose pyrophosphorylase (EC 2.7.7.27), starch synthases, starch branching enzymes (EC 2.4.1.18), starch debranching enzymes (EC 3.2.1.41), and starch phosphorylases.[9] In addition to these, non-catalytic proteins are also essential for the correct assembly of the starch granule.[10]
In the endosperm of cereals, the formation of multienzyme complexes between starch synthases and branching enzymes depends not only on specific phosphorylation events but also on the presence of Pho1.[11]
Starch phosphorylase is capable of forming a complex with disproportionating enzyme (EC 2.4.1.25).[11] This complex appears to synthesize short malto-oligosaccharides (MOS), which are α-(1→4)-glucans with a degree of polymerization between 2 and 7.[12][13]
MOS serve as primers for starch synthase IV and granule-bound starch synthase in the initial steps of amylopectin and amylose synthesis, respectively, a role analogous to that of glycogenin in glycogen biosynthesis.[14]
MOS can also originate from the activity of starch debranching enzymes during the trimming of amylopectin molecules.[13]
Glucosyltransferase profiles in glycogen and starch metabolism
Enzyme
EC number
Glucosyl donor
Metabolic pathway
Starch phosphorylase
EC 2.4.1.1
Glucose 1-phosphate
Starch synthesis / degradation
Starch synthase
EC 2.4.1.21
ADP-glucose
Starch synthesis (Amylose / Amylopectin)
Glycogen phosphorylase
EC 2.4.1.1
Glucose 1-phosphate
Glycogenolysis
Glycogen synthase
EC 2.4.1.11
UDP-glucose
Glycogen synthesis
Functional and localization profiles of plant starch phosphorylase isoforms
Isoform
Cellular localization
Primary biological role
Pho1
Stroma of plastids
Regulatory role; elongation of nascent glucan chain in early starch synthesis
Pho2
Cytosolic localization
Direct degradation of starch granules and branched glucans
References
^ ab Rathore R.S., Garg N., Garg S., Kumar A. Starch phosphorylase: role in starch metabolism and biotechnological applications. Crit Rev Biotechnol 2009;29(3):214-24. doi:10.1080/07388550902926063
^ ab Tickle P., Burrell M.M., Coates S.A., Emes M.J., Tetlow I.J., Bowsher C.G. Characterization of plastidial starch phosphorylase in Triticum aestivum L. endosperm. J Plant Physiol 2009;166(14):1465-78. doi:10.1016/j.jplph.2009.05.004
^ Newgard C.B., Hwang P.K., Fletterick R.J. The family of glycogen phosphorylases: structure and function. Crit Rev Biochem Mol Biol 1989;24(1):69-99. doi:10.3109/10409238909082552
^ ab Cuesta-Seijo J.A., Ruzanski C., Krucewicz K., Meier S., Hägglund P., Svensson B., Palcic M.M. Functional and structural characterization of plastidic starch phosphorylase during barley endosperm development. PLoS One 2017;12(4):e0175488. doi:10.1371/journal.pone
^ Kadokawa J.I. α-Glucan phosphorylase-catalyzed enzymatic reactions using analog substrates to synthesize non-natural oligo- and polysaccharides. Catalysts 2018;8(10):473. doi:10.3390/catal8100473
^ ab Yu G., Shoaib N., Xie Y., Liu L., Mughal N., Li Y., Huang H., Zhang N., Zhang J., Liu Y., Hu Y., Liu H., Huang Y. Comparative study of starch phosphorylase genes and encoded proteins in various Monocots and Dicots with emphasis on maize. Int J Mol Sci 2022;23:4518. doi:10.3390/ijms23094518
^ Steup M., Robenek H., Melkonian M. In-vitro degradation of starch granules isolated from spinach chloroplasts. Planta 1983;158(5):428-36. doi:10.1007/BF00397736
^ Crofts N., Nakamura Y., Fujita N. Critical and speculative review of the roles of multi-protein complexes in starch biosynthesis in cereals. Plant Sci 2017;262:1-8. doi:10.1016/j.plantsci.2017.05.007
^ Seung D., Soyk S., Coiro M., Maier B.A., Eicke S., Zeeman S.C. PROTEIN TARGETING TO STARCH is required for localising GRANULE-BOUND STARCH SYNTHASE to starch granules and for normal amylose synthesis in Arabidopsis. PLOS Biol 2015;13(2):e1002080. doi:10.1371/journal.pbio.1002080
^ ab Crofts N., Abe N., Oitome N.F., Matsushima R., Hayashi M., Tetlow I.J., Emes M.J., Nakamura Y., Fujita N. Amylopectin biosynthetic enzymes from developing rice seed form enzymatically active protein complexes. J Exp Bot 2015;66(15):4469-82. doi:10.1093/jxb/erv212
^ Hwang S.K., Koper K., Satoh H., Okita T.W. Rice endosperm starch phosphorylase (Pho1) assembles with disproportionating enzyme (Dpe1) to form a protein complex that enhances synthesis of malto-oligosaccharides. J Biol Chem 2016;291(38):19994-20007. doi:10.1074/jbc.M116.735449
^ ab Tetlow I.J., Bertoft E. A review of starch biosynthesis in relation to the building block-backbone model. Int J Mol Sci 2020;21(19):7011. doi:10.3390/ijms21197011
^ Pfister B., Zeeman S.C., Rugen M.D., Field R.A., Ebenhöh O., Raguin A. Theoretical and experimental approaches to understand the biosynthesis of starch granules in a physiological context. Photosynth Res 2020;145:55-70. doi:10.1007/s11120-019-00704-y
Amylopectin is a highly branched polysaccharide composed of α-D-glucose units. Together with amylose, it is one of the two main constituents of starch granules, the primary form of energy storage in plants and the most widespread and abundant form of carbohydrate reserve on Earth.[1]
Glucose monomers are connected by α-(1→4) glycosidic bonds to form linear chains, while branches are introduced through α-(1→6) glycosidic bonds.[2]
Its biosynthesis requires the coordinated activity of at least four distinct classes of enzymes: starch synthases (EC 2.4.1.21), starch branching enzymes (EC 2.4.1.18), starch debranching enzymes, and starch phosphorylase (EC 2.4.1.1).[3]
Within starch granules, amylopectin is more abundant than amylose and forms a semi-crystalline matrix in which amylose appears to be embedded.
The amylose/amylopectin ratio significantly affects the physicochemical properties of starch, thereby influencing both its industrial applications, such as the production of food additives, and its potential health effects.[4][5]
Summary: Key Points
Starch matrix: amylopectin is a giant, highly branched polysaccharide that forms the primary semi-crystalline framework of plant starch granules.
Chemical linkages: linear glucose chains are connected by α-(1→4) glycosidic bonds, while the characteristic branch points are introduced via α-(1→6) bonds.
Cluster architecture: chains are classified into outer (A), inner (B), and reducing-end (C) types, assembling into dense crystalline polymorphs (A-type in cereals) or open hydrated structures (B-type in tubers).
Coordinated biosynthesis: its synthesis relies on the strict cooperation of starch synthases (SSI–SSV), starch branching enzymes (SBEs), debranching enzymes, and starch phosphorylase.
Amylopectin is a highly branched polysaccharide with a molecular weight on the order of 107-108 Daltons, making it much larger than amylose. It is composed of 104-105 glucose residues linked by α-(1→4) glycosidic bonds to form numerous relatively short chains, with a degree of polymerization ranging from 18 to 25 units.[6] The chain length varies depending on the source of starch as well as the environmental and nutritional conditions during plant growth and seed development.[2]
The chains are interconnected by α-(1→6) glycosidic bonds, giving rise to a tree-like architecture in which neighboring chains assemble into a cluster-like structure.[7]
Amylopectin Structural Architecture
In most starches, α-(1→6) linkages account for about 5% of the total glycosidic bonds, a lower proportion than in glycogen (≈9%), where the branches are more evenly distributed. The length and distribution of branches strongly influence the physicochemical properties of amylopectin, including solubility, viscosity, retrogradation behavior, and the gelatinization and pasting temperatures. For example, glycogen is water-soluble, whereas amylopectin and starch are not.[5]
Amylopectin chains
Amylopectin chains can be classified either by their length or by the presence or absence of branching.
Length-based classification
Two main types of chains are distinguished: short and long. Short chains have a degree of polymerization (DP) ranging from 6 to 36 glucosyl units, although the upper limit depends on the amylopectin source. Long chains are defined as those with a DP ≥ 36. In most starches, the molar ratio of long to short chains is approximately 19:6, and is generally higher in A-type crystalline starches (e.g., cereal endosperm starches) than in B-type crystalline starches (e.g., potato starch).[6]
Branching-based classification
According to their connections to other chains, amylopectin chains are divided into three categories: A-chains, B-chains, and C-chains.[8]
A-chains are unbranched, short chains with an average DP of about 13; they represent the outer chains of the molecule.
B-chains contain at least one branch (either an A- or another B-chain), are longer than A-chains, and are located in the inner regions of the molecule. They are further subclassified into B1-chains (DP ≈ 22), B2-chains (DP ≈ 42), B3-chains (DP ≈ 69), B4-chains, and so forth.
The C-chain is a special type of B-chain that carries the sole reducing end of the amylopectin molecule.
A-chains and B1-chains participate in the formation of clusters, while B2-, B3-, and B4-chains are thought to span two, three, and four clusters, respectively.[8][9]
Classification and structural characteristics of amylopectin chains
Classification criteria
Chain type
Degree of polymerization (DP)
Structural position and function
Length-based
Short chains
6 to 36 glucosyl units
Predominant in A-type crystalline starches (e.g., cereal endosperm)
Long chains
≥ 36 glucosyl units
More frequent in B-type crystalline starches (e.g., potato starch)
Branching-based
A-chains
Average DP ≈ 13
Unbranched outer chains; participate in cluster formation
B-chains
DP varies (B1 ≈ 22, B2 ≈ 42, B3 ≈ 69)
Branched inner chains; span across one or multiple clusters
C-chain
Variable (Special B-chain)
Carries the sole reducing end of the entire amylopectin molecule
A-type, B-type and C-type polymorphs
Within the clusters, neighboring linear chain segments form double helices that run parallel to each other, with a periodicity of 2.1 nm, where each turn comprises six glucose residues per chain.[10] These double helices assemble into two distinct crystalline structures: the A-type polymorph, which is denser and typical of cereal grains, and the B-type polymorph, which has a more open hexagonal structure, is less dense and more hydrated, and is characteristic of tuber and high-amylose starches. The C-type polymorph represents a mixture of A- and B-type structures and is found in the starches of roots, legumes, and certain fruits.
This organization underlies the semi-crystalline nature of starch granules.[2]
Physicochemical properties of starch crystalline polymorphs
Polymorph
Structure and density
Hydration level
Typical botanical sources
A-type
Dense, parallel double helices
Low hydration
Cereal grains (e.g., cereal endosperm starches)
B-type
Open hexagonal structure, less dense
Highly hydrated
Tubers (e.g., potato starch) and high-amylose starches
C-type
Mixture of A-type and B-type structures
Variable / Intermediate
Roots, legumes, and certain fruits
Growth rings
Although starch granules vary in shape, their internal architecture is remarkably conserved across species. When observed under a microscope, most starches display a regular pattern of alternating light and dark rings, known as growth rings because of their resemblance to tree rings.[10]
The growth rings surround the hilum, the central region of the granule, whose precise structure remains unclear, although it appears to consist of a relatively disordered α-glucan arrangement. Each ring has a thickness of 200–400 nm and reflects the alternation of less dense amorphous regions and denser semi-crystalline regions.[10]
According to the cluster model, the semi-crystalline regions arise from the alternation of crystalline and amorphous lamellae, stacked with a periodicity of about 9–10 nm.[9] The crystalline lamellae, composed of amylopectin linear chains arranged in A-, B-, or C-type polymorphs, extend about 6–7 nm, whereas the amorphous lamellae, which contain most of the branch points, extend about 3 nm.[11][12]
Amylopectin synthesis
Amylopectin synthesis is thought to initiate at the hilum of the starch granule.[13]
It requires the coordinated activities of at least four distinct classes of enzymes: starch synthases, starch phosphorylase, starch branching enzymes, and starch debranching enzymes.[1] Each class comprises several isoforms with distinct biochemical properties.
Like amylose biosynthesis, amylopectin synthesis depends on short malto-oligosaccharides (MOS), α-(1→4)-glucans with a DP of 2 to 7, which act as primers and are elongated by starch synthase, in a manner similar to the role of glycogenin during the early stages of glycogen synthesis.[14]
MOS appear to originate from multiple sources, all of which require the action of enzymes involved in starch biosynthesis, including:
starch synthase III (SSIII) and starch phosphorylase (the latter in cooperation with the disproportionating enzyme, EC 2.4.1.25), which use ADP-glucose and glucose-1-phosphate as substrates, respectively;
starch debranching enzymes, which generate MOS during the trimming of other amylopectin molecules.[14]
Because MOS exhibit low solubility in aqueous environments, they seem to evade hydrolysis by alpha-amylase (EC 3.2.1.1) and beta-amylase (EC 3.2.1.2).[6]
The spatial and temporal coordination of the enzymes involved, many of which physically interact to form multienzyme complexes, is essential for converting the products of photosynthesis into the highly organized and insoluble polysaccharide structure.[5] Moreover, as in amylose and glycogen synthesis, the polymerization of glucose into amylopectin, and more generally of osmotically active monosaccharides into osmotically inert polysaccharides, enables the storage of large amounts of carbohydrates within the cell without causing a substantial increase in osmotic pressure.[15]
Starch synthase
Six isoforms of starch synthase have been identified, all structurally related. Five of these, starch synthase I, II, III, IV, and V (SSI, SSII, SSIII, SSIV, and SSV; EC 2.4.1.21), are involved in amylopectin biosynthesis. They are localized either in the plastid stroma or partitioned between the stroma and starch granules. The sixth isoform, granule-bound starch synthase (GBSS; EC 2.4.1.242), is almost exclusively associated with granules and is responsible for amylose synthesis.[10][16]
The first four isoforms are catalytically active and, like GBSS, glycogen phosphorylase (EC 2.4.1.1), and glycogen synthase (EC 2.4.1.11), which are enzymes involved in glycogenolysis and glycogen synthesis, belong to the glycosyltransferase family (EC 2.4). In contrast, starch synthase V lacks catalytic activity.
During amylopectin synthesis, starch synthase catalyzes the addition of one glucose residue to the non-reducing end of a pre-existing α-(1→4)-linked glucan chain, forming a new α-(1→4) glycosidic bond.[12]
Unlike glycogen synthase, which uses UDP-glucose, starch synthase employs ADP-glucose as the glucosyl donor.[5]
The mode of action of starch synthases I–IV differs from that of GBSS. While SS isoforms catalyze the incorporation of only one glucose unit per substrate encounter, a distributive mode of action, GBSS is capable of adding multiple glucose units per encounter, a processive mode of action.[6]
Roles of starch synthases
The initial steps of amylopectin biosynthesis, as well as the formation of normal starch granules, require the presence of SSIV, although SSIII also appears to contribute, with partially overlapping functions.[14]
Like GBSS, SSIV depends on a member of the PTST protein family, PTST2, which lacks catalytic activity but facilitates enzyme binding to α-glucans through a specific carbohydrate-binding domain. SSIV can also dimerize, a feature important both for its catalytic activity and for protein–protein interactions.
According to a proposed model of PTST2 function, the protein recognizes malto-oligosaccharides with a specific three-dimensional helical conformation via its carbohydrate-binding domain. PTST2 then forms a complex with MOS, which subsequently interacts with an SSIV dimer. The dimer catalyzes the elongation of the α-glucan, while PTST2 is released, enabling it to bind another MOS and mediate further interactions with SSIV dimers.[17]
Following the action of SSIV, the other starch synthase isoforms extend the glucan chains. SSI elongates malto-oligosaccharides with a DP of 6–7 to form oligosaccharides with a DP of 8–12. These, in turn, are excellent substrates for SSII, which extends them to chains with a DP of 12–30. SSIII further elongates the glucans, producing linear chains with DP values greater than 30. Thus, SSIII appears to function not only in the early stages of granule initiation but also during later phases of starch biosynthesis.[1]
Finally, SSIV and SSV seem to be required for the production of a regular number of starch granules with normal morphology.[7][14]
Starch branching enzymes
Starch branching enzymes (SBEs) catalyze the formation of α-(1→6) glycosidic bonds, thereby introducing branch points into linear α-glucan chains, such as those in glycogen and amylopectin.[18][19] Their action increases the number of non-reducing ends, which serve as acceptors of glucose units during elongation reactions.[20]
SBEs function by cleaving an internal α-(1→4) bond within an α-glucan chain, releasing an oligosaccharide (or oligonucleotide) whose reducing end is subsequently attached to the hydroxyl group at the C6 position of a glucosyl residue on an α-glucan chain. The result is a new α-(1→6) linkage. The acceptor chain can be either the same chain from which the oligosaccharide was removed (intra-chain transfer) or a different chain (inter-chain transfer).
One of the factors influencing the type of transfer appears to be the relative concentration of linear α-(1→4) chains. In particular, closely associated chains, such as those forming double helices within clusters, tend to favor inter-chain transfer.[21] Moreover, the interaction between starch synthase I and starch branching enzymes seems to play a key role in determining the bimodal chain-length distribution characteristic of plant starches.[14]
Starch branching enzyme isoforms
Plants possess two isoforms of starch branching enzyme, referred to as SBEI and SBEII. Encoded by different genes, they exhibit distinct biochemical properties, suggesting that they play different roles in determining the structure of amylopectin and amylose.[6]
SBEI is expressed predominantly in storage tissues, indicating an important role in defining the structural properties of storage starches. It shows a substrate preference for amylose and can transfer oligosaccharides with a DP greater than 30, although most transfers involve chains of DP 10–13. SBEI also appears to be involved in the synthesis of super-long (or extra-long) amylopectin chains, while its other contributions to amylopectin structure seem less significant. Not all plants express SBEI; for example, Arabidopsis and canola (Brassica napus L.), both oil-storing plants, possess only SBEII, and starch is found exclusively in their photosynthetic tissues.[22][23]
SBEII is widely expressed in grasses, cereals, and many other plants. Loss of SBEII activity results in pronounced alterations to amylopectin architecture and a reduction in starch content. The enzyme has a substrate preference for amylopectin and transfers oligosaccharides with a DP of 6–14. In cereals and grasses, two tissue-specific isoforms are encoded by distinct genes: SBEIIa, expressed mainly in leaves, and SBEIIb, expressed mainly in the endosperm.[6]
Starch debranching enzymes
Starch debranching enzymes catalyze the hydrolysis of α-(1→6) glycosidic bonds and are members of the α-amylase superfamily.
Two types of debranching enzymes are present in plants: isoamylases (EC 3.2.1.68) and pullulanases (EC 3.2.1.41).[24] Isoamylases act on amylopectin and other polyglucans, whereas pullulanases debranch both amylopectin and pullulan, a fungal polysaccharide. Isoamylases and pullulanases also differ in substrate specificity: isoamylases hydrolyze branches composed of at least three glycosidic residues, while pullulanases can act on branches of just two.[25]
During starch granule formation, starch debranching enzymes play a crucial role in defining the water-insoluble properties and fine structure of amylopectin. Enzyme activity is thought to promote clustering of the remaining branches, thereby enhancing interactions between adjacent chains and facilitating α-helix formation. This process, in turn, appears essential for the development of the semi-crystalline structures of amylopectin and, consequently, of starch. In these semi-crystalline regions, branches are presumably inaccessible to starch debranching enzymes, α-amylase, and β-amylase.[6]
Starch debranching enzymes are also employed industrially, particularly in the production of resistant starch and cyclodextrins, which are cyclic oligosaccharides.[25]
Starch phosphorylase
Like starch synthases, starch phosphorylase belongs to the family of glycosyltransferases and closely resembles glycogen phosphorylase. In plants, it occurs in at least two isoenzymatic forms: Pho1, located in the stroma of plastids and considered the true starch phosphorylase involved in starch synthesis, and Pho2, which is cytosolic.[26]
Starch phosphorylase is thought to participate in the initial steps of starch synthesis by catalyzing the reversible transfer of glucosyl units to an α-glucan, where they are linked by an α-(1→4) glycosidic bond.[5] Unlike starch synthases, starch phosphorylase uses glucose-1-phosphate, not ADP-glucose, as the glucosyl donor.[26]
Phosphorylation of amylopectin
Amylopectin, like glycogen, carries phosphate groups in variable amounts depending on the botanical source of the starch. For example, potato starch contains relatively high levels of phosphate groups, with a degree of substitution of about 0.1%–0.3%, whereas cereal endosperm starches generally have phosphate contents below 0.01%.[27]
Phosphorylation of amylopectin is catalyzed by two dikinases present in plastids: α-glucan water dikinase (EC 2.7.9.4) and phospho-glucan water dikinase (EC 2.7.9.5). These enzymes transfer the β-phosphate group of ATP to a glucosyl unit of an α-glucan chain, while the γ-phosphate group is transferred to water. Specifically, α-glucan water dikinase phosphorylates the hydroxyl group at the C6 position, whereas phospho-glucan water dikinase phosphorylates the hydroxyl group at the C3 position, usually on a prephosphorylated glucan chain. About two-thirds of phosphate groups are bound at the C6 position and 20%–30% at the C3 position. Phosphate groups are also detected at the C2 position, but in much smaller amounts. The enzyme responsible for this phosphorylation is not known.[28][29]
With regard to substrate specificity, phosphorylation appears to accumulate more readily on longer chains. Furthermore, there seems to be an inverse correlation between total phosphate content and the frequency of amylopectin branching. The negative charges carried by phosphate groups cause mutual repulsion between neighboring phosphorylated oligosaccharides. These repulsions seem to promote chain opening and hydration, thereby influencing the activity of biosynthetic enzymes and making the chains more susceptible to attack by amylases.[30][31]
Amylose/amylopectin ratio
Starch granules are composed primarily of amylopectin and amylose.[1] The relative proportions of the two polysaccharides vary, with amylose typically accounting for no more than 35% of the granule’s dry weight.[12] However, some plants produce starch granules composed mostly, or almost entirely, of amylopectin, (known as waxy starches), while others produce starch granules composed predominantly, or almost exclusively, of amylose.[21]
The amylose/amylopectin ratio strongly influences the physicochemical properties of starch, including water absorption, gelatinization, retrogradation, and resistance to enzymatic hydrolysis. The latter property is especially relevant during carbohydrate digestion, as it determines the rate at which amylose and amylopectin are hydrolyzed by α-amylase to maltose and maltotriose. Consequently, the amylose/amylopectin ratio affects both the health impacts of different starch types and their industrial applications.[5][32][33]
References
^ abcd Qu J., Xu S., Zhang Z., Chen G., Zhong Y., Liu L., Zhang R., Xue J., Guo D. Evolutionary, structural and expression analysis of core genes involved in starch synthesis. Sci Rep 2018;8(1):12736. doi:10.1038/s41598-018-30411-y
^ abc Cornejo-Ramírez Y.I., Martínez-Cruz O., Del Toro-Sánchez C.L., Wong-Corral F.J., Borboa-Flores J. & Cinco-Moroyoqui F.J. The structural characteristics of starches and their functional properties. CYTA J Food 2018;16(1):1003-1017. doi:10.1080/19476337.2018.1518343
^ Smith A.M., Zeeman S.C. Starch: a flexible, adaptable carbon store coupled to plant growth. Annu Rev Plant Biol 2020;71:217-245. doi:10.1146/annurev-arplant-050718-100241
^ Junejo S.A., Flanagan B.M., Zhang B., Dhital S. Starch structure and nutritional functionality – Past revelations and future prospects. Carbohydr Polym 2022;277:118837. doi:10.1016/j.carbpol.2021.118837
^ abcdef Crofts N., Abe N., Oitome N.F., Matsushima R., Hayashi M., Tetlow I.J., Emes M.J., Nakamura Y., Fujita N. Amylopectin biosynthetic enzymes from developing rice seed form enzymatically active protein complexes. J Exp Bot 2015;66(15):4469-82. doi:10.1093/jxb/erv212
^ abcdefg Tetlow I.J., Bertoft E. A review of starch biosynthesis in relation to the building block-backbone model. Int J Mol Sci 2020;21(19):7011. doi:10.3390/ijms21197011
^ ab Abt M.R., Pfister B., Sharma M., Eicke S., Bürgy L., Neale I., Seung D., Zeeman S.C. STARCH SYNTHASE5, a noncanonical starch synthase-like protein, promotes starch granule initiation in Arabidopsis. Plant Cell 2020;32(8):2543-2565. doi:10.1105/tpc.19.00946
^ ab Li G., Yacine Y., Zhu F. Relationships between supramolecular organization and amylopectin fine structure of quinoa starch. Food Hydrocoll 2021;117:106685. doi:10.1016/j.foodhyd.2021.106685
^ ab Pfister B., Zeeman S.C., Rugen M.D., Field R.A., Ebenhöh O., Raguin A. Theoretical and experimental approaches to understand the biosynthesis of starch granules in a physiological context. Photosynth Res 2020;145:55-70. doi:10.1007/s11120-019-00704-y
^ abcd Pfister B., Zeeman S.C. Formation of starch in plant cells. Cell Mol Life Sci 2016;73(14):2781-807. doi:10.1007/s00018-016-2250-x
^ Jenkins P.J., Donald A.M. The influence of amylose on starch granule structure. Int J Biol Macromol 1995;17(6):315-21. doi:10.1016/0141-8130(96)81838-1
^ abc Gous P.W., Fox G.P. Review: Amylopectin synthesis and hydrolysis – Understanding isoamylase and limit dextrinase and their impact on starch structure on barley (Hordeum vulgare) quality. Trends Food Sci Technol 2017;62:23-32. doi:10.1016/j.tifs.2016.11.013
^ Ziegler G.R., Creek J.A., Runt J. Spherulitic crystallization in starch as a model for starch granule initiation. Biomacromolecules 2005;6(3):1547-54. doi:10.1021/bm049214p
^ abcde Szydlowski N., Ragel P., Raynaud S., Lucas M.M., Roldán I., Montero M., Muñoz F.J., Ovecka M., Bahaji A., Planchot V., Pozueta-Romero J., D’Hulst C., Mérida A. Starch granule initiation in Arabidopsis requires the presence of either class IV or class III starch synthases. Plant Cell 2009;21(8):2443-57. doi:10.1105/tpc.109.066522
^ Nelson D.L., Cox M.M. Lehninger. Principles of biochemistry. 8th Edition. W.H. Freeman and Company, 2021.
^ Zeeman S.C., Kossmann J., Smith A.M. Starch: its metabolism, evolution, and biotechnological modification in plants. Annu Rev Plant Biol 2010;61:209-34. doi:10.1146/annurev-arplant-042809-112301
^ Seung D., Boudet J., Monroe J., Schreier T.B., David L.C., Abt M., Lu K.J., Zanella M., Zeeman S.C. Homologs of PROTEIN TARGETING TO STARCH control starch granule initiation in Arabidopsis leaves. Plant Cell 2017;29(7):1657-1677. doi:10.1105/tpc.17.00222
^ Ball S.G., Morell M.K. From bacterial glycogen to starch: understanding the biogenesis of the plant starch granule. Annu Rev Plant Biol. 2003;54:207-33. doi:10.1146/annurev.arplant.54.031902.134927
^ Wilkens C., Svensson B., Møller M.S. Functional roles of starch binding domains and surface binding sites in enzymes involved in starch biosynthesis. Front Plant Sci 2018;9:1652. doi:10.3389/fpls.2018.01652
^ Sawada T., Nakamura Y., Ohdan T., Saitoh A., Francisco P.B. Jr, Suzuki E., Fujita N., Shimonaga T., Fujiwara S., Tsuzuki M., Colleoni C., Ball S. Diversity of reaction characteristics of glucan branching enzymes and the fine structure of α-glucan from various sources. Arch Biochem Biophys 2014;562:9-21. doi:10.1016/j.abb.2014.07.032
^ ab Wang J., Hu P., Lin L., Chen Z., Liu Q., Wei C. Gradually decreasing starch branching enzyme expression is responsible for the formation of heterogeneous starch granules. Plant Physiol 2018;176(1):582-595. doi:10.1104/pp.17.01013
^ Guan H.P., Preiss J. Differentiation of the properties of the branching isozymes from maize (Zea mays). Plant Physiol 1993;102(4):1269-1273. doi:10.1104/pp.102.4.1269
^ Dumez S., Wattebled F., Dauvillee D., Delvalle D., Planchot V., Ball S.G., D’Hulst C. Mutants of Arabidopsis lacking starch branching enzyme II substitute plastidial starch synthesis by cytoplasmic maltose accumulation. Plant Cell 2006;18(10):2694-709. doi:10.1105/tpc.105.037671
^ Møller M.S., Henriksen A., Svensson B. Structure and function of α-glucan debranching enzymes. Cell Mol Life Sci 2016;73(14):2619-41. doi:10.1007/s00018-016-2241-y
^ ab Xia W., Zhang K., Su L., Wu J. Microbial starch debranching enzymes: developments and applications. Biotechnol Adv 2021;50(3):107786. doi:10.1016/j.biotechadv.2021.107786
^ ab Cuesta-Seijo J.A., Ruzanski C., Krucewicz K., Meier S., Hägglund P., Svensson B., Palcic M.M. Functional and structural characterization of plastidic starch phosphorylase during barley endosperm development. PLoS One 2017;12(4):e0175488. doi:10.1371/journal.pone
^ Nitschke F., Wang P., Schmieder P., Girard J.M., Awrey D.E., Wang T., Israelian J., Zhao X., Turnbull J., Heydenreich M., Kleinpeter E., Steup M., Minassian B.A. Hyperphosphorylation of glucosyl C6 carbons and altered structure of glycogen in the neurodegenerative epilepsy Lafora disease. Cell Metab 2013;17(5):756-67. doi:10.1016/j.cmet.2013.04.006
^ Hizukuri S., Tabata S., Kagoshima Nikuni Z. Studies on starch phosphate Part 1. Estimation of glucose-6-phosphate residues in starch and the presence of other bound phosphate(s). Starch/Stärke 1970;22:338-343. doi:https://doi.org/10.1002/star.19700221004
^ Ritte G., Heydenreich M., Mahlow S., Haebel S., Kötting O., Steup M. Phosphorylation of C6- and C3-positions of glucosyl residues in starch is catalysed by distinct dikinases. FEBS Lett 2006;580(20):4872-6. doi:10.1016/j.febslet.2006.07.085
^ Zhou W., He S., Naconsie M., Ma Q., Zeeman S.C., Gruissem W. & Zhang P. Alpha-glucan, water dikinase 1 affects starch metabolism and storage root growth in Cassava (Manihot esculenta Crantz). Sci Rep 2017;7:9863 doi:10.1038/s41598-017-10594-6
^ Baunsgaard L., Lütken H., Mikkelsen R., Glaring M.A., Pham T.T., Blennow A. A novel isoform of glucan, water dikinase phosphorylates pre-phosphorylated alpha-glucans and is involved in starch degradation in Arabidopsis. Plant J 2005;41(4):595-605. doi:10.1111/j.1365-313X.2004.02322.x
^ Tester R.F., Morrison W.R. Swelling and gelatinization of cereal starches. I. Effects of amylopectin, amylose and lipids. Cereal Chem 1990;67:551-557.
^ Hoover R. Composition, molecular structure, and physicochemical properties of tuber and root starches: a review. Carbohydr Polym 2001;45(3):253-267 doi:10.1016/S0144-8617(00)00260-5
Hypertension is defined as a mean resting arterial pressure of 140/90 mm Hg or higher and/or current use of antihypertensive drugs.
It is the most common public health problem in developed countries. Often referred to as the “silent killer”, as affected individuals may be asymptomatic for many years and then suffer a fatal heart attack, it is a major risk factor for developing coronary artery disease, myocardial infarction, heart failure, stroke, and a leading cause of morbidity and mortality. However, among the risk factors for cardiovascular disease, it is the most modifiable.
It is often classified as primary or essential hypertension and secondary hypertension.
Primary hypertension, responsible for about 95 percent of cases, is probably the consequence of environmental factors, genetic factors, and their interaction. Among the environmental factors, diet plays a central role. Among the genetic factors, interest has focused on factors influencing the blood pressure response to salt intake, and several genotypes have been identified, many of which influence the renin-angiotensin-aldosterone system or renal salt handling.
Secondary hypertension is due to other diseases, usually endocrine, such as hyperthyroidism, hyperaldosteronism, and Cushing’s syndrome.
Above-optimal blood pressure levels, not yet in the hypertensive or prehypertensive range, confers an increased risk of cardiovascular disease, as shown by the fact that nearly one-third of blood pressure-related deaths from coronary heart disease are estimated to occur in non-hypertensive individuals with systolic blood pressure of 120-139 mm Hg, or diastolic blood pressure of 80-89 mm Hg. This means that the risk of cardiovascular disease increases throughout the blood pressure range, starting from 115/75 mm Hg.
Classification of blood pressure values (mm Hg)
Category
Blood Pressure (mm Hg)
Systolic
Diastolic
Optimal
< 120
< 80
Normal
< 130
< 85
High-Normal
130 – 139
85 – 89
Grade 1 hypertension
140 – 159
90 – 99
Grade 2 hypertension
160 – 179
100 – 109
Grade 3 hypertension
≥180
≥110
Isolated systolic hypertension
≥140
≤ 90
Finally, pre-hypertensive individuals have a high risk, about 90%, of developing hypertension over time, although the transition is not inevitable.
Age-related hypertension
The prevalence of hypertension increases with increasing age, as shown by the fact that more than half of the adult population over 60 years old is hypertensive. Age-related risk is a function of variables such as weight gain, low physical activity, excessive use of salt, fats and saturated fatty acids, alcohol, hypercholesterolemia, and low intake of fruits and vegetables, rather than of aging per se. For example, studies of vegetarians living in industrialized countries have shown that such dietary habits are associated with a lower increase in blood pressure with increasing age, and with a markedly lower blood pressure compared to non-vegetarians.
Hypertension and childhood
According to a study conducted by a team of researchers from Johns Hopkins University, prevention of hypertension starts in childhood.
Furthermore, a meta-analysis on studies from diverse populations, studies published between January 1970 and July 2006, have examined the tracking of blood pressure from childhood to adulthood showing that childhood blood pressure is associated with blood pressure in later life, and that a high values in childhood are likely to help predict hypertension in adulthood.
Finally, other studies have also shown that increased blood pressure among children is related to the growing obesity epidemic.
How to prevent hypertension
A downward trend in blood pressure has been documented in the USA over the last two decades, and the adoption of healthy lifestyle have contributed to this trend.
Lifestyle modifications that effectively lower blood pressure are:
reduce the intake of salt and other forms of sodium;
follow a diet rich in fresh fruit, vegetables, complex carbohydrates and low-fat dairy products;
increase potassium intake by consuming fruit, vegetables and legumes;
lose body weight if overweight, or prevent weight gain among those who are thin;
increase physical activity of low or moderate intensity;
stop smoking;
These changes are the first line of defense in preventing high blood pressure, and need not be made one at a time: the best results are achieved when they occur simultaneously, as demonstrated by two studies in which multicomponent interventions lowered blood pressure in hypertensive and nonhypertensive individuals.
Finally, it has been demonstrated that there is also a relationship between alcohol and hypertension.
Role of potassium intake
Potassium, an essential nutrient for humans, is the most abundant cation in intracellular fluids. It is therefore widely distributed in foods that come from living tissues, both animal and vegetable, but which have not undergone salting and/or drying. Cooking methods tend to lower the amount of potassium, as well.
Considering vegetables, the worst cooking method is boiling in plenty of water, for more than an hour, whereas the best is microwave cooking.
Potassium content (mg/100 g) in selected food categories: classification and sources
Potassium content
Category
Examples
>250
Legumes
Chickpeas, beans (dried and fresh), lentils, peas, soybeans
Fresh or preserved (latter should be limited due to high sodium content)
A high dietary potassium intake and blood pressure are inversely correlated, as demonstrated by animal studies, observational epidemiological studies, clinical trials, controlled feeding studies, such as the DASH Study and the OmniHeart trial, and meta-analysis. Furthermore, a high potassium intake also increases urinary sodium excretion.
The optimal strategy for increasing potassium intake is to consume foods naturally rich in the mineral, such as seasonal fruit and vegetables, and legumes, typical foods of the Mediterranean diet. It is therefore not difficult to reach the recommended daily intake, for the healthy population, equal to 4.7 g per day.
Role of sodium intake
Sodium is the most abundant cation in extracellular fluids, of which it strongly affects the osmotic pressure values.
There are three main source of sodium.
The most intuitive source is table salt, which represents up to 20 percent of the daily intake. It is important to note the terms salt and sodium are often used interchangeably, but this is incorrect. On a weight basis, salt is 40 percent sodium and 60 percent chlorine.
A second source is salt or sodium compounds added during food preparation or processing. Between 35 to 80 percent of the daily sodium intake comes from processed foods such as:
The third source is negligible, namely, the sodium naturally present in foods, generally low in fresh foods.
A high sodium intake contributes to the increase in blood pressure and the development of hypertension. This is supported by many epidemiological, animal, and migration studies, and meta-analysis, with the final evidence coming from carefully controlled dose-response studies. Furthermore, in primitive societies, where sodium intake is very low, people rarely develop hypertension, and blood pressure does not increase with increasing age.
Therefore, a reduction in sodium intake is recommended to prevent the development of hypertension. In view of the available food supply and the high daily sodium intake, a reasonable recommendation may be to limit its intake to 2.3 g per day, equal to 5.8 g per day of salt. How can this level be achieved?
Using as little salt as possible when preparing food.
Avoiding adding salt at the table.
Avoiding highly salted, processed foods.
Clinical studies have documented that a reduced sodium intake is able to lower blood pressure even the setting of antihypertensive therapy, and can facilitate hypertension control.
Some components of the diet may modify the blood pressure response to sodium. A high dietary intake of foods rich in potassium and calcium may prevent or attenuate the increase in blood pressure for a given increase in sodium intake. Conversely, some data, mainly observed in animal models, suggest that a high sucrose intake could enhance salt sensitivity of blood pressure.
Note: high sodium intakes may contribute to the development of osteoporosis by increasing renal calcium excretion, particularly if daily calcium intake is low.
Role of body weight
Body weight, especially overweight and obesity, is a determinant of blood pressure at any age. Indeed:
it has been estimated that the risk of developing high blood pressure is two to six times greater in overweight people than in normal weight people;
there is a linear correlation between blood pressure and body weight or body mass index, which, if greater than 27, correlates with an increase in blood pressure;
even when sodium intake is held constant, the correlation between change in weight and change in blood pressure is linear;
60 percent of hypertensive subjects are more than 20 percent overweight;
the central distribution of body fat, as a determinant of blood pressure, with a waist circumference greater than 88 cm in women and 102 in men, is more important than the peripheral distribution of fat, both in men and women;
weight loss, in both hypertensive and normotensive subjects, may reduce blood pressure, and the reduction occurs before, and without, achieving a desirable body weight.
Role of physical activity
Physical activity produces a drop in systolic and diastolic blood pressure. Therefore, for the primary prevention of hypertension, it is important to increase physical activity of low or moderate intensity for 30-45 minutes 3-4 times a week up to an hour most days, as recommended by the World Health Organization. Conversely, less active people are 30 to 50 percent more likely to develop hypertension than active people.
References
Appel L.J., Brands M.W., Daniels S.R., Karanja N., Elmer P.J. and Sacks F.M. Dietary approaches to prevent and treat HTN: a scientific statement from the American Heart Association. Hypertension 2006;47:296-08. doi:10.1161/01.HYP.0000202568.01167.B6
Bibbins-Domingo K., Chertow G.M., Coxson P.G., Moran A., Lightwood J.M., Pletcher M.J., and Goldman L. Projected effect of dietary salt reductions on future cardiovascular disease. N Engl J Med 2010;362:590-9. doi:10.1056/NEJMoa0907355
Cappuccio FP. Overview and evaluation of national policies, dietary recommendtions and programmes around the world aiming at reducing salt intake in the population. World Health Organization. Reducing salt intake in populations: report of a WHO forum and technical meeting. WHO Geneva 2007;1-60.
Chen J, Gu D., Jaquish C.E., Chen C., Rao D.C., Liu D., Hixson J.E., Lee Hamm L., Gu C.C., Whelton P.K. and He J. for the GenSalt Collaborative Research Group. Association between blood pressure responses to the cold pressor test and dietary sodium intervention in a chinese population. Arch Intern Med. 2008;168:1740-1746. doi:10.1001/archinte.168.16.1740
Chen X. and Wang Y. Tracking of blood pressure from childhood to adulthood. A systematic review and meta-regression analysis. Circulation 2008;117:3171-80. doi:10.1161/CIRCULATIONAHA.107.730366
Denton D., Weisinger R., Mundy N.I., Wickings E.J., Dixson A., Moisson P., Pingard A.M., Shade R., Carey D., Ardaillou R., Paillard F., Chapman J., Thillet J. & Michel J.B. The effect of increased salt intake on blood pressure of chimpanzees. Nature Med 1995;10:1009-1016. doi:10.1038/nm1095-1009
Ford E.S., Ajani U.A., Croft J.B., Critchley J.A., Labarthe D.R., Kottke T.E., Giles W.H, and Capewell S. Explaining the decrease in U.S. deaths from coronary disease, 1980-2000. N Engl J Med 2007;356:2388-98. doi:10.1056/NEJMsa053935
Geleijnse J.M., Witteman J.C., den Breeijen J.H., Hofman A., de Jong P., Pols H.A. and Grobbee D.E. Dietary electrolyte intake and blood pressure in older subjects: the Rotterdam Study. J Hyperten 1996;14:73741. doi:10.1097/00004872-199606000-00009
Gutiérrez O.M. Sodium- and phosphorus-based food additives: persistent but surmountable hurdles in the management of nutrition in chronic kidney disease. Adv Chronic Kidney Dis 2013;20(2):150-6. doi:10.1053/j.ackd.2012.10.008
Harlan W.R. and Harlan L.C. Blood pressure and calcium and magnesium intake. In: Laragh J.H., Brenner B.M., eds. Hypertension: pathophysiology, diagnosis and management. 2end ed. New York: Raven Press 1995;1143-1154
He F.J., Tan M., Ma Y., MacGregor G.A. Salt reduction to prevent hypertension and cardiovascular disease: JACC state-of-the-art review. J Am Coll Cardiol 2020;75(6):632-647. doi:10.1016/j.jacc.2019.11.055
Holmes E., Loo R.L., Stamler J., Bictash M., Yap I.K.S., Chan Q., Ebbels T., De Iorio M., Brown I.J., Veselkov K.A., Daviglus M.L., Kesteloot H., Ueshima H., Zhao L., Nicholson J.K. and Elliott P. Human metabolic phenotype diversity and its association with diet and blood pressure. Nature 2008;453:396-400. doi:10.1038/nature06882
Nugroho P., Andrew H., Kohar K., Noor C.A., Sutranto A.L. Comparison between the world health organization (WHO) and international society of hypertension (ISH) guidelines for hypertension. Ann Med 2022;54(1):837-845. doi:10.1080/07853890.2022.2044510
Sesso H.D., Cook N.R., Buring J.E., Manson J.E. and Gaziano J.M. Alcohol consumption and the risk of hypertension in women and men. Hypertension 2008;51:1080-1087. doi:10.1161/HYPERTENSIONAHA.107.104968
Simpson F.O. Blood pressure and sodium intake. In: Laragh J.H., Brenner B.M. eds. Hypertension: pathophysiology, diagnosis and management. 2end ed. New York: Raven Press 1995;273-281
Stone M.S., Martyn L., Weaver C.M. Potassium intake, bioavailability, hypertension, and glucose control. Nutrients 2016;8(7):444. doi:10.3390/nu8070444
Strazzullo P., D’Elia L., Kandala N. and Cappuccio F.P. Salt intake, stroke, and cardiovascular disease: meta-analysis of prospective studies. BMJ 2009;339:b4567. doi:10.1136/bmj.b4567
Tzoulaki I., Brown I.J., Chan Q., Van Horn L., Ueshima H., Zhao L., Stamler J., Elliott P., for the International Collaborative Research Group on Macro-/Micronutrients and Blood Pressure. Relation of iron and red meat intake to blood pressure: cross sectional epidemiological study. BMJ 2008;337:a258. doi:10.1136/bmj.a258
Unger T., Borghi C., Charchar F., Khan N.A., Poulter N.R., Prabhakaran D., Ramirez A., Schlaich M., Stergiou G.S., Tomaszewski M., Wainford R.D., Williams B., Schutte A.E. 2020 International society of hypertension global hypertension practice guidelines. hypertension 2020;75(6):1334-1357. doi:10.1161/HYPERTENSIONAHA.120.15026
Weinberger M.H. The effects of sodium on blood pressure in humans. In: Laragh J.H., Brenner B.M., eds. Hypertension: pathophysiology, diagnosis and management. 2end ed. New York: Raven Press 1995;2703-2714.
Writing Group of the PREMIER Collaborative Research Group. Effects of comprehensive lifestyle modification on blood pressure control: main results of the PREMIER Clinical Trial. JAMA 2003;289:2083-2093. doi:10.1001/jama.289.16.2083
World Health Organization, International Society of Hypertension Writing Group. 2003 World Health Organization (WHO)/ISH statement on management of HTN. Guidelines and recommendations. J Hyperten 2003;21:1983-92. doi:10.1097/00004872-200311000-00002
And dietary cholesterol?
There is not a direct correlation between blood cholesterol and cholesterol intake. Dietary cholesterol may increase plasma cholesterol only when it is consumed with trans fats and saturated fatty acids.
However, if you want to reduce your cholesterol intake, we advise to reduce the use of animal products and/or use semi-skimmed or skimmed milk, light cheese, light yogurt, and lean meat.
A risky factor for hypercholesterolemia is a high intake of saturated fatty acids, a group of lipids that can be easily used for the endogenous synthesis of cholesterol.
These fatty acids are present in meat, diary products, and in abundance in vegetal fats and oils, such as margarine, palm oil, palm seed oil, and coconut oil, which are much used in the confectionery industry.
What to do:
to eliminate the visible fat of meat, or buy lean cuts;
to replace whole milk, butter, fat cheese, creams, and ice-creams with products which contain less fat, such as low-fat yogurt, semi-skimmed or skimmed milk, low-fat cheeses;
to avoid confectionery products.
Trans fatty acids
Trans fatty acids or trans fats are an extremely risky factor, and not only for hypercholesterolemia.
Studies have observed a high atherogenic potential caused by changes in plasmatic lipoproteins, where a decrease of HDL levels, and an increase of LDL and triglyceride levels occur.
Where can they be found?
In a lot of foods for kids.
In baked industrial products, such as crackers, breadsticks, cakes, packed bread, and snacks.
In a lot of industrial foods, such as soups, ready fresh or frozen meals, and mixtures to prepare pies and pizza.
In bouillon cubes.
In soft candies.
In some corn flakes.
In ice creams, in vegetal substitutes of cream, and in margarine.
In a lot of preserves, jams included.
As regards to the content of saturated and trans fatty acids, there is often no difference between classic products and “natural” or “organic” ones.
What can we do?
To avoid to buy products that contain vegetal fats and/or hydrogenated fatty acids, and to avoid to buy fried products.
Overweight
A significant body fat gain contributes to hypercholesterolemia.
In a lot of people, the decrease in the intake of satured and trans fatty acids doesn’t reduce the cholesterolemia levels till weight starts to drop.
What to do:
to reduce the intake of animal and vegetable fats;
to reduce foods rich in simple sugars, such as sweets, soft drinks, desserts, candies, and cakes;
do not win back calories you have eliminated in the preceding points by an excessive use of extravergin olive oil and starch, namely pasta, potatoes, rice, bread;
to increase the physical activity;
to increase the intake of fruit and vegetables.
Genetic causes
In this case, it needs a drug prescription by physician, which must be however combined with right nutritional advices.
References
Ascherio A., Katan M.B., Zock P.L., Stampfer M.J., Willett W.C. Trans fatty acids and coronary heart disease. N Engl J Med 1999;340:1994-1998. doi:10.1056/NEJM199906243402511
Benito-Vicente A., Uribe K.B., Jebari S., Galicia-Garcia U., Ostolaza H., Martin C. Familial hypercholesterolemia: the most frequent cholesterol metabolism disorder caused disease. Int J Mol Sci 2018;19(11):3426. doi:10.3390/ijms19113426
Fernandez M.L., Murillo A.G. Is there a correlation between dietary and blood cholesterol? Evidence from epidemiological data and clinical interventions. Nutrients 2022;14(10):2168. doi:10.3390/nu14102168
Hu F.B., Willett W.C. Optimal diet for prevention of coronary heart disease JAMA 2002;288:2569-2578. doi:10.1001/jama.288.20.2569
Lichtenstein A.H. Dietary fat, carbohydrate, and protein: effects on plasma lipoprotein patterns J. Lipid Res. 2006;47:1661-1667. doi:10.1194/jlr.R600019-JLR200
Lichtenstein A.H., Ausman L., Jalbert S.M., Schaefer E.J. Effect of different forms of dietary hydrogenated fats on serum lipoprotein cholesterol levels. N Engl J Med 1999;340:1933-1940. doi:10.1056/NEJM199906243402501
Mensink R.P., Katan M.B. Effect of dietary trans fatty acids on high-density and low-density lipoprotein cholesterol levels in healthy subjects. N Engl J Med 1990;323:439-445. doi:10.1056/NEJM199008163230703
Mozaffarian D., Katan M.B., Ascherio A., Stampfer M.J., Willett W.C. Trans fatty acids and cardiovascular disease. N Engl J Med 2006;354:1601-1613. doi:10.1056/NEJMra054035
Shils M.E., Olson J.A., Shike M., Ross A.C.: “Modern nutrition in health and disease” 9th ed., by Lippincott, Williams & Wilkins, 1999
Starch synthase (EC 2.4.1.21) is an enzyme that catalyzes the transfer of glucose molecules from ADP-glucose to the non-reducing end of a pre-existing α-(1→4) linked glucan chain, where the glucosyl residues are attached via an α-(1→4) glycosidic bond.[1]
This enzymatic activity is involved in the synthesis of amylose and amylopectin, the two major constituents of starch, which is the main storage form of carbohydrates in plants.[2]
Starch synthase belongs to the family of glycosyltransferases (EC 2.4), like starch phosphorylase (EC 2.4.1.1), another enzyme involved in starch metabolism, and glycogen synthase (EC 2.4.1.11) and glycogen phosphorylase (EC 2.4.1.1), which are involved in glycogen synthesis and glycogen degradation (glycogenolysis), respectively.[3]
However, whereas glycogen synthase uses UDP-glucose as the glucosyl donor, and starch phosphorylase uses glucose 1-phosphate, starch synthase uses ADP-glucose.[4][5]
Summary: Key Points
Core function: starch synthase catalyzes the synthesis of plant amylose and amylopectin by transferring glucose residues from ADP-glucose.
Six plant isoforms: features five soluble variants in the stroma for amylopectin and one granule-bound variant for amylose.
Metabolic priming: requires short malto-oligosaccharides that serve as biological primers to initiate de novo polysaccharide synthesis.
PTST1 interaction: the granule-bound starch synthase isoform relies on transient binding with the PTST1 protein in the stroma to be successfully targeted to the nascent granule.
Six isoforms of starch synthase are known in plants. They are structurally related proteins, with five involved in the synthesis of amylopectin, referred to as starch synthase I, II, III, IV and V (SSI, SSII, SSIII, SSIV and SSV, respectively), and one involved in the synthesis of amylose, the granule-bound starch synthase (GBSS; EC 2.4.1.242).[3]
GBSS, SSI, SSII, SSIII, and SSIV possess catalytic activity, whereas SSV lacks it.[6]
GBSS is almost exclusively bound to starch granules and is located mainly within them, as evidenced by protease treatment of the granule surface. The other isoforms of starch synthase are found either only in the stroma of plastids or partitioned between starch granules and the stroma, and are referred to as soluble starch synthases.[7]
Starch synthases I, II, III, and IV catalyze the addition of a single glucose residue per substrate encounter, a distributive mode of action, whereas GBSS catalyzes the addition of more than one glucosidic unit per substrate encounter, a processive mode of action.[8]
Processive: adds multiple glucose units per encounter
Primarily bound to starch granules
Catalyzes the elongation of amylose chains
SSI–IV
Amylopectin
Distributive: adds a single glucose residue per encounter
Stroma and/or soluble in starch granules
Exhibit catalytic activity; contribute to amylopectin branching
SSV
Amylopectin
None (inactive)
Stroma
Lacks catalytic activity; function not fully understood
Starch synthase and MOS
Starch synthases involved in the early steps of amylose and amylopectin synthesis require short malto-oligosaccharides (MOS) to initiate the de novo synthesis of these two polysaccharides.
These small oligosaccharides, α-(1→4)-glucans with a degree of polymerization from 2 to 7, act as primers and are elongated, a function analogous to that performed by glycogenin in glycogen synthesis.
MOS can originate from the activity of starch synthase III, starch phosphorylase, or starch debranching enzymes.
Due to their low water solubility, MOS are able to evade the hydrolytic action of alpha-amylase (EC 3.2.1.1) and beta-amylase (EC 3.2.1.2).[8]
Starch synthase and amylopectin synthesis
The synthesis of amylopectin requires the temporally coordinated action of at least four classes of enzymes: starch synthase isoenzymes, starch phosphorylase, starch branching enzymes (EC 2.4.1.18), and starch debranching enzymes.[2][4] It is also thought that, in many cases, these enzymes physically interact with each other to form multienzyme complexes, structures capable of increasing the efficiency of the metabolic pathway.[8]
It is generally accepted that starch granule growth occurs from a central core called the hilum, whose precise structure is unknown, although it appears to consist of a disordered arrangement of α-glucans.[9] The initiation of the hilum, the formation of normal starch granule morphology, and the degree of starch accumulation require the presence of SSIV, although SSIII and SSV are also thought to contribute, overlapping in function with SSIV.[10]
GBSS and amylose synthesis
Granule-bound starch synthase is involved in the synthesis of amylose. This enzyme was first described by Luis Federico Leloir in the early 1960s, the same researcher who, in 1948, had discovered the main pathway for galactose metabolism, known as the Leloir pathway.[11]
Its catalytic action is not entirely simultaneous with that of the other starch synthases, as it requires the presence of an amylopectin matrix.[3]
In grasses, granule-bound starch synthase is present in two isoforms, encoded by distinct genes, referred to as GBSSI and GBSSII.[12]
GBSS requires, for its catalytic activity, the presence of a protein from the PTST family, PTST1, which enables its binding to the starch granule and whose action appears to be more important in chloroplasts than in amyloplasts.
Mechanism of GBSS and PTST1 Interaction
PTST1 appears to associate in the plastid stroma with GBSS. The complex binds to the nascent starch granule; the protein then dissociates from the enzyme, which begins catalyzing the elongation of malto-oligosaccharides, while the protein returns to the stroma to recruit another GBSS molecule.[13]
References
^ Zeeman S.C., Kossmann J., Smith A.M. Starch: its metabolism, evolution, and biotechnological modification in plants. Annu Rev Plant Biol 2010;61:209-34. doi:10.1146/annurev-arplant-042809-112301
^ ab Qu J., Xu S., Zhang Z., Chen G., Zhong Y., Liu L., Zhang R., Xue J., Guo D. Evolutionary, structural and expression analysis of core genes involved in starch synthesis. Sci Rep 2018;8(1):12736. doi:10.1038/s41598-018-30411-y
^ abc Pfister B., Zeeman S.C. Formation of starch in plant cells. Cell Mol Life Sci 2016;73(14):2781-807. doi: 10.1007/s00018-016-2250-x
^ ab Crofts N., Abe N., Oitome N.F., Matsushima R., Hayashi M., Tetlow I.J., Emes M.J., Nakamura Y., Fujita N. Amylopectin biosynthetic enzymes from developing rice seed form enzymatically active protein complexes. J Exp Bot 2015;66(15):4469-82. doi:10.1093/jxb/erv212
^ Cuesta-Seijo J.A., Ruzanski C., Krucewicz K., Meier S., Hägglund P., Svensson B., Palcic M.M. Functional and structural characterization of plastidic starch phosphorylase during barley endosperm development. PLoS One 2017;12(4):e0175488. doi:10.1371/journal.pone
^ Abt M.R., Pfister B., Sharma M., Eicke S., Bürgy L., Neale I., Seung D., Zeeman S.C. STARCH SYNTHASE5, a noncanonical starch synthase-like protein, promotes starch granule initiation in Arabidopsis. Plant Cell 2020;32(8):2543-2565. doi:10.1105/tpc.19.00946
^ Seung D., Boudet J., Monroe J., Schreier T.B., David L.C., Abt M., Lu K.J., Zanella M., Zeeman S.C. Homologs of PROTEIN TARGETING TO STARCH control starch granule initiation in Arabidopsis leaves. Plant Cell 2017;29(7):1657-1677. doi:10.1105/tpc.17.00222
^ abc Tetlow I.J., Bertoft E. A review of starch biosynthesis in relation to the building block-backbone model. Int J Mol Sci 2020;21(19):7011. doi:10.3390/ijms21197011
^ Ziegler G.R., Creek J.A., Runt J. Spherulitic crystallization in starch as a model for starch granule initiation. Biomacromolecules 2005;6(3):1547-54. doi:10.1021/bm049214p
^ Szydlowski N., Ragel P., Raynaud S., Lucas M.M., Roldán I., Montero M., Muñoz F.J., Ovecka M., Bahaji A., Planchot V., Pozueta-Romero J., D’Hulst C., Mérida A. Starch granule initiation in Arabidopsis requires the presence of either class IV or class III starch synthases. Plant Cell 2009;21(8):2443-57. doi:10.1105/tpc.109.066522
^ Leloir L.F., de Fekete M.A., Cardini C.E. Starch and oligosaccharide synthesis from uridine diphosphate glucose. J Biol Chem 1961;236:636-41. doi:10.1016/S0021-9258(18)64280-2
^ Vrinten P.L., Nakamura T. Wheat granule-bound starch synthase I and II are encoded by separate genes that are expressed in different tissues. Plant Physiol 2000;122(1):255-64. doi:10.1104/pp.122.1.255
^ Seung D., Soyk S., Coiro M., Maier B.A., Eicke S., and Zeeman S.C. PROTEIN TARGETING TO STARCH is required for localising GRANULE-BOUND STARCH SYNTHASE to starch granules and for normal amylose synthesis in Arabidopsis. PLoS Biol 2015;13:e1002080. doi:10.1371/journal.pbio.1002080
The concept of the Mediterranean diet was first developed in the 1950s by the American physiologist Ancel Keys. Through the landmark Seven Countries Study, Keys highlighted for the first time the significant health benefits of this dietary pattern on cardiovascular disease (CVD) reductionn.[1][2][3]
Recognized as one of the healthiest models of nutrition, the Mediterranean diet is characterized by a high intake of minimally processed plant foods, such as vegetables, legumes, and whole-grain cereals, with extra virgin olive oil as the main source of fats. Consequently, it is naturally rich in antioxidant compounds and has well-documented anti-inflammatory properties.[4][5]
Subsequent research in both industrialized and non-industrialized populations confirmed its protective role not only against CVD, but also against chronic-degenerative diseases and depressive disorders, while showing positive effects on cognitive performance. Greater adherence to this pattern is consistently associated with better overall health and reduced mortality.[6]
No scientific evidence suggests that the Mediterranean diet is harmful. On the contrary, its reduced reliance on meat consumption supports public health and promotes environmental sustainability by helping lower greenhouse gas emissions.[7][8]
Ultimately, it represents a cultural and nutritional heritage that must be safeguarded, standing in contrast to the global trend toward dietary uniformityy.[9][10]
Summary: Key Points
Origins and research: developed in the 1950s by Ancel Keys, the benefits of the Mediterranean diet were first proven by the landmark “Seven Countries Study.”
Nutritional profile: characterized by a high intake of minimally processed plant foods, with extra virgin olive oil serving as the primary source of healthy fats.
Chronic prevention: scientific evidence confirms its protective role against cardiovascular diseases, cognitive decline, type 2 diabetes, and chronic inflammation.
Global sustainability: beyond personal longevity, its reduced reliance on meat consumption significantly helps lower greenhouse gas emissions compared to industrial diets.
In the early 1950s, Keys identified a correlation between diet and cardiovascular disease risk by comparing the incidence of CVD among American business executives with that of European populations just emerging from World War II. In the former group, composed of well-nourished subjects, the incidence was high, whereas in the latter, affected by food insecurity, it was low. These observations led Keys to hypothesize a correlation between dietary fat intake and deaths from cardiovascular diseases.[11]
Subsequent observations revealed an extremely low incidence of coronary heart disease and certain cancers in the population of Crete, in much of the rest of Greece, and in southern Italy compared with the United States.[3] This led Keys to hypothesize that the diet of these populations, characterized by a low intake of animal fats, was protective, and to launch the long-term observational project known as the Seven Countries Study, the most influential longitudinal study on the Mediterranean diet.
This study demonstrated:
an inverse correlation between diet quality and both overall and cardiovascular mortality;
that saturated fats were the major dietary risk factor;
that adherence to a Mediterranean-type diet reduced the risk of developing cardiovascular diseases.[1][12]
Characteristics of the Mediterranean diet
The Mediterranean diet is characterized by the consumption of large amounts of vegetables, legumes, fruits, cereals (preferably whole grain), and extra virgin olive oil, which provides an abundant supply of fiber, antioxidants, phytosterols, polyphenols and unsaturated fatty acids.[5]
As for animal products, the consumption of meat, especially red meat and processed meat, as well as high-fat dairy should be limited, while fish and seafood should be included regularly. Alcohol consumption should be moderate, primarily in the form of red wine consumed with meals. In the Greek cohort of the EPIC study, extra virgin olive oil, vegetables, legumes, moderate alcohol intake, and low consumption of meat and meat products were identified as the main dietary components associated with reduced mortality.[13][14]
A Bottle of Extra Virgin Olive Oil
A cornerstone of the Mediterranean diet is extra virgin olive oil. It is an excellent source of monounsaturated fatty acids and contains over 2,000 different compounds, many of which have antioxidant activity.
As the main source of dietary fat, and when combined with low consumption of high-fat animal products, it ensures a high ratio of monounsaturated to saturated fatty acids, which improves lipid profiles and glycemic control in people with diabetes.[15][16]
However, it is misleading to focus on a single element of this dietary pattern. There is no “magic bullet”, as shown by studies examining isolated components. People do not consume nutrients individually but as part of a complex whole, and more importantly, these nutrients interact with each other in synergistic or antagonistic ways. Thus, the health benefits of the Mediterranean diet arise from the combined effect of all its components.[17]
The Mediterranean diet and chronic diseases
Since the Seven Countries Study, numerous investigations have demonstrated the effectiveness of this dietary pattern in both primary and secondary prevention of major chronic diseases, from cardiovascular conditions to depressive disorders, as well as in reducing overall mortality.
Here are some examples.
A meta-analysis evaluated the association between adherence to the Mediterranean diet, mortality, and disease incidence, showing that “greater adherence to a Mediterranean diet is significantly associated with a reduced risk of overall mortality, cardiovascular mortality, cancer incidence and mortality, and incidence of Parkinson’s disease”.[4]
A randomized multicenter study demonstrated its efficacy in the primary prevention of cardiovascular events in subjects at high cardiovascular risk.[18][19]
Adherence to the Mediterranean diet has been associated with a lower risk of Alzheimer’s disease, as well as a more favorable course and outcome. Higher adherence is linked to lower mortality, with evidence suggesting a dose–response effect.[20][21][22]
Mounting evidence suggests a protective effect against weight gain.[23][24]
An inverse association has been reported between adherence to this dietary pattern and the incidence of type 2 diabetes, both among initially healthy individuals and among patients who survived myocardial infarction.[25][26]
It is also associated with a lower prevalence of metabolic syndrome.[27][28]
Epidemiological and interventional studies have revealed a protective effect against low-grade chronic inflammation and its metabolic complications.[29][30]
There is also evidence that adherence to the Mediterranean diet may play a protective role in the prevention of depressive disorders.[31][32]
Its role in reducing greenhouse gas emissions
The Mediterranean diet can also improve public health by contributing to the reduction of greenhouse gas emissions, namely carbon dioxide (CO2), methane, nitrous oxide, and similar compounds, originating from the livestock sector, which is responsible for four-fifths of agriculture-related emissions. These emissions exceed those generated by transportation and are second only to those produced by the energy sector.[33][34][35]
Considering that the global population is growing, and that this growth is accompanied by an increase in per capita meat consumption, with estimates predicting an 85% increase in meat production by 2030 compared with 2000, the role of the Mediterranean diet in mitigating greenhouse gas emissions becomes even more evident.[36][37]
Greenhouse gas emission and cattle farming
A detailed analysis of greenhouse gas emissions from cattle farming, the main contributor within the livestock sector, shows the following distribution:
about 40% comes from the loss of annual plants, grasses, and trees that originally covered the land used to grow feed crops;
32% from methane emissions generated by animal waste and by the animals themselves as a result of digestion;
14% from the use of fertilizers to grow feed grain (approximately 16 pounds of grain are required to produce every kilogram of meat consumed);
14% from agricultural production in general.
The table below compares CO2-equivalent emissions from the production of different foods (per 225 g portion) with the distance traveled by a gasoline-powered car consuming 1 liter of fuel every 12 km.
Comparison of CO2-equivalent emissions (g) for 225 g portions of various foods, relative to the distance (km and miles) traveled by a gasoline car (12 km/L fuel consumption)
Foods
CO2 equivalent (g)
Equivalent Distance (km/miles)
Potatoes
59
0.300 (0.17)
Apples
68
0.320 (0.2)
Asparagus
91
0.440 (0.27)
Chicken
249
1.17 (0.73)
Pork
862
4.10 (2.52)
Beef
3360
15.80 (9.81)
This comparison highlights the environmental impact of different food choices. Producing 225 grams of beef releases almost 13 times more greenhouse gases than producing an equal amount of chicken, and 57 times more than producing potatoes.
To put this into perspective, producing the 41 kilograms of beef consumed annually by the average American releases the same amount of CO2 as a gasoline car traveling approximately 3,000 kilometers.[38][39][40][41]
The Mediterranean diet is a proven path to health and longevity. Beyond personal wellness, it stands as a sustainable model, showing that what’s good for us is also good for the planet.
References
^ ab Keys A., Aravanis C., Blackburn H., et al. Seven Countries: A Multivariate Analysis of Death and Coronary Heart Disease. Harvard University Press, Cambridge, Harvard University Press, ISBN: 0-674-80237-3, 1980. 381 pp.
^ Keys A. Mediterranean diet and public health: personal reflections. Am J Clin Nutr 1995;61:1321S-1323S doi:10.1093/ajcn/61.6.1321S
^ ab Menotti A., Puddu P.E. Ancel Keys, the Mediterranean diet, and the Seven Countries Study: a review. J Cardiovasc Dev Dis 2025;12(4):141. doi:10.3390/jcdd12040141
^ ab Sofi F., Cesari F., Abbate R., Gensini G.F. and Casini A. Adherence to Mediterranean diet and health status: meta-analysis. BMJ 2008;337:a1344. doi:10.1136/bmj.a1344
^ ab Barbouti A., Goulas V. Dietary antioxidants in the Mediterranean diet. Antioxidants (Basel) 2021;10(8):1213. doi:10.3390/antiox10081213
^ Friel S., Dangour A.D., Garnett T., Lock K., Chalabi Z., Roberts I., Butler A., Butler C.D., Waage J., McMichael A.J. and Haines A. Public health benefits of strategies to reduce greenhouse-gas emissions: food and agriculture. Lancet 2009;374:2016-2025. doi:10.1016/S0140-6736(09)61753-0
^ García S., Bouzas C., Mateos D., et al. Carbon dioxide (CO2) emissions and adherence to Mediterranean diet in an adult population: the Mediterranean diet index as a pollution level index. Environ Health 2023;22(1):1. doi:10.1186/s12940-022-00956-7
^ Nestle M. Mediterranean diets: historical and research overview. Am J Clin Nutr 1995;61:1313S-1320S doi:10.1093/ajcn/61.6.1313S
^ Keys A., Taylor H.L., Blackburn H., Brozek J., Anderson J.T., Simonson E. Coronary heart disease among Minnesota business and professional men followed fifteen years. Circulation 1963;28:381–395. doi:10.1161/01.CIR.28.3.381
^ Menotti A., Lanti M., Kromhout D., Blackburn H. Nissinen A., Dontas A., Kafatos A., Nedeljkovic S., Adachi H. Forty-year coronary mortality trends and changes in major risk factors in the first 10 years of follow-up in the Seven Countries Study. Eur J Epidemiol 2007;22(11):747-54. doi:10.1007/s10654-007-9176-4
^ Trichopoulou A., Costacou T., Bamia C., Trichopoulos D. Adherence to a Mediterranean Diet and Survival in a Greek Population. N Engl J Med 2003;348:2599-2608. doi:10.1056/NEJMoa025039
^ Trichopoulou A., Bamia C. and Trichopoulos D. Anatomy of health effects of Mediterranean diet: Greek EPIC prospective cohort study. BMJ 2009;338:b2337. doi:10.1136/bmj.b2337
^ Covas M.I. Olive oil and the cardiovascular system. Pharmacol Res 2007;55(3):175-86. doi:10.1016/j.phrs.2007.01.010
^ Riolo R., De Rosa R., Simonetta I., Tuttolomondo A. Olive oil in the Mediterranean diet and Its biochemical and molecular effects on cardiovascular health through an analysis of genetics and epigenetics. Int J Mol Sci 2022;23(24):16002. doi:10.3390/ijms232416002
^ Giugliano D., Esposito K. Mediterranean diet and metabolic diseases. Curr Opin Lipidol 2008;19:63-68. doi:10.1097/MOL.0b013e3282f2fa4d
^ Estruch R., Ros E., Salas-Salvadó J., et al. Primary prevention of cardiovascular disease with a Mediterranean Diet. N Engl J Med 2013;368:1279-1290. doi:10.1056/NEJMoa1200303
^ Laffond A., Rivera-Picón C., Rodríguez-Muñoz P.M., Juárez-Vela R., Ruiz de Viñaspre-Hernández R., Navas-Echazarreta N., Sánchez-González J.L. Mediterranean det for primary and secondary prevention of cardiovascular disease and mortality: an updated systematic review. Nutrients 2023;15(15):3356. doi:10.3390/nu15153356
^ Scarmeas N., Luchsinger J.A., Mayeux R. and Stern Y. Mediterranean diet and Alzheimer disease mortality. Neurology 2007;69(11):1084-1093 doi:10.1212/01.wnl.0000277320.50685.7c
^ Morris M.C., Tangney C.C., Wang Y., Sacks F.M., Bennett D.A., Aggarwal N.T. MIND diet associated with reduced incidence of Alzheimer’s disease. Alzheimers Dement 2015;11(9):1007-14. doi:10.1016/j.jalz.2014.11.009
^ Vaziri Y. The Mediterranean diet: a powerful defense against Alzheimer disease – A comprehensive review. Clin Nutr ESPEN 2024;64:160-167. doi:10.1016/j.clnesp.2024.09.020
^ Schröder H. Protective mechanisms of the Mediterranean diet in obesity and type 2 diabetes. J Nutr Biochem 2007;18:149-60. doi:10.1016/j.jnutbio.2006.05.006
^ Lotfi K., Saneei P., Hajhashemy Z., Esmaillzadeh A. Adherence to the Mediterranean diet, five-year weight change, and risk of overweight and obesity: a systematic review and dose-response meta-analysis of prospective cohort studies. Adv Nutr 2022;13(1):152-166. doi:10.1093/advances/nmab092
^ Martínez-González M.Á., de la Fuente-Arrillaga C., Nunez-Cordoba J.M., Basterra-Gortari F.J., Beunza J.J., Vazquez Z., Benito S., Tortosa A., Bes-Rastrollo M. Adherence to Mediterranean diet and risk of developing diabetes: prospective cohort study. BMJ 2008;336:1348-1351. doi:10.1136/bmj.39561.501007.BE
^ Martín-Peláez S., Fito M., Castaner O. Mediterranean diet effects on type 2 diabetes prevention, disease progression, and related mechanisms. A review. Nutrients 2020;12(8):2236. doi:10.3390/nu12082236
^ Kastorini C.M., Milionis H.J., Esposito K., Giugliano D., Goudevenos J.A., Panagiotakos D.B. The effect of Mediterranean diet on metabolic syndrome and its components: a meta-analysis of 50 studies and 534,906 individuals. J Am Coll Cardiol 2011;57(11):1299-313. doi:10.1016/j.jacc.2010.09.073
^ Dayi T, Ozgoren M. Effects of the Mediterranean diet on the components of metabolic syndrome. J Prev Med Hyg 2022;63(2 Suppl 3):E56-E64. doi:10.15167/2421-4248/jpmh2022.63.2S3.2747
^ Casas R., Sacanella E., Urpí-Sardà M., et al. The effects of the mediterranean diet on biomarkers of vascular wall inflammation and plaque vulnerability in subjects with high risk for cardiovascular disease. A randomized trial. PLoS One 2014;9(6):e100084. doi:10.1371/journal.pone.0100084
^ Bonaccio M., Pounis G., Cerletti C., Donati M.B., Iacoviello L., de Gaetano G; MOLI-SANI Study Investigators. Mediterranean diet, dietary polyphenols and low grade inflammation: results from the MOLI-SANI study. Br J Clin Pharmacol 2017;83(1):107-113. doi:10.1111/bcp.12924
^ Sánchez-Villegas A., Delgado-Rodríguez M., Alonso A., Schlatter J., Lahortiga F., Serra Majem L., Martínez-González M.A. Association of the Mediterranean Dietary pattern with the incidence of depression: The Seguimiento Universidad de Navarra/University of Navarra Follow-up (SUN) Cohort. Arch Gen Psychiatry 2009;66:1090-1098 doi:10.1001/archgenpsychiatry.2009.129
^ Bizzozero-Peroni B., Martínez-Vizcaíno V., Fernández-Rodríguez R., Jiménez-López E., Núñez de Arenas-Arroyo S., Saz-Lara A., Díaz-Goñi V., Mesas A.E. The impact of the Mediterranean diet on alleviating depressive symptoms in adults: a systematic review and meta-analysis of randomized controlled trials. Nutr Rev 2025;83(1):29-39. doi:10.1093/nutrit/nuad176
^ Willett W., Rockström J., Loken B., et al. Food in the Anthropocene: the EAT-Lancet Commission on healthy diets from sustainable food systems. Lancet 2019;393(10170):447-492. doi:10.1016/S0140-6736(18)31788-4
^ Koliaki C.C., Katsilambros N.L., Dimosthenopoulos C. The Mediterranean diet in the era of climate change: a reference diet for human and planetary health. Climate 2024 12(9):136. doi:10.3390/cli12090136
^ Kristiansen S., Painter J., Shea M. Animal agriculture and climate change in the US and UK elite media: volume, responsibilities, rauses and solutions. Environ Commun 2021;15(2):153-172. doi:10.1080/17524032.2020.1805344
^ FAO. Livestock’s long shadow: environmental issues and options. Rome: Food and Agriculture Organization of the United Nations. 2006. https://www.fao.org/4/a0701e/a0701e00.htm
^ Font-I-Furnols M. Meat consumption, sustainability and alternatives: an overview of motives and barriers. Foods 2023;12(11):2144. doi:10.3390/foods12112144
^ Opio C., Gerber P., Mottet A., Falcucci A., Tempio G., MacLeod M., Vellinga T., Henderson B., Steinfeld H. Greenhouse gas emissions from ruminant supply chains – A global life cycle assessment. Food and Agriculture Organization of the United Nations (FAO), Rome. 2013. https://www.fao.org/4/i3461e/i3461e.pdf
^ Poore J., Nemecek T. Reducing food’s environmental impacts through producers and consumers. Science 2018;360(6392):987-992. doi:10.1126/science.aaq0216
^ Nugrahaeningtyas E., Lee J.S., Park K.H. Greenhouse gas emissions from livestock: sources, estimation, and mitigation. J Anim Sci Technol 2024;66(6):1083-1098. doi:10.5187/jast.2024.e86
Amylose is a polysaccharide composed of α-D-glucose units linked by α-(1→4) glycosidic bonds, with a few branches connected to the main chain by α-(1→6) glycosidic bonds.[1]
Together with amylopectin, it is one of the two main constituents of starch, the major storage form of energy and carbohydrates in the biosphere.[2][3]
Its synthesis is catalyzed by the enzyme granule-bound starch synthase (GBSS; EC 2.4.1.242) and requires the presence of a second protein, known as protein targeting to starch 1 (PTST1), which has no catalytic activity.[4]
Within the starch granule, amylose is embedded in the semi-crystalline matrix formed by amylopectin.[5] Unlike amylopectin, amylose is not essential for the formation of starch granules, is present in smaller amounts, but exerts a strong influence on the physicochemical properties of starch.[6][7]
Plant varieties have been developed whose starch granules contain either negligible amounts or, conversely, very high amounts of amylose. These phenotypes have both industrial applications and potential health benefits.[8][9][10]
Summary: Key Points
Molecular structure: amylose is a predominantly linear polysaccharide composed of α-D-glucose units linked by α-(1→4) glycosidic bonds, featuring a few sparse α-(1→6) branches.
Biosynthesis: synthesized inside plastids by the processive enzyme GBSS, its granule-binding mechanism strictly requires the non-catalytic accessory protein PTST1.
Physicochemical properties: unlike amylopectin, the amylose ratio drives starch behavior, directly dictating gelling strength, gelatinization temperature, and retrogradation rates.
Health and nutrition: high-amylose starches function as resistant starch, evading small intestine digestion to undergo colonic fermentation, producing health-promoting short-chain fatty acids (SCFAs).
Amylose molecules have a molecular weight of about 106 daltons. They are mostly linear and composed of α-D-glucose units (hereinafter referred to as glucose) linked by α-(1→4) glycosidic bonds, that is, covalent bonds between the C-1 atom of one unit and the hydroxyl group on the C-4 atom of the next unit.[11] The linear chains are composed of several hundred to several thousand monosaccharides; therefore, they are much longer than amylopectin chains.[1]
Molecular Differences Between Starch Components: Amylopectin and Amylose
The few branches are connected to the linear chain by α-(1→6) glycosidic bonds, as in amylopectin and glycogen, the storage form of carbohydrates in animals. An α-(1→6) glycosidic bond is a covalent bond between the C-1 atom of one unit and the hydroxyl group on the C-6 atom of another glucose unit. The number of branches ranges from 5 to 20, depending on the botanical origin of the starch. Unlike those of amylopectin, the branches are not clustered.[12][13]
Bimodal distribution
Studies on the length of amylose branches have shown a bimodal distribution, with two fractions linked to specific interspecies genetic variations and termed:
AM1, comprising shorter chains, with a degree of polymerization between 100 and 700 glucose units;
AM2, comprising longer chains, with a degree of polymerization between 700 and 40,000 glucose units.[14]
Classification and structural characteristics of amylose fractions
Comprises significantly longer chains; intraspecies variation is relatively small.
A similar bimodal distribution of branch length is also observed in amylopectin, whose fractions are termed AP1 (shorter and more abundant) and AP2. The intraspecies variation in the distribution of AM1 and AM2 fractions is relatively small, whereas the variation among different species is considerable and has a genetic basis.[14]
Amylose location in starch granules
The precise location of amylose within starch granules is not fully known, although it is generally believed to be concentrated in the amorphous regions. However, some studies suggest that its distribution is not limited to these regions, but that amylose can also be found interspersed between amylopectin chains and on the surface of the granules. Thus, amylose may occupy multiple locations within the granule.[5][15]
Synthesis
In plants, the synthesis of amylose is catalyzed by GBSS, one of the six isoforms of starch synthase.[16] This enzyme, whose activity is the major determinant of amylose content in starch granules, requires the presence of the PTST1 protein.[4] Amylose branching appears to be carried out by the starch branching enzyme (SBE; EC 2.4.1.18).[17]
As in the case of amylopectin biosynthesis, it is believed that the enzymes involved physically interact to form multienzyme complexes, which optimize the efficiency of the process.[1] Because amylose synthesis requires a pre-existing amylopectin matrix to target GBSS to the starch granules, the synthesis of the two polysaccharides is not entirely simultaneous.[16]
Priming and initiation of amylose synthesis
In the initial steps, GBSS, like other starch synthases, requires short malto-oligosaccharides (MOS), α-(1→4) glucans with a degree of polymerization of 2 to 7, which act as primers for chain elongation.[17] MOS can originate from various sources, such as the trimming of nascent amylopectin molecules by starch debranching enzymes, or the activity of starch phosphorylase (EC 2.4.1.1), another enzyme involved in starch metabolism.[18] Because MOS are poorly soluble in water, they appear able to evade the hydrolytic activity of α-amylase (EC 3.2.1.1) and β-amylase (EC 3.2.1.2), and diffuse within the starch granule matrix, where they are elongated by GBSS.[19] Once malto-oligosaccharides are elongated beyond seven glucose residues, they can no longer diffuse out of the granule and are further extended in situ.[20]
Since a primer is required, the early stages of amylose and amylopectin biosynthesis resemble those of glycogen. However, in glycogen synthesis the primer is the self-glucosylating protein glycogenin.[21]
Importantly, the polymerization of glucose into amylopectin, amylose, glycogen, and, more generally, the conversion of osmotically active monosaccharides into osmotically inactive polysaccharides, enables the storage of large amounts of carbohydrate within the cell without increasing osmotic pressure.[21][22]
Granule-bound starch synthase
GBSS, together with the other isoforms of starch synthase and starch phosphorylase, belongs to the glycosyltransferase family (EC 2.4).[16]
GBSS was discovered by Louis Federico Leloir’s group, which had previously identified the main pathway for galactose, known as the Leloir pathway. It is the most abundant protein associated with starch granules.[23] Unlike the other isoforms of starch synthase, which are mostly located in the plastid stroma or partitioned between starch granules and the stroma, GBSS is found almost exclusively bound to granules. Protease treatment of the starch granule surface has shown that most GBSS is located within the granule rather than on its surface, a position consistent with amylose synthesis inside nascent granules.[4]
In grasses, GBSS is present in two isoforms encoded by distinct genes. These isoforms are:
GBSSI, present in the amyloplasts of storage tissues (non-photosynthetic tissues);
GBSSII, present in chloroplasts (photosynthetic tissues), where it participates in the synthesis of transient starch.[24]
GBSS catalyzes the transfer of a glucose residue from ADP-glucose to the non-reducing end of an α-(1→4)-glucan, forming a new α-(1→4) glycosidic bond.[21][25]
Notably, starch synthases use ADP-glucose as the glucosyl donor, whereas glycogen synthase, the enzyme responsible for glycogen synthesis, uses UDP-glucose.[22][26]
Granule-bound starch synthase can add more than one glucose monomer per substrate encounter, a processive mode of action. This contrasts with the other isoforms of starch synthase, which add only a single glucose unit per encounter, a distributive mode of action. The processive activity of GBSS enables the biosynthesis of long linear chains and appears to be strongly enhanced by the presence of amylopectin.[1]
PTST1
Amylose synthesis requires the presence of a protein from the PTST family, namely PTST1, which was discovered more than fifty years after GBSS.
PTST1 has no catalytic activity but enables the binding of GBSS to the starch granule. This function appears to be more important in chloroplasts, and therefore in the synthesis of transient starch, than in amyloplasts.
It has been proposed that PTST1 associates with GBSS in the plastid stroma. The complex then binds to the nascent starch granule, after which PTST1 dissociates, allowing GBSS to initiate amylose synthesis. PTST1 subsequently returns to the plastid stroma to recruit another GBSS molecule. The importance of PTST1 is highlighted by its conservation throughout the plant kingdom. Loss of PTST1 causes GBSS to detach from the nascent starch granule, thereby preventing amylose synthesis.[4][19]
Starch branching enzymes
The enzyme responsible for generating the few α-(1→6) linkages present in amylose molecules is not definitively known, although an isoform of starch branching enzyme, SBEI, may be involved.[5]
SBEI is located primarily in the plastid stroma, with only a small proportion bound to starch granules, and is mainly expressed in storage tissues. The low frequency of branching in amylose may result from its biosynthesis inside the granules, where SBEI is scarce, thereby protecting the nascent molecule from the enzyme’s action.[27]
Amylose/amylopectin ratio
In the starch granules of land plants, amylose is almost always present in variable amounts, generally between 5% and 35%. Variability occurs not only among species but also within the same species, depending on the organ or tissue examined. In tubers and seeds, the amylose content also varies with the stage of development: it is generally low in the early stages and increases until the final value is reached, a pattern consistent with the synthesis of amylose within an amylopectin matrix.[5][25]
However, some plants have starch with very low, or even no, amylose content. This type of starch is referred to as waxy starch, owing to the raw endosperm’s appearance, which resembles wax. Conversely, certain plants produce starch granules composed mostly, or even entirely, of amylose.[9]
Classification and physicochemical properties of starch phenotypes
Starch phenotype
Amylose content
Physicochemical behavior
Nutritional impact and applications
Waxy starch
Negligible or zero (≤ 5%)
Wax-like appearance, high peak viscosity, and very low retrogradation tendency.
Utilized in food and manufacturing industries where structural stability is required.
Standard starch
Between 5% and 35%
Balanced profile between water absorption, gelatinization, and recrystallization (pasting).
Major storage form of energy; exhibits standard susceptibility to amylase hydrolysis.
High-amylose starch
Elevated (> 35% up to 85%)
High gelling strength, rapid retrogradation, and excellent film-forming ability.
Rich in resistant starch; lowers the glycemic index and promotes colonic SCFA production.
Although its precise role is not yet fully understood, the near-constant presence of amylose suggests that this polysaccharide plays an important structural role in starch granules and confers some advantage to plants during growth and development.[5]
Physicochemical properties
The amylose/amylopectin ratio strongly influences the physicochemical properties of starch. For example, it affects water absorption, which in turn influences processes such as starch retrogradation and gelatinization, as well as resistance to enzymatic hydrolysis. This determines, for instance, the rate at which maltose and maltotriose are released during starch degradation by α-amylase or β-amylase.[28] These properties, in turn, influence both the industrial applications of starch and its effects on human health.[10]
High-amylose starches
High-amylose cereals can be obtained by enhancing GBSSI gene expression or by suppressing or eliminating the genes encoding starch branching enzymes, SSIIa, or other enzymes and proteins involved in amylopectin biosynthesis. However, in cereal endosperm, the most effective method is the suppression or elimination of one or more starch branching enzyme isoforms.[9]
High-amylose starches exhibit distinctive physicochemical properties, such as high gelling strength, easy retrogradation, and excellent film-forming ability. These properties make them suitable for industrial applications, including the production of biodegradable plastics, paper, and adhesives.[6][28]
High-amylose starches also contain elevated levels of resistant starch, a form of starch that escapes digestion in the small intestine by α-amylase, one of the key hydrolases involved in carbohydrate digestion. Studies with resistant starch–enriched foods have shown improvements in insulin sensitivity and glycemic response, as well as a reduced risk of cardiovascular disease, obesity, and type II diabetes mellitus.[29]
Mechanism of action
Resistant starch, by escaping intestinal digestion, lowers the glycemic index of foods in which it is present, thereby helping regulate blood glucose levels. Once it reaches the colon, it is fermented by the gut microbiota, which is part of the human microbiota, producing short-chain fatty acids (mainly butyric acid, acetic acid, and propionic acid), which play an essential role in maintaining intestinal health.[30][31]
References
^ abcd Tetlow I.J., Bertoft E. A review of starch biosynthesis in relation to the building block-backbone model. Int J Mol Sci 2020;21(19):7011. doi:10.3390/ijms21197011
^ Qu J., Xu S., Zhang Z., Chen G., Zhong Y., Liu L., Zhang R., Xue J., Guo D. Evolutionary, structural and expression analysis of core genes involved in starch synthesis. Sci Rep 2018;8(1):12736. doi:10.1038/s41598-018-30411-y
^ Apriyanto A., Compart J., Fettke J. A review of starch, a unique biopolymer – Structure, metabolism and in planta modifications. Plant Sci 2022;318:111223. doi:10.1016/j.plantsci.2022.111223
^ abcd Seung D., Soyk S., Coiro M., Maier B.A., Eicke S., Zeeman S.C. PROTEIN TARGETING TO STARCH is required for localising GRANULE-BOUND STARCH SYNTHASE to starch granules and for normal amylose synthesis in Arabidopsis. PLOS Biol 2015;13(2):e1002080. doi:10.1371/journal.pbio.1002080
^ abcde Seung D. Amylose in starch: towards an understanding of biosynthesis, structure and function. New Phytol 2020;228:1490-1504. doi:10.1111/nph.16858
^ ab Jobling S. Improving starch for food and industrial applications. Curr Opin Plant Biol 2004;7(2):210-8. doi:10.1016/j.pbi.2003.12.001
^ Junejo S.A., Flanagan B.M., Zhang B., Dhital S. Starch structure and nutritional functionality – Past revelations and future prospects. Carbohydr Polym 2022;277:118837. doi:10.1016/j.carbpol.2021.118837
^ Funnell-Harris D.L., Sattler S.E., O’Neill P.M., Eskridge K.M., and Pedersen J.F. Effect of waxy (low amylose) on fungal infection of Sorghum grain. Phytopathology 2015;105(6):716-846. doi:10.1094/PHYTO-09-14-0255-R
^ abc Wang J., Hu P., Chen Z., Liu Q., Wei C. Progress in high-amylose cereal crops through inactivation of starch branching enzymes. Front Plant Sci 2017;8:469. doi:10.3389/fpls.2017.00469
^ ab Li H-T., Zhang W., Zhu H, Chao C., Guo Q. Unlocking the potential of high-amylose starch for gut health: not all function the same. Fermentation 2023;9(2):134. doi:https://doi.org/10.3390/fermentation9020134
^ Hizukuri S., Takeda Y., Yasuda M., Suzuki A. Multi-branched nature of amylose and the action of debranching enzymes. Carbohydr Res 1981;94:205-213. doi:10.1016/S0008-6215(00)80718-1
^ Zhiguang C., Haixia Z., Min C., Fayong G., Jing L. The fine structure of starch: a review. NPJ Sci Food 2025;9(1):50. doi:10.1038/s41538-025-00414-x
^ ab Wang K., Hasjim J., Wu A.C., Henry R.J., Gilbert R.G. Variation in amylose fine structure of starches from different botanical sources. J Agric Food Chem 2014;62(19):4443-53. doi:10.1021/jf5011676
^ Teobaldi A.G., Carrillo Parra E.J., Barrera G.N., Ribotta P.D. The properties of damaged starch granules: the relationship between granule structure and water–starch polymer interactions. Foods 2025;14(1):21. doi:https://doi.org/10.3390/foods14010021
^ abc Pfister B., Zeeman S.C. Formation of starch in plant cells. Cell Mol Life Sci 2016;73(14):2781-807. doi:10.1007/s00018-016-2250-x
^ Tetlow I.J., Emes M.J. A review of starch-branching enzymes and their role in amylopectin biosynthesis. IUBMB Life 2014;66(8):546-58. doi:10.1002/iub.1297
^ Szydlowski N., Ragel P., Raynaud S., Lucas M.M., Roldán I., Montero M., Muñoz F.J., Ovecka M., Bahaji A., Planchot V., Pozueta-Romero J., D’Hulst C., Mérida A. Starch granule initiation in Arabidopsis requires the presence of either class IV or class III starch synthases. Plant Cell 2009;21(8):2443-57. doi:10.1105/tpc.109.066522
^ ab Seung D., Boudet J., Monroe J., Schreier T.B., David L.C., Abt M., Lu K.J., Zanella M., Zeeman S.C. Homologs of PROTEIN TARGETING TO STARCH control starch granule initiation in Arabidopsis leaves. Plant Cell 2017;29(7):1657-1677. doi:10.1105/tpc.17.00222
^ Denyer K., Johnson P., Zeeman S., Smith A.M. The control of amylose synthesis. J Plant Physiol 2001;158: 479-487. doi:10.1078/0176-1617-00360
^ abc Nelson D.L., Cox M.M. Lehninger. Principles of biochemistry. 8th Edition. W.H. Freeman and Company, 2021.
^ ab Heldt H-W. Plant biochemistry – 4th Edition. Elsevier Academic Press, 2010.
^ Leloir L.F., de Fekete M.A., Cardini C.E. Starch and oligosaccharide synthesis from uridine diphosphate glucose. J Biol Chem 1961;236:636-41. doi:10.1016/S0021-9258(18)64280-2
^ Vrinten P.L., Nakamura T. Wheat granule-bound starch synthase I and II are encoded by separate genes that are expressed in different tissues. Plant Physiol 2000;122(1):255-64. doi:10.1104/pp.122.1.255
^ ab Gous P.W., Fox G.P. Review: amylopectin synthesis and hydrolysis – Understanding isoamylase and limit dextrinase and their impact on starch structure on barley (Hordeum vulgare) quality. Trends Food Sci Technol 2016;62:23-32. doi:10.1016/j.tifs.2016.11.013
^ Crofts N., Abe N., Oitome N.F., Matsushima R., Hayashi M., Tetlow I.J., Emes M.J., Nakamura Y., Fujita N. Amylopectin biosynthetic enzymes from developing rice seed form enzymatically active protein complexes. J Exp Bot 2015;66(15):4469-82. doi:10.1093/jxb/erv212
^ Kram A.M., Oostergetel G.T., Van Bruggen E. Localization of branching enzyme in potato tuber cells with the use of immunoelectron microscopy. Plant Physiol 1993;101(1):237-243. doi:10.1104/pp.101.1.237
^ ab Magallanes-Cruz P.A., Flores-Silva P.C., Bello-Perez L.A. Starch structure influences its digestibility: a review. J Food Sci 2017;82(9):2016-2023. doi:10.1111/1750-3841.13809
^ Birt D.F., Boylston T., Hendrich S., Jane J.L., Hollis J., Li L., McClelland J., Moore S., Phillips G.J., Rowling M., Schalinske K., Scott M.P., Whitley E.M. Resistant starch: promise for improving human health. Adv Nutr 2013;4(6):587-601. doi:10.3945/an.113.004325
^ Usuda H., Okamoto T., Wada K. Leaky gut: effect of dietary fiber and fats on microbiome and intestinal iarrier. Int J Mol Sci 2021;22(14):7613. doi:10.3390/ijms22147613
^ Topping D.L., Clifton P.M. Short-chain fatty acids and human colonic function: roles of resistant starch and nonstarch polysaccharides. Physiol Rev 2001;81(3):1031-64. doi:10.1152/physrev.2001.81.3.1031
The Leloir pathway is the primary route for galactose metabolism.
Discovered by Luis F. Leloir and colleagues in 1948, this pathway converts galactose into glucose 1-phosphate. Specifically, it involves the inversion of the configuration of the hydroxyl group at carbon 4 of galactose, one of the monosaccharide’s chiral centers.[1]
The metabolic intermediates involved in this isomerization serve as building blocks in various biosynthetic pathways, such as the glycosylation of proteins and lipids or glycogen synthesis. Their role depends on the developmental stage, the cell’s metabolic state, and the tissue type.[2]
With the exception of the first step, the reactions in the Leloir pathway are reversible, proceeding in either direction depending on substrate concentrations and the tissue’s metabolic needs. This enables the interconversion of galactose and glucose.[3]
The importance of the Leloir pathway, and of galactose itself, is highlighted by its high degree of evolutionary conservation, from bacteria to plants and animals.[4] In humans, its relevance is further underscored by the severe consequences of mutations in the genes encoding its enzymes, which lead to the inherited metabolic disorder known as galactosemia.[5]
Summary: Key Points
Primary function: The Leloir pathway is the essential metabolic route that converts dietary galactose into glucose 1-phosphate, making it available for energy production or glycogen storage.
Cellular trapping and irreversibility: The galactokinase reaction is the only irreversible step; it adds a negative charge to galactose, effectively preventing it from diffusing out of the cell.
Biochemical flexibility: Except for the second step, the reactions are fully reversible, enabling cells to interconvert sugar nucleotides based on developmental stages and specific tissue needs.
Clinical relevance: Inherited mutations in the pathway’s genes cause galactosemia. The resulting accumulation of galactitol triggers osmotic and oxidative stress, leading to early cataract formation.
Galactose, along with glucose and fructose, is one of the monosaccharides that can be absorbed in the intestine. The main dietary source of galactose is lactose, which, together with maltose, trehalose and sucrose, is one of the disaccharides commonly found in food.
Since there are no transporters for disaccharides, their glycosidic bonds are hydrolyzed in the final stage of carbohydrate digestion, releasing their constituent monosaccharides. In the case of lactose, these are glucose and galactose.[6]
The monosaccharides are then absorbed and transported via the portal circulation to the liver, the primary site of galactose metabolism. The liver absorbs most of the galactose (approximately 88%) through facilitated passive diffusion mediated by the GLUT2 transporter.[7]
The small remaining amount of circulating galactose reaches other organs and tissues, such as the mammary gland, which during lactation uses galactose for lactose synthesis and for the glycosylation of milk proteins and lipids.[4]
The steps of the Leloir pathway
The Leloir pathway consists of four enzymatic reactions, catalyzed respectively by:
galactose mutarotase (also known as aldose 1-epimerase; EC 5.1.3.3);
Detailed Schematic Representation of the Leloir Pathway
Step 1: galactose mutarotase
The hydrolysis of the β-(1→4) glycosidic bond in lactose results in the release of glucose and β-D-galactose.
Galactokinase, the enzyme responsible for the second step of the Leloir pathway, is specific for the α-anomer of galactose.[8] Therefore, the β-anomer must first be converted into the α-anomer. This conversion is catalyzed by galactose mutarotase.
In addition to galactose, this enzyme is also capable of interconverting the α- and β-anomeric forms of other sugars, including glucose, xylulose, maltose, and lactose, although with varying degrees of efficiency.[9]
Step 2: galactokinase
In the second step, α-D-galactose is phosphorylated to galactose 1-phosphate in a reaction catalyzed by galactokinase.[8] Phosphorylation of galactose, like that of glucose to glucose 6-phosphate, is metabolically important for several reasons.
Galactose 1-phosphate cannot diffuse out of the cell because it carries a negative charge, and there are no transporters for phosphorylated sugars in the plasma membrane.[10]
Phosphorylation increases the energy content of the monosaccharide, initiating destabilization and facilitating its subsequent metabolism.[11]
By converting galactose into galactose 1-phosphate, the reaction lowers the intracellular concentration of free galactose, promoting its continued uptake via facilitated transport.[10]
The reaction catalyzed by galactokinase represents the irreversible step of the Leloir pathway.[3] Unlike hexokinase and glucokinase (EC 2.7.1.1), which phosphorylate the hydroxyl group at carbon 6 of glucose, galactokinase and fructokinase (EC 2.7.1.4) phosphorylate the hydroxyl group at carbon 1 of galactose and fructose, respectively.[12]
The conversion of galactose 1-phosphate to glucose-1-phosphate requires two additional reactions: the third and fourth steps of the Leloir pathway.
Step 3: galactose 1-phosphate uridylyltransferase
In the third step, galactose 1-phosphate uridylyltransferase catalyzes the transfer of a uridine monophosphate (UMP) group from UDP-glucose to galactose 1-phosphate, yielding UDP-galactose and glucose 1-phosphate.
The reaction follows a ping-pong (double displacement) mechanism, involving the formation of a covalent intermediate between the enzyme and the UMP group.[10]
Step 4: UDP-galactose 4-epimerase
In the final step, UDP-galactose is converted into UDP-glucose in a reaction catalyzed by UDP-galactose 4-epimerase. This enzyme inverts the configuration of the hydroxyl group at carbon 4 and is responsible for the interconversion between UDP-galactose and UDP-glucose, and, by extension, between galactose and glucose.[13]
UDP-galactose 4-epimerase requires NAD+ as a cofactor, and the reaction proceeds through the formation of a ketonic intermediate at C4, accompanied by the reduction of NAD+ to NADH. The sugar then rotates within the active site, exposing the opposite face to NADH, which transfers a hydride ion back to carbon 4, but in the reversed configuration.[14]
Because NAD+ is first reduced and then re-oxidized, there is no net redox change for the coenzyme, which therefore does not appear in the overall reaction equation.
UDP-galactose 4-epimerase is thought to be the rate-limiting enzyme of the Leloir pathway.[4]
The UDP-glucose produced in this reaction is subsequently recycled by UDP-glucose pyrophosphorylase, releasing glucose 1-phosphate.[2]
In mammals, UDP-galactose 4-epimerase also catalyzes the interconversion between UDP-N-acetylgalactosamine and UDP-N-acetylglucosamine.[15]
It is important to note that UDP-galactose and UDP-glucose, like galactose and glucose in general, have the same molecular formula. They differ only in the configuration of the hydroxyl group at carbon 4, making them stereoisomers, and more specifically, epimers, a form of optical isomerism.
Role of the Leloir pathway
The Leloir pathway enables cells to utilize galactose or its derivative, glucose, in various metabolic pathways, both anabolic and catabolic, depending on the metabolic state of the cell or tissue.
Because the reaction catalyzed by UDP-galactose 4-epimerase is reversible, the conversion of glucose into galactose (and its nucleotide derivatives) is also possible.[2]
UDP-galactose can be used in:
the glycosylation of proteins and lipids, such as the formation of galactocerebrosides, which are major glycolipid components of myelin. For this reason, galactose was initially referred to as cerebrose;[4][16]
the lactating mammary gland, where it is used for lactose synthesis in a reaction catalyzed by the lactose synthase system.[17]
Furthermore, since the UDP-galactose 4-epimerase reaction is reversible, glucose, once activated to UDP-glucose by UDP-glucose pyrophosphorylase (EC 2.7.7.9), can be converted to UDP-galactose for lactose production.[18]
In the liver and skeletal muscle, UDP-glucose derived from UDP-galactose can be used:[3]
for protein and lipid glycosylation;
in glycogen synthesis, especially when the cell’s energy demand is low. Compared to glucose and fructose, galactose is preferentially incorporated into hepatic glycogen rather than entering oxidative pathways;
after conversion to glucose 1-phosphate (via UDP-glucose pyrophosphorylase), and subsequent isomerization to glucose 6-phosphate (via phosphoglucomutase, EC 5.4.2.2), it may enter various metabolic routes, including glycolysis, the pentose phosphate pathway or gluconeogenesis.[4]
Note: UDP-galactose, discovered during studies on the Leloir pathway, was the first nucleotide sugar to be identified.[19]
Leloir pathway and galactosemia
Glycosylations are post-translational modifications that play a crucial role in enabling and regulating a wide range of biological processes. Defects in glycosylation have been associated with numerous pathological conditions, including cancer, diabetes, and congenital metabolic disorders, particularly the congenital disorders of glycosylation (CDGs), which are primarily autosomal recessive monogenic conditions.[20] Among these, galactosemia is a well-known disorder, first described by von Reuss A. in 1908.[21] Galactosemia results from mutations in one of the genes encoding the enzymes of the Leloir pathway, and four clinical types have been identified.
Type I: due to galactose-1-phosphate uridylyltransferase deficiency. This is the most common and severe form and is referred to as classic galactosemia.[22]
Type III: due to UDP-galactose 4-epimerase deficiency.[24]
Type IV: due to galactose mutarotase deficiency.[25]
At present, the standard treatment for all forms of galactosemia consists of a galactose-restricted diet, aimed at preventing the toxic accumulation of galactose or its metabolites.[26]
Galactosemia and cataracts
The accumulation of galactose activates alternative metabolic pathways, including the synthesis of galactitol and galactonate.
One of the early clinical manifestations of galactosemia is the development of cataracts, typically within the first two years of life. In the most severe cases, the disease may also lead to brain, liver, and kidney damage.[9]
One proposed mechanism underlying cataract formation involves the reduction of galactose, accumulated in the lens, to galactitol in a reaction catalyzed by aldose reductase (EC 1.1.1.21).[27] Galactitol is poorly metabolized and does not readily diffuse across cell membranes due to its low lipophilicity. As an osmotically active compound, it increases intracellular osmotic pressure, leading to a net influx of water into the lens cells.[28]
Moreover, its synthesis consumes NADPH, potentially depleting cellular NADPH pools and impairing the activity of glutathione reductase (EC 1.8.1.7). This reduction in antioxidant capacity may contribute to the accumulation of free radicals.[29]
The combined effects of osmotic stress and oxidative damage can ultimately compromise cell integrity, resulting in cell death and the formation of lens opacities. Additionally, galactitol has been reported to act as an inhibitor of galactose mutarotase, which may exacerbate galactose accumulation by further hindering its metabolism.[30]
References
^ Leloir L.F., de Fekete M.A., Cardini C.E. Starch and oligosaccharide synthesis from uridine diphosphate glucose. J Biol Chem 1961;236:636-41. doi:10.1016/S0021-9258(18)64280-2
^ abc Frey P.A. The Leloir pathway: a mechanistic imperative for three enzymes to change the stereochemical configuration of a single carbon in galactose. FASEB J 1996;10(4):461-70. doi:10.1096/fasebj.10.4.8647345
^ abc Conte F., van Buuringen N., Voermans N.C., Lefeber D.J. Galactose in human metabolism, glycosylation and congenital metabolic diseases: time for a closer look. Biochim Biophys Acta Gen Subj 2021;1865(8):129898. doi:10.1016/j.bbagen.2021.129898
^ abcde Coelho A.I., Berry G.T., Rubio-Gozalbo M.E. Galactose metabolism and health. Curr Opin Clin Nutr Metab Care 2015;18(4):422-427. doi:10.1097/MCO.0000000000000189
^ Petry K.G., Reichardt J.K. The fundamental importance of human galactose metabolism: lessons from genetics and biochemistry. Trends Genet 1998;14(3):98-102. doi:10.1016/s0168-9525(97)01379-6
^ Coelho A.I., Rubio-Gozalbo M.E., Vicente J.B., Rivera I. Sweet and sour: an update on classic galactosemia. J Inherit Metab Dis 2017;40(3):325-342. doi:10.1007/s10545-017-0029-3
^ abc Holden H.M., Rayment I., Thoden J.B. Structure and function of enzymes of the Leloir pathway for galactose metabolism. J Biol Chem 2003;278(45):43885-43888. doi:10.1074/jbc.R300025200
^ ab Thoden J.B., Timson D.J., Reece R.J., and M. Holden H.M. Molecular structure of human galactose mutarotase. J Biol Chem 2004;279(22):23431-23437. doi:10.1074/jbc.M402347200
^ Berg J.M., Tymoczko J.L., Gatto J.G., Stryer L. Biochemistry. 9th Edition. W.H. Freeman and Company, 2019.
^ Rosenthal M.D., Glew R.H. Medical Biochemistry – Human Metabolism in Health and Disease. John Wiley J. & Sons, Inc., 2009.
^ Thoden J.B., Holden H.M. Dramatic differences in the binding of UDP-galactose and UDP-glucose to UDP-galactose 4-epimerase from Escherichia coli. Biochemistry 1998;37(33):11469-77. doi:10.1021/bi9808969
^ Thoden J.B., Wohlers T.M., Fridovich-Keil J.L., Holden H.M. Human UDP-galactose 4-epimerase. Accommodation of UDP-N-acetylglucosamine within the active site. J Biol Chem 2001;276(18):15131-6. doi:10.1074/jbc.M100220200
^ Helenius A., Aebi M. Intracellular functions of N-linked glycans. Science 2001;291(5512):2364-9. doi:10.1126/science.291.5512.2364
^ Lin Y., Sun X., Hou X., Qu B., Gao X., Li Q. Effects of glucose on lactose synthesis in mammary epithelial cells from dairy cow. BMC Vet Res 2016;12:81. doi:10.1186/s12917-016-0704-x
^ Sunehag A., Tigas S., Haymond M.W. Contribution of plasma galactose and glucose to milk lactose synthesis during galactose ingestion. J Clin Endocrinol Metab 2003;88(1):225-9. doi:10.1210/jc.2002-020768
^ Cardini C.E., Paladini A.C., Caputto R., Leloir L.F. Uridine diphosphate glucose: the coenzyme of the galactose-glucose phosphate isomerization. Nature 1950;165:191-192. doi:10.1038/165191a0
^ Los E., Ford G.A. Galactose-1-phosphate uridyltransferase deficiency. [Updated 2023 Jul 17]. In: StatPearls [Internet]. Treasure Island (FL): StatPearls Publishing; 2025 Jan-. Available from: https://www.ncbi.nlm.nih.gov/books/NBK441957/
^ Ramani P.K., Arya K. Galactokinase deficiency. [Updated 2023 Jul 31]. In: StatPearls [Internet]. Treasure Island (FL): StatPearls Publishing; 2025 Jan-. Available from: https://www.ncbi.nlm.nih.gov/books/NBK560683/
^ Fridovich-Keil J., Bean L., He M., et al. Epimerase deficiency galactosemia. 2011 Jan 25 [Updated 2021 Mar 4]. In: Adam MP, Feldman J, Mirzaa GM, et al., editors. GeneReviews® [Internet]. Seattle (WA): University of Washington, Seattle; 1993-2025. Available from: https://www.ncbi.nlm.nih.gov/books/NBK51671/
^ Wada Y., Kikuchi A., Arai-Ichinoi N., Sakamoto O., Takezawa Y., Iwasawa S., Niihori T., Nyuzuki H., Nakajima Y., Ogawa E., Ishige M., Hirai H., Sasai H., Fujiki R., Shirota M., Funayama R., Yamamoto M., Ito T., Ohara O., Nakayama K., Aoki Y., Koshiba S., Fukao T., Kure S. Biallelic GALM pathogenic variants cause a novel type of galactosemia. Genet Med 2019;21(6):1286-1294. doi:10.1038/s41436-018-0340-x
^ Succoio M., Sacchettini R., Rossi A., Parenti G., Ruoppolo M. Galactosemia: biochemistry, molecular genetics, newborn screening, and treatment. Biomolecules 2022;12(7):968. doi:10.3390/biom12070968
^ Pintor J. Sugars, the crystalline lens and the development of cataracts. Biochem Pharmacol 2012;1:4. doi:10.4172/2167-0501.1000e119
^ Tsakiris S., Marinou K., Schulpis K. H. The in vitro effects of galactose and its derivatives on rat brain Mg2+-ATPase activity. Pharmacol Toxicol 2022;91:254-257. doi:10.1034/j.1600-0773.2002.910506.x
^ Lai K., Elsas L.J., Wierenga K.J. Galactose toxicity in animals. IUBMB Life 2009;61(11):1063-74. doi:10.1002/iub.262
^ Keston A.S. Inhibition of action of lens mutarotase on glucose by cataractogenic sugars and corresponding polyols. Arch Biochem Biophys 1963;102(2):306-312. doi:10.1016/0003-9861(63)90184-X
In 1906, Russian-American chemist Martin André Rosanoff, then working at New York University, selected glyceraldehyde, a simple monosaccharide, as the standard for designating the stereochemistry of molecules with at least one chiral center, such as carbohydrates. This nomenclature system became known as the Fischer-Rosanoff convention (or simply the D-L system).[1]
Summary: Key Points:
Relative configuration: the Fischer-Rosanoff convention (D-L system) determines the relative spatial orientation of carbohydrates and amino acids using glyceraldehyde as an arbitrary standard.
Optical independence: there is no direct correlation between the D/L stereochemical prefixes (configuration) and the (+)/(–) signs indicating the direction of optical rotation.
Assignment rules: the classification is determined by the asymmetric carbon farthest from the carbonyl group in monosaccharides, and by the asymmetric α-carbon in amino acids.
Structural limitations: the system specifies only the geometry of the reference carbon; ambiguities in molecules with multiple chiral centers were resolved in 1956 by the RS absolute nomenclature.
Fischer-Rosanoff convention: origin and application
Since the absolute configuration of glyceraldehyde was unknown at the time, Rosanoff assigned the stereochemistry in an entirely arbitrary way:
The D prefix (from the Latin dexter, meaning “right”) was assigned to (+)-glyceraldehyde, the dextrorotatory enantiomer, assuming that, in its Fischer projection, the hydroxyl group (–OH) was on the right side of the chiral center.
The L prefix (from the Latin laevus, meaning “left”) was assigned to (−)-glyceraldehyde, the levorotatory enantiomer, assuming the hydroxyl group was on the left side of the chiral center.[2]
Fischer Projections of D- and L-Glyceraldehyde Enantiomers
Although Emil Fischer himself rejected this system, it was widely adopted for determining the relative configurations of chiral molecules. This was achieved by chemically converting a molecule into a derivative of glyceraldehyde using reactions that retain the configuration, meaning no bonds to the chiral center are broken; the spatial arrangement around the chiral center is preserved.[3]
The Fischer-Rosanoff convention allows chemists to classify chiral molecules, such as amino acids and monosaccharides, into two categories: the D series and the L series, depending on whether their configuration corresponds to that of D- or L-glyceraldehyde.
Note: there is no direct correlation between configuration (D or L) and the direction of optical rotation. The D–L system does not indicate whether a molecule is dextrorotatory or levorotatory; it only relates molecular configuration to that of glyceraldehyde.[4]
Fischer-Rosanoff convention: carbohydrates
Monosaccharides can be classified as either aldoses or ketoses. Aldoses, and ketoses with more than three carbon atoms, have at least one chiral center. By convention, they are assigned to the D or L series depending on the configuration of the chiral carbon farthest from the carbonyl group (the carbon with the highest oxidation state, from which numbering begins). If this configuration matches that of D-glyceraldehyde or L-glyceraldehyde, the molecule is placed in the corresponding D or L series.
Determination of D- or L-Series in Monosaccharides
In Fischer projections, the longest carbon chain is drawn vertically, and the carbon atoms are numbered so that the carbonyl carbon receives the lowest possible number: C-1 in aldoses and C-2 in ketoses.[5]
Note: in nature, D-sugars are far more common than L-sugars.
When it is necessary to specify the optical rotation of a monosaccharide, the prefixes (+) or (–) can be added to the D or L designation. For example, fructose, which is levorotatory, can be written as D-(–)-fructose, whereas glucose, which is dextrorotatory, can be written as D-(+)-glucose.
Fischer-Rosanoff convention: α-amino acids
Amino acids can be classified based on the position of the amino group (–NH2) relative to the carboxyl group (–COOH):
α-amino acids: the amino group is attached to the α-carbon;
β-amino acids: the amino group is attached to the β-carbon;
γ-amino acids: the amino group is attached to the γ-carbon;
δ-amino acids: the amino group is attached to the δ-carbon.
Correlation of the Spatial Arrangement Around the Asymmetric α-Carbon of α-Amino Acids to the Standard Configurations of D- and L-Glyceraldehyde
α-Amino acids are assigned to the D or L series based on the configuration of the four groups attached to the α-carbon, the chiral center: –NH2, –COOH, –R, and –H. If their spatial arrangement matches that of the hydroxyl, aldehyde (–CHO), hydroxymethyl (–CH2OH), and hydrogen atoms in D- or L-glyceraldehyde, the amino acid belongs to the corresponding series.[4]
In Fischer projections, amino acids are represented with the carboxyl group, the carbon with the highest oxidation state, at the top, and the R group at the bottom.
Among α-amino acids, the proteinogenic amino acids (those involved in protein synthesis), with the exception of glycine, whose α-carbon is not chiral, all exhibit the L configuration, and are thus known as L-α-amino acids.
Note: in nature, L-α-amino acids are significantly more abundant than other types of amino acids, which do not participate in protein synthesis.[5]
Relative and absolute configurations
When Rosanoff arbitrarily assigned the D prefix to (+)-glyceraldehyde and the L prefix to (–)-glyceraldehyde, he had a 50/50 chance of being correct.[6]
In the early 1950s, the development of X-ray diffraction analysis made it possible to determine the absolute configuration of chiral molecules. In 1951, Dutch chemist Johannes Martin Bijvoet established the absolute configuration of sodium rubidium (+)-tartrate tetrahydrate. By comparing it with glyceraldehyde, he demonstrated that Rosanoff’s assumption was correct.
As a result, the configurations of chiral compounds previously assigned relative to glyceraldehyde turned out to match their true absolute configurations, thereby converting these relative configurations into absolute ones.[7]
Ambiguities of the Fischer-Rosanoff convention
The Fischer-Rosanoff convention can lead to ambiguities when applied to molecules with more than one chiral center. For example, in D-(+)-glucose, the D–L system provides information only about the configuration at C-2, but gives no indication regarding the other chiral centers, namely C-3, C-4, and C-5.[3]
Structural Limitations of the Fischer-Rosanoff Convention
In such cases, the RS system, developed in 1956 by Robert Sidney Cahn, Christopher Ingold, and Vladimir Prelog, offers a more precise description by assigning a configuration to each chiral center individually. For instance, D-(+)-glucose has the configuration (2R,3S,4R,5R).[5][8]
It should also be noted that the D or L designation depends on which chiral center is chosen as the reference point. Consequently, the same molecule can sometimes be classified as either D or L, depending on the structural context.
References
^ Rosanoff M.A. On Fischer’s classification of stereo-isomers. J Am Chem Soc 1906:28(1);114-121. doi:10.1021/ja01967a014
^ IUPAC. Compendium of Chemical Terminology, 2nd ed. (the “Gold Book”). Compiled by A. D. McNaught and A. Wilkinson. Blackwell Scientific Publications, Oxford (1997). Online version (2019-) created by S. J. Chalk. ISBN 0-9678550-9-8. doi:10.1351/goldbook
^ ab Nelson D.L., Cox M.M. Lehninger. Principles of biochemistry. 8th Edition. W.H. Freeman and Company, 2021.
^ abc Heilman D., Woski S., Voet D., Voet J.G., Pratt C.W. Fundamentals of biochemistry: life at the molecular level. 6th Edition. Wiley, 2023.
^ Moran L.A., Horton H.R., Scrimgeour K.G., Perry M.D. Principles of Biochemistry. 5th Edition. Pearson, 2012.
^ Bijvoet J.M., Peerdeman A.F., Van Bommel A.J. Determination of the absolute configuration of optically active compounds by means of X-rays. Nature 1951;168(4268):271. doi:10.1038/168271a0
^ Cahn R.S., Ingold C., Prelog V. Specification of molecular chirality. Angew Chem 1966:5(4); 385-415. doi:10.1002/anie.196603851
In 1891, Hermann Emil Fischer, a German chemist and Nobel Laureate in Chemistry (1902), developed a systematic method for the two-dimensional representation of molecules with chiral centers (also known as chirality centers): the so-called Fischer projections, or Fischer projection formulas.[1]
Although they are two-dimensional representations, Fischer projections preserve important information about the stereochemistry of molecules.[2] While they do not reflect the actual three-dimensional shape of molecules in solution, they are still widely used by biochemists to define the stereochemistry of amino acids, carbohydrates, nucleic acids, terpenes, steroids, and other biologically relevant molecules.[3]
Summary: Key Points:
Two-dimensional representation: developed by Emil Fischer in 1891, they project the 3D structure of a chiral molecule onto a cross-shaped plane while preserving essential stereochemical information.
Bond geometry: by convention, horizontal lines represent bonds pointing forward (toward the observer), whereas vertical lines represent bonds pointing backward (behind the plane).
Rotation rules: the stereocenter configuration remains unchanged only when the projection is rotated by 180° in-plane; rotations of 90° or 270° invert the configuration into its mirror-image enantiomer.
Group manipulation: performing an even number of swaps between chemical groups preserves the original configuration, while an odd number of exchanges inverts the stereocenter.
To draw a Fischer projection of a molecule with a single chiral center (e.g., a carbon atom), the tetrahedral structure is rotated so that two groups point downward and two groups point upward. Next, draw a cross, place the chiral carbon at the intersection, and arrange the molecule so that the groups pointing downward (i.e., behind the plane of the paper) are attached to the ends of the vertical line, while the groups pointing upward (i.e., projecting out of the plane of the paper) are attached to the ends of the horizontal line.[4]
Drawing a Fischer Projection
For compounds with more than one chiral center, the same procedure is applied to each asymmetric center.
A Fischer projection can also be converted into a three-dimensional representation, such as a wedge-and-dash (perspective) formula, in which the two horizontal bonds are shown as solid wedges, and the vertical bonds as dashed lines.[5]
How to manipulate Fischer projection formulas
Since Fischer projections represent three-dimensional molecules on a two-dimensional plane, certain rules must be followed to preserve the correct configuration.[2]
The projection must not be lifted out of the plane of the paper, as doing so would convert one enantiomer into its mirror image (the other enantiomer).
If you rotate the projection within the plane of the paper, the configuration remains unchanged only when rotated by 180° in either direction. This is because the vertical bonds are oriented behind the plane of the paper, while the horizontal bonds project out of the plane. Conversely, a rotation of 90° or 270° in either direction inverts the configuration and converts the enantiomer into its mirror image.
Finally, performing an odd number of exchanges between any two groups around the chiral center also results in the conversion of one enantiomer into the other.[5]
Manipulation Rules for Fischer Projection Formulas
In 1956, Robert Sidney Cahn, Christopher Ingold, and Vladimir Prelog developed a nomenclature system which, based on a few simple rules, allows for the assignment of the absolute configuration of each chiral center in a molecule.[1][2]
This nomenclature system, called the RS system or the Cahn–Ingold–Prelog (CIP) system, when combined with the IUPAC nomenclature, makes it possible to name chiral molecules accurately and unambiguously, even when more than one asymmetric center is present.[3]
In most cases, chiral molecules can rotate plane-polarized light when it passes through a solution containing them. In this regard, it should be emphasized that the sign of the rotation of plane-polarized light caused by a chiral compound provides no information about the RS configuration of its chiral centers.
The Fischer–Rosanoff convention is another way to describe the configuration of chiral molecules.[4] However, compared with the RS system, it labels the molecule as a whole rather than each individual chiral center and is often ambiguous for molecules with two or more chiral centers.[5]
Summary: Key Points
Definition: a nomenclature system used to assign the absolute configuration of chiral centers in a molecule.
Priority rules: a set of three rules used to determine the R or S configuration based on the atomic number of bonded atoms, the sequence of successive atoms, and the presence of multiple bonds.
Biochemical context: allows the unambiguous classification of molecules with one or more chiral centers, such as amino acids and monosaccharides.
Optical activity independence: the RS configuration is a structural descriptor and does not predict the direction in which a molecule rotates plane-polarized light (+/−).
The RS system assigns a priority sequence to the groups attached to a chiral center. By tracing a curved arrow from the highest-priority group to the lowest-priority group (with the lowest-priority group pointing away from the observer), each chiral center is labeled as either R or S.[6][7]
First rule
A priority sequence is assigned to the groups based on the atomic number of the atoms directly bonded to the chiral center.
The atom with the highest atomic number is given the highest priority, while the atom with the lowest atomic number is given the lowest priority.
For example, if an oxygen atom (O, atomic number 8), a carbon atom (C, atomic number 6), a chlorine atom (Cl, atomic number 17), and a bromine atom (Br, atomic number 35) are attached to the chiral center, the priority order is:
Br > Cl > O > C
For isotopes, the atom with the higher atomic mass is assigned the higher priority.[8]
Second rule
When different groups are attached to a chiral center through identical atoms, the priority sequence is determined by examining the atomic numbers of the next set of atoms bonded, moving outward from the chiral center until the first point of difference is found.
For example, consider the following groups attached to a chiral center: –CH3, –CH2CH3 and –CH2OH. All of these have a carbon atom directly bonded to the chiral center. To determine their hierarchy, the atoms bonded to each of these carbons are examined:
methyl group (–CH3): H, H, H
ethyl group (–CH2CH3): H, H, C
hydroxymethyl group (–CH2OH): H, H, O
Priority Rules of the RS System: the Second Rule
Since oxygen has a higher atomic number than carbon, and carbon has a higher atomic number than hydrogen, the order of priority is:
–CH2OH > –CH2CH3 > –CH3
A typical priority order for common substituents is:
Note: 2H and 1H refer to the isotopes deuterium and protium, respectively.
It is important to note that if two or more groups attached to a chiral center have identical priority, the center is not chiral.
Determining clockwise and counterclockwise orientation
Once the priority sequence has been established, the molecule is oriented so that the group with the lowest priority points away from the observer, behind the chiral center. A circular arrow is then traced from the highest-priority group through the second and third highest.
If the arrow moves in a clockwise direction, the configuration is R (from the Latin rectus, meaning “right”).
If the arrow moves in a counterclockwise direction, the configuration is S (from the Latin sinister, meaning “left”).[8]
Clockwise Tracing of Substituents at a Chiral Center
Third rule
The third rule of the RS system is used to determine the configuration of a chiral center when one or more of the attached groups contain double or triple bonds.
To assign priorities correctly in such cases, atoms involved in double or triple bonds are treated as if they were duplicated or triplicated, respectively.
Third Priority Rule of the RS System
In the case of a C=Y double bond, the carbon is considered to be bonded to two Y atoms, and the Y atom is considered to be bonded to two carbon atoms.
In the case of a C≡Y triple bond, the carbon is treated as being bonded to three Y atoms, and the Y atom as being bonded to three carbon atoms.[8]
RS system and molecules with multiple chiral centers
When two or more chiral centers are present in a molecule, each center is analyzed independently using the rules previously described.
Consider 2,3-butanediol. This molecule contains two chiral centers, carbon 2 and carbon 3, and exists as three stereoisomers: two enantiomers and one meso compound. What is the RS configuration of the chiral centers in the enantiomer shown in the figure?
RS System Assignment of Absolute Configuration to 2,3-Butanediol
Let us analyze carbon 2. The order of priority of the attached groups is:
–OH > –CH(OH)CH3 > –CH3 > –H
(Here, –CH(OH)CH3 represents the portion of the molecule extending toward carbon 3.)
The molecule is then rotated so that the hydrogen, the group with the lowest priority, points away from the observer (i.e., behind the chiral center). A path is traced from –OH (highest priority) to –CH3. This path moves in a clockwise direction, so the configuration at carbon 2 is R.
Applying the same procedure to carbon 3, its configuration is also found to be R.
Therefore, the enantiomer shown in the figure is (2R,3R)-2,3-butanediol.
Amino acids and glyceraldehyde
In the Fischer–Rosanoff convention, all proteinogenic amino acids are classified as L-amino acids. In the RS system, with the exception of glycine, which is not chiral, and cysteine, which, due to the presence of a thiol group, is classified as (R)-cysteine, all other proteinogenic amino acids are (S)-amino acids.
Threonine and isoleucine each have two chiral centers: the α-carbon and an additional carbon atom in the side chain. Both exist as three stereoisomers: two enantiomers and one meso compound. The naturally occurring forms found in proteins are:
(2S,3R)-threonine;
(2S,3S)-isoleucine.
These correspond, in the Fischer–Rosanoff convention, to L-threonine and L-isoleucine, respectively.
In the RS system, L-glyceraldehyde is classified as (S)-glyceraldehyde; accordingly, D-glyceraldehyde is classified as (R)-glyceraldehyde.[9]
References
^ Cahn R.S., Ingold C., Prelog V. Specification of molecular chirality. Angew Chem 1966:5(4); 385-415. doi:10.1002/anie.196603851
^ Prelog V. and Helmchen G. Basic principles of the CIP‐system and proposals for a revision. Angew Chem 1982:21(8);567-583. doi:10.1002/anie.198205671
^ IUPAC. Compendium of chemical terminology, 2nd ed. (the “Gold Book”). Compiled by A. D. McNaught and A. Wilkinson. Blackwell Scientific Publications, Oxford (1997). Online version (2019-) created by S. J. Chalk. ISBN 0-9678550-9-8. doi:10.1351/goldbook
^ Rosanoff M.A. On Fischer’s classification of stereo-isomers. J Am Chem Soc 1906:28(1);114-121. doi:10.1021/ja01967a014
^ Heilman D., Woski S., Voet D., Voet J.G., Pratt C.W. Fundamentals of biochemistry: life at the molecular level. 6th Edition. Wiley, 2023.
Chirality is the geometric property of a group of points or atoms in space, or of a solid object, of not being superimposable on its mirror image.[1] These structures, defined as chiral, have the peculiar characteristic of lacking second-order symmetry elements, namely a plane of symmetry, a center of inversion, or a rotation-reflection axis.[2]
The term chirality, from the Greek cheir meaning “hand”, was coined by Lord Kelvin, who introduced it during the “Baltimore Lectures”, a series of talks held at Johns Hopkins University in Baltimore, starting on October 1st, 1884, and published twenty years later, in 1904.[3]
The world is rich in chiral objects: your hands are the prime example, but many others exist, from the shell of a snail to a spiral galaxy. In chemistry, especially in organic chemistry, chirality is a property of primary importance, because molecules such as carbohydrates, many amino acids, and numerous drugs are chiral.[4]
Chiral molecules can exist in two forms: mirror images of each other that are non-superimposable. In other words, no combination of rotations or translations in the plane of the sheet can align them perfectly. These molecules are called enantiomers, from the Greek enántios, meaning “opposite”, and meros, meaning “part”.[5]
The most common cause of chirality in a molecule is the presence of a chiral center or chirality center, also called an asymmetric center, an atom bonded to a set of atoms or functional groups arranged in space such that the resulting molecule can exist as two enantiomers.
Enantiomers are a type of stereoisomers, which can be defined as isomers that have the same number and types of atoms and bonds, but differ in the spatial orientation of those atoms.[2]
Two enantiomers of a chiral molecule, being non-superimposable, are distinct compounds. But how do they differ?
Each pair of enantiomers has identical physical and chemical properties with respect to achiral characteristics, such as melting point, boiling point, refractive index, infrared spectrum, solubility in the same solvent, and reaction rate with achiral reagents.
The differences emerge when enantiomers interact with chemical or physical phenomena that possess chirality.
From a chemical point of view, two enantiomers can be distinguished by how they interact with chiral structures, such as the binding site of a chiral receptor or the active site of a chiral enzyme.
From a physical point of view, they differ in their interaction with plane-polarized light, which exhibits chiral properties, in other words, they display optical activity.[6]
Chirality and optical activity
The optical activity of materials such as quartz and, more importantly, of organic compounds such as sugars or tartaric acid, was discovered in 1815 by the French scientist Jean-Baptiste Biot.[7]
Chiral molecules can be classified based on the direction in which plane-polarized light is rotated, from the observer’s point of view, when it passes through a solution containing them.
If a solution containing one enantiomer rotates plane-polarized light in a clockwise direction, the molecule is called dextrorotatory or dextrorotary, from the Latin dexter, meaning “right”, and is designated by the prefixes (+)- or d-, from dextro-.
If the solution rotates plane-polarized light in a counterclockwise direction, the molecule is called levorotatory or levorotary, from the Latin laevus, meaning “left”, and is designated by the prefixes (–)- or l-, from laevo-.[8]
Obviously, if we consider a pair of enantiomers, one is dextrorotatory and the other levorotatory.
Currently, it is not possible to reliably predict the magnitude, direction, or sign of the optical rotation caused by an enantiomer. Conversely, the optical activity of a molecule provides no information about the spatial arrangement of the chemical groups attached to its chirality center.
Note: a system containing molecules that all have the same chirality (i.e., the same “handedness”) is called enantiomerically pure or enantiopure.[9]
Pasteur and the discovery of enantiomers
In 1848, thirty-three years after Biot’s work, studies on the optical activity of molecules led Louis Pasteur, who had been a student of Biot, to observe that, following the recrystallization of a concentrated aqueous solution of sodium ammonium tartrate (which was optically inactive), two types of crystals precipitated that were non-superimposable mirror images of each other.[10]
After separating them with tweezers, Pasteur discovered that the solutions obtained by dissolving equimolar amounts of the two types of crystals were optically active. Interestingly, the rotation angle of plane-polarized light was equal in magnitude but opposite in direction.
Since the differences in optical activity were due to the dissolved sodium ammonium tartrate crystals, Pasteur hypothesized that the molecules themselves must also be non-superimposable mirror images of each other, just like the crystals. These were what we now call enantiomers.[11]
It was Pasteur who first used the term asymmetry to describe this property, which would later be termed chirality by Lord Kelvin.[12]
Racemic mixtures
A solution containing equal amounts of each member of a pair of enantiomers is called a racemic mixture or racemate. These solutions are optically inactive: there is no net rotation of plane-polarized light, since the quantities of dextrorotatory and levorotatory molecules are exactly the same.[13]
Unlike what occurs in biochemical processes, the chemical synthesis of chiral molecules that does not involve chiral reactants, or is not followed by enantiomer separation methods, inevitably leads to the production of a racemic mixture.[9] Pharmaceutical chemistry is among the fields most affected by this. As previously mentioned, two enantiomers are distinct compounds. Many chiral drugs are synthesized as racemic mixtures; however, the desired pharmacological activity often resides in only one enantiomer, called the eutomer, while the other, known as the distomer, is less active or inactive.[14]
An example is ibuprofen, an arylpropionic acid derivative and anti-inflammatory drug: only the S-enantiomer, named according to the nomenclature system called RS system, exhibits pharmacological activity.
Arylpropionic acid derivatives are commonly sold as racemic mixtures. A racemase enzyme in the liver converts the distomer into the eutomer.[15]
However, in some cases, the distomer may cause harmful effects and must therefore be removed from the racemic mixture. A tragic example is thalidomide, a sedative and anti-nausea drug sold as a racemic mixture from the 1950s until 1961, and also taken during pregnancy.
The distomer, the S-enantiomer, was found to cause serious birth defects, particularly phocomelia (malformation of limbs). This remains one of the most striking examples of the importance of the chiral properties of molecules, and it prompted health organizations to encourage the pharmaceutical industry to develop drugs, thalidomide included, containing only a single enantiomer.[16]
Chirality centers
Any tetrahedral atom bearing four different substituents can function as a chirality center.
The classic example is the carbon atom, but other group IVA elements in the periodic table, such as the semimetals silicon and germanium, also adopt tetrahedral geometry and can serve as chiral centers.[2]
Another notable example is the phosphorus atom in organic phosphate esters: when it adopts a tetrahedral arrangement and is bonded to four different substituents, it too becomes a chirality center.[4]
The nitrogen atom in a tertiary amine, an amine in which nitrogen is bonded to three different groups, can also be a chiral center. In such compounds, nitrogen occupies the center of a tetrahedron, with its four sp3 hybrid orbitals directed toward the vertices: three are occupied by substituents, while the fourth contains a nonbonding electron pair.
At room temperature, however, nitrogen undergoes rapid inversion of configuration. This process, known as nitrogen inversion, involves a fast oscillation in which the nitrogen atom passes through a planar, sp2 hybridized transition state. As a result, if the nitrogen atom is the only chirality center in a molecule, the compound exhibits no optical activity, because it effectively exists as a racemic mixture.Nitrogen inversion does not occur only in specific cases, such as when nitrogen is part of a cyclic structure that prevents this motion. Therefore, the mere presence of a chirality center may not always be sufficient to allow for the isolation or resolution of enantiomers.[4]
Note: in 1874, Jacobus Henricus van ‘t Hoff and Joseph Achille Le Bel, building on Pasteur’s work, were the first to propose the theory of the tetrahedral carbon atom. For this pioneering contribution, van ‘t Hoff was awarded the first Nobel Prize in Chemistry in 1901.[17]
Chirality in the absence of a chiral center
Chirality can also arise in the absence of a traditional chiral center, often due to the restricted rotation around certain bonds, typically a double bond or a hindered single bond.[18] This phenomenon is observed in cases such as:
allene derivatives: organic compounds containing two cumulated double bonds, i.e., two double bonds located on the same carbon atom;[19]
biphenyl derivatives: compounds consisting of two aromatic rings connected by a single bond that cannot freely rotate due to steric hindrance from substituents.[20]
In such cases, chirality results from the presence of an axis of chirality rather than a center. This form of chirality is known as axial chirality.[21]
Meso compounds
Meso compounds are stereoisomers that contain two or more chiral centers but are superimposable on their mirror image. As such, they are achiral and therefore optically inactive. A defining feature of meso compounds is the presence of an internal mirror plane that bisects the molecule, with each half being the mirror image of the other.[8]
Meso compounds are classified as diastereomers, meaning stereoisomers that are not enantiomers.
For a molecule with n chirality centers, the maximum number of possible stereoisomers is 2n.[2]
Consider 2,3-butanediol, which contains two chirality centers, specifically at carbon atoms 2 and 3. According to the formula, there are 22 = 4 possible stereoisomers, whose structures are depicted in the accompanying figure as Fischer projections, labeled A, B, C, and D.
Structures A and B are non-superimposable mirror images of each other, and thus constitute a pair of enantiomers.
Structures C and D are also mirror images of each other, but they are superimposable. In fact, if either structure is rotated by 180 degrees, it aligns perfectly with the other. Therefore, C and D are not enantiomers; they are the same compound in different orientations.
Furthermore, these structures possess an internal mirror plane that divides the molecule into two symmetric halves, each a mirror image of the other. Structure C (or D) is therefore a meso compound: it contains chiral centers, is superimposable on its mirror image, and has an internal plane of symmetry that results in two mirror-image halves.[2]
References
^ Chirality, in IUPAC Compendium of Chemical Terminology, 5th ed. International Union of Pure and Applied Chemistry; 2025. Online version 5.0.0, 2025. doi:10.1351/goldbook.C01058
^ abcde Solomons T.W.G., Fryhle C.B., Snyder S.A. Solomons’ organic chemistry. 12th Edition. John Wiley & Sons Incorporated, 2017.
^ abc Morsch L., Farmer S., Cunningham K., Sharrett Z., Shea K.M. Organic Chemistry II. Open Educational Resources: Textbooks, Smith College, Northampton, MA, 2023. https://scholarworks.smith.edu/textbooks/6
^ Enantiomer, in IUPAC Compendium of Chemical Terminology, 5th ed. International Union of Pure and Applied Chemistry; 2025. Online version 5.0.0, 2025. doi:10.1351/goldbook.E02069
^ Gogoi A., Konwer S., Zhuo G.Y. Polarimetric measurements of surface chirality based on linear and nonlinear light scattering. Front Chem 2021;8:611833. doi:10.3389/fchem.2020.611833
^ Flack H.D. Louis Pasteur’s discovery of molecular chirality and spontaneous resolution in 1848, together with a complete review of his crystallographic and chemical work. Acta Crystallogr A 2009;65(Pt 5):371-89. doi:10.1107/S0108767309024088
^ ab Ariëns E.J. Stereochemistry: a source of problems in medicinal chemistry. Med Res Rev 1986;6(4):451-66. doi:10.1002/med.2610060404
^ Vantomme G., Crassous J. Pasteur and chirality: a story of how serendipity favors the prepared minds. Chirality 2021;33(10):597-601. doi:10.1002/chir.23349
^ Geison G.L. The private science of Louis Pasteur. Princeton University Press, 2014.
^ Pasteur L. Memoires sur la relation qui peut exister entre la forme crystalline et al composition chimique, et sur la cause de la polarization rotatoire. C R Acad Sci 1848;26:535‐538.
^ Racemate, in IUPAC Compendium of Chemical Terminology, 5th ed. International Union of Pure and Applied Chemistry; 2025. Online version 5.0.0, 2025. 10.1351/goldbook.R05025
^ Tamatam R., Shin D. Asymmetric synthesis of US-FDA approved drugs over five years (2016-2020): a recapitulation of chirality. Pharmaceuticals (Basel) 2023;16(3):339. doi:10.3390/ph16030339
^ Evans A.M., Nation R.L., Sansom L.N., Bochner F., Somogyi A.A. The relationship between the pharmacokinetics of ibuprofen enantiomers and the dose of racemic ibuprofen in humans. Biopharm Drug Dispos 1990;11(6):507-18. doi:10.1002/bdd.2510110605
^ Tokunaga E., Yamamoto T., Ito E., Shibata N. Understanding the thalidomide chirality in biological processes by the self-disproportionation of enantiomers. Sci Rep 2018;8(1):17131. doi:10.1038/s41598-018-35457-6
^ Capozziello S., Lattanzi A. Geometrical approach to central molecular chirality: a chirality selection rule. Chirality 2003;15:227-230. doi:10.1002/chir.10191
^ Ōki M. The chemistry of rotational isomers. New York: Springer; 1993.
^ Runge W. The chemistry of the allenes. Vol. 2, Landor S R: Academic Press; 1982.
^ Axial chirality, in IUPAC Compendium of Chemical Terminology, 5th ed. International Union of Pure and Applied Chemistry; 2025. Online version 5.0.0, 2025. doi:10.1351/goldbook.A00547
The phenomenon whereby two or more different chemical compounds share the same molecular formula is called isomerism, from the Greek isos meaning “equal” and meros meaning “part.” The concept and term were introduced by the Swedish scientist Jacob Berzelius in 1830.[1]
Isomerism arises from the fact that the atoms within a molecular formula can be arranged in different ways to form compounds, called isomers, that differ in their physical and chemical properties.
There are two main types of isomerism: structural isomerism and stereoisomerism, each of which can be further divided into subtypes.[2]
Tree Diagram Illustrating the General Classification of Isomerism
Summary: Key Points
Definition and origin: introduced by Berzelius in 1830, isomerism describes different chemical compounds that share the same molecular formula but display unique atomic arrangements and properties.
Structural isomerism: also known as constitutional isomerism, it occurs when isomers differ in their actual atom connectivity and bonding sequences, such as chain, position, or functional group variations.
Stereoisomerism: compounds share identical bonding sequences but differ entirely in their 3D spatial orientation; it is subdivided into conformational (single-bond rotations) and configurational isomerism.
Enantiomers and cis-trans forms: configurational subtypes include optical enantiomers (non-superimposable mirror images that rotate polarized light) and geometric cis–trans isomers (restricted by rigid bonds or rings).
In structural isomerism, also known as constitutional isomerism, isomers differ in the way the constituent atoms are connected to each other, both in bonding sequences and atom arrangement.[3]
Several subtypes of structural isomerism exist: positional isomerism, functional group isomerism, and chain isomerism.
Positional isomers
Molecular Structures of Dibromobenzene Positional Isomers
In positional isomerism, also called position isomerism, isomers contain the same functional groups but located at different positions along the same carbon chain.[2]
An example is the compound with molecular formula C6H4Br2, which has three isomers: 1,2-dibromobenzene, 1,3-dibromobenzene, and 1,4-dibromobenzene. These isomers differ in the position of the bromine atoms on the aromatic ring.
Another example is the compound with molecular formula C3H8O, which has two isomers: 1-propanol (also known as n-propyl alcohol) and 2-propanol (isopropyl alcohol). These differ in the position of the hydroxyl group (–OH) on the carbon chain.
Functional group isomers
Functional group isomerism, also known as functional isomerism, occurs when compounds with the same molecular formula contain different functional groups.[2]
An example is the compound with molecular formula C2H6O, which has two isomers: dimethyl ether and ethanol (also called ethyl alcohol). These isomers differ in their functional groups: an ether group (–O–) in dimethyl ether, and a hydroxyl group (–OH) in ethanol.
Chain isomers
In chain isomerism, isomers differ in the arrangement of the carbon skeleton, which may be either straight or branched.[2]
An example is the compound with the molecular formula C5H12, which has three isomers: n-pentane, 2-methylbutane (also known as isopentane), and 2,2-dimethylpropane (neopentane).
Molecular Structure Diagrams of Pentane Chain Isomers
Chain isomerism also occurs in lipids. For instance, among short-chain fatty acids, butyric acid and isobutyric acid (C4H8O2) are chain isomers, as are valeric acid, isovaleric acid, and 2-methylbutyric acid, which share the molecular formula C5H10O2.
Stereoisomerism
In stereoisomerism, isomers have the same number and types of atoms and the same bonding sequence, but differ in the spatial orientation of their atoms. Such compounds are called stereoisomers, from the Greek stereos, meaning “solid”.[4]
There are two subtypes of stereoisomerism: conformational isomerism and configurational isomerism. The latter can be further subdivided into optical isomerism and geometrical isomerism.[5]
Conformational isomerism
In conformational isomerism, stereoisomers can be interconverted by rotation around one or more single bonds (σ bonds). These rotations generate different spatial arrangements of atoms that are non-superimposable.[6] The number of possible conformations a molecule can adopt is theoretically unlimited, ranging from the lowest-energy conformation (most stable) to the highest-energy conformation (least stable). Such isomers are called conformers.[7]
For example, consider ethane C2H6. When viewed along the carbon-carbon bond using a Newman projection, the hydrogen atoms of one methyl group can adopt different orientations relative to those of the other methyl group.
Eclipsed conformation: the hydrogen atoms of one methyl group are aligned directly behind those of the other, resulting in dihedral angles of 0°, 120°, 240°, or 360°. This is the highest-energy (and thus least stable) conformation due to increased electron repulsion.
Staggered conformation: the hydrogen atoms of one methyl group are positioned between those of the other, giving dihedral angles of 60°, 180°, or 300°. This is the lowest-energy (most stable) conformation, as repulsions are minimized.
Skew conformation: any intermediate orientation between eclipsed and staggered conformations.
Newman Projections of Ethane Conformers, Showing the Potential Energy Differences Between Staggered, Eclipsed, and Skew Forms
The relative stability of ethane conformers depends on the degree of overlap between the electron pairs in the C–H bonds of the two methyl groups:
in staggered conformations, these electron pairs are as far apart as possible, minimizing repulsion;
in eclipsed conformations, they are as close as possible, leading to increased repulsion.
The potential energy barrier between these conformations is relatively low, about 2.8 kcal/mol (11.7 kJ/mol). At room temperature, molecular kinetic energy ranges from 15 to 20 kcal/mol (62.7–83.6 kJ/mol), which is more than sufficient to overcome this barrier. As a result, free rotation occurs around the C–C bond, and individual conformers cannot be isolated.
Note: the potential energy barrier to rotation around carbon-carbon double bonds is approximately 63 kcal/mol (264 kJ/mol), corresponding to the energy required to break the π bond. This value is about three times higher than the average kinetic energy at room temperature, making free rotation impossible under normal conditions. Only at temperatures above 300 °C do molecules acquire sufficient thermal energy to break the π bond, allowing rotation around the remaining σ bond. This permits interconversion between the trans and cis isomers (see geometric isomerism).[2]
Configurational isomerism
In configurational isomerism, the interconversion between stereoisomers cannot occur through rotation around single (σ) bonds, but instead requires breaking and reforming of covalent bonds. As a result, such interconversion does not occur spontaneously at room temperature.[7]
There are two subtypes of configurational isomerism: optical isomerism and geometrical isomerism.
Optical isomers
Optical isomerism occurs in molecules that contain one or more chiral centers, which are typically tetrahedral atoms bonded to four different substituents. The chiral center is most commonly a carbon atom, but it can also be phosphorus, sulfur, or nitrogen.[6]
Geometric Representation of a Chiral sp3 Carbon Center
Optical isomers lack both a center and a plane of symmetry, are non-superimposable mirror images of each other, and are called enantiomers, from the Greek enántios (opposite) and meros (part). Unlike other isomers, enantiomers have identical physical and chemical properties, with two important exceptions.[8]
Rotation of plane-polarized light.
One enantiomer rotates the plane of polarized light in a clockwise direction and is labeled (+), while its mirror image rotates the plane in a counterclockwise direction by the same angle and is labeled (–). This property gives rise to the term optical isomerism.
Behavior in chiral environments.
Although enantiomers are indistinguishable by most standard analytical techniques, they behave differently in chiral environments, such as the active sites of enzymes, which are themselves chiral.[9]
Note: for a molecule with n chiral centers, the maximum number of possible stereoisomers is 2n.
Geometric isomers
Geometric isomerism, also known as cis-trans isomerism, occurs when atoms cannot freely rotate due to the presence of a rigid structure, such as:
double bonds between atoms (e.g., C=C, C=N, or N=N), where rigidity arises from the π bond;
cyclic structures, where the ring prevents free rotation.[10]
A classic example of geometric isomerism involving a carbon–carbon double bond is stilbene (C14H12), which exists in two isomeric forms. In the cis isomer, the identical phenyl groups are on the same side of the double bond; in the trans isomer, the same groups are on opposite sides.
Geometric Isomerism in Stilbene Molecules
Note: the terms cis and trans derive from Latin: cis meaning “on this side of” and trans meaning “across”.
Geometric isomerism also occurs in cyclic compounds, especially when the ring contains an even number of carbon atoms and substituents are positioned opposite each other (i.e., para-substituted).[5] For example, 1,4-dimethylcyclohexane, a cycloalkane (general formula CnH2n), exists as two stereoisomers: cis-1,4-dimethylcyclohexane and trans-1,4-dimethylcyclohexane.
Representation of the Two Geometric Isomers of 1,4-Dimethylcyclohexane
This type of stereoisomerism cannot occur if either atom involved in the restricted rotation carries two identical substituents. Why? Because converting between the cis and trans forms requires switching the positions of the groups across the rigid structure. If two groups are the same, the resulting molecule after the “switch” is identical to the original, thus, no distinct isomer is formed.[7]
Note: geometric isomers are a subclass of diastereomers, which are stereoisomers that are not mirror images of each other. Other types of diastereomers include meso compounds and non-enantiomeric optical isomers.[11]
^ abcde Solomons T.W.G., Fryhle C.B., Snyder S.A. Solomons’ organic chemistry. 12th Edition. John Wiley & Sons Incorporated, 2017.
^ Constitutional isomerism, in IUPAC Compendium of Chemical Terminology, 5th ed. International Union of Pure and Applied Chemistry; 2025. Online version 5.0.0, 2025. doi:10.1351/goldbook.C01285
^ Stereoisomerism, in IUPAC Compendium of Chemical Terminology, 5th ed. International Union of Pure and Applied Chemistry; 2025. Online version 5.0.0, 2025. doi:10.1351/goldbook.S05983
^ ab North M. Principles and applications of stereochemistry. 1th Edition. CRC Press, 1998.
^ ab Morsch L., Farmer S., Cunningham K., Sharrett Z., Shea K.M. Organic Chemistry II. Open Educational Resources: Textbooks, Smith College, Northampton, MA, 2023. https://scholarworks.smith.edu/textbooks/6
^ Enantiomer, in IUPAC Compendium of Chemical Terminology, 5th ed. International Union of Pure and Applied Chemistry; 2025. Online version 5.0.0, 2025. doi:10.1351/goldbook.E02069
^ Gogoi A., Konwer S., Zhuo G.Y. Polarimetric measurements of surface chirality based on linear and nonlinear light scattering. Front Chem 2021;8:611833. doi:10.3389/fchem.2020.611833
^ Hunt I. Stereochemistry. University of Calgary. Retrieved 3 November 2023.
^ Diastereoisomerism, in IUPAC Compendium of Chemical Terminology, 5th ed. International Union of Pure and Applied Chemistry; 2025. Online version 5.0.0, 2025. doi:10.1351/goldbook.D01679
In a solution, solvent molecules tend to move from a region of higher concentration to one of lower concentration. When two different solutions are separated by a semipermeable membrane, namely, a membrane that allows certain ions or molecules to pass, in this case the solvent molecules, a net flow of solvent molecules from the side with higher concentration to the side with lower concentration will occur.[1] This net flow through the semipermeable membrane produces a pressure called osmotic pressure, denoted as Π, which can be defined as the force that must be applied to prevent the movement of solvent molecules through a semipermeable membrane.[2][3]
Summary: Key Points
Definition: osmotic pressure stops solvent flow across a membrane and is measured via the van ’t Hoff equation.
van ’t Hoff Factor: measures solute dissociation. It equals 1 for non-ionizable molecules and is greater than 1 for dissociating salts.
Cellular tonicity: governs water movement. In hypotonic solutions, cells face osmotic lysis, which is prevented by cell walls or energy-dependent ion pumps.
Glucose storage strategy: storing glucose as polymers (glycogen or starch), minimizes particle count, lowering intracellular osmolarity to prevent dangerous water influx.
Clinical relevance: unabsorbed gut solutes retain water, causing osmotic diarrhea. In galactosemia, galactitol buildup inside the lens drives water influx, leading to cataracts.
Osmotic pressure, along with boiling point elevation, freezing point depression, and vapor pressure lowering, is one of the four colligative properties of solutions. These are properties that do not depend on the chemical nature of the solute particles, namely, ions, molecules, or supramolecular structures, but only on the number of solute particles present in the solution.[4]
For a solution containing n solutes, the equation that describes osmotic pressure is the sum of the contributions of each solute:
Π = RT(i1c1 + i2c2 + … + incn)
This equation is known as the van ’t Hoff equation, and it relates osmotic pressure (Π) to the following variables:
The van ’t Hoff factor is a measure of the degree of dissociation of solutes in solution. It is described by the equation:
i = 1 + α(n − 1)
where:
α is the degree of dissociation of the solute, defined as the ratio between the number of moles of solute that have dissociated and the initial number of moles. Its value ranges from 0, for substances that do not ionize or dissociate in solution, to 1, for substances that completely dissociate or ionize;
n is the number of ions formed per molecule of solute upon dissociation.[7]
Non-ionizable compounds, such as glucose, glycogen, or starch, have n = 1 and i = 1. In contrast, compounds that fully dissociate, like strong acids, strong bases, or salts, exhibit a van ’t Hoff factor greater than one, as their degree of dissociation is 1 and n is at least 2. A typical example can be found in dilute solutions.
In the first two cases, i = 2, while for calcium chloride, i = 3.
Finally, for substances that do not fully dissociate, such as weak acids and weak bases, i is not an integer.
The product of the van ’t Hoff factor and the molar concentration of solute particles (i·c) is called the osmolarity of the solution, namely, the concentration of osmotically active solute particles per liter of solution.[7]
Osmotic pressure, osmosis, and plasma membranes
Osmosis can be defined as the net movement of solvent molecules through a semipermeable membrane, driven by osmotic pressure differences across the membrane, in an attempt to equalize solute concentrations on both sides.[8]
In biological systems, water acts as the solvent, and plasma membranes serve as the semipermeable membranes. Plasma membranes permit the passage of water molecules through protein channels known as aquaporins, as well as small non-polar molecules that diffuse rapidly across the membrane. However, they are impermeable to ions and macromolecules.[9]
Inside the cell, there are macromolecules such as nucleic acids, proteins, glycogen, and supramolecular aggregates, for example, multienzyme complexes, as well as ions, often present at higher concentrations than in the extracellular environment. This difference in solute concentration causes osmotic pressure to drive water from the outside to the inside of the cell.[10]
If this net influx of water is not counterbalanced, the cell swells, and the plasma membrane becomes distended until the cell bursts, a process known as osmotic lysis. Under physiological conditions, this does not occur because, over the course of evolution, several mechanisms have developed to counteract, or in some cases exploit, these osmotic forces.[7] Two of the main strategies are energy-dependent ion pumps, and in plants, bacteria, and fungi, the cell wall.
Energy dependent ion pumps
Ion pumps lower, at the expense of ATP, the intracellular concentration of specific ions relative to their concentration in the extracellular environment, thereby establishing an unequal distribution of ions across the plasma membrane, an ion gradient. In doing so, the cell counterbalances the osmotic forces created by the ions and macromolecules trapped within it.
A classic example of an energy-dependent ion pump is the Na+/K+-ATPase, which actively reduces the intracellular concentration of Na⁺ compared to the outside.[8]
Cell wall
Plant cells are surrounded by an extracellular matrix known as the cell wall. This structure, being non-expandable and tightly associated with the plasma membrane, enables cells to resist the osmotic forces that would otherwise cause swelling and eventually lysis.[8]
How does it work?
In mature plant cells, vacuoles are the largest organelles, occupying approximately 80% of the total cell volume. These vacuoles accumulate large amounts of solutes, mostly organic and inorganic acids, that osmotically draw water into the cell, causing the vacuoles to swell.
As a result, the tonoplast (the membrane surrounding the vacuole) pushes the plasma membrane outward against the rigid cell wall. The cell wall mechanically resists this force, preventing osmotic lysis.[11]
This internal pressure is known as turgor pressure, which can reach values of up to 2 MPa (approximately 20 atmospheres), about ten times the air pressure in a car tire.[12] Turgor pressure is crucial for the rigidity of non-woody plant tissues and plays a role in:
plant growth;
the wilting of vegetables (due to turgor loss);
plant movements, such as:
circadian movements of leaves;
the snapping shut of Dionaea muscipula (Venus flytrap),
the folding of sensitive plants like Mimosa pudica.[11]
Similarly, in bacteria and fungi, the plasma membrane is surrounded by a cell wall that stably contains internal pressure, thereby preventing osmotic lysis.[12]
Isotonic, hypotonic, and hypertonic solutions
By comparing the osmotic pressure of two solutions separated by a semipermeable membrane, three types of relationships can be defined, as described below.
Isotonic solutions have the same osmotic pressure.
If the solutions have different osmotic pressures, the one with the higher osmotic pressure is termed hypertonic relative to the other.
Conversely, the one with the lower osmotic pressure is termed hypotonic.[1]
In biological systems, the cytosol is typically used as the reference solution. When a cell is placed in a:
Isotonic solution: no net movement of water occurs across the plasma membrane.
Hypertonic solution: water flows out of the cell, leading to cell shrinkage.
Hypotonic solution: water flows into the cell, causing it to swell and potentially burst, this process is known as osmotic lysis.
Effects of osmotic pressure on cells
Solution type
Relative osmotic pressure
Water movement
Effect on the Cell
Isotonic
Equal to cytosol
No net movement
Cell remains stable
Hypertonic
Higher than cytosol
Water flows out of the cell
Cell shrinks (crenation)
Hypotonic
Lower than cytosol
Water flows into the cell
Cell swells and may burst (lysis)
In addition to ion pumps and the cell wall, multicellular organisms have evolved another strategy to counter osmotic forces: surrounding cells with a solution that is isotonic, or nearly isotonic, with respect to the cytosol.[13]
An example is plasma, the liquid component of blood, which, due to the presence of salts and proteins (primarily albumin in humans), has an osmolarity similar to that of the cytosol. This isotonic environment helps prevent excessive water movement into or out of cells.[14]
Osmotic pressure, starch and glycogen
Living organisms store glucose in polymeric forms, glycogen in animals, fungi, and bacteria, and starch in photoautotrophs, rather than as free glucose. This strategy prevents the osmotic pressure exerted by stored carbohydrates from becoming excessively high.
Since osmotic pressure, like the other colligative properties, depends solely on the number of solute particles rather than their mass or size, storing millions of glucose units as a much smaller number of polysaccharide molecules significantly reduces the resulting osmotic pressure.[4]
Here are some illustrative examples
One gram of a polysaccharide (e.g., glycogen or starch) composed of ~1,000 glucose units exerts far less osmotic pressure than just one milligram of free glucose, because the polysaccharide counts as a single solute particle per macromolecule.[15]
In hepatocytes, if all glucose currently stored as glycogen were instead present in its free form, the intracellular glucose concentration would rise to about 0.4 M, compared to the actual polysaccharide concentration of roughly 0.04 μM. This would create a steep osmotic gradient, causing a net inflow of water and potentially leading to osmotic lysis.[7]
Even if cell lysis were avoided, glucose transport into the cell would become energetically unfavorable. In humans, normal blood glucose levels range from 3.33 to 5.56 mmol/L (60–100 mg/dL). If free glucose reached intracellular concentrations of 0.4 M, this would be 72 to 120 times higher than blood glucose levels, requiring significant active transport and energy expenditure to maintain.[16]
Effect of glucose gtorage form on osmotic pressure
Storage form
Molecular units
Approximate concentration
Osmotic effect
Cellular consequences
Free Glucose
~1,000 individual molecules
~0.4 M
Very high osmotic pressure
Water influx → Cell swelling → Risk of lysis
Glycogen/Starch
1 macromolecule (polymer of 1,000 glucose units)
~0.04 μM
Negligible osmotic pressure
Stable osmotic conditions
Osmotic diarrhea
Osmotic diarrhea occurs when diseases lead to the accumulation of non-absorbed, osmotically active solutes in the distal small intestine and colon.[17]
Possible causes include bacterial infections, pancreatic diseases, and celiac disease, an autoimmune enteropathy triggered by gluten intake in genetically predisposed individuals, as well as congenital deficiencies in brush border disaccharidases, such as in lactose intolerance. In these conditions, incomplete carbohydrate digestion may occur due to deficiencies in alpha-amylase and/or one or more disaccharidases.[18] As a result, unabsorbed osmotically active solutes reach the colon, where they can also be fermented by the gut microbiota, part of the human microbiota, producing excess gas (such as hydrogen, carbon dioxide, and methane) and short-chain fatty acids, mainly butyric acid, acetic acid, and propionic acid. This leads to a condition known as osmotic-fermentative diarrhea.[19]
Osmotic diarrhea can also result from the use of osmotic laxatives, such as polyethylene glycol (PEG) or magnesium sulfate. Osmotically active solutes from incomplete digestion and osmotic laxatives increase intraluminal osmotic pressure and inhibit the normal absorption of water and electrolytes, leading to looser stools and increased intestinal motility.[20]
Osmotic pressure, galactosemia, and cataracts
Galactose, along with glucose and fructose, is one of the monosaccharides absorbed in the intestine.[21]
Galactose is metabolized primarily in the liver, and to a lesser extent in other organs and tissues. Through the Leloir pathway, it is converted into UDP-glucose and UDP-galactose, which can then be used for both anabolic and catabolic processes.[22]
Mutations in the genes encoding enzymes of the Leloir pathway lead to the accumulation of galactose and cause galactosemia, a genetic metabolic disorder whose only treatment is a galactose-restricted diet.[23] The accumulated galactose is redirected into alternative metabolic pathways, resulting in the production of galactose-related compounds such as galactitol and galactonate.[24]
One of the symptoms of galactosemia is cataracts, and the synthesis and accumulation of galactitol in the lens of the eye appears to be a contributing factor. Why? Galactitol is a poorly metabolized polyol. Due to its low lipophilicity, it does not readily diffuse across cell membranes and tends to accumulate inside the cell. Being osmotically active, its intracellular buildup increases osmotic pressure, leading to a net influx of water. This osmotic effect is believed to be one of the mechanisms through which galactitol contributes to the development of galactosemic cataracts.[25]
References
^ ab Zheng S., Li Y., Shao Y., Li L., Song F. Osmotic pressure and its biological implications. Int J Mol Sci 2024;25(6):3310. doi:10.3390/ijms25063310
^ Bowler M.G. The physics of osmotic pressure. Eur J Phys 2017;38:055102. doi:10.1088/1361-6404/aa7fd3
^ Osmotic pressure, in IUPAC Compendium of Chemical Terminology, 5th ed. International Union of Pure and Applied Chemistry; 2025. Online version 5.0.0, 2025. doi:10.1351/goldbook.O04344
^ ab Hammel H.T. Colligative properties of a solution. Science 1976;192(4241):748-56. doi:10.1126/science.1265478
^ van’t Hoff J.H. The role of osmotic pressure in the analogy between solutions and gases. J Membr Sci 1995;100:39-44. doi:10.1016/0376-7388(94)00232-N
^ Hoff J.H.v.t. Die rolle des osmotischen druckes in der analogie zwischen lösungen und gasen. Z Phys Chem 1887;1U:481-508. doi:10.1515/zpch-1887-0151
^ abcd Nelson D.L., Cox M.M. Lehninger. Principles of biochemistry. 8th Edition. W.H. Freeman and Company, 2021.
^ abc Berg J.M., Tymoczko J.L., Gatto J.G., Stryer L. Biochemistry. 9th Edition. W.H. Freeman and Company, 2019.
^ Agre P., Preston G.M., Smith B.L., Jung J.S., Raina S., Moon C., Guggino W.B., Nielsen S. Aquaporin CHIP: the archetypal molecular water channel. Am J Physiol 1993;265(4 Pt 2):F463-76. doi:10.1152/ajprenal.1993.265.4.F463
^ Phillips R., Kondev J., Theriot J., Garcia H.G. Physical Biology of the Cell. 2nd Edition. Garland Science. 2012. doi:10.1201/9781134111589
^ ab Heldt H-W. Plant biochemistry – 3th Edition. Elsevier Academic Press, 2005.
^ ab Beauzamy L., Nakayama N., and Boudaoud A. Flowers under pressure: ins and outs of turgor regulation in development. Ann Bot 2014;114(7):1517-1533. doi:10.1093/aob/mcu187
^ Alberts B., Heald B., Johnson A.D., Morgan D., Raff M., Roberts K., Walter P. Molecular Biology of the Cell. 7th Edition. Garland Science, 2022.
^ Brinkman J.E., Dorius B., Sharma S. Physiology, Body fluids. [Updated 2023 Jan 27]. In: StatPearls [Internet]. Treasure Island (FL): StatPearls Publishing; 2025 Jan-. Available from: https://www.ncbi.nlm.nih.gov/books/NBK482447/
^ Sadava D.E., Hillis D., Craig Heller H., Berenbaum M.R. Life: the science of biology. 10th Edition. Sinauer Associates. 2014.
^ Nakrani M.N., Wineland R.H., Anjum F. Physiology, Glucose Metabolism. [Updated 2023 Jul 17]. In: StatPearls [Internet]. Treasure Island (FL): StatPearls Publishing; 2025 Jan-. Available from: https://www.ncbi.nlm.nih.gov/books/NBK560599/
^ Bashir A., Sizar O. Laxatives. [Updated 2024 Jan 30]. In: StatPearls [Internet]. Treasure Island (FL): StatPearls Publishing; 2025 Jan-. Available from: https://www.ncbi.nlm.nih.gov/books/NBK537246/
^ Wright E.M., Martín M.G., Turk E. Intestinal absorption in health and disease–sugars. Best Pract Res Clin Gastroenterol 2003;17(6):943-56. doi:10.1016/s1521-6918(03)00107-0
Multifunctional enzymes are proteins in which two or more enzymatic activities, catalyzing consecutive steps of a metabolic pathway, are located on the same polypeptide chain. They are thought to have arisen through gene fusion events and, like multienzyme complexes, represent an evolutionary strategy to maximize catalytic efficiency. This configuration provides advantages that would not be possible if these enzymatic activities were present on separate proteins freely dissolved in the cytosol.[1][2]
Summary: Key Points
Structural nature: multifunctional enzymes are single polypeptide chains possessing two or more distinct catalytic activities, which evolved through gene fusion events.
Substrate channeling: due to the proximity of active sites (and sometimes intramolecular tunnels), intermediate metabolites pass directly from one reaction to the next without diffusing into the cytosol.
Efficiency and protection: this configuration maximizes reaction rates, minimizes substrate dilution, and prevents the degradation of unstable or toxic metabolic intermediates.
Regulatory advantage: being encoded by a single gene allows for perfectly coordinated control of both enzyme synthesis and catalytic activities, preventing energy waste.
What advantages do multifunctional enzymes provide?
Living organisms constantly fight against natural processes of decay which, if left unchecked, lead to increasing disorder and ultimately death.
At the molecular level, life is sustained by the extraordinary effectiveness of enzymes in accelerating chemical reactions and minimizing side reactions. The rate of ATP turnover in a mammalian cell gives an idea of how fast cellular metabolism operates: every 1–2 minutes, the entire ATP pool is turned over, hydrolyzed and then regenerated via phosphorylation. This corresponds to a turnover of about 107 ATP molecules per second, and, for the human body, to about 1 gram of ATP every minute.[3] Some enzymes have even achieved catalytic perfection, meaning they are so efficient that nearly every collision with their substrate leads to catalysis.[2]
One of the limiting factors of an enzymatic reaction is the frequency of collisions between enzymes and substrates. The simplest way to increase this frequency would be to increase their concentrations. However, given the vast number of different reactions taking place within the cell, this strategy is not feasible. In other words, there is a physical limit to the concentrations that substrates and enzymes can reach, with substrate concentrations typically in the micromolar range, and even lower for enzymes.[3] Exceptions include the enzymes of glycolysis in muscle cells and erythrocytes, which can be present at concentrations around 0.1 mM or even higher.[4]
Metabolic channeling
One of the strategies favored by evolution to increase the rate of enzymatic reactions is the selection of molecular structures, such as multifunctional enzymes and multienzyme complexes, that optimize the spatial organization of enzymes within a metabolic pathway. This spatial optimization minimizes the distance that the product of reaction A must travel to reach the active site catalyzing reaction B in the sequence, and so on. This phenomenon is known as substrate channeling, or more broadly, metabolic channeling.[5] In some multifunctional enzymes and multienzyme complexes, channeling is achieved through the presence of intramolecular channels.[6]
Schematic Representation of Metabolic Channeling
How metabolic channeling enhances catalytic efficiency
Metabolic channeling enhances catalytic efficiency, and therefore the reaction rate, in several ways, outlined below.
It prevents the diffusion of substrates into the bulk solvent, thereby minimizing their dilution. This enables high local substrate concentrations, even when their overall cellular concentrations are low, increasing the frequency of enzyme-substrate collisions.
It reduces the time required for substrates to diffuse from one active site to the next.
It lowers the probability of side reactions.
It decreases the likelihood that unstable intermediates will degrade before reaching the next active site.[2][5]
Multifunctional enzymes also offer advantages in terms of the regulation of their synthesis. Since all enzymatic activities are encoded by a single gene, their expression can be coordinated efficiently.[7]
Finally, like multienzyme complexes, multifunctional enzymes enable coordinated control of catalytic activities. Often, the enzyme that catalyzes the committed step of the pathway is also responsible for the first reaction. This positioning prevents the synthesis of unnecessary products, which would occur if regulation took place downstream, thereby avoiding waste of energy and preventing the depletion of metabolites from other metabolic pathways.[2]
Analysis of kinetic advantages and biochemical mechanisms of substrate channeling (metabolic channeling)
Kinetic Advantage
Biochemical Mechanism
Effect on the Cell
Reduced diffusion
The metabolite passes directly from one active site to the next.
Maximizes the frequency of enzyme-substrate collisions.
Minimized dilution
The substrate does not diffuse out into the bulk solvent.
Maintains high local concentrations even with low overall cellular levels.
Intermediate protection
Unstable or reactive intermediates are structurally isolated.
Drastically decreases the likelihood of decay or side reactions.
Coordinated control
Expression and regulation depend on a single, shared gene.
Prevents the synthesis of unnecessary products, avoiding energy waste.
Examples of multifunctional enzymes
Like multienzyme complexes, multifunctional enzymes are also common and play key roles in many metabolic pathways, both anabolic and catabolic.
Below are several noteworthy examples.
Acetyl-CoA carboxylase
Acetyl-CoA carboxylase (ACC; EC 6.4.1.2) is a biotin-dependent carboxylase composed of two catalytic domains, biotin carboxylase (EC 6.3.4.14) and carboxyltransferase, as well as a biotin carboxyl carrier protein (BCCP). ACC catalyzes the synthesis of malonyl-CoA by carboxylating acetyl-CoA, in a reaction that represents the committed step in fatty acid biosynthesis.[7] The reaction occurs in two sequential steps.
In the first step, biotin carboxylase catalyzes the ATP-dependent carboxylation of the nitrogen atom in biotin, which acts as a carrier of carbon dioxide (CO2). The source of CO2 in this reaction is the bicarbonate ion.
In the second step, carboxyltransferase catalyzes the transfer of the carboxyl group from carboxybiotin to acetyl-CoA, forming malonyl-CoA.
Malonyl-CoA then serves as the donor of an activated two-carbon unit to fatty acid synthase (EC 2.3.1.85) during the elongation of fatty acid chains.[8]
In mammals and birds, acetyl-CoA carboxylase is a multifunctional enzyme, with biotin carboxylase, carboxyltransferase, and BCCP activities located on a single polypeptide chain.[9]
In contrast, in bacteria, ACC exists as a multienzyme complex composed of three distinct polypeptide chains: biotin carboxylase, carboxyltransferase, and BCCP.[10]
Both forms, the multifunctional enzyme and the multienzyme complex, are found in higher plants.[8]
Type I fatty acid synthase
Fatty acid synthase (FAS) catalyzes the synthesis of palmitic acid, using malonyl-CoA, the product of the reaction catalyzed by acetyl-CoA carboxylase, as a donor of two-carbon units.
There are two types of FAS.
In fungi and animals, FAS is a multifunctional enzyme known as Type I.
In animals, it exists as a homodimer, with each polypeptide chain containing all seven enzymatic activities, along with an acyl carrier protein (ACP) domain.
In yeast and fungi, FAS is composed of two distinct multifunctional subunits, designated α and β, which assemble into an α6β6 heterododecameric complex.
In most prokaryotes and in plants, FAS is classified as Type II. It is not a multifunctional enzyme, but rather a multienzyme complex composed of separate, individual enzymes and ACP.[11][12][13]
PRA-isomerase:IGP synthase
The biosynthesis of the amino acid tryptophan from chorismate involves several steps, summarized below.
In the first step, glutamine donates a nitrogen atom to the indole ring of chorismate, which is converted into anthranilate, while glutamine is simultaneously converted into glutamate. This reaction is catalyzed by anthranilate synthase (EC 4.1.3.27).
Anthranilate is then phosphoribosylated to form N-(5′-phosphoribosyl)-anthranilate (PRA), in a reaction catalyzed by anthranilate phosphoribosyltransferase (EC 2.4.2.18).
In this step, 5-phosphoribosyl-1-pyrophosphate (PRPP) acts as the donor of a 5-phosphoribosyl group.
In the next step, PRA is isomerized to enol-1-o-carboxyphenylamino-1-deoxyribulose phosphate (CdRP) by PRA isomerase (EC 5.3.1.24).
PRA and CdRP are an example of structural isomers.
CdRP is then converted into indole-3-glycerol phosphate (IGP) in a reaction catalyzed by indole-3-glycerol phosphate synthase (IGP synthase) (EC 4.1.1.48).
Finally, tryptophan synthase (EC 4.2.1.20) catalyzes the last two steps of the pathway: the hydrolysis of IGP to indole, and the condensation of indole with serine to form tryptophan.[11]
In E. coli, PRA isomerase and IGP synthase are located on a single polypeptide chain, making it a bifunctional enzyme.[14] In other microorganisms, such as Bacillus subtilis, Salmonella typhimurium, and Pseudomonas putida, the two catalytic activities are found on separate polypeptide chains.[2] In contrast, tryptophan synthase is a classic example of a multienzyme complex, and one of the best-characterized examples of metabolic channeling.[15][16]
Glutamine-PRPP amidotransferase
Glutamine-PRPP amidotransferase (GPATase; EC 2.4.2.14) catalyzes the first of ten steps in the de novo synthesis of purine nucleotides, specifically, the formation of 5-phosphoribosylamine via transfer of the amide nitrogen from glutamine to PRPP.
In this reaction, glutamine acts as a nitrogen donor.
The reaction proceeds in two steps, which occur at distinct active sites: one located at the N-terminal and the other at the C-terminal region of the enzyme.
In the first step, the N-terminal active site catalyzes the hydrolysis of glutamine, releasing glutamate and ammonia.
In the second step, catalyzed by the C-terminal active site (which has phosphoribosyltransferase activity), the ammonia is attached to the C-1 position of PRPP, forming 5-phosphoribosylamine.
This step also involves inversion of configuration at the ribose C-1 carbon, from α to β, thereby establishing the anomeric form of the future nucleotide.
There are three key regulatory points in the control of purine nucleotide biosynthesis. The reaction catalyzed by GPATase, being the first committed step of the pathway, represents the primary control point.[2]
As in the bacterial carbamoyl phosphate synthetase complex (EC 6.3.4.16), the active sites of this multifunctional enzyme are connected by an intramolecular channel. However, in this case the channel is shorter, approximately 20 Å in length, and is lined with conserved nonpolar (hydrophobic) amino acids.
Due to the lack of hydrogen-bonding groups, the channel does not impede the diffusion of ammonia between active sites.[17][18]
CAD
The de novo synthesis of pyrimidine nucleotides proceeds through a series of enzymatic reactions that, unlike the de novo synthesis of purine nucleotides, begins with the formation of the pyrimidine ring, which is then attached to ribose 5-phosphate. The first three steps of the pathway are catalyzed sequentially by the enzymes carbamoyl phosphate synthetase, aspartate transcarbamoylase (EC 2.1.3.2), and dihydroorotase (EC 3.5.2.3), a sequence that is conserved across all species.
In the first step, carbamoyl phosphate synthetase, which has two enzymatic activities, a glutamine-dependent amidotransferase and a synthase, catalyzes the formation of carbamoyl phosphate from glutamine, a bicarbonate ion, and ATP.
In the second step, catalyzed by aspartate transcarbamoylase, carbamoyl phosphate reacts with aspartate to form N-carbamoyl aspartate. This is the committed step of the pathway.
In the final step, dihydroorotase catalyzes the removal of water from N-carbamoyl aspartate, leading to ring closure and the formation of L-dihydroorotate.[8]
Structural organization in eukaryotes and prokaryotes
In eukaryotes, particularly in mammals, Drosophila, and Dictyostelium (a genus of amoebae), these three enzymatic activities are located on a single polypeptide chain, encoded by a gene derived from a gene fusion event that occurred at least 100 million years ago. The resulting multifunctional enzyme, known by the acronym CAD, functions as a homomultimer composed of three or more subunits.[19]
In contrast, in prokaryotes, the three enzymes exist as separate proteins, and carbamoyl phosphate synthetase is a typical example of a multienzyme complex.[20]
In yeasts, dihydroorotase is located on a distinct polypeptide chain, separate from the other two enzymes.[21]
Interestingly, studies of enzymatic activity have revealed evidence of substrate channeling, particularly between the first two steps. This channeling appears to be more efficient in the yeast protein compared to the mammalian CAD enzyme.[22]
Comparison of structural characteristics and metabolic pathways of multifunctional enzymes across different organisms
^ abcdef Heilman D., Woski S., Voet D., Voet J.G., Pratt C.W. Fundamentals of biochemistry: life at the molecular level. 6th Edition. Wiley, 2023.
^ ab Alberts B., Heald B., Johnson A.D., Morgan D., Raff M., Roberts K., Walter P. Molecular Biology of the Cell. 7th Edition. Garland Science, 2022.
^ Maughan D.W., Henkin J.A., Vigoreaux J.O. Concentrations of glycolytic enzymes and other cytosolic proteins in the diffusible fraction of a vertebrate muscle proteome. Mol Cell Proteomics 2005;4(10):1541-9. doi:10.1074/mcp.M500053-MCP200
^ ab Moran L.A., Horton H.R., Scrimgeour K.G., Perry M.D. Principles of Biochemistry. 5th Edition. Pearson, 2012.
^ Kondrat S., von Lieres E. Mechanisms and effects of substrate channelling in enzymatic cascades. Methods Mol Biol 2022;2487:27-50. doi:10.1007/978-1-0716-2269-8_3
^ ab Berg J.M., Tymoczko J.L., Gatto J.G., Stryer L. Biochemistry. 9th Edition. W.H. Freeman and Company, 2019.
^ abc Nelson D.L., Cox M.M. Lehninger. Principles of biochemistry. 8th Edition. W.H. Freeman and Company, 2021.
^ Wang Y., Yu W., Li S., Guo D., He J., Wang Y. Acetyl-CoA carboxylases and diseases. Front Oncol 2022;12:836058. doi:10.3389/fonc.2022.836058
^ Salie M.J., Thelen J.J. Regulation and structure of the heteromeric acetyl-CoA carboxylase. Biochim Biophys Acta 2016;1861(9 Pt B):1207-1213. doi:10.1016/j.bbalip.2016.04.004
^ Priestle J.P., Grütter M.G., White J.L., Vincent M.G., Kania M., Wilson E., Jardetzky T.S., Kirschner K., Jansonius J.N. Three-dimensional structure of the bifunctional enzyme N-(5′-phosphoribosyl)anthranilate isomerase-indole-3-glycerol-phosphate synthase from Escherichia coli. Proc Natl Acad Sci USA 1987;84(16):5690-4. doi:10.1073/pnas.84.16.5690
^ Hyde C.C., Ahmed S.A., Padlan E.A., Miles E.W., and Davies D.R. Three-dimensional structure of the tryptophan synthase multienzyme complex from Salmonella typhimurium. J Biol Chem 1988:263(33);17857-17871. doi:10.1016/S0021-9258(19)77913-7
^ Hyde C.C., Miles E.W. The tryptophan synthase multienzyme complex: exploring structure-function relationships with X-ray crystallography and mutagenesis. Nat Biotechnol 1990:8;27-32. doi:10.1038/nbt0190-27
^ Muchmore C.R.A., Krahn J.M, Smith J.L., Kim J.H., Zalkin H. Crystal structure of glutamine phosphoribosylpyrophosphate amidotransferase from Escherichia coli. Protein Sci 1998:7;39-51. doi:10.1002/pro.5560070104
^ Raushel F.M., Thoden J.B., Holden H.M. The amidotransferase family of enzymes: molecular machines for the production and delivery of ammonia. Biochemistry 1999;38(25):7891-9. doi:10.1021/bi990871p
^ Del Caño-Ochoa F., Moreno-Morcillo M., Ramón-Maiques S. CAD, a multienzymatic protein at the head of de novo pyrimidine biosynthesis. Subcell biochem 2019;93:505-538. doi:10.1007/978-3-030-28151-9_17
^ Washabaugh M.W., Collins K.D. Dihydroorotase from Escherichia coli. Purification and characterization. J Biol Chem 1984;259(5):3293-8.
^ Guan H.H., Huang Y.H., Lin E.S., Chen C.J., Huang C.Y. Structural analysis of Saccharomyces cerevisiae dihydroorotase reveals molecular insights into the tetramerization mechanism. Molecules 2021;26(23):7249. doi:10.3390/molecules26237249
^ Belkaïd M., Penverne B., Hervé G. In situ behavior of the pyrimidine pathway enzymes in Saccharomyces cerevisiae. 3. Catalytic and regulatory properties of carbamylphosphate synthetase: channeling of carbamylphosphate to aspartate transcarbamylase. Arch Biochem Biophys 1988;262(1):171-80. doi:10.1016/0003-9861(88)90179-8
Multienzyme complexes are discrete and stable structures composed of noncovalently associated enzymes that catalyze two or more sequential steps of a metabolic pathway.[1]
They can be considered a step forward in the evolution of catalytic efficiency, as they provide advantages that individual enzymes, even those that have achieved catalytic perfection, would not have on their own.[2]
During evolution, some enzymes have reached a state of virtual catalytic perfection, meaning that nearly every collision with their substrate results in catalysis. Below are several noteworthy examples.
Fumarase (EC 4.2.1.2) catalyzes the seventh reaction of the citric acid cycle, the reversible hydration/dehydration of fumarate’s double bond to form malate.
Acetylcholinesterase (EC 3.1.1.7) catalyzes the hydrolysis of acetylcholine, a neurotransmitter, into choline and acetic acid, which then dissociates to form a hydrogen ion and acetate.
Superoxide dismutase (EC 1.15.1.1) catalyzes the conversion and inactivation of the highly reactive superoxide radical (O2.-) into hydrogen peroxide (H2O2)and water.
Catalase (EC 1.11.1.6) catalyzes the degradation of H2O2 into water and oxygen.[2]
The rate of an enzymatic reaction is partly determined by how often enzymes and substrates collide. A simple way to increase this rate would be to increase enzyme and substrate concentrations. However, within a cell, their concentrations cannot be very high due to the large number of different reactions occurring simultaneously. In fact, most reactants are present in micromolar concentrations (10-6 M), while most enzymes are found at even lower concentrations.[3]
How metabolic channeling optimizes biochemical reactions
To overcome these limitations, evolution has taken different routes to enhance reaction rates. One such route is the optimization of enzyme spatial organization through the formation of multienzyme complexes and multifunctional enzymes. These structures minimize the distance that a reaction product must travel to reach the next active site, which is located close by.[1]
In other words, this leads to substrate (or metabolic) channeling, which can also occur through intramolecular channels connecting active sites.[4]
Metabolic channeling increases not just reaction rate but overall catalytic efficiency in several ways:
minimizing diffusion of substrates and products into bulk solvent, which prevents dilution and maintains high local concentrations, even when overall intracellular concentrations are low;
reducing the time required for substrates to diffuse between successive active sites;
lowering the probability of side reactions;
protecting chemically labile intermediates from degradation by the solvent.[2][4]
Another metabolic advantage, similar to multifunctional enzymes, is that multienzyme complexes allow coordinated regulation of the catalytic activity of their constituent enzymes. Since the enzyme catalyzing the first reaction in a pathway is often the regulatory enzyme, this prevents:
the synthesis of unneeded intermediates that would occur if regulation happened downstream;
the removal of metabolites from other pathways, as well as energy waste.[2]
Examples of multienzyme complexes
As noted above, especially in eukaryotes, multienzyme complexes, like multifunctional enzymes, are common in both anabolic and catabolic pathways, whereas few enzymes diffuse freely in solution. Two examples of multienzyme complexes include the tryptophan synthase complex (EC 4.2.1.20), whose tunnel was the first to be discovered, and bacterial carbamoyl phosphate synthase complex (EC 6.3.4.16).[5][6][7]
2-Ketoacid dehydrogenase family
A classic case of multienzyme organization is the 2-ketoacid (or 2-oxoacid) dehydrogenase family, which includes:
α-ketoglutarate dehydrogenase complex, also called 2-oxoglutarate dehydrogenase (OGDH).[1][8]
α-Ketoglutarate Dehydrogenase Complex
These multienzyme complexes are structurally and functionally similar. PDC, for instance, consists of multiple copies of three enzymes:
pyruvate dehydrogenase (E1; EC 1.2.4.1);
dihydrolipoyl transacetylase (E2; EC 2.3.1.12);
dihydrolipoyl dehydrogenase (E3; EC 1.8.1.4).
The same E1–E2–E3 architecture occurs in all three complexes, both in prokaryotes and eukaryotes. Within a given species, E3 is identical, while E1 and E2 are homologous.[9]
Though substrate-specific, these enzymes share the same cofactors: coenzyme A, NAD+, thiamine pyrophosphate, FAD, and lipoamide. For clarity, their components are labeled:
Note: eukaryotic PDC is the largest known multienzyme complex, larger than a ribosome, and can be visualized by electron microscopy.[10]
PDC links glycolysis to the citric acid cycle, catalyzing the irreversible oxidative decarboxylation of pyruvate to acetyl-CoA, with carbon dioxide (CO2) release and electron transfer to NAD+. Similarly, OGDH and BCKDH catalyze oxidative decarboxylations of α-ketoglutarate (to succinyl-CoA) and branched-chain α-keto acids (from valine, leucine, and isoleucine), involving:
CO2 release;
acyl group transfer to coenzyme A (forming acyl-CoA derivatives);
NAD+ reduction to NADH.
The striking similarities in structure, cofactors, and mechanisms point to a common evolutionary origin.[10]
Tryptophan synthase complex
The tryptophan synthase complex is one of the best-studied examples of substrate channeling.[4] It is present in bacteria and plants, but not in animals.[11] In bacteria, it is composed of two α and two β subunits that associate into αβ dimers, which represent the functional units of the complex. These dimers further assemble into an αββα tetramer.[5][6]
The complex catalyzes the final two steps of tryptophan biosynthesis. In the first step, indole-3-glycerol phosphate undergoes an aldol cleavage, catalyzed by a lyase (EC 4.1.2.8) located on the α subunits, producing indole and glyceraldehyde 3-phosphate. Indole then reaches the active site of the β subunit through an approximately 30 Å-long hydrophobic tunnel that, within each αβ dimer, connects the two active sites. In the second step, in the presence of pyridoxal 5-phosphate, indole condenses with serine to form tryptophan.[4][12]
Acetyl-CoA carboxylase
Acetyl-CoA carboxylase (ACC; EC 6.4.1.2), a member of the biotin-dependent carboxylase family, catalyzes the committed step of fatty acid synthesis: the carboxylation of acetyl-CoA to malonyl-CoA. Malonyl-CoA, in turn, serves as a donor of two-carbon units for the elongation process leading to the synthesis of palmitic acid, catalyzed by fatty acid synthase (EC 2.3.1.85).[13]
In bacteria, ACC is a multienzyme complex composed of two enzymes, biotin carboxylase (EC 6.3.4.14) and carboxytransferase, plus a biotin carboxyl-carrier protein (BCCP).[13]
Conversely, in mammals and birds, it is a multifunctional enzyme, with both enzymatic activities and BCCP present on the same polypeptide chain.[8]
In higher plants, both forms are present.[14]
Carbamoyl phosphate synthetase complex
Another well-characterized example of substrate channeling is the bacterial carbamoyl phosphate synthetase complex, which catalyzes the synthesis of carbamoyl phosphate, required for pyrimidine and arginine synthesis. This multienzyme complex contains an approximately 100 Å-long tunnel that connects its three active sites.
The first active site catalyzes the release of the amide nitrogen from glutamine as an ammonium ion, which enters the tunnel and reaches the second active site, where it is combined with bicarbonate, at the expense of ATP, to yield carbamate. In the last active site, carbamate is phosphorylated to form carbamoyl phosphate.[7][15]
References
^ abc Michal G., Schomburg D. Biochemical pathways. An atlas of biochemistry and molecular biology. 2nd Edition. John Wiley J. & Sons, Inc. 2012.
^ abcde Voet D. and Voet J.D. Biochemistry. 4th Edition. John Wiley J. & Sons, Inc. 2011.
^ Alberts B., Johnson A., Lewis J., Morgan D., Raff M., Roberts K., Walter P. Molecular biology of the cell. 6th Edition. Garland Science, Taylor & Francis Group, 2015.
^ abcd Moran L.A., Horton H.R., Scrimgeour K.G., Perry M.D. Principles of Biochemistry. 5th Edition. Pearson, 2012.
^ ab Hyde C.C., Ahmed S.A., Padlan E.A., Miles E.W., and Davies D.R. Three-dimensional structure of the tryptophan synthase multienzyme complex from Salmonella typhimurium. J Biol Chem 1988;263(33):17857-17871. doi:10.1016/S0021-9258(19)77913-7
^ ab Hyde C.C., Miles E.W. The tryptophan synthase multienzyme complex: exploring structure-function relationships with X-ray crystallography and mutagenesis. Nat Biotechnol 1990:8;27-32. doi:10.1038/nbt0190-27
^ ab Thoden J.B., Holden H.M., Wesenberg G., Raushel F.M., Rayment I. Structure of carbamoyl phosphate synthetase: a journey of 96 A from substrate to product. Biochemistry 1997;36(21):6305-16. doi:10.1021/bi970503q
^ Zhou Z.H., McCarthy D.B., O’Connor C.M., Reed L.J., and J.K. Stoops. The remarkable structural and functional organization of the eukaryotic pyruvate dehydrogenase complexes. Proc Natl Acad Sci USA 2001;98(26):14802-14807. doi:10.1073/pnas.011597698
^ ab Nelson D.L., Cox M.M. Lehninger. Principles of biochemistry. 8th Edition. W.H. Freeman and Company, 2021.
^ Xie G., Forst C., Bonner C., Jensen R.A. Significance of two distinct types of tryptophan synthase beta chain in Bacteria, Archaea and higher plants. Genome Biol 2002;3(1):RESEARCH0004. doi:10.1186/gb-2001-3-1-research0004
^ Hilario E., Caulkins B.G., Huang Y-M. M., You W., Chang C-E.A., Mueller L.J., Dunn M.F., and Fan L. Visualizing the tunnel in tryptophan synthase with crystallography: insights into a selective filter for accommodating indole and rejecting water. Biochim Biophys Acta 2016;1864(3):268-279. doi:10.1016/j.bbapap.2015.12.006
^ ab Cronan J.E. Jr, Waldrop G.L. Multi-subunit acetyl-CoA carboxylases. Prog Lipid Res 2002;41(5):407-35. doi:10.1016/s0163-7827(02)00007-3
^ Sasaki Y., Nagano Y. Plant acetyl-CoA carboxylase: structure, biosynthesis, regulation, and gene manipulation for plant breeding. Biosci Biotechnol Biochem 2004;68(6):1175-84. doi:10.1271/bbb.68.1175
^ Holden H.M., Thoden J.B., Raushel F.M. Carbamoyl phosphate synthetase: an amazing biochemical odyssey from substrate to product. Cell Mol Life Sci 1999;56(5-6):507-22. doi:10.1007/s000180050448
The pyruvate dehydrogenase complex (PDC) is a mitochondrial multienzyme complex comprising three distinct enzymes:
pyruvate dehydrogenase (E1; EC 1.2.4.1);
dihydrolipoyl transacetylase (E2; EC 2.3.1.12);
dihydrolipoyl dehydrogenase (E3; EC 1.8.1.4).
Subunit stoichiometry and complex size vary among species, with molecular masses ranging from ≈ 4 × 106 to 1 × 107 daltons.[1]
In addition to its core enzymes, the PDC contains several accessory components. These include five essential coenzymes required for catalysis and, in plants, fungi, and in animals such as birds and mammals, two regulatory enzymes: a pyruvate dehydrogenase kinase (EC 2.7.11.2) and a pyruvate dehydrogenase phosphatase (EC 3.1.3.43).
In eukaryotes, the complex also includes an E3-binding protein (E3BP), which contributes to the structural organization of the complex.[2]
The pyruvate dehydrogenase complex catalyzes, through five sequential reactions, the oxidative decarboxylation of pyruvate to acetyl-coenzyme A (acetyl-CoA), producing one molecule of carbon dioxide (CO2) and reducing NAD+ through the transfer of two electrons.[3]
PDC Reaction
The overall reaction is essentially irreversible under physiological conditions (ΔG°′ ≈ −8.0 kcal/mol; −33.4 kJ/mol). During catalysis, the enzymes act in a coordinated manner, with reaction intermediates remaining bound to the complex, enabling efficient substrate channeling and rapid turnover.[4][5]
The Five Reactions Catalyzed by the PDC
Importantly, the PDC catalyzes the same reactions through highly conserved mechanisms in all organisms.[6]
Summary: Key Points
Function: catalyzes the irreversible oxidative decarboxylation of pyruvate to acetyl-CoA.
Structure: mitochondrial multienzyme complex (E1-E2-E3) requiring five cofactors and two regulatory enzymes.
Mechanism and Regulation: utilizes substrate channeling and is tightly controlled by allosteric inhibition and covalent modification.
Metabolic Role: acts as a crucial gatekeeper for carbohydrate metabolism, linking glycolysis to the citric acid cycle.
Five coenzymes are involved in the reactions catalyzed by the pyruvate dehydrogenase complex. They are thiamine pyrophosphate (TPP), flavin adenine dinucleotide (FAD), coenzyme A (CoA), nicotinamide adenine dinucleotide (NAD), and lipoic acid.[1]
Thiamine pyrophosphate
Thiamine pyrophosphate is the active form of thiamine, or vitamin B1. TPP is the coenzyme of pyruvate dehydrogenase, to which it is tightly bound through noncovalent interactions. It is involved in the transfer of hydroxyethyl, or “activated aldehyde,” groups.[2]
Flavin adenine dinucleotide
Flavin adenine dinucleotide is one of the active forms of riboflavin, or vitamin B2; the other is flavin mononucleotide (FMN).
Reduced and Oxidized Forms of Flavin Adenine Dinucleotide
FAD is the coenzyme of dihydrolipoyl dehydrogenase, to which it is tightly bound. Like NAD, it participates in electron transfer, specifically two electrons and two protons (2H+ + 2e−).[5]
Coenzyme A
Coenzyme A consists of a β-mercaptoethylamine group connected to pantothenic acid, or vitamin B5, through an amide linkage, which is in turn bonded to a 3′-phosphoadenosine moiety through a pyrophosphate bridge.
CoA participates in the reaction catalyzed by dihydrolipoyl transacetylase and acts as a carrier of acyl groups.[7]
Coenzyme A and Acetyl-CoA
The β-mercaptoethylamine moiety terminates with a sulfhydryl group (–SH), a reactive thiol crucial to the role played by the coenzyme because acyl groups bonded to it through a thioester linkage have a high standard free energy of hydrolysis. This gives acyl groups a high transfer potential, equal to −7.5 kcal/mol (−31.5 kJ/mol), slightly more exergonic [+0.2 kcal/mol (+1 kJ/mol)] than the hydrolysis of ATP to ADP and Pi.
Therefore, thioesters have a high acyl-group transfer potential and can donate the acyl group to a variety of molecules, that is, the acyl group can be considered an activated group ready for transfer. It can also be stated that formation of the thioester bond conserves part of the free energy released during the oxidation of metabolic fuels.
Note that coenzyme A is also abbreviated as CoA-SH to emphasize the role of the thiol group.[4]
Note: in a thioester bond, a sulfur atom occupies the position where an oxygen atom is found in an ester bond.[8]
Ester and Thioester Bonds
Nicotinamide adenine dinucleotide
Nicotinamide adenine dinucleotide (NAD+) can be synthesized from tryptophan, an essential amino acid, or from niacin, or vitamin B3, or vitamin PP (from “Pellagra-Preventing”), the source of the nicotinamide moiety.
Reduced and Oxidized Forms of Nicotinamide Adenine Dinucleotide
NAD+ participates in the reaction catalyzed by dihydrolipoyl dehydrogenase and, like FAD, carries out electron (hydride) transfer.[4]
Lipoic acid
Unlike the other coenzymes of the pyruvate dehydrogenase complex, lipoic acid does not derive, directly or indirectly, from vitamins and/or essential amino acids, that is, from building blocks that cannot be synthesized de novo and must be supplied through the diet.
It is the coenzyme of dihydrolipoyl transacetylase, to which it is covalently bound through an amide linkage to the ε-amino group of a lysine residue to form lipoyl-lysine, or lipoamide, the so-called lipoyl-lysine arm. It couples electron transfer with acyl-group transfer.[9]
Lipoamide or Lipoyl-lysine
Lipoic acid has two thiol groups that can undergo reversible intramolecular oxidation to form a disulfide bridge (–S–S–), a reaction analogous to that occurring between two cysteine residues (Cys).
Because the disulfide bridge (a cyclic disulfide) can undergo redox reactions, during the reactions catalyzed by the pyruvate dehydrogenase complex it is first reduced to dihydrolipoamide, a dithiol (the reduced form of the prosthetic group), and then reoxidized to the cyclic form.[1]
Note
Many enzymes require small non-protein components, called cofactors, for their catalytic activity. Cofactors may be metal ions or small organic or organometallic molecules and are classified as coenzymes and prosthetic groups.
A prosthetic group is a cofactor that binds tightly to an enzyme by noncovalent or covalent bonds, that is, it is permanently bound to the protein. TPP, FAD, and lipoic acid are considered prosthetic groups in the PDC due to their tight binding.
A coenzyme (e.g. CoA or NAD+) is a cofactor that is not permanently bound to the enzyme.[5]
Cellular location of the pyruvate dehydrogenase complex
In eukaryotes, the pyruvate dehydrogenase complex, like the enzymes of the citric acid cycle and fatty acid oxidation, is located in the mitochondrion, where it is associated with the surface of the inner membrane facing the matrix.
In prokaryotes, it is located in the cytosol.[6]
Functions of the pyruvate dehydrogenase complex
The main functions of the pyruvate dehydrogenase complex are the production of acetyl-CoA and NADH.
The acetyl group linked to coenzyme A, an activated acetate, can be:
oxidized to two carbon dioxide molecules via the reactions of the citric acid cycle, harvesting a portion of the potential energy in the form of ATP or GTP;
used for the synthesis of fatty acids, cholesterol, steroids, isoprenoids, ketone bodies, and acetylcholine.
It is therefore possible to state that, depending on the metabolic conditions and/or the cell type, the pyruvate dehydrogenase complex commits carbon intermediates from amino acid and glucose catabolism to:
the citric acid cycle, and thus to energy production, for example, in skeletal muscle under aerobic conditions, and always in cardiac muscle;
In aerobic organisms, NADH can be oxidized to NAD+ by transferring a hydride ion to Complex I of the mitochondrial electron transport chain, which in turn carries the two electrons to molecular oxygen (O2), allowing the production of 2.5 ATP molecules per pair of electrons.[1]
Note: in anaerobic organisms there are electron acceptors alternative to oxygen, such as sulfate or nitrate.[11]
Conceptually, the pyruvate dehydrogenase complex represents the bridge between glycolysis and the citric acid cycle. However, due to the irreversibility of the overall reaction catalyzed by the multienzyme complex, it acts as a one-way bridge: pyruvate can be decarboxylated and oxidized, and the remaining acetyl unit can be linked to CoA, but the reverse reaction, conversion of acetyl-CoA to pyruvate, is not possible.
The irreversibility of this reaction, together with the absence of alternative pathways, explains why acetyl-CoA, and therefore fatty acids, cannot be used as substrates for gluconeogenesis.[5]
Other sources of acetyl-CoA
Besides pyruvate, the acetyl group of acetyl-CoA can derive from the oxidation of fatty acids and the catabolism of many amino acids. However, regardless of its origin, acetyl-CoA represents an entry compound for new carbon units into the citric acid cycle. It may also be stated that the acetyl group of acetyl-CoA is the form in which most carbon enters the cycle.[10]
Mitochondrial pyruvate transport
In eukaryotes, glycolysis occurs in the cytosol, whereas all subsequent steps of aerobic metabolism, that is, the reactions catalyzed by the pyruvate dehydrogenase complex, the citric acid cycle, the electron transport chain, and oxidative phosphorylation, take place in the mitochondria.[12]
Similarly to most other metabolites and anions, the transport of pyruvate across the outer mitochondrial membrane is probably mediated by a relatively nonspecific, voltage-dependent anion channel. Conversely, its transport across the inner mitochondrial membrane occurs through a specific transporter composed of two proteins named MPC1 and MPC2 (Mitochondrial Pyruvate Carrier), which form a hetero-oligomeric complex in the membrane, catalyzing a pyruvate/H+ symport towards the matrix.[13]
Structure of the pyruvate dehydrogenase complex
Although the pyruvate dehydrogenase complex is composed of multiple copies of three different enzymes and catalyzes the same reactions through similar mechanisms in all organisms in which it is present, it nevertheless displays very different quaternary structures.[6]
Structure of the E. coli complex
The structure of the E. coli multienzyme complex, which has a mass of ≈ 4,600 kDa and a diameter of ≈ 300 Å, was the first to be characterized, thanks to the work of Lester Reed. In this complex, 24 units of dihydrolipoyl transacetylase form a structure with cubic symmetry; the enzymes, associated as trimers, are located at the corners of a cube. Dimers of pyruvate dehydrogenase are associated with the dihydrolipoyl transacetylase core at the center of each edge of the cube, for a total of 24 units. Finally, dimers of dihydrolipoyl dehydrogenase are located at the center of each of the six faces of the cube, for a total of 12 units. Note that the entire complex is composed of 60 units. A similar structure with cubic symmetry is also found in most other Gram-negative bacteria.[14]
Structure of the eukaryotic and Gram-positive bacterial complex
In some Gram-positive bacteria and in eukaryotes, the pyruvate dehydrogenase complex has a dodecahedral form, namely, that of a regular polyhedron with 20 vertices, 12 pentagonal faces, and 30 edges, with icosahedral symmetry (also called I symmetry). For example, the mitochondrial multienzyme complex is the largest known multienzyme complex, with a mass of ≈ 10,000 kDa (10 MDa) and a diameter of ≈ 500 Å, more than five times the size of a ribosome. Notably, it can be visualized by electron microscopy.[15][16]
The complex consists of a dodecahedral core, with a diameter of about 25 nm, formed, as in Gram-negative bacteria, by dihydrolipoyl transacetylase, but composed of 20 trimers of the enzyme (60 units) located at the vertices of the structure. The core is surrounded by 30 units of pyruvate dehydrogenase, one centered on each edge, and 12 units of dihydrolipoyl dehydrogenase, one centered on each face. The entire complex therefore contains 102 units.[2]
Additional subunits
The quaternary structure of the pyruvate dehydrogenase complex is further complicated, as mentioned previously, by the presence of three additional subunits: a pyruvate dehydrogenase kinase, a pyruvate dehydrogenase phosphatase, and the E3-binding protein (E3BP). The kinase and phosphatase are bound to the dihydrolipoyl transacetylase core.[4]
E3BP is bound to each of the 12 pentagonal faces and is therefore present in about 12 copies. It is required for the binding of dihydrolipoyl dehydrogenase to the dihydrolipoyl transacetylase core, as demonstrated by the fact that its partial proteolysis reduces the binding ability of the dehydrogenase.[17]
In the E3-binding protein, one can identify a C-terminal domain, which has no catalytic activity, and a lipoamide-containing domain, similar to that of dihydrolipoyl transacetylase, capable of accepting an acetyl group. However, removal of this domain does not reduce the catalytic activity of the multienzyme complex.[18]
Structure of pyruvate dehydrogenase
Pyruvate dehydrogenase in eukaryotes and some Gram-positive bacteria is composed of two different polypeptide chains, called α and β, which associate to form a 2-fold symmetric α2β2 heterotetramer. Conversely, in E. coli and other Gram-negative bacteria, the two subunits are fused into a single polypeptide chain, and the enzyme is therefore a homodimer.[6][19]
The enzyme contains two active sites.
In the heterotetrameric structure of Bacillus (Geobacillus) stearothermophilus pyruvate dehydrogenase, a Gram-positive bacterium, each thiamine pyrophosphate molecule binds between the N-terminal domains of an α and a β subunit, at the end of a funnel-shaped channel ≈ 21 Å deep that leads to the active site. Its reactive group, the thiazole ring, is positioned closest to the channel entrance. At this entrance, two conserved loops are present, both essential for the catalytic activity of the enzyme and for its regulation.[20]
Active site architecture and structure
X-ray analysis of the B. stearothermophilus enzyme bound to both TPP and the peripheral subunit-binding domain (PSBD) of dihydrolipoyl transacetylase, which interacts with the C-terminal domain of the β subunits, has revealed that, in addition to having a tightly packed heterotetrameric structure, the two active sites differ structurally, particularly in the arrangement of the two conserved loops.[16] Specifically, in one enzyme subunit, in the presence of activated thiamine pyrophosphate, the inner loop is ordered in such a way that it blocks the entrance to the active site, whereas in the other subunit, the corresponding loop is disordered and does not obstruct the entrance.[21]
This observation explains, from a structural standpoint, the differences in substrate-binding rates exhibited by the two active sites. A similar arrangement and asymmetry have been observed in all thiamine pyrophosphate–dependent enzymes whose structures have been determined.
In addition to TPP and a magnesium ion located in each of the two active sites, a third Mg2+ is positioned at the center of the tetramer, within a ≈ 20 Å deep solvent-filled tunnel that connects the two active sites. The tunnel is largely lined by ten conserved amino acid residues from all four subunits, specifically, six glutamate (Glu) and four aspartate (Asp) residues, along with other acidic residues around the TPP aminopyrimidine ring. Notably, there is a complete absence of basic residues to neutralize them. Similar tunnels have been found in all thiamine pyrophosphate-dependent enzymes with known crystal structures, whether dimeric or tetrameric, such as transketolase, an enzyme of the pentose phosphate pathway.[2]
Note: B. stearothermophilus belongs to the phylum Firmicutes and has recently been renamed Geobacillus stearothermophilus.
Role of the acidic tunnel
Mutagenesis experiments on B. stearothermophilus pyruvate dehydrogenase have shown that the tunnel plays a role in the catalytic mechanism.[22][23]
Changing some of the aforementioned acidic residues to neutral amino acids does not alter, compared with the wild-type enzyme:
the efficiency of incorporation of the modified enzyme into the multienzyme complex;
Nevertheless, the rate of decarboxylation is reduced by more than 70% compared with the wild-type enzyme. Likewise, once the multienzyme complex is assembled with the mutant pyruvate dehydrogenase, the overall PDC activity is reduced by more than 85% relative to the wild-type complex.[23]
How does this occur?
Because the distance between the substituted amino acids and the active sites is ≥ 7 Å, that is, the residues are remote from the active sites, they cannot directly influence catalytic activity. Therefore, the catalytic mechanism described below was proposed.[3]
Proton-wire mechanism and communication between the active sites
In the apoenzyme, thiamine pyrophosphate binds rapidly and tightly to the first active site, becomes activated, and the active site closes, thus protecting the zwitterionic thiazolium from the external environment.
Conversely, in the second active site TPP binds but is not activated, and the active site remains in an open conformation.[4]
In the first active site, pyruvate reacts with the thiazolium C-2. Thiamine pyrophosphate in the second active site, acting as a general acid, donates a proton to the first site. The result is decarboxylation in the first active site and activation of the coenzyme in the second site, which then closes.[3]
It should be noted that, whereas activation of the first thiamine pyrophosphate results from its binding to the active site, activation of the second coenzyme, and thus of the second active site, is coupled to the decarboxylation of pyruvate in the first active site. From another point of view: while one active site requires a general acid, the other requires a general base.[2]
Protons are required for catalytic activity, and their transport between the two active sites occurs through the acidic tunnel. They are reversibly shuttled along a chain of donor–acceptor groups provided by glutamate and aspartate residues and by the entrained water, which together act as a proton wire.
Thus, unlike many other enzymes in which communication between active sites occurs through conformational changes and subunit rearrangements, in pyruvate dehydrogenase and other TPP–dependent enzymes, the proton wire is the molecular basis for such communication.[22]
At this point, the holoenzyme has been formed, and the active sites are in dynamic equilibrium, each alternating between the dormant and activated states (flip-flop mechanism). This appears to be the state in which the enzyme exists in vivo at the start of each catalytic cycle.[19]
Implications of proton-wire-mediated asymmetry for catalysis
A consequence of this mechanism is that, as the catalytic cycles proceed, the two active sites remain out of phase with each other; when one active site requires a general acid, the other requires a general base, and vice versa.[22]
Finally, it should be noted that this mechanism allows the loops that close the active sites to switch in a coordinated fashion, thereby:
coordinating substrate uptake and product release;
explaining the asymmetry between the two active sites.[23]
Note: an apoenzyme is an enzyme lacking its cofactors. Conversely, a holoenzyme is the apoenzyme together with its cofactors. The apoenzyme is catalytically inactive, whereas the holoenzyme is catalytically active.[5]
Structure of dihydrolipoyl transacetylase
Three functionally distinct domains can be identified in the structure of dihydrolipoyl transacetylase: an N-terminal lipoyl domain, a peripheral subunit-binding domain, and a C-terminal catalytic (or acyltransferase) domain. These domains are connected by 20- to 40-residue linkers that are rich in alanine and proline, hydrophobic residues interspersed with charged ones. These linkers are highly flexible and largely extended, which allows the three domains to remain separated from each other.[25][26]
E2 Domains
Note: flexible linkers are also present in E3BP.
The lipoyl domain
The N-terminal lipoyl domain is composed of ≈ 80 amino acid residues and is so called because it binds lipoic acid. The number of these domains varies by species, ranging from one to three. For example, there is one domain in Enterococcus faecalis, two in mammals, and three in Azotobacter vinelandii and E. coli.[27][28]
The linkage between the ɛ-amino group of a lysine residue and lipoic acid results in a flexible arm, the lipoyl-lysine, which has a maximum extended length of ≈ 14 Å. When considering the length of the lipoyl-lysine arm and the highly flexible 20- to 40-residue linker (which can span greater than 140 Å distance between active sites), the resulting flexible tether is capable of swinging the lipoyl group between the active sites of pyruvate dehydrogenase and dihydrolipoyl dehydrogenase, as well as interacting with neighboring dihydrolipoyl transacetylases within the core.[2][29]
Notably, the number of these tethers is 3 × 24 = 72 in E. coli, whereas in mammals it is 2 × 60 = 120, based on the number of N-terminal domains and the number of dihydrolipoyl transacetylase units.
A single pyruvate dehydrogenase can therefore acetylate numerous dihydrolipoyl transacetylases, and one dihydrolipoyl dehydrogenase can reoxidize many dihydrolipoamide groups.
Moreover, the following also occur:
interchange of acetyl groups between the lipoyl groups of the dihydrolipoyl transacetylase core;
exchange of both acetyl groups and disulfides between the tethered arms.[25]
The peripheral subunit-binding domain
PSBD is composed of ≈ 35 amino acid residues arranged into a globular structure that binds both pyruvate dehydrogenase and dihydrolipoyl dehydrogenase; that is, it helps hold the multienzyme complex together.[30]
The C-terminal catalytic domain
The C-terminal catalytic domain, which contains the active site, consists of ≈ 250 amino acid residues arranged into a hollow, cage-like structure containing channels large enough to allow substrates and products to diffuse in and out. For example, CoA and lipoamide, the two substrates of dihydrolipoyl transacetylase, bind in their extended conformations at opposite ends of a channel located at the interface between each pair of subunits in each trimer.[26][31]
Structure of dihydrolipoyl dehydrogenase
The structure of dihydrolipoyl dehydrogenase has been deduced from studies of the enzyme in several microorganisms. It has a homodimeric structure, with each ≈ 470-residue polypeptide chain folded into four domains, from the N-terminal to the C-terminal end: a FAD-binding domain, a NAD+-binding domain, a central domain, and an interface domain. All domains participate in the formation of the active site.[32]
FAD is almost completely buried inside the protein because, unlike a thiol or NADH, it is easily oxidized and must therefore be protected from the surrounding solution. In fact, in the absence of the nicotinamide coenzyme, the phenolic side chain of a tyrosine residue (e.g., Tyr181 in the Gram-negative bacterium Pseudomonas putida) covers the NAD+-binding pocket so as to protect FADH2 from exposure to the solvent.[2]
Conversely, when NAD+ occupies the active site, the phenolic side chain of the this tyrosine residue becomes interposed between the nicotinamide ring and the flavin ring.[33]
In the oxidized form of the enzym, a redox-active disulfide bridge is present. It forms between two cysteine residues located in a highly conserved segment of the polypeptide chain, e.g., Cys43 and Cys48 in P. putida, and is positioned on the side of the flavin ring opposite the nicotinamide ring. This bridge connects consecutive turns of a distorted α-helix; without this distortion, the Cα atoms of the two cysteine residues would be too far apart to allow disulfide bond formation.[34]
Dihydrolipoyl dehydrogenase therefore has two electron acceptors: FAD and the redox-active disulfide bridge.
Note: the heterocyclic rings of NAD and FAD are parallel and in contact through van der Waals interactions; the sulfur atom of Cys48 is also in van der Waals contact with the flavin ring on the side opposite the NAD ring.[2]
Reaction of pyruvate dehydrogenase
In the reaction sequence catalyzed by the components of the pyruvate dehydrogenase complex, pyruvate dehydrogenase catalyzes the first two steps:
the decarboxylation of pyruvate to form CO2 and the hydroxyethyl-TPP intermediate;
the reductive acetylation of the lipoyl group of dihydrolipoyl transacetylase.
The first reaction is essentially identical to the reaction catalyzed by pyruvate decarboxylase (EC 4.1.1.1), which carries out a non-oxidative decarboxylation during glucose fermentation to ethanol. What differs is the fate of the hydroxyethyl group bound to thiamine pyrophosphate: in the reaction catalyzed by pyruvate dehydrogenase, this group is transferred to the next enzyme in the sequence, dihydrolipoyl transacetylase, whereas in the reaction catalyzed by pyruvate decarboxylase it is converted into acetaldehyde.[4]
Catalytic mechanism: the first stage
In thiamine pyrophosphate-dependent enzymes, the thiazolium ring is the active center, but only in its dipolar carbanion, or ylid, form, that is, a zwitterion (German for “hybrid ion”) with a positive charge on N-3 and a negative charge on C-2. Conversely, the positively charged thiazolium ring (positively charged nitrogen and no charge on C-2) can be considered the “dormant” or inactive form.[35]
The reaction begins with the nucleophilic attack by the C-2 carbanion on the carbonyl carbon of pyruvate, which has the oxidation state of an aldehyde, leading to the formation of a covalent bond between the coenzyme and pyruvate.
Then, cleavage of the C-1–C-2 bond of pyruvate occurs. This results in the release of the carboxyl group, namely C-1 as CO2, while the remaining carbon atoms, C-2 and C-3, remain bound to thiamine pyrophosphate as a hydroxyethyl group. Cleavage of the C-1–C-2 bond, and thus pyruvate decarboxylation, is favored because the negative charge on carbon C-2, which would otherwise be unstable, is stabilized by the positively charged N-3 of the thiazolium ring, an iminium nitrogen (C=N+). This electrophilic, electron-deficient structure acts as an electron sink, in which the carbanion electrons can be delocalized by resonance.[36]
At this point, the resonance-stabilized intermediate can be protonated to form hydroxyethyl–TPP.[5]
Note: this first reaction catalyzed by pyruvate dehydrogenase is the step at which the pyruvate dehydrogenase complex exerts its substrate specificity; furthermore, it is the slowest of the five reactions and thus rate-limiting for the overall process.[1]
Catalytic Mechanism of Pyruvate Dehydrogenase
Catalytic mechanism: the second stage
Pyruvate dehydrogenase then catalyzes the oxidation of the hydroxyethyl group to an acetyl group and its transfer to the lipoyl-lysyl arm of dihydrolipoyl transacetylase. The reaction begins with the formation of a carbanion on the hydroxyl-bearing carbon of hydroxyethyl–TPP, via removal of its proton by an enzyme base.[5]
The carbanion carries out a nucleophilic attack on the lipoamide disulfide, forming a high-energy acetyl-thioester bond with one of the two –SH groups. During this reaction, oxidation of the hydroxyethyl group to an acetyl group occurs simultaneously with reduction of the lipoamide disulfide bond: the two electrons removed from the hydroxyethyl group are used to reduce the disulfide. This reaction is therefore a reductive acetylation accompanied by regeneration of the active form of pyruvate dehydrogenase, namely the enzyme with thiazolium C-2 in its deprotonated, ylid (dipolar carbanion) form.[36]
Note that the energy derived from the oxidation of the hydroxyethyl group to an acetyl group drives the formation of the thioester bond between the acetyl group and lipoamide.[4]
Note: as previously mentioned, the lipoyl-lysyl arm, arranged in an extended conformation and able to access the active site of pyruvate dehydrogenase where TPP is bound, enables the transfer of the acetyl group, generated by oxidation of hydroxyethyl–TPP, to the lipoamide moiety. The swinging arm then delivers the acetyl group to the active site of dihydrolipoyl transacetylase for transfer to coenzyme A. It can subsequently move to the active site of dihydrolipoyl dehydrogenase.[2]
A deeper look at thiamine pyrophosphate
Thiamine pyrophosphate consists of three chemical moieties on which its chemistry and enzymology depend: a thiazolium ring, a 4-aminopyrimidine ring, and the diphosphate side chain.[37]
The diphosphate side chain anchors the cofactor to the enzyme through electrostatic interactions between its negatively charged phosphoryl groups and the positively charged Ca2+ and Mg2+ ions, which are themselves bound to highly conserved sequences, Gly-Asp-Gly-(GDG) and Gly-Asp-Gly-X26-Asn-Asn (GDG-X26-NN), respectively.[38]
The thiazolium ring plays the central role in catalysis because of its ability to form the C-2 carbanion, which acts as a nucleophilic center on the C-2 atom.[39]
Note: as mentioned previously, once bound to the enzyme, thiamine pyrophosphate positions itself in the active site so that the thiazolium ring lies near the entrance of the channel leading to the active site.[5]
The aminopyrimidine ring has a dual function:
it anchors the coenzyme, holding it in place;
it has a specific catalytic role, participating in acid–base catalysis, as demonstrated by studies with TPP analogs in which the three nitrogen atoms of the ring were substituted in turn. These studies showed that the N-1′ atom and the N-4′ amino group are essential, whereas the N-3′ atom is required to a lesser extent.[4]
How the dipolar carbanion of thiamine pyrophosphate is formed
Three tautomeric forms of the aminopyrimidine ring can be identified in the enzyme-bound coenzyme (before substrate entry):
the canonical 4′-aminopyrimidine tautomer;
the N-1 protonated form (the 4-aminopyrimidinium ion);
Evidence indicates that the 1′,4′-imino tautomer is the form that undergoes deprotonation before the substrate enters the active site. The C-2 proton of the thiazolium ring is “much more acidic than most =C–H groups in other molecules.” Its unusually high acidity, i.e., the ease with which the C-2 proton dissociates, is due to the presence of the quaternary nitrogen in the thiazolium ring, a positively charged atom capable of stabilizing the resulting carbanion by electrostatic attraction.[41]
In the deprotonation reaction, the amino group of the aminopyrimidine ring appears to play an essential role: it acts as a base and is ideally positioned to accept the proton. However, in the 4′-aminopyrimidine tautomer, one of its protons sterically clashes with the C-2 proton, and its pKa is too low to perform the deprotonation efficiently.[37]
A mechanism was therefore proposed in which the side chain of a conserved glutamate residue, for example, βGlu59 in Bacillus stearothermophilus or Glu51 in Saccharomyces uvarum (brewer’s yeast) pyruvate decarboxylase, donates a proton to the aminopyrimidine ring. This converts it to the 1′,4′-iminopyrimidine tautomer, which then accepts the C-2 proton and reverts to the canonical 4′-aminopyrimidine form, enabling formation of the carbanion.[2]
Note: formation of the C-2 carbanion occurs through an intramolecular proton transfer.
Deprotonation of thiamine pyrophosphate
Loss of the C-2 proton of the thiazolium ring converts it from a positively charged ring into a dipolar ion (zwitterion). This change in charge state induces a conformational change in one of the two conserved loops located at the entrance of the active site channel, specifically the inner loop, which in turn causes the channel to close to the surrounding aqueous environment. In this closed conformation, the thiazolium carbanion is protected from electrophiles.[42]
To summarize: deprotonation of thiamine pyrophosphate leads to closure of the active site and protection of the newly formed dipolar carbanion. Thus, TPP-dependent enzymes are active only in the closed conformation.
Conversely, in the other active site (since these enzymes typically have two active sites per dimer), thiamine pyrophosphate is not in the ylid form, the channel remains open, and that site is inactive.[5]
Reaction of dihydrolipoyl transacetylase
In the reaction sequence catalyzed by the components of the pyruvate dehydrogenase complex, dihydrolipoyl transacetylase catalyzes the third step: the transfer of the acetyl group from acetyl-dihydrolipoamide to CoA to form acetyl-CoA and dihydrolipoamide, the fully reduced dithiol form of lipoamide.
It should be noted that the acetyl group, initially linked by a thioester bond to one of the –SH groups of lipoamide, is subsequently transferred to the –SH group of coenzyme A, also via a thioester bond, hence the term transthioesterification.[4]
Catalytic mechanism
During the reaction, the sulfhydryl group of coenzyme A performs a nucleophilic attack on the carbonyl carbon of the acetyl group of acetyl-dihydrolipoamide (bound to dihydrolipoyl transacetylase). This forms a transient tetrahedral intermediate, which then decomposes to produce dihydrolipoamide–dihydrolipoyl transacetylase and acetyl-CoA.
Catalytic Mechanism of Dihydrolipoyl Transacetylase
As mentioned earlier, the mobility of the lipoyl-lysyl arm plays a central role in this mechanism.[43][44]
Reaction of dihydrolipoyl dehydrogenase
In the reaction sequence catalyzed by the pyruvate dehydrogenase complex, dihydrolipoyl dehydrogenase catalyzes the fourth and fifth steps. The enzyme mediates the electron transfers required to regenerate the disulfide bridge of the lipoyl group of dihydrolipoyl transacetylase, that is, to restore the oxidized form of the prosthetic group, thus completing the catalytic cycle of the transacetylase.[5]
The reaction follows a ping-pong catalytic mechanism: it proceeds through two successive half-reactions in which each of the two substrates, NAD+ and dihydrolipoamide, reacts in the absence of the other. During the first half-reaction, release of the first product and formation of an enzyme intermediate occur before the second substrate binds, and the enzyme undergoes a structural change. During the second half-reaction, release of the second product occurs, and the enzyme returns to its initial state, again through a conformational change.[2]
According to the ping-pong kinetic mechanism:
in the first half-reaction, dihydrolipoamide is oxidized to lipoamide;
in the second half-reaction, NAD+ is reduced to NADH.[4][45]
Catalytic mechanism: first half-reaction
Below, the reaction mechanism of P. putida dihydrolipoyl dehydrogenase is described.
In the first half-reaction, oxidized dihydrolipoyl dehydrogenase (E), i.e., the enzyme containing the Cys43–Cys48 disulfide, binds dihydrolipoamide (LH2) to form the enzyme–dihydrolipoamide complex (E–LH2). Subsequently, a sulfur atom of dihydrolipoamide performs a nucleophilic attack on the sulfur of Cys43, forming the lipoamide–Cys43 disulfide bridge (E–S–S–L), while the sulfur of Cys48 is released as a thiolate ion (S48−).[34]
The proton on the second thiol group of lipoamide is then abstracted by histidine (His) 451, which acts as a general acid–base catalyst, leading to the formation of a second thiolate ion, this time on the lipoamide (E–S–S–L–S⁻). This thiolate, through a nucleophilic attack, displaces the sulfur of Cys43, S43, aided by general acid catalysis from His451, which donates a proton to S43. The catalytic action of His451 is essential, as demonstrated by mutagenesis studies in which its substitution with a glutamine residue causes the enzyme to retain ≈ 0.4% of the wild-type catalytic activity.[18]
Then, the thiolate anion S48− interacts, through non-covalent contacts, with the flavin ring near the 4a position; that is, an electron pair of S48−, acting as electron donor, is partially transferred to the oxidized flavin ring, which acts as the electron acceptor. The resulting structure is called a charge-transfer complex.
Meanwhile, the phenolic side chain of Tyr181 continues to hinder access to the flavin ring, thereby protecting it from oxidation by O2.[2]
Dihydrolipoamide Oxidation via E3
To summarize, what occurs is an interchange reaction of disulfide bridges leading to the formation of the oxidized form of lipoamide, the first product, which is released, and the reduced form of dihydrolipoyl dehydrogenase.
Catalytic mechanism: second half-reaction
The second half-reaction involves the reduction of NAD+ to NADH + H+ by electron transfer from the reactive disulfide of the enzyme via FAD.
Oxidation of Reduced E3
It begins with the entry of NAD+ into the active site and its binding to form the E–H2–NAD+ complex. It should be noted that the entry of the coenzyme causes the phenolic side chain of Tyr181 to be pushed aside by the nicotinamide ring.
Following the collapse of the charge-transfer complex, a covalent bond is formed between flavin atom C-4a and S48, accompanied by the extraction of a proton from S43 by flavin atom N-5, yielding the corresponding thiolate anion (S43−).
S43− then carries out a nucleophilic attack on S48, leading to the formation of the redox-active disulfide bridge between Cys43 and Cys48, followed by the cleavage of the covalent bond between S48 and flavin atom C-4a, producing the reduced FADH− anion with a negative charge on atom N-1.
It should be noted that dihydrolipoyl dehydrogenase is now in the oxidized form (E).[34]
FADH− has a transient existence because it instantly transfers a hydride ion to nicotinamide atom C-4, which is juxtaposed to flavin atom N-5. This results in the formation of FAD and of the second product of the reaction, NADH, which is released.[1]
Functional implications and comparison with glutathione reductase
To summarize, what occurs is that the electrons removed from the hydroxyethyl group, which derives from pyruvate, pass via FAD to NAD+. The catalytic cycle of dihydrolipoyl dehydrogenase is therefore completed, with the enzyme and its coenzymes in their oxidized forms. At this point, the catalytic cycle of the entire pyruvate dehydrogenase complex is also completed, and the complex is ready for a new reaction cycle.[1]
Note: unlike the thiazolium ring of thiamine pyrophosphate, FAD does not act as an electron trap or electron sink, but rather as an electron conduit between the reduced redox-active disulfide and NAD+.
The catalytic mechanism of dihydrolipoyl dehydrogenase has been determined by analogy with that of glutathione reductase (EC 1.8.1.7), which is 33% identical and whose structure is more extensively characterized.[46] It should, however, be noted that although the two enzymes catalyze similar reactions, these generally occur in opposite directions:
dihydrolipoyl dehydrogenase uses NAD+ to oxidize two –SH groups to a disulfide (–S–S–);
glutathione reductase uses NADPH to reduce a –S–S– to two thiol groups.
Nevertheless, their active sites are closely superimposable.[2]
Regulation of the pyruvate dehydrogenase complex
In mammals, the regulation of the activity of the pyruvate dehydrogenase complex is essential in both the fed and fasted states. In fact, this multienzyme complex plays a central role in metabolism because, by catalyzing the irreversible oxidative decarboxylation of pyruvate, it represents the entry point of carbon flux into the citric acid cycle or lipid and synthesis (fed state). This flux derives from all carbohydrate sources and ≈ 50% of the carbon skeletons of glucogenic amino acids, which, taken together, account for ≈ 60% of daily caloric intake.[47]
The importance of regulating the conversion of pyruvate into acetyl-CoA is also underscored by the fact that mammals, although able to produce glucose from pyruvate, cannot synthesize it from acetyl-CoA because of the irreversibility of the pyruvate dehydrogenase reaction and the absence of alternative pathways. Thus, inhibition of the activity of the complex allows glucose, and amino acids that can be converted into pyruvate, such as alanine, to be spared when other fuels, for example acetyl-CoA from fatty acid oxidation, are available.[48]
This explains why the activity of the complex is tightly regulated by:
feedback inhibition;
nucleotides;
covalent modifications, namely phosphorylation and dephosphorylation of specific target proteins.[5]
Regulation by feedback inhibition and the energy status of the cell
The activity of the dephosphorylated form of the pyruvate dehydrogenase complex is regulated by feedback inhibition.
Acetyl-CoA and NADH allosterically inhibit the enzymes that catalyze their formation, dihydrolipoyl transacetylase and dihydrolipoyl dehydrogenase, respectively.[49]
In addition, CoA and acetyl-CoA, as well as NAD+ and NADH, compete for binding sites on E2 and E3, respectively, which catalyze reversible reactions. This means that, when the ratios [acetyl-CoA]/[CoA] and [NADH]/[NAD+] are high, the transacetylation and dehydrogenation reactions proceed in reverse. Consequently, dihydrolipoyl transacetylase cannot accept the hydroxyethyl group from TPP because it is maintained in the acetylated form. This causes thiamine pyrophosphate to remain bound to pyruvate dehydrogenase in its hydroxyethyl form, which, in turn, decreases the rate of pyruvate decarboxylation. Hence, high [acetyl-CoA]/[CoA] and [NADH]/[NAD+] ratios indirectly influence pyruvate dehydrogenase activity.[1]
PDC Activity: Regulation by Feedback Inhibition
Links with fatty acid oxidation
Acetyl-CoA and NADH are also produced by fatty acid oxidation, which, like the reactions of the pyruvate dehydrogenase complex, takes place within the mitochondrion. This means that the cell, by regulating the activity of the multienzyme complex, preserves carbohydrate stores when fatty acids are available for energy. This reciprocal relationship between the oxidation of glucose and fatty acids, characterized by the inhibition of glucose utilization when fatty acid availability is high, is known as the Randle cycle (or glucose–fatty acid cycle). For example, during the fasted state, the liver, skeletal muscle, and many other organs and tissues rely primarily on fatty acid oxidation for energy. Conversely, the activity of the multienzyme complex is increased in the fed state, when many different types of cells and tissues mainly use glucose as a fuel.
More generally, when the production of NADH and/or acetyl-CoA exceeds the capacity of the cell to use them for ATP production, the activity of the pyruvate dehydrogenase complex is inhibited. The same is true when there is no need for additional ATP to be produced. In fact, the activity of the multienzyme complex is also sensitive to the energy charge of the cell. Through allosteric mechanisms, high ATP levels inhibit the activity of the pyruvate dehydrogenase component of the complex, whereas high ADP levels, which signal that the energy charge of the cell may be falling, activate it, thus committing the carbon skeletons of carbohydrates and some amino acids to energy production.
Note: in skeletal muscle, the activity of the pyruvate dehydrogenase complex increases with increased aerobic activity, resulting in a greater dependence on glucose as a fuel source.[4]
Regulation by phosphorylation/dephosphorylation
Unlike prokaryotes, in mammals the activity of the pyruvate dehydrogenase complex is also regulated by covalent modifications, namely, the phosphorylation and dephosphorylation of three specific serine residues on the α-subunit of pyruvate dehydrogenase, the enzyme that catalyzes the first and irreversible step of the overall reaction sequence.
Note: since mammalian pyruvate dehydrogenase is a heterotetramer, there are six potential phosphorylation sites.[1]
PDC Activity: Regulation by Covalent Modifications
Phosphorylation, which inactivates pyruvate dehydrogenase and thereby blocks the overall reaction sequence, is catalyzed by a Mg2+-dependent pyruvate dehydrogenase kinase. Two of the aforementioned serine residues are located on the more C-terminal loop at the entrance of the substrate channel leading to the respective active site, and phosphorylation of only one of them is sufficient to inactivate pyruvate dehydrogenase, thus demonstrating the out-of-phase coupling between its active sites.[50][51]
Conversely, in the dephosphorylated state the complex is active. Dephosphorylation is catalyzed by a specific protein phosphatase, a Ca2+-activated pyruvate dehydrogenase phosphatase.[52]
The activities of pyruvate dehydrogenase kinase and pyruvate dehydrogenase phosphatase are, in turn, subject to allosteric regulation by several modulators.[53]
Regulation of pyruvate dehydrogenase kinase
The activity of pyruvate dehydrogenase kinase depends on the ratios of [NADH]/[NAD+], [acetyl-CoA]/[CoA], and [ATP]/[ADP], as well as on the pyruvate concentration in the mitochondrial matrix.[54]
High ratios of [NADH]/[NAD+] and [acetyl-CoA]/[CoA], such as those occurring during the oxidation of fatty acids and ketone bodies, activate the kinase. As a result, pyruvate dehydrogenase is phosphorylated, and the pyruvate dehydrogenase complex is inhibited. This allows tissues, such as cardiac muscle, to preserve glucose when fatty acids and/or ketone bodies are being used for energy, because acetyl-CoA synthesis from pyruvate, and therefore from carbohydrates (and some amino acids), is turned off. Conversely, when the concentrations of NAD+ and coenzyme A are high, the activity of the kinase is inhibited and the multienzyme complex is active. Therefore, acetyl-CoA and NADH, two of the three end products of the reactions catalyzed by the pyruvate dehydrogenase complex, control their own synthesis allosterically, both directly and indirectly, by regulating the activity of pyruvate dehydrogenase kinase.
High ratio of [ATP]/[ADP] activates the kinase and thereby inhibits the pyruvate dehydrogenase complex. Note: unlike many other kinases, such as those involved in regulating glycogen metabolism, pyruvate dehydrogenase kinase is not regulated by cAMP levels, but rather by molecules that signal changes in the energy status of the cell and the availability of biosynthetic intermediates, ATP and NADH, and acetyl-CoA, respectively.
Pyruvate allosterically inhibits pyruvate dehydrogenase kinase. When its levels are high, it binds to the kinase and inactivates it; pyruvate dehydrogenase is not phosphorylated, and the pyruvate dehydrogenase complex remains active.
Pyruvate dehydrogenase kinase is also activated by interaction with dihydrolipoyl transacetylase in its acetylated form, i.e., when acetyl-dihydrolipoamide is present.
Other activators of the kinase are potassium and magnesium ions.[2][53]
Regulation of pyruvate dehydrogenase phosphatase
The activity of pyruvate dehydrogenase phosphatase depends on the ratios of [NADH]/[NAD+] and [acetyl-CoA]/[CoA], as well as on the concentration of Ca2+ in the mitochondrial matrix.
Low ratios of [NADH]/[NAD+] and [acetyl-CoA]/[CoA] activate the phosphatase; pyruvate dehydrogenase is dephosphorylated, and the pyruvate dehydrogenase complex is activated. Conversely, when these ratios are high, phosphatase activity decreases, kinase activity increases, and the multienzyme complex is inhibited.
Calcium ion activates pyruvate dehydrogenase phosphatase.
Ca2+ is an important second messenger that signals that the cell requires more energy. Therefore, when its levels are high, as in cardiac muscle cells after epinephrine stimulation or in skeletal muscle cells during muscular contraction, the phosphatase is active, the complex is dephosphorylated, and thus active.
Insulin also contributes to the regulation of the pyruvate dehydrogenase complex by activating pyruvate dehydrogenase phosphatase. In response to increases in blood glucose, the hormone stimulates glycogen synthesis and the synthesis of acetyl-CoA, a precursor for lipid biosynthesis.[2][53]
Fasting and subsequent refeeding also affect the activity of the multienzyme complex.
In tissues such as skeletal muscle, cardiac muscle, and kidney, fasting significantly decreases the activity of the complex, whereas refeeding reverses the inhibition produced by fasting. In the brain, however, these variations are not observed, because the activity of the pyruvate dehydrogenase complex is essential for ATP production.[1][55]
References
^ abcdefghij Nelson D.L., Cox M.M. Lehninger. Principles of biochemistry. 8th Edition. W.H. Freeman and Company, 2021.
^ abcdefghijklmno Heilman D., Woski S., Voet D., Voet J.G., Pratt C.W. Fundamentals of biochemistry: life at the molecular level. 6th Edition. Wiley, 2023.
^ abc Patel M.S., Nemeria N.S., Furey W., Jordan F. The pyruvate dehydrogenase complexes: structure-based function and regulation. J Biol Chem 2014;289(24):16615-16623. doi:10.1074/jbc.R114.563148
^ abcdefghijk Berg J.M., Tymoczko J.L., Gatto G.J. Jr., Stryer L. Biochemistry. 9th Edition. W.H. Freeman and Company, 2019.
^ abcd Bothe S.N., Zdanowicz R. Structural diversity of pyruvate dehydrogenase complexes. FEBS Lett 2025. doi:10.1002/1873-3468.70140
^ Czumaj A., Szrok-Jurga S., Hebanowska A., Turyn J., Swierczynski J., Sledzinski T., Stelmanska E. The pathophysiological role of CoA. Int J Mol Sci 2020;21(23):9057. doi:10.3390/ijms21239057
^ Solomons T.W.G., Fryhle C.B., Snyder S.A. Solomons’ organic chemistry. 12th Edition. John Wiley & Sons Incorporated, 2017.
^ Solmonson A., DeBerardinis R.J. Lipoic acid metabolism and mitochondrial redox regulation. J Biol Chem 2018;293(20):7522-7530. doi:10.1074/jbc.TM117.000259
^ ab Stipanuk M.H., Caudill M.A. Biochemical, physiological, and molecular aspects of human nutrition. 4th Edition. St. Louis: Elsevier, 2018.
^ Lu Z., Imlay J.A. When anaerobes encounter oxygen: mechanisms of oxygen toxicity, tolerance and defence. Nat Rev Microbiol 2021;19(12):774-785. doi:10.1038/s41579-021-00583-y
^ Chaudhry R., Varacallo M.A. Biochemistry, Glycolysis. [Updated 2023 Aug 8]. In: StatPearls [Internet]. Treasure Island (FL): StatPearls Publishing; 2025 Jan-. Available from: https://www.ncbi.nlm.nih.gov/books/NBK482303/
^ Zangari J., Petrelli F., Maillot B., Martinou J.C. The multifaceted pyruvate metabolism: role of the mitochondrial pyruvate carrier. Biomolecules 2020;10(7):1068. doi:10.3390/biom10071068
^ Reed L.J., Pettit F.H., Eley M.H., Hamilton L., Collins J.H., Oliver R.M. Reconstitution of the Escherichia coli pyruvate dehydrogenase complex. Proc Natl Acad Sci USA. 1975;72(8):3068-72. doi:10.1073/pnas.72.8.3068
^ Stoops J.K., Cheng R.H., Yazdi M.A., et al. On the unique structural organization of the Saccharomyces cerevisiae pyruvate dehydrogenase complex. J Biol Chem 1997;272(9):5757-64. doi:10.1074/jbc.272.9.5757
^ ab Zhou Z.H., McCarthy D.B., O’Connor C.M., Reed L.J., Stoops J.K. The remarkable structural and functional organization of the eukaryotic pyruvate dehydrogenase complexes. Proc Natl Acad Sci USA 2001;98(26):14802-7. doi:10.1073/pnas.011597698
^ Forsberg B.O., Aibara S., Howard R.J., Mortezaei N., Lindahl E. Arrangement and symmetry of the fungal E3BP-containing core of the pyruvate dehydrogenase complex. Nat Commun 2020;11(1):4667. doi:10.1038/s41467-020-18401-z
^ ab Ciszak E.M., Makal A., Hong Y.S., Vettaikkorumakankauv A.K., Korotchkina L.G., Patel M.S. How dihydrolipoamide dehydrogenase-binding protein binds dihydrolipoamide dehydrogenase in the human pyruvate dehydrogenase complex. J Biol Chem 2006;281(1):648-55. doi:10.1074/jbc.M507850200
^ ab Wang C., Ma C., Xu Y., et al. Dynamics of the mammalian pyruvate dehydrogenase complex revealed by in-situ structural analysis. Nat Commun 2025;16(1):917. doi:10.1038/s41467-025-56171-8
^ Milne J.L., Wu X., Borgnia M.J., Lengyel J.S., Brooks B.R., Shi D., Perham R.N., Subramaniam S. Molecular structure of a 9-MDa icosahedral pyruvate dehydrogenase subcomplex containing the E2 and E3 enzymes using cryoelectron microscopy. J Biol Chem 2006;281(7):4364-70. doi:10.1074/jbc.M504363200
^ Kale S., Arjunan P., Furey W., Jordan F. A dynamic loop at the active center of the Escherichia coli pyruvate dehydrogenase complex E1 component modulates substrate utilization and chemical communication with the E2 component. J Biol Chem 2007;282(38):28106-16. doi:10.1074/jbc.M704326200
^ abc Frank R.A.W., Titman C.M., Pratap J.V., Luisi B.F., Perham R.N. A molecular switch and proton wire synchronize the active sites in thiamine enzymes. Science 2004;306(5697):872-876. doi:10.1126/science.1101030
^ abc Nemeria N.S., Arjunan P., Chandrasekhar K., Mossad M., Tittmann K., Furey W., Jordan F. Communication between thiamin cofactors in the Escherichia coli pyruvate dehydrogenase complex E1 component active centers: evidence for a “direct pathway” between the 4′-aminopyrimidine N1′ atoms. J Biol Chem 2010;285(15):11197-209. doi:10.1074/jbc.M109.069179
^ Arjunan P., Nemeria N., Brunskill A., Chandrasekhar K., Sax M., Yan Y., Jordan F., Guest J.R., Furey W. Structure of the pyruvate dehydrogenase multienzyme complex E1 component from Escherichia coli at 1.85 A resolution. Biochemistry 2002;41(16):5213-21. doi:10.1021/bi0118557
^ ab Perham R.N. Swinging arms and swinging domains in multifunctional enzymes: catalytic machines for multistep reactions. Annu Rev Biochem 2000;69:961-1004. doi:10.1146/annurev.biochem.69.1.961
^ ab Wang J., Nemeria N.S., Chandrasekhar K., et al. Structure and function of the catalytic domain of the dihydrolipoyl acetyltransferase component in Escherichia coli pyruvate dehydrogenase complex. J Biol Chem 2014;289(22):15215-30. doi:10.1074/jbc.M113.544080
^ Allen A.G., Perham R.N. Two lipoyl domains in the dihydrolipoamide acetyltransferase chain of the pyruvate dehydrogenase multienzyme complex of Streptococcus faecalis. FEBS Lett 1991;287(1-2):206-10. doi:10.1016/0014-5793(91)80052-5
^ Hanemaaijer R., de Kok A., Jolles J., Veeger C. The domain structure of the dihydrolipoyl transacetylase component of the pyruvate dehydrogenase complex from Azotobacter vinelandii. Eur J Biochem 1987;169(2):245-52. doi:10.1111/j.1432-1033.1987.tb13604.x
^ Hale G., Perham R.N. Amino acid sequence around lipoic acid residues in the pyruvate dehydrogenase multienzyme complex of Escherichia coli. Biochem J 1980;187(3):905-8. doi:10.1042/bj1870905
^ Hipps D.S., Packman L.C., Allen M.D., Fuller C., Sakaguchi K., Appella E., Perham R.N. The peripheral subunit-binding domain of the dihydrolipoyl acetyltransferase component of the pyruvate dehydrogenase complex of Bacillus stearothermophilus: preparation and characterization of its binding to the dihydrolipoyl dehydrogenase component. Biochem J 1994;297(Pt 1):137-43. doi:10.1042/bj2970137
^ Schulze E., Westphal A.H., Obmolova G., Mattevi A., Hol W.G., de Kok A. The catalytic domain of the dihydrolipoyl transacetylase component of the pyruvate dehydrogenase complex from Azotobacter vinelandii and Escherichia coli. Expression, purification, properties and preliminary X-ray analysis. Eur J Biochem 1991;201(3):561-8. doi:10.1111/j.1432-1033.1991.tb16315.x
^ Brautigam C.A., Chuang J.L., Tomchick D.R., Machius M., Chuang D.T. Crystal structure of human dihydrolipoamide dehydrogenase: NAD+/NADH binding and the structural basis of disease-causing mutations. J Mol Biol 2005;350(3):543-52. doi:10.1016/j.jmb.2005.05.014
^ abc Mattevi A., Obmolova G., Sokatch J.R., Betzel C., Hol W.G. The refined crystal structure of Pseudomonas putida lipoamide dehydrogenase complexed with NAD+ at 2.45 A resolution. Proteins 1992;13(4):336-51. doi:10.1002/prot.340130406
^ Kern D., Kern G., Neef H., Tittmann K., Killenberg-Jabs M., Wikner C., Schneider G., Hübner G. How thiamine diphosphate is activated in enzymes. Science 1997;275(5296):67-70. doi:10.1126/science.275.5296.67
^ ab Jordan F. Current mechanistic understanding of thiamin diphosphate-dependent enzymatic reactions. Nat Prod Rep 2003;20(2):184-201. doi:10.1039/b111348h
^ ab Nemeria N.S., Chakraborty S., Balakrishnan A., Jordan F. Reaction mechanisms of thiamin diphosphate enzymes: defining states of ionization and tautomerization of the cofactor at individual steps. FEBS J 2009;276(9):2432-46. doi:10.1111/j.1742-4658.2009.06964.x
^ Hawkins C.F., Borges A., Perham R.N. A common structural motif in thiamin pyrophosphate-binding enzymes. FEBS Lett 1989;255(1):77-82. doi:10.1016/0014-5793(89)81064-6
^ Breslow R. Rapid deuterium exchange in thiazolium salts. J Am Chem Soc 1957;79:1762-1763. doi:10.1021/ja01564a064
^ Baykal A.T., Kakalis L., Jordan F. Electronic and nuclear magnetic resonance spectroscopic features of the 1′,4′-iminopyrimidine tautomeric form of thiamin diphosphate, a novel intermediate on enzymes requiring this coenzyme. Biochemistry 2006;45(24):7522-8. doi:10.1021/bi060395k
^ Meyer D., Neumann P., Koers E., Sjuts H., Lüdtke S., Sheldrick G.M., Ficner R., Tittmann K. Unexpected tautomeric equilibria of the carbanion-enamine intermediate in pyruvate oxidase highlight unrecognized chemical versatility of thiamin. Proc Natl Acad Sci USA 2012;109(27):10867-72. doi:10.1073/pnas.1201280109
^ Shaanan B., Chipman D.M. Reaction mechanisms of thiamin diphosphate enzymes: new insights into the role of a conserved glutamate residue. FEBS J 2009 May;276(9):2447-53. doi:10.1111/j.1742-4658.2009.06965.x
^ Yang Y.S., Frey P.A. Dihydrolipoyl transacetylase of Escherichia coli. Formation of 8-S-acetyldihydrolipoamide. Biochemistry 1986;25(25):8173-8. doi:10.1021/bi00373a008
^ Škerlová J., Berndtsson J., Nolte H., Ott M., Stenmark P. Structure of the native pyruvate dehydrogenase complex reveals the mechanism of substrate insertion. Nat Commun 2021;12(1):5277. doi:10.1038/s41467-021-25570-y
^ Massey V., Gibson Q.H., Veeger C. Intermediates in the catalytic action of lipoyl dehydrogenase (diaphorase). Biochem J 1960;77(2):341-51. doi:10.1042/bj0770341
^ Rice D.W., Schulz G.E., Guest J.R. Structural relationship between glutathione reductase and lipoamide dehydrogenase. J Mol Biol 1984;174(3):483-96. doi:10.1016/0022-2836(84)90332-2
^ Denton R.M., Randle P.J., Bridges B.J., et al. Regulation of mammalian pyruvate dehydrogenase. Mol Cell Biochem 1975;9(1):27-53. doi:10.1007/BF01731731
^ Gray L.R., Tompkins S.C., Taylor E.R. Regulation of pyruvate metabolism and human disease. Cell Mol Life Sci 2014;71(14):2577-2604. doi:10.1007/s00018-013-1539-2
^ Harris R.A., Bowker-Kinley M.M., Huang B., Wu P. Regulation of the activity of the pyruvate dehydrogenase complex. Adv Enzyme Regul 2002;42:249-59. doi:10.1016/s0065-2571(01)00061-9
^ Kolobova E., Tuganova A., Boulatnikov I., Popov K.M. Regulation of pyruvate dehydrogenase activity through phosphorylation at multiple sites. Biochem J 2001;358(Pt 1):69-77. doi:10.1042/0264-6021:3580069
^ Hiromasa Y., Fujisawa T., Aso Y., Roche T.E. Organization of the cores of the mammalian pyruvate dehydrogenase complex formed by E2 and E2 plus the E3-binding protein and their capacities to bind the E1 and E3 components. J Biol Chem 2004;279(8):6921-33. doi:10.1074/jbc.M308172200
^ Roche T.E., Baker J.C., Yan X., et al. Distinct regulatory properties of pyruvate dehydrogenase kinase and phosphatase isoforms. Prog Nucleic Acid Res Mol Biol 2001;70:33-75. doi:10.1016/s0079-6603(01)70013-x
^ abc Pettit F.H., Pelley J.W., Reed L.J. Regulation of pyruvate dehydrogenase kinase and phosphatase by acetyl-CoA/CoA and NADH/NAD ratios. Biochem Biophys Res Commun 1975;65(2):575-82. doi:10.1016/s0006-291x(75)80185-9
^ Patel M.S., Korotchkina L.G. Regulation of the pyruvate dehydrogenase complex. Biochem Soc T 2006;34(2):217-222. doi:10.1042/bst0340217
^ Small L., Brandon A.E., Quek L.E., Krycer J.R., James D.E., Turner N., Cooney G.J. Acute activation of pyruvate dehydrogenase increases glucose oxidation in muscle without changing glucose uptake. Am J Physiol Endocrinol Metab 2018;315(2):E258-E266. doi:10.1152/ajpendo.00386.2017
The pentose phosphate pathway, also known as the phosphogluconate pathway, is a metabolic route common to all living organisms that oxidizes glucose and serves as an alternative to glycolysis. It branches off after the formation of glucose 6-phosphate (G6P) and is also referred to as the hexose monophosphate shunt, where shunt denotes a metabolic diversion or bypass.
Its primary function is the production, in varying proportions, of NADPH, a reduced coenzyme, and ribose 5-phosphate, a five-carbon phosphorylated sugar (i.e., a pentose phosphate), from which the pathway derives its name.[1]
Conceptually, the pathway consists of two phases: an oxidative phase, in which NADPH is generated, and a non-oxidative phase, which produces ribose 5-phosphate and other phosphorylated carbohydrates.[2]
It is estimated that over 10% of cellular glucose is metabolized via this pathway, which notably oxidizes glucose without directly producing or consuming ATP.[3]
Summary: Key Points
Definition: a cytosolic pathway for the oxidative metabolism of glucose, alternative to glycolysis, whose main function is the production, in variable proportions, of NADPH and ribose 5-phosphate.
Fate of NADPH: produced in the oxidative phase, it provides the reducing power required for reductive biosyntheses and antioxidant defense mechanisms.
Fate of ribose 5-phosphate: produced in the non-oxidative phase, it is used for the synthesis of nucleotides and various coenzymes.
Key enzymes: glucose 6-phosphate dehydrogenase, regulated by the NADP+/NADPH ratio, and transketolase, a thiamine pyrophosphate–dependent enzyme.
Metabolic flexibility: the pathway adapts to cellular needs, operating in different modes to favor the production of NADPH, ribose 5-phosphate, or the recovery of carbon in the form of glycolytic intermediates.
The first evidence of the pentose phosphate pathway emerged in the 1930s through the work of Otto Warburg, who received the Nobel Prize in Physiology or Medicine in 1931 for his work on cellular metabolism and respiratory enzymes.[4]
Warburg and his collaborator Erwin Christian discovered NADP during studies on the oxidation of glucose 6-phosphate to 6-phosphogluconate.
Further evidence came from observations that glucose metabolism continued in tissues even in the presence of glycolysis inhibitors such as fluoride and iodoacetate ions, which inhibit enolase (EC 4.2.1.11) and glyceraldehyde 3-phosphate dehydrogenase (EC 1.2.1.12), respectively.[5]
However, the pathway was fully elucidated only in the 1950s, thanks to the work of several researchers, notably Efraim Racker, Bernard Horecker, Frank Dickens, and Fritz Lipmann, who received the Nobel Prize in Physiology or Medicine in 1953 for his discovery of coenzyme A, not specifically for the pentose phosphate pathway, although his work was highly relevant in the broader context of intermediary metabolism.[6][7]
Main function
The primary function of the pentose phosphate pathway is the production of NADPH and ribose 5-phosphate.[8]
NADPH is needed for reductive biosynthesis, such as the synthesis of fatty acids, cholesterol, steroid hormones and two non-essential amino acids, proline and tyrosine, from glutamate and phenylalanine, respectively, as well as for the reduction of oxidized glutathione. In these reactions, the reduced coenzyme acts as an electron donor, more precisely as a hydride ion donor (:H−), a species composed of one proton and two electrons.[1][9]
Reduced and Oxidized Forms of Nicotinamide Adenine Dinucleotide Phosphate
Note: In vertebrates, approximately half of the NADPH required for the reductive steps of fatty acid synthesis is produced via the pentose phosphate pathway. The remainder is generated by the reaction catalyzed by the malic enzyme (EC 1.1.1.40).[10]
Malate + NADP+ ⇌ Pyruvate + NADPH + CO2
Ribose 5-phosphate is used in the synthesis of nucleotides and nucleic acids (DNA and RNA), as well as ATP, and coenzymes such as coenzyme A, NAD, NADP, and FAD. It also plays a role in the biosynthesis of the essential amino acids tryptophan and histidine.[8] This five-carbon phosphorylated sugar is not used directly; instead, it is converted to 5-phosphoribosyl 1-pyrophosphate (PRPP) in a reaction catalyzed by ribose phosphate pyrophosphokinase, also known as PRPP synthase (EC 2.7.6.1).[10]
Ribose 5-phosphate + ATP → 5-Phosphoribosyl 1-pyrophosphate + AMP
Additional functions
In addition to producing NADPH and ribose 5-phosphate, the pentose phosphate pathway also serves other functions, both anabolic and catabolic.
In yeasts and many bacteria, it is involved in the catabolism of the five-carbon sugars ribose, xylose, and arabinose.[9]
In humans, it also contributes to the catabolism of the aforementioned pentoses, as well as of less common sugars containing three, four, or seven carbon atoms, derived from the diet or from endogenous sources. These include:
pentoses released during the breakdown of structural carbohydrates;
ribose 5-phosphate generated from nucleotide catabolism.[11][12]
In photosynthetic organisms, it contributes to carbon dioxide (CO2) fixation during the Calvin cycle.[9]
In addition to ribose 5-phosphate, the pathway also provides several intermediates for other biosynthetic processes, including:
erythrose 4-phosphate, used in the synthesis of the aromatic amino acids phenylalanine, tryptophan, and tyrosine;
ribulose 5-phosphate, a precursor in riboflavin (vitamin B2) biosynthesis;
sedoheptulose 7-phosphate, which, in Gram-negative bacteria, is involved in the synthesis of heptose units found in the lipopolysaccharide layer of the outer membrane.[1][13]
Sites of the pentose phosphate pathway
In animal cells and bacteria, the hexose monophosphate shunt, like glycolysis, fatty acid synthesis, and most reactions of gluconeogenesis, occurs in the cytosol. Notably, glycolysis, gluconeogenesis, and the pentose phosphate pathway are interconnected through several shared enzymes and intermediates.[12]
In plant cells, the pentose phosphate pathway takes place in the plastids, and its intermediates can reach the cytosol through membrane pores in these organelles.[10]
In humans, the expression of the enzymes involved in the pathway varies significantly between tissues. Relatively high levels are found in the liver, adrenal cortex, testes, ovaries, thyroid, mammary glands during lactation, and in red blood cells.[2] In all these tissues, a constant supply of NADPH is required to sustain reductive biosynthesis and/or to counteract reactive oxygen species (ROS), which can damage sensitive cellular structures such as DNA, membrane lipids, and proteins. This protection is largely achieved through the reduction of oxidized glutathione (GSSG) to reduced glutathione (GSH), the major intracellular antioxidant in erythrocytes and most other cells. This reaction is catalyzed by glutathione reductase (EC 1.8.1.7).[14]
High levels of phosphogluconate pathway enzymes are also found in rapidly dividing cells, such as enterocytes, skin cells, bone marrow cells, embryonic cells, and, under pathological conditions, cancer cells. These cells require a continuous supply of ribose 5-phosphate for nucleic acid synthesis.
Conversely, these enzymes are present at very low levels in skeletal muscle, where the pentose phosphate pathway is virtually absent. In this tissue, glucose 6-phosphate is primarily utilized for energy production through glycolysis and the citric acid cycle.[2]
Oxidative phase of the pentose phosphate pathway
The oxidative phase of the pentose phosphate pathway consists of two irreversible oxidation reactions, the first and third steps, and one hydrolysis.
Summary of the Reactions of the Pentose Phosphate Pathway
During this phase, glucose 6-phosphate is converted into ribulose 5-phosphate, a five-carbon phosphorylated sugar that serves as the starting substrate for the reactions of the non-oxidative phase.
This conversion is accompanied by the formation of two molecules of NADPH and the release of carbon 1 of glucose as CO2.[15]
The overall equation is:
Oxidation of glucose 6-phosphate to 6-phosphoglucono-δ-lactone
In the first step of the oxidative phase, glucose 6-phosphate dehydrogenase (G6PD; EC 1.1.1.49) catalyzes the oxidation of glucose 6-phosphate to 6-phosphoglucono-δ-lactone, an intramolecular ester.
This occurs via the transfer of a hydride ion (H−) from carbon 1 of glucose 6-phosphate to NADP+, which acts as the oxidizing agent.[12]
Note: this reaction produces the first molecule of NADPH in the pentose phosphate pathway.
The reaction catalyzed by G6PD is unique to the pathway. As in most metabolic pathways, the first reaction that is unique, known as the committed step, is essentially irreversible.
In the liver, it has a ΔG of −17.6 kJ/mol (−4.21 kcal/mol), and it is highly allosterically regulated. Indeed, glucose 6-phosphate dehydrogenase serves as the major control point for the flux of metabolites through the pentose phosphate pathway.[5]
G6PD expression and immune function
In humans, the highest levels of G6PD are found in neutrophils and macrophages, two types of phagocytic cells.
During inflammation, these cells use NADPH to generate superoxide radicals (O2•−) from molecular oxygen, in a reaction catalyzed by NADPH oxidase (EC 1.6.3.1).
2 O2 + NADPH → 2 O2•− + NADP+ + H+
Superoxide radicals are used to generate, for antimicrobial defense, both other reactive oxygen species (ROS) and reactive nitrogen species (RNS), such as:[2]
hydrogen peroxide (H2O2), via the reaction catalyzed by superoxide dismutase (SOD; EC 1.15.1.1)
2 O2•− + 2 H+ → H2O2 + O2
peroxynitrite (ONOO−), via the reaction with nitric oxide (•NO)
O2•− + •NO → ONOO−
hydroperoxide radical (HOO•)
O2•− + H+ → HOO•
Catalytic mechanism of G6PD
The catalytic mechanism of glucose 6-phosphate dehydrogenase has been studied in great detail in the microorganism Leuconostoc mesenteroides, whose enzyme displays the unusual ability to use NAD+ and/or NADP+ as coenzyme.
Catalytic Mechanism of Glucose 6-Phosphate Dehydrogenase
The enzyme does not require metal ions for its activity. Instead, an amino acid residue in the active site acts as a general base, capable of abstracting a proton from the hydroxyl group attached to carbon 1 of glucose 6-phosphate.[16]
In the bacterial enzyme, this function is performed by the Nɛ2 atom of the imidazole ring in a histidine side chain. This nitrogen atom contains a lone pair of electrons that enables it to act as a nucleophile.
Its action facilitates the oxidation of glucose 6-phosphate, a cyclic hemiacetal with C-1 in the aldehyde oxidation state, into a cyclic ester, specifically a lactone.
Simultaneously, the hydride ion is transferred from C-1 of glucose 6-phosphate to the C-4 position of the nicotinamide ring of NADP+ to form NADPH.
Since this histidine residue is conserved in many of the glucose 6-phosphate dehydrogenase sequences identified so far, it is likely that this catalytic mechanism is common to G6PD enzymes across a wide range of organisms.[17]
Regulation of G6PD
Glucose 6-phosphate dehydrogenase is the primary control point in the pentose phosphate pathway and the main regulator of NADPH production.[18]
In humans, G6PD exists in two forms:
an inactive monomeric form;
an active form, which exists in a dimer–tetramer equilibrium.[14]
One of the main modulators of its activity is the cytosolic NADP+/NADPH ratio.
NADPH acts as a competitive inhibitor, while NADP+ is both a substrate and a structural activator, stabilizing the enzyme’s active conformation by binding to a regulatory site near the dimer interface, helping to maintain the dimeric (active) structure.
Regulation of G6PD Activity
Under typical metabolic conditions, the NADP+/NADPH ratio is low.
As a result, NADP+ availability is limited, less coenzyme binds to the enzyme, and G6PD activity is reduced, regardless of expression levels. In these conditions, the oxidative phase of the pathway is virtually inactive.
Conversely, in cells where NADPH-consuming reactions are active (e.g., fatty acid synthesis, antioxidant defense), the cytosolic concentration of NADPH decreases, while NADP+ increases.
This change promotes the activation of G6PD, triggering the oxidative phase of the hexose monophosphate pathway.
Therefore, the fate of glucose 6-phosphate is influenced by the cell’s current demand for NADPH.[19][20]
A second regulatory mechanism involves the accumulation of acyl-CoAs, intermediates in fatty acid biosynthesis.[8] These molecules bind to the dimeric form of G6PD and induce its dissociation into monomers, resulting in the loss of catalytic activity.[14]
Insulin also plays a role by upregulating the expression of the genes encoding glucose 6-phosphate dehydrogenase and 6-phosphogluconate dehydrogenase.
Thus, in the well-fed state, insulin enhances the carbon flux through the pentose phosphate pathway, increasing NADPH production
Note: insulin also promotes fatty acid synthesis, which depends on a continuous supply of NADPH.[15]
Hydrolysis of 6-phosphoglucono-δ-lactone to 6-phosphogluconate
In the second step of the oxidative phase, 6-phosphoglucono-δ-lactone is hydrolyzed to form 6-phosphogluconate, a linear molecule.
Although 6-phosphoglucono-δ-lactone is hydrolytically unstable and can undergo spontaneous (nonenzymatic) ring-opening at a significant rate, this hydrolysis reaction is greatly accelerated in the cell by the enzyme 6-phosphogluconolactonase (EC 3.1.1.31).[21]
The reaction is catalyzed by 6-phosphogluconate dehydrogenase (EC 1.1.1.44), an enzyme that requires Mg2+ ions for activity.[5]
6-Phosphogluconate + NADP+ → Ribulose 5-phosphate + NADPH + CO2
Catalytic mechanism of 6-phosphogluconate dehydrogenase
The catalytic mechanism of 6-phosphogluconate dehydrogenase closely resembles that of isocitrate dehydrogenase (EC 1.1.1.41), a key enzyme of the citric acid cycle.[5]
It proceeds via acid-base catalysis through a three-step mechanism, involving two strictly conserved amino acid residues, a lysine (Lys) and a glutamate (Glu).[22]
In humans:
Lys185, which acts as both a general base and a general acid;
Catalytic Mechanism of 6-Phosphogluconate Dehydrogenase
Step 1: oxidation
In the first step, 6-phosphogluconate is oxidized to a β-keto acid, specifically 3-keto-6-phosphogluconate.
The ε-amino group of Lys185 acts as a general base, abstracting a proton from the hydroxyl group at C-3 of 6-phosphogluconate.
This promotes the transfer of a hydride ion (H−) from C-3 of the substrate to C-4 of the nicotinamide ring in NADP+, yielding NADPH.
The 3-keto intermediate and NADPH are released from the active site.
Step 2: decarboxylation
The 3-keto-6-phosphogluconate formed is highly unstable and undergoes a spontaneous decarboxylation, resulting in:
the formation of CO2 (from C-1 of the original glucose 6-phosphate);
the intermediate cis-1,2-enediol of ribulose 5-phosphate, a high-energy tautomer.
In this step Lys185 acts as a general acid, donating a proton to the C-3 carbonyl oxygen, facilitating the decarboxylation.
Step 3: Keto–enol tautomerization
In the final step, the cis-1,2-enediol intermediate undergoes a stereospecific keto–enol tautomerization to form ribulose 5-phosphate.
Glu192 donates a proton to the C-1 of the enediol.
Simultaneously, the ε-amino group of Lys185 acts as a base, abstracting a proton from the hydroxyl group on C-2.
The result is the formation of ribulose 5-phosphate, completing the oxidative phase of the pentose phosphate pathway.[22][23]
Non-oxidative phase of the pentose phosphate pathway
In the non-oxidative phase of the pentose phosphate pathway, several phosphorylated carbohydrates are produced, and their fate depends on the cell’s relative needs for NADPH, ribose 5-phosphate, and ATP.
This phase consists of five freely reversible steps, involving a series of interconversions of phosphorylated sugars.
It begins with two initial reactions: an isomerization and an epimerization.
These transform ribulose 5-phosphate into:
Epimerases (EC 5.1), a subclass of isomerases, catalyze configurational changes at a single asymmetric carbon atom, typically via a deprotonation/protonation mechanism.
In contrast, isomerases mediate the rearrangement of chemical groups between different carbon atoms.[24]
Note: enzymatic isomerizations and epimerizations play a key role in carbohydrate metabolism, enabling the interconversion of sugars with distinct functional properties.[25]
Isomerization of ribulose 5-phosphate to ribose 5-phosphate
In the first step of the non-oxidative phase, ribulose 5-phosphate (a ketose) is converted into its corresponding aldose, ribose 5-phosphate, via an isomerization reaction.
The reaction is catalyzed by phosphopentose isomerase, also known as ribose 5-phosphate isomerase (EC 5.3.1.6).
Ribulose 5-phosphate ⇄ Ribose 5-phosphate
This is an example of functional group isomerism, where a ketone is converted into an aldehyde.[1]
Catalytic mechanism of phosphopentose isomerase
The catalytic mechanism of phosphopentose isomerase resembles that of phosphohexose isomerase (EC 5.3.1.9), a glycolytic enzyme. Both involve the formation of a high-energy intermediate, cis-1,2-enediol, through a proton-transfer mechanism that is common in aldose–ketose isomerizations.[26]
In Escherichia coli, the mechanism (described here in the direction of ribulose 5-phosphate formation from ribose 5-phosphate, as occurs in the Calvin cycle of photosynthesis) proceeds as follows.
Catalytic Mechanism of Phosphopentose Isomerase
Step 1: ring opening
The furanose ring of ribose 5-phosphate is opened by interaction with an aspartic acid residue (Asp81), which accepts a proton from the hydroxyl group bound to C-1.
It is likely that a water molecule donates the proton required for this step.
Note: in aqueous solution, spontaneous ring opening of ribose is rare, less than 0.5% occurs naturally.
Step 2: formation of the enediol intermediate
A glutamic acid residue (Glu103) acts as a general base, abstracting a proton from the C-2 carbon. Simultaneously, Asp81 donates a proton. This concerted action leads to the formation of the cis-1,2-enediol intermediate.
Step 3: protonation and product formation
The now protonated Glu103 acts as a general acid, donating a proton to C-1 of the enediol intermediate. At the same time, Asp81 accepts a proton from the hydroxyl group on C-2. These proton transfers lead to the formation of ribulose 5-phosphate.
During ribose 5-phosphate synthesis from ribulose 5-phosphate, as occurs in the pentose phosphate pathway, phosphopentose isomerase functions in reverse, following the same general principles of acid-base catalysis.[27]
Epimerization of ribulose 5-phosphate to xylulose 5-phosphate
The other metabolic fate of ribulose 5-phosphate in the pentose phosphate pathway is its epimerization to xylulose 5-phosphate, a ketose like ribulose 5-phosphate.
This reaction is catalyzed by phosphopentose epimerase (EC 5.1.3.1).[5]
Ribulose 5-Phosphate ⇄ Xylulose 5-Phosphate
Note: xylulose 5-phosphate also acts as a regulatory molecule. It inhibits gluconeogenesis and stimulates glycolysis by modulating the intracellular concentration of fructose 2,6-bisphosphate in the liver.[28]
Catalytic mechanism of phosphopentose epimerase
Like the reactions catalyzed by 6-phosphogluconate dehydrogenase and ribose 5-phosphate isomerase, this reaction also proceeds through the formation of an enediol intermediate.
However, in this case, the double bond is formed between C-2 and C-3, rather than between C-1 and C-2.[5]
During the reaction, an amino acid residue in the enzyme’s active site acts as a general base and abstracts a proton from C-3, leading to the formation of the cis-2,3-enediol intermediate.
Next, an acidic amino acid residue donates a proton back to C-3, but from the opposite face, resulting in inversion at C-3 and formation of xylulose 5-phosphate.[29]
Catalytic Mechanism of Phosphopentose Epimerase
Up to this point, the hexose monophosphate shunt has generated the following, for each molecule of glucose 6-phosphate metabolized:
a pool of three pentose 5-phosphates, ribulose 5-phosphate, ribose 5-phosphate, and xylulose 5-phosphate, which coexist at equilibrium;
two molecules of NADPH.
In the next three steps (steps 6 through 8), the enzymes transketolase (EC 2.2.1.1) and transaldolase (EC 2.2.1.2), key enzymes of the pentose phosphate pathway, catalyze a series of carbon skeleton rearrangements.
These reactions lead to the formation of three-, four-, six-, and seven-carbon sugar phosphates, which can be redirected into other metabolic pathways, depending on the cell’s metabolic needs.[12]
By analyzing the flow of metabolites across different pathways, it becomes clear that the concerted action of transketolase and transaldolase allows the non-oxidative phase of the pentose phosphate pathway to interact with:
glycolysis;
gluconeogenesis;
pathways for the synthesis of various vitamins, coenzymes, and nucleic acid precursors.[1]
Transketolase
Transketolase is the rate-limiting enzyme of the non-oxidative phase of the pentose phosphate pathway and is the first enzyme to act downstream of ribose 5-phosphate isomerase and phosphopentose epimerase.[30]
Discovered independently in 1953 by Horecker and Racker, and named by Racker, transketolase catalyzes the transfer of a two-carbon unit from a ketose donor to an aldose acceptor. This occurs in both the sixth and eighth steps of the pathway.
The ketose donors are typically:
Taking the forward reactions as an example, in the sixth step, the ketose donor xylulose 5-phosphate transfers a two-carbon unit to the aldose acceptor ribose 5-phosphate. This reaction generates glyceraldehyde 3-phosphate, which corresponds to the three-carbon remainder of xylulose 5-phosphate, and sedoheptulose 7-phosphate, a seven-carbon sugar that participates in the subsequent step of the pathway.[31]
In the eighth step, xylulose 5-phosphate once again acts as the donor, but this time the acceptor is erythrose 4-phosphate. The products of this reaction are another molecule of glyceraldehyde 3-phosphate and fructose 6-phosphate.
It is worth noting that three out of the four products generated by transketolase, namely, two molecules of glyceraldehyde 3-phosphate and one of fructose 6-phosphate, are also key intermediates of glycolysis.[30]
Beyond xylulose 5-phosphate, sedoheptulose 7-phosphate, and fructose 6-phosphate, transketolase is also capable of using other 2-keto sugars and a variety of aldose phosphates as substrates.[32]
Transketolase requires thiamine pyrophosphate (TPP) as a cofactor. TPP, the biologically active form of thiamine (vitamin B1), is tightly bound to the enzyme and participates in the transfer of activated aldehyde intermediates by stabilizing the two-carbon carbanions formed during the reaction.[8]
Catalytic mechanism of transketolase
The carbon atom located between the sulfur and nitrogen atoms of the thiazolium ring of thiamine pyrophosphate, namely, the C-2 atom, is significantly more acidic than most =CH groups in other molecules. This is due to the adjacent positively charged nitrogen, which electrostatically stabilizes the carbanion formed upon proton dissociation. As a result, the C-2 proton is readily abstracted, generating a carbanion. This proton abstraction is catalyzed by transketolase.
The resulting carbanion attacks the carbonyl carbon of the donor ketose substrate. In step 6, this is xylulose 5-phosphate (or sedoheptulose 7-phosphate in the reverse reaction); in step 8, it is again xylulose 5-phosphate (or fructose 6-phosphate in reverse). Taking the forward direction of step 6 as an example, the covalent adduct formed between thiamine pyrophosphate and xylulose 5-phosphate undergoes cleavage at the C-2–C-3 bond. This reaction produces glyceraldehyde 3-phosphate, which is released, and a two-carbon hydroxyethyl group, which remains covalently bound to the C-2 atom of the thiazolium ring.
Catalytic Mechanism of Transketolase
The negative charge on this hydroxyethyl intermediate is stabilized by the thiazolium ring of thiamine pyrophosphate. The positively charged nitrogen in the ring acts as an electron sink, delocalizing the carbanion’s negative charge via resonance. In this way, the thiazolium ring provides an electron-deficient (electrophilic) environment that stabilizes the intermediate.
Subsequently, the hydroxyethyl-TPP group condenses with ribose 5-phosphate, the aldehyde acceptor substrate, via nucleophilic attack on the aldehyde carbon. This forms a new covalent adduct with thiamine pyrophosphate.
Finally, cleavage of the adduct releases sedoheptulose 7-phosphate and regenerates the TPP carbanion.[8][12][30]
Transaldolase
Transaldolase was discovered in 1953 by Horecker and Smyrniotis in brewer’s yeast, identified as Saccharomyces cerevisiae. In the seventh step of the pentose phosphate pathway, this enzyme catalyzes the transfer of a three-carbon unit from the donor substrate sedoheptulose 7-phosphate to the acceptor substrate glyceraldehyde 3-phosphate. The reaction yields fructose 6-phosphate and erythrose 4-phosphate.
As in the reactions catalyzed by transketolase, the donor of the carbon unit is a ketose, while the acceptor is an aldose. In the reverse direction, the donor becomes fructose 6-phosphate and the acceptor erythrose 4-phosphate.[9]
Catalytic mechanism of transaldolase
Unlike transketolase, transaldolase does not require a cofactor for its activity.
The reaction proceeds in two steps: an aldol cleavage followed by an aldol condensation. Below, the catalytic mechanism of E. coli transaldolase B is described, taking as an example the forward reaction that produces erythrose 4-phosphate and fructose 6-phosphate.
Step 1: aldol cleavage and intermediate formation
In the first step, the ε-amino group of a lysine residue (Lys132) in the active site performs a nucleophilic attack on the carbonyl carbon (C-2) of sedoheptulose 7-phosphate. This occurs after a proton transfer to a glutamic acid residue (Glu96), mediated by a water molecule. The result is the formation of a carbinolamine intermediate.
Catalytic Mechanism of Transaldolase
Subsequently, the elimination of a water molecule leads to the formation of an enzyme-bound imine, also known as a Schiff base. This step also involves the transfer of a proton from Glu96 to the catalytic water molecule.
Note: this enzyme–substrate covalent intermediate is similar to that formed during the reaction catalyzed by aldolase (EC 4.1.2.13) in glycolysis.
Then, an aspartic acid residue (Asp17) acts as a base and abstracts a proton from the hydroxyl group at C-4. This facilitates the cleavage of the C–C bond between C-3 and C-4, releasing erythrose 4-phosphate, an aldose. The remaining three-carbon carbanion stays covalently bound to the enzyme and is stabilized by resonance. Just like in the transketolase mechanism, the positive charge on the Schiff base nitrogen acts as an electron sink, stabilizing the negative charge on the carbanion.[5][8][12][33]
Step 2: aldol condensation and product release
After the release of erythrose 4-phosphate, the acceptor substrate glyceraldehyde 3-phosphate enters the active site.
The previously formed carbanion performs a nucleophilic attack on the carbonyl carbon of glyceraldehyde 3-phosphate. This aldol condensation results in the formation of a new carbon–carbon bond and a covalently bound ketose intermediate.
The final step involves the hydrolysis of the Schiff base. This reaction restores the free ε-amino group of Lys132 and releases fructose 6-phosphate, a ketose and the second product of the reaction. The enzyme is now regenerated and ready for a new catalytic cycle.
As previously mentioned, in the eighth step of the pentose phosphate pathway, transketolase catalyzes the synthesis of fructose 6-phosphate and glyceraldehyde 3-phosphate from erythrose 4-phosphate and xylulose 5-phosphate, linking the activities of transaldolase and transketolase in the non-oxidative phase of the pathway.[33]
The cell’s need for NADPH, ribose 5-phosphate, and ATP
From a molecular point of view, the fate of glucose 6-phosphate depends largely on the relative activities of the enzymes that metabolize it through glycolysis and the pentose phosphate pathway, particularly phosphofructokinase-1 (PFK-1; EC 2.7.1.11) and glucose 6-phosphate dehydrogenase, both of which are highly regulated.[1]
PFK-1 is inhibited when ATP and/or citrate concentrations increase, that is, when the cell’s energy charge is high. Conversely, it is activated when AMP and/or fructose 2,6-bisphosphate concentrations increase, indicating a low energy charge. As a result, when the energy charge is high, the carbon flux, specifically the flux of glucose 6-phosphate, through glycolysis decreases.[34][35]
G6PD, in contrast, is inhibited by NADPH and by acyl-CoAs, which are intermediates in fatty acid biosynthesis. Thus, when cytosolic NADPH levels rise, the pentose phosphate pathway is downregulated. However, when NADPH levels fall, the inhibition is relieved, the pathway is reactivated, and both NADPH and ribose 5-phosphate are synthesized.[8][19]
Therefore, depending on the cell’s current demand for ATP, NADPH, and ribose 5-phosphate, reactions from glycolysis and the pentose phosphate pathway can be strategically combined to prioritize the synthesis of specific metabolites. This metabolic flexibility is also made possible by the fact that the non-oxidative phase of the pentose phosphate pathway is primarily controlled by substrate availability.
The four main scenarios are outlined below.[12]
When the need for NADPH is much greater than that for ribose 5-phosphate or ATP
When the cellular requirement for NADPH far exceeds that for ribose 5-phosphate or ATP, namely, when no additional ATP is needed and the energy charge is high, glucose 6-phosphate enters the pentose phosphate pathway and is fully oxidized to CO2. These metabolic conditions are typically found in adipose tissue during fatty acid synthesis.
Through a combination of reactions from the non-oxidative phase and selected gluconeogenic reactions, namely, those catalyzed by triose phosphate isomerase (EC 5.3.1.1), aldolase (EC 4.1.2.13), phosphohexose isomerase (EC 5.3.1.9), and fructose 1,6-bisphosphatase (EC 3.1.3.11), six molecules of ribulose 5-phosphate can be converted into five molecules of glucose 6-phosphate. In this way, the non-oxidative phase supports the continuation of the oxidative phase by replenishing the starting substrate.
The process can be divided into three groups of reactions.
Oxidative phase reactions
These reactions are catalyzed by the enzymes of the oxidative phase, producing two molecules of NADPH and one molecule of ribulose 5-phosphate per glucose 6-phosphate.
Non-oxidative phase reactions
These include the enzymes phosphopentose epimerase, ribose 5-phosphate isomerase, transketolase, and transaldolase, which convert ribulose 5-phosphate into fructose 6-phosphate and glyceraldehyde 3-phosphate.
Gluconeogenic reactions
The fructose 6-phosphate and glyceraldehyde 3-phosphate produced in the non-oxidative phase are recycled into glucose 6-phosphate via gluconeogenic reactions. These reactions allow the cycle to restart.
The net result of the last two groups of reactions is the conversion of six molecules of ribulose 5-phosphate into five molecules of glucose 6-phosphate.
6 Ribulose 5-phosphate+ H2O → 5 Glucose 6-phosphate + Pi
Finally, by summing all three groups of reactions, the oxidative phase, non-oxidative phase, and gluconeogenic steps, the overall reaction is:
Glucose 6-phosphate + 12 NADP+ + 7 H2O → 6 CO2 + 12 NADPH + 12 H+ + Pi
Thus, one molecule of glucose 6-phosphate, through six complete cycles of the pentose phosphate pathway (coupled with specific gluconeogenic reactions), is oxidized to six molecules of CO2. In the process, twelve molecules of NADPH are generated, with no net production of ribose 5-phosphate.[5][8][12]
When the need for NADPH and ATP is much greater than that for ribose 5-phosphate
When the cell requires significantly more NADPH than ribose 5-phosphate, and the energy charge is low, that is, there is a need for ATP, the ribulose 5-phosphate formed in the oxidative phase of the pentose phosphate pathway is converted into fructose 6-phosphate and glyceraldehyde 3-phosphate through the reactions of the non-oxidative phase. These two intermediates then enter glycolysis, where they are oxidized to pyruvate (the conjugate base of pyruvic acid), with the concomitant production of ATP.
The net reaction is as follows:
If the cell requires additional ATP, the pyruvate produced can be further oxidized via the citric acid cycle. Conversely, if there is no need for further ATP production, the carbon skeleton of pyruvate can be diverted into various biosynthetic pathways.
Note: as in the previous scenario, there is no net production of ribose 5-phosphate.[5][8][12]
When the need for ribose 5-phosphate is much greater than that for NADPH
When significantly more ribose 5-phosphate than NADPH is required, as in rapidly dividing cells with high rates of nucleotide synthesis, precursors of DNA, the oxidative phase of the pentose phosphate pathway is bypassed, and NADPH is not produced. Instead, the rapid utilization of ribose 5-phosphate causes its intracellular levels to drop, thereby stimulating its synthesis. This is possible because the reactions of the non-oxidative phase are readily reversible.
In this metabolic context, most of the glucose 6-phosphate is first converted into fructose 6-phosphate and glyceraldehyde 3-phosphate via glycolysis. These intermediates are then used by transaldolase and transketolase to generate ribose 5-phosphate and xylulose 5-phosphate. The latter is further converted into ribose 5-phosphate through the actions of phosphopentose epimerase and ribose 5-phosphate isomerase.
The overall reaction is:
Under these metabolic conditions, there is a functional interplay between glycolysis and the non-oxidative phase of the pentose phosphate pathway, with the latter running in the direction of ribose 5-phosphate synthesis.
Note: no metabolites return to glycolysis in this case.[5][8][12]
When the needs for ribose 5-phosphate and NADPH are balanced
If the metabolic needs of the cell are satisfied by one molecule of ribose 5-phosphate and two molecules of NADPH per molecule of glucose 6-phosphate metabolized, the predominant reactions are those of the oxidative phase and the one catalyzed by ribose 5-phosphate isomerase.
The net reaction is:
Under these metabolic conditions as well, no metabolites return to glycolysis.[5][8][12]
Metabolic scenarios compared
Scenario
Predominant pathway
Main output
Notes
High NADPH demand, low ribose 5-P or ATP need
Full oxidative phase + gluconeogenic recycling
↑ NADPH (12 per G6P), CO2 (6), no net ribose 5-P
Supports fatty acid synthesis (e.g., in adipose tissue)
High NADPH and ATP demand, low ribose 5-P need
Oxidative phase + glycolysis
NADPH (6), ATP (8), pyruvate (5), NADH (5), CO2 (3)
Supports both biosynthesis and energy production
High ribose 5-P demand, low NADPH need
Non-oxidative phase from glycolytic intermediates
Ribose 5-P (6 per 6 G6P), consumes ATP
Found in rapidly dividing cells (e.g., cancer, bone marrow)
Balanced need for ribose 5-P and NADPH
Oxidative phase + ribose 5-P isomerase
Ribose 5-P (1), NADPH (2), CO2; no return to glycolysis
Typical of balanced anabolic demand
Refences
^ abcdef Nelson D.L., Cox M.M. Lehninger. Principles of biochemistry. 8th Edition. W.H. Freeman and Company, 2021.
^ abcd Rosenthal M.D., Glew R.H. Medical Biochemistry – Human Metabolism in Health and Disease. John Wiley J. & Sons, Inc., 2009.
^ Gebril H.M., Avula B., Wang Y.H., Khan I.A., Jekabsons M.B. (13)C metabolic flux analysis in neurons utilizing a model that accounts for hexose phosphate recycling within the pentose phosphate pathway. Neurochem Int 2016;93:26-39. doi:10.1016/j.neuint.2015.12.008
^ abcdefghijk Heilman D., Woski S., Voet D., Voet J.G., Pratt C.W. Fundamentals of biochemistry: life at the molecular level. 6th Edition. Wiley, 2023.
^ abcd Samland A.K., Sprenger G.A. Transaldolase: from biochemistry to human disease. Int J Biochem Cell Biol 2009;41(7):1482-1494. doi:10.1016/j.biocel.2009.02.001
^ abc Michal G., Schomburg D. Biochemical pathways. An atlas of biochemistry and molecular biology. 2nd Edition. John Wiley & Sons, 2012.
^ Stincone A., Prigione A., Cramer T., Wamelink M.M., Campbell K., Cheung E., Olin-Sandoval V., Grüning N.M., Krüger A., Tauqeer Alam M., Keller M.A., Breitenbach M., Brindle K.M., Rabinowitz J.D., Ralser M. The return of metabolism: biochemistry and physiology of the pentose phosphate pathway. Biol Rev Camb Philos Soc 2015;90(3):927-63. doi:10.1111/brv.12140
^ abcdefghijk Berg J.M., Tymoczko J.L., Gregory J.G. Jr., Stryer L. Biochemistry. 9th Edition. W.H. Freeman and Company, 2019.
^ Sprenger G.A. Genetics of pentose-phosphate pathway enzymes of Escherichia coli K-12. Arch Microbiol 1995;164(5):324-30. doi:10.1007/BF02529978
^ abc Au S.W.N., Gover S., Lam V.M.S., Adams M.J. Human glucose-6-phosphate dehydrogenase: the crystal structure reveals a structural NADP+ molecule and provides insights into enzyme deficiency. Structure 2000;8(3):293-303. doi:10.1016/S0969-2126(00)00104-0
^ Levy H.R. Glucose-6-phosphate dehydrogenase from Leuconostoc mesenteroides. Biochem Soc Trans. 1989 Apr;17(2):313-5. doi:10.1042/bst0170313
^ Cosgrove M.S., Naylor C., Paludan S., Adams M.J., Richard Levy H. On the mechanism of the reaction catalyzed by glucose 6-phosphate dehydrogenase. Biochemistry 1998;37(9);2759-2767. doi:10.1021/bi972069y
^ Stanton R.C. Glucose 6-phosphate dehydrogenase, NADPH, and cell survival. IUBMB Life 2012;64(5):362-9. doi:10.1002/iub.1017
^ abc Patra K.C., Hay N. The pentose phosphate pathway and cancer. Trends Biochem Sci 2014;39(8):347-354. doi:10.1016/j.tibs.2014.06.005
^ García-Domínguez E., Carretero A., Viña-Almunia A., Domenech-Fernandez J., Olaso-Gonzalez G., Viña J., Gomez-Cabrera M.C. Glucose 6-P dehydrogenase – An antioxidant enzyme with regulatory functions in skeletal muscle during exercise. Cells 2022;11(19):3041. doi:10.3390/cells11193041
^ Phégnon L., Pérochon J., Uttenweiler-Joseph S., Cahoreau E., Millard P., Létisse F. 6-Phosphogluconolactonase is critical for the efficient functioning of the pentose phosphate pathway. FEBS J 2024;291(20):4459-4472. doi:10.1111/febs.17221
^ ab Ruda G.F., Campbell G., Alibu V.P., Barrett M.P., Brenk R., Gilbert I.H. Virtual fragment screening for novel inhibitors of 6-phosphogluconate dehydrogenase. Bioorg Med Chem 2010;18(14):5056-62. doi:10.1016/j.bmc.2010.05.077
^ ab Hanau S., Montin K., Cervellati C., Magnani M., Dallocchio F. 6-Phosphogluconate dehydrogenase mechanism: evidence for allosteric modulation by substrate. J Biol Chem 2010;285(28):21366-21371. doi:10.1074/jbc.M110.105601
^ Allard S.T., Giraud M.F., Naismith J.H. Epimerases: structure, function and mechanism. Cell Mol Life Sci 2001;58(11):1650-65. doi:10.1007/PL00000803
^ Samuel J., Tanner M.E. Mechanistic aspects of enzymatic carbohydrate epimerization. Nat Prod Rep 2002;19(3):261-77. doi:10.1039/b100492l
^ Bartkevihi L., Caruso Í.P., Martins B., Pires, J.R.M., Oliveira D.M.P., Anobom C.D., Almeida, F.C.L. Insights into the substrate uptake mechanism of Mycobacterium tuberculosis ribose 5-phosphate isomerase and perspectives on drug development. Biophysica 2023;3:139-157. doi:10.3390/biophysica3010010
^ Zhang R., Andersson C.E., Savchenko A., Skarina T., Evdokimova E., Beasley S., Arrowsmith C.H., Edwards A.M., Joachimiak A., Mowbray S.L. Structure of Escherichia coli ribose-5-phosphate isomerase: a ubiquitous enzyme of the pentose phosphate pathway and the Calvin cycle. Structure 2003;11(1):31-42. doi:10.1016/S0969-2126(02)00933-4
^ Kabashima T., Kawaguchi T., Wadzinski B.E., Uyeda K. Xylulose 5-phosphate mediates glucose-induced lipogenesis by xylulose 5-phosphate-activated protein phosphatase in rat liver. Proc Natl Acad Sci USA 2003;100:5107-5112. doi:10.1073/pnas.0730817100
^ Jelakovic S., Kopriva S., Süss K-H, Schulz G.E. Structure and catalytic mechanism of the cytosolic D-ribulose-5-phosphate 3-epimerase from rice. J Mol Biol 2003;326:127-135. doi:10.1016/S0022-2836(02)01374-8
^ abc Kochetov G.A., Solovjeva O.N. Structure and functioning mechanism of transketolase. Biochim Biophys Acta 2014;1844(9):1608-1618. doi:10.1016/j.bbapap.2014.06.003
^ Solovjeva O.N. Regulation of enzymes with identical subunits on the example of transketolase. Open J Anal Bioanal Chem 2022;6(1):004-012. doi:10.17352/ojabc.000024
^ Sharkey T.D. Pentose phosphate pathway reactions in photosynthesizing cells. Cells 2021;10(6):1547. doi:10.3390/cells10061547
^ ab Lehwess-Litzmann A., Neumann P., Parthier C., Lüdtke S., Golbik R., Ficner R., Tittmann K. Twisted Schiff base intermediates and substrate locale revise transaldolase mechanism. Nat Chem Biol 2011;7(10):678-84. doi:10.1038/nchembio.633
^ Van Schaftingen E., Hers H-G. Inhibition of fructose-1,6-bisphosphatase by fructose-2,6-bisphosphate. Proc Natl Acad Sci USA 1981;78(5):2861-2863. doi:10.1073/pnas.78.5.2861
^ Van Schaftingen E., Jett M-F., Hue L., Hers H-G. Control of liver 6-phosphofructokinase by fructose 2,6-bisphosphate and other effectors. Proc Natl Acad Sci USA 1981;78(6):3483-3486. doi:10.1073/pnas.78.6.3483
Glycolysis, also known as the glycolytic pathway, from the Greek words glykys (“sweet”) and lysis (“dissolution” or “breakdown”), is the sequence of enzymatic reactions that occur in the cytosol and, even in the absence of oxygen, convert glucose, a six-carbon sugar, into two molecules of pyruvate, a three-carbon compound. This process is accompanied by the production of two molecules of ATP and NADH.[1]
Glycolysis, which evolved before a significant accumulation of oxygen in the atmosphere, is the metabolic pathway with the highest carbon flux in most living cells and is present in nearly all organisms.[1]
Because it does not require oxygen, glycolysis played a crucial role during the first two billion years of life’s evolution, representing one of the earliest biological mechanisms for energy extraction from organic molecules. In addition, it supplies key intermediates for aerobic catabolism and numerous biosynthetic pathways.[2]
Note: glycolysis is also known as the Embden–Meyerhof–Parnas pathway, named after Gustav Embden, Otto Meyerhof, and Jakub Karol Parnas, the researchers who elucidated the pathway in muscle tissue.[3]
Summary: Key Points
Definition: a sequence of 10 cytosolic enzymatic reactions which, even in the absence of oxygen, convert glucose into pyruvate, with the simultaneous production of 2 molecules of ATP and 2 of NADH.
Fates of pyruvate: in the presence of oxygen, pyruvate can enter the Krebs cycle, while in the absence of oxygen it can be converted via lactic or alcoholic fermentation into lactate and ethanol, respectively.
Regulation: mainly mediated by three key enzymes (hexokinase, phosphofructokinase-1, and pyruvate kinase) through allosteric mechanisms, covalent modifications, and hormonal signals.
The development of biochemistry progressed in parallel with the study of glucose metabolism, particularly glycolysis, the first metabolic pathway to be fully elucidated.[4][5]
Although the pathway was not completely mapped until the 1940s, a key discovery was made in 1897, by chance. A year earlier, German chemist M. Hahn, while attempting to obtain and preserve cell-free protein extracts of yeast, had encountered difficulties with their stability. His colleague Hans Buchner, recalling a method used for preserving jams, suggested adding sucrose to the extract.[6]
Eduard Buchner, Hans’ brother, applied this idea and observed that the solution produced bubbles. He concluded that fermentation was occurring, an entirely unexpected finding. According to Pasteur’s assertion in 1860, fermentation was thought to be inseparably linked to living cells. Eduard’s experiments, however, demonstrated that it could also occur in their absence. These results disproved the vitalist dogma and marked a turning point in the emergence of modern biochemistry.[7]
For this work, Eduard Buchner was awarded the Nobel Prize in Chemistry in 1907, becoming the first of several scientists later honored for discoveries related to glycolysis. Subsequent studies with muscle extracts revealed that many of the reactions involved in lactic fermentation were identical to those in alcoholic fermentation, highlighting the fundamental unity of biochemistry.[8]
As noted, glycolysis was eventually fully elucidated during the first half of the 20th century, thanks to the contributions of Gerty and Carl Cori, Carl Neuberg, Arthur Harden, William Young, Jacob Parnas, Otto Warburg, Hans von Euler-Chelpin, Gustav Embden, and Otto Meyerhof. Warburg and von Euler-Chelpin clarified the pathway in yeast, while Embden and Meyerhof did so in muscle tissue during the 1930s.[3]
Importance of glycolysis
Glycolysis is essential for most living cells, both as a source of energy and as a provider of precursors for many other metabolic pathways. The rate of carbon flow through glycolysis, that is, the amount of glucose converted to pyruvate per unit of time, is regulated to satisfy these two fundamental cellular demands.
Although relatively inefficient energetically, glycolysis can proceed in the absence of oxygen, a condition under which life first evolved and one still encountered by many modern cells, both eukaryotic and prokaryotic. Several examples illustrate this adaptability.[9]
Anaerobic glycolysis
In animals, skeletal muscle exhibits activity-dependent anaerobiosis; it can function without oxygen for short periods. During intense exercise, when ATP demand exceeds oxygen delivery, muscles continue to operate anaerobically, though only temporarily.
The cornea of the eye provides another example, because it is poorly vascularized.[9]
Many microorganisms also thrive in low-oxygen environments such as deep water, soil, or skin pores. Some, like Clostridium perfringens, Clostridium tetani, and Clostridium botulinum, which cause gangrene, tetanus, and botulism, respectively, are obligate anaerobes that cannot survive in the presence of oxygen.[10]
Glycolysis in glucose-dependent cells
Glycolysis also sustains cells and tissues where glucose is the sole source of energy, including:
red blood cells, which lack mitochondria,
sperm cells;
the brain (which can also utilize ketone bodies during glucose scarcity);
A similar pattern occurs in plants. Many aquatic plants and starch-storing tissues (e.g., potato tubers) rely on glucose as their main energy source.[12]
Note: some organisms, known as facultative anaerobes, can survive both in the presence and absence of oxygen, switching between aerobic and anaerobic metabolism. For instance, Mytilus species exhibit habitat-dependent anaerobiosis, comparable to that of muscle tissue.[13]
Aerobic glycolysis
Under aerobic conditions, in cells containing mitochondria, glycolysis represents the first stage of the metabolic pathway that leads to the complete oxidation of glucose to carbon dioxide (CO2) and water (H2O), producing ATP.[14]
Sources of building blocks
Several glycolytic intermediates, for example, glucose 6-phosphate (G6P), fructose 6-phosphate (F6P), and dihydroxyacetone phosphate (DHAP), serve as building blocks for other metabolic pathways. These include glycogen synthesis, as well as the biosynthesis of fatty acids, triglycerides, nucleotides, certain amino acids, and 2,3-bisphosphoglycerate (2,3-BPG).[15]
Glycolysis as a Source of Building Blocks
Sequence of reactions
The ten steps that constitute glycolysis can be divided into two phases.
The first, known as the preparatory phase, consists of five steps and begins with the conversion of glucose to fructose 1,6-bisphosphate (F1,6BP) through three enzymatic reactions: phosphorylation at C-6, isomerization, and a second phosphorylation at C-1, with the consumption of two ATP molecules.
Fructose 1,6-bisphosphate is then cleaved into two phosphorylated three-carbon compounds: glyceraldehyde 3-phosphate (G3P) and dihydroxyacetone phosphate. Finally, DHAP is isomerized into a second molecule of glyceraldehyde 3-phosphate. Thus, in the preparatory phase, one glucose molecule is split into two molecules of glyceraldehyde 3-phosphate, with a net consumption of two ATP molecules.
The Glycolytic Pathway
The second phase, the payoff phase, consists of the remaining five steps. In this phase, the two molecules of glyceraldehyde 3-phosphate are converted into two molecules of pyruvate, with the simultaneous production of four ATP molecules. Part of the energy stored in the chemical bonds of glucose is extracted and conserved in the form of ATP. In addition, reducing equivalents are captured and stored in the form of NADH, the reduced form of the coenzyme NAD+ (nicotinamide adenine dinucleotide). The metabolic fate of NADH depends on the cell type and whether conditions are aerobic or anaerobic.
Note: the glucose metabolized via the glycolytic pathway may originate either from extracellular glucose entering the cell through specific membrane transporters (derived from the bloodstream) or from intracellular glucose 6-phosphate produced by glycogenolysis.[11]
Reaction 1
In the first step of glycolysis, glucose is phosphorylated to glucose 6-phosphate at the expense of one ATP molecule.
Glucose + ATP → G6P + ADP
In most cells, this reaction is catalyzed by hexokinase (EC 2.7.1.1), an enzyme present in all organisms. In humans, four isoforms of hexokinase are expressed.[16] Both hexokinase and pyruvate kinase (EC 2.7.1.40), two of the key kinases of glycolysis, require a divalent metal ion such as magnesium (Mg2+) or manganese (Mn2+) for activity. Mg2+ binds to ATP, forming the MgATP2− complex, which is the true substrate of the enzyme rather than free ATP. The nucleophilic attack by the hydroxyl group (–OH) of glucose on the terminal (γ) phosphorus atom of ATP is facilitated by Mg2+, which stabilizes the negative charges on the phosphoryl groups of the nucleotide triphosphate.
The reaction involves the formation of a phosphoester bond between the phosphoryl group and the hydroxyl group at the C-6 position of glucose. This step is thermodynamically unfavorable and requires an input of energy, provided by ATP.[3]
Energetics and irreversibility
In the absence of ATP, the direct phosphorylation of glucose at C-6 by inorganic phosphate (Pi) is endergonic, with a standard Gibbs free energy change (ΔG°′) of +13.8 kJ/mol (+3.3 kcal/mol).
ATP hydrolysis to ADP and Pi has a ΔG°’ of –30.5 kJ/mol (–7.3 kcal/mol), an exergonic process.
The net ΔG°’ of the coupled reaction is –16.7 kJ/mol (–4.0 kcal/mol).
Under physiological conditions, the reaction is even more favorable, with a ΔG of ≈ –33.5 kJ/mol (–8.0 kcal/mol). Consequently, this step is considered essentially irreversible.[17]
Note: phosphorylation is a fundamental biochemical reaction catalyzed by kinases, a subclass of transferases. Kinases catalyze the transfer of the terminal phosphoryl group from a nucleoside triphosphate (usually ATP) to an acceptor nucleophile, forming a phosphoester bond. Specifically, hexokinase catalyzes the transfer of the γ-phosphoryl group of ATP to a variety of hexoses, including glucose, fructose, and mannose.[5]
Reaction 1 – Phosphorylation of Glucose
Property
Details
Reaction
Glucose + ATP → G6P + ADP
Enzyme
Hexokinase. In humans: four isoforms.
Cofactors
Mg2+ (as MgATP2−) or Mn2+
ΔG°′
–16.7 kJ/mol (net) (–4.0 kcal/mol)
ΔG
≈ –33.5 kJ/mol (–8.0 kcal/mol)
Reversibility
Irreversible under physiological conditions
Reaction 2
In the second step of glycolysis, G6P, an aldose, is isomerized to fructose 6-phosphate, a ketose.
G6P ⇄ F6P
This reaction is catalyzed by phosphoglucose isomerase (also known as phosphohexose isomerase or glucose phosphate isomerase; EC 5.3.1.9). The enzyme requires Mg2+ for activity. Glucose 6-phosphate and fructose 6-phosphate represent a case of functional group isomerism.
The ΔG°′ of the reaction is +1.7 kJ/mol (+0.4 kcal/mol), whereas the ΔG is ≈ –2.5 kJ/mol (–0.6 kcal/mol). These small values indicate that the reaction operates near equilibrium and is therefore readily reversible.
The reaction involves a shift of the carbonyl group from C-1 in the open-chain form of glucose 6-phosphate to C-2 in the open-chain form of fructose 6-phosphate.[3]
Mechanism and importance
The enzyme first opens the ring of glucose 6-phosphate, since both hexoses are mainly present in cyclic form in aqueous solution.
It then catalyzes the isomerization of the open-chain intermediate, shifting the carbonyl group from C-1 to C-2.
Finally, it promotes ring closure, forming fructose 6-phosphate, which adopts a five-membered furanose structure.[5]
Phosphoglucose Isomerase Reaction
This isomerization is crucial because it prepares the substrate for subsequent reactions.
In the third step, phosphorylation occurs at the C-1 position, which requires a hydroxyl group rather than a carbonyl group.
In the fourth step, cleavage of the bond between C-3 and C-4 is facilitated by the presence of a carbonyl group at C-2, generated during this isomerization.[11]
Reaction 2 – Isomerization of glucose 6-phosphate
Property
Details
Reaction
G6P ⇄ F6P
Enzyme
Phosphoglucose isomerase
Cofactors
Mg2+
ΔG°′
+1.7 kJ/mol (+0.4 kcal/mol)
ΔG
≈ –2.5 kJ/mol (–0.6 kcal/mol)
Reversibility
Reversible (near equilibrium)
Reaction 3
In the third step of glycolysis, F6P undergoes a second phosphorylation. Phosphofructokinase-1 (PFK-1; EC 2.7.1.11) catalyzes the phosphorylation of fructose 6-phosphate at the C-1 position to yield fructose 1,6-bisphosphate, at the expense of one ATP molecule.
F6P + ATP → F1,6BP + ADP
PFK-1 is named to distinguish it from phosphofructokinase-2 (PFK-2; EC 2.7.1.105), which catalyzes the formation of fructose 2,6-bisphosphate (F2,6BP) from fructose 6-phosphate.[1]
Like the hexokinase-catalyzed reaction, this ATP-dependent phosphorylation step is essentially irreversible. Its irreversibility results from coupling to ATP hydrolysis, which provides the necessary free energy. Phosphorylation of fructose 6-phosphate by inorganic phosphate alone is endergonic, with a ΔG°′ of +16.3 kJ/mol (+3.9 kcal/mol). When coupled to ATP hydrolysis, however, the overall reaction becomes exergonic, with a ΔG°′ of –14.2 kJ/mol (–3.4 kcal/mol) and a cellular ΔG of ≈ –22.2 kJ/mol (–5.3 kcal/mol).[3]
While hexokinase functions primarily to trap glucose inside the cell, PFK-1 commits glucose-derived carbon to glycolysis rather than directing it toward glycogen synthesis or other biosynthetic pathways. Unlike glucose 6-phosphate, fructose 1,6-bisphosphate cannot readily enter alternative metabolic routes, making this the first committed step of glycolysis.
Committed steps are typically catalyzed by allosterically regulated enzymes, preventing the unnecessary accumulation of intermediates and end products. PFK-1 exemplifies this regulation, as it is subject to activation and inhibition by metabolites that reflect both the cell’s energy status and hormonal signals.[5]
Reaction 3 – Phosphorylation of fructose 6-phosphate
Property
Details
Reaction
F6P + ATP → F1,6BP + ADP
Enzyme
Phosphofructokinase-1 (PFK-1)
Cofactors
Mg2+ (as MgATP2–)
ΔG°′
–14.2 kJ/mol (–3.4 kcal/mol)
ΔG
≈ –22.2 kJ/mol (–5.3 kcal/mol)
Reversibility
Irreversible (first committed step of glycolysis)
PPi dependent phosphofructokinase
In some protists and bacteria, and possibly in all plants, a variant phosphofructokinase uses pyrophosphate (PPi) instead of ATP as the phosphoryl donor. This alternative reaction has a ΔG°′ of –12.1 kJ/mol (–2.9 kcal/mol).[18]
F6P + PPi → F1,6BP + Pi
Reaction 4
In the fourth step of glycolysis, fructose 1,6-bisphosphate aldolase (commonly known as aldolase; EC 4.1.2.13) catalyzes the reversible cleavage of F1,6BP into two triose phosphates: glyceraldehyde 3-phosphate (an aldose) and dihydroxyacetone phosphate (a ketose). The enzyme cleaves the carbon–carbon bond between C-3 and C-4 of the fructose backbone.[1]
F1,6-BP ⇄ DHAP + G3P
From this step onward, all glycolytic intermediates are three-carbon compounds, whereas the preceding intermediates were six-carbon sugars.[11]
Note on nomenclature
The name “aldolase” derives from the reverse reaction, i.e., the condensation of an aldehyde and a ketone to form a β-hydroxyketone (an aldol), in a process known as aldol condensation.
Energetics and reversibility
The ΔG°′ of the cleavage reaction is +23.8 kJ/mol (+5.7 kcal/mol), with an equilibrium constant (Keq) of approximately 10−4 M. These values indicate that under standard conditions the reaction would not favor the forward (cleavage) direction. However, in the cellular context, the products are rapidly consumed in subsequent reactions, maintaining their concentrations at low levels. As a result, the actual free energy change is about –1.3 kJ/mol (–0.3 kcal/mol), showing that the reaction is near equilibrium and easily reversible.[5]
Reaction 4 – Cleavage of fructose 1,6-bisphosphate
Property
Details
Reaction
F1,6 ⇄ DHAP + G3P
Enzyme
Aldolase (Fructose 1,6-bisphosphate aldolase)
ΔG°′
+23.8 kJ/mol (+5.7 kcal/mol)
ΔG
≈ –1.3 kJ/mol (–0.3 kcal/mol)
Reversibility
Reaction near equilibrium; readily reversible
Note
The enzyme name originates from the reverse aldol condensation reaction
Reaction 5
Of the two products generated in the previous step, glyceraldehyde 3-phosphate directly enters the second phase of glycolysis. In contrast, DHAP is not part of the main glycolytic route and must first be isomerized into glyceraldehyde 3-phosphate. This reversible reaction is catalyzed by triose phosphate isomerase (EC 5.3.1.1).
DHAP ⇄ G3P
Triose phosphate isomerase catalyzes a keto–enol tautomerization involving the transfer of a hydrogen atom from C-1 to C-2 of DHAP. As a consequence of this isomerization, the carbon atoms C-1, C-2, and C-3 of glucose become chemically indistinguishable from C-6, C-5, and C-4, respectively. The net result of reactions 4 and 5 is therefore the production of two molecules of glyceraldehyde 3-phosphate: one formed directly in reaction 4, and the other via isomerization.[3]
The ΔG°′ of this step is +7.5 kJ/mol (+1.8 kcal/mol), while the actual ΔG under cellular conditions is about +2.5 kJ/mol (+0.6 kcal/mol). At equilibrium, ≈ 96% of the triose phosphate pool exists as DHAP. Nonetheless, the reaction proceeds efficiently toward G3P because this intermediate is rapidly consumed in the following glycolytic step, driving the reaction forward.[1]
One notable feature of triose phosphate isomerase is its extraordinary catalytic efficiency. The enzyme is considered kinetically “perfect” because it accelerates the reaction rate by a factor of 1010 compared to a simple catalyst (e.g., acetate ion). Its catalytic efficiency, expressed as the Kcat/KM ratio, is about 2 x 108 M–1 s–1, approaching the diffusion-controlled limit. Thus, the rate-limiting factor is not the chemistry of the reaction itself but the rate at which substrate and enzyme encounter each other.[19]
Energetics and metabolic relevance
From a thermodynamic perspective, reactions 4 and 5 together are unfavorable, with a combined ΔG°′ of +31.3 kJ/mol (+7.5 kcal/mol). However, when the hydrolysis of two ATP molecules in earlier steps is taken into account, the overall ΔG°′ for the preparatory phase (steps 1–5) is only +2.1 kJ/mol (+0.5 kcal/mol). The corresponding Keq is ≈ 0.43. Importantly, under physiological conditions, the actual ΔG is strongly negative (≈ –56.8 kJ/mol; –13.6 kcal/mol), ensuring the pathway proceeds forward.[17]
Beyond glycolysis, DHAP can also serve as a precursor in lipid metabolism. It can be reduced to glycerol 3-phosphate by cytosolic glycerol 3-phosphate dehydrogenase (EC 1.1.1.8)
DHAP + NADH + H+ ⇄ Glycerol 3-phosphate + NAD+
This reaction links carbohydrate metabolism to lipid biosynthesis, as glycerol 3-phosphate is an essential precursor for triacylglycerols and phospholipids. In adipose tissue and the small intestine, this pathway represents a major source of glycerol 3-phosphate.[11]
Reaction 5 – Isomerization of DHAP to G3P
Property
Details
Reaction
DHAP ⇄ G3P
Enzyme
Triose phosphate isomerase
ΔG°′
+7.5 kJ/mol (+1.8 kcal/mol)
ΔG
≈ +2.5 kJ/mol (+0.6 kcal/mol), but pulled forward by rapid G3P utilization
Equilibrium
≈ 96% DHAP at equilibrium
Catalytic efficiency
Kinetically “perfect”: Kcat/KM ≈ 2 x 108 M–1s–1
Additional role
DHAP can be reduced to glycerol 3-phosphate, linking glycolysis to lipid metabolism
Reaction 6
In the sixth step of glycolysis, and the first of the payoff phase, glyceraldehyde 3-phosphate dehydrogenase (EC 1.2.1.12) catalyzes the oxidation of G3P to 1,3-bisphosphoglycerate (1,3-BPG), coupled with the reduction of NAD+ to NADH.[3]
G3P + NAD+ + Pi ⇄ 1,3-BPG + NADH + H+
This is the first of two glycolytic reactions that conserve the chemical energy required for the subsequent synthesis of ATP.
Mechanism and energetics
The reaction consists of two tightly coupled processes.
Oxidation: the aldehyde group of G3P is oxidized to a carboxylic acid, with NAD+ acting as the oxidizing agent. This process is strongly exergonic (ΔG°′ = –43.1 kJ/mol, −10.3 kcal/mol).
Phosphorylation: a high-energy acyl phosphate bond is formed between the new carboxyl group and inorganic phosphate, yielding 1,3-BPG. This step is highly endergonic (ΔG°′ = +49.3 kJ/mol, +11.8 kcal/mol).[11]
Although each process alone would be thermodynamically unbalanced, their tight coupling allows the energy released from oxidation to drive acyl phosphate formation. The overall reaction has a ΔG°′ of +6.3 kJ/mol (+1.5 kcal/mol) and a cellular ΔG of ≈ +2.5 kJ/mol (+0.6 kcal/mol), both slightly endergonic.[17]
Thus, free energy is conserved in the form of the high-energy acyl phosphate bond of 1,3-BPG, rather than being lost as heat.[20]
Reaction 6 – Oxidation and Phosphorylation of G3P
Property
Details
Reaction
G3P + NAD+ + Pi ⇄ 1,3-BPG + NADH + H+
Enzyme
Glyceraldehyde 3-phosphate dehydrogenase
Cofactor
NAD+ (reduced to NADH)
ΔG°′
+6.3 kJ/mol (+1.5 kcal/mol)
ΔG
≈ +2.5 kJ/mol (+0.6 kcal/mol)
Importance
First energy-conserving step; formation of high-energy acyl phosphate bond
Note on NAD+ reduction
The reversible reduction of NAD⁺ involves the transfer of two hydrogen atoms from the substrate, the aldehyde group of glyceraldehyde 3-phosphate undergoing oxidation: one as a hydride ion (2 e− + H+) to the nicotinamide ring, and the other as a free proton released into solution.[5]
Half-reactions:
NAD+ + 2 e– + 2 H+ → NADH + H+
NADP+ + 2 e– + 2 H+ → NADPH + H+
Reaction 7
In the seventh step of glycolysis, phosphoglycerate kinase (EC 2.7.2.3) catalyzes the transfer of a high-energy phosphoryl group from the acyl phosphate of 1,3-BPG to ADP, forming ATP and 3-phosphoglycerate (3-PG).[1]
1,3-BPG + ADP ⇄ 3-PG + ATP
The reaction has a ΔG°′ of −18.5 kJ/mol (−4.4 kcal/mol), making it exergonic, although under cellular conditions the free energy change is ≈ +1.3 kJ/mol (+0.3 kcal/mol).[17]
Energetics and reversibility
The high phosphoryl-transfer potential of the acyl phosphate group is harnessed to phosphorylate ADP in a process known as substrate-level phosphorylation. In other words, part of the energy released during the oxidation of glyceraldehyde 3-phosphate in the previous step is conserved in the synthesis of ATP.[5]
This is the first step in glycolysis where the chemical energy of glucose is captured as ATP. Since aldolase and triose phosphate isomerase (steps 4 and 5) yield two molecules of glyceraldehyde 3-phosphate per glucose, this step generates two ATP molecules, thereby offsetting the ATP investment made earlier (steps 1 and 3).
The enzyme name refers to the reverse reaction, i.e., the phosphorylation of 3-phosphoglycerate to form 1,3-bisphosphoglycerate using ATP. Like all enzymes, phosphoglycerate kinase can catalyze the reaction in both directions. The reverse reaction occurs in gluconeogenesis and in photosynthetic CO2 fixation.[21]
Reaction 7 – Substrate-level Phosphorylation by Phosphoglycerate Kinase
Property
Details
Reaction
1,3-BPG + ADP ⇄ 3-PG + ATP
Enzyme
Phosphoglycerate kinase
ΔG°′
−18.5 kJ/mol (−4.4 kcal/mol)
ΔG
≈ +1.3 kJ/mol (+0.3 kcal/mol)
Process
Substrate-level phosphorylation; ATP generation from the high-energy acyl phosphate of 1,3-BPG
ATP Yield
2 ATP per glucose (since 2 × G3P enter the payoff phase)
Importance
First ATP-generating step in glycolysis; compensates the ATP invested in the preparatory phase
Reversibility
Reversible reaction; reverse direction occurs in gluconeogenesis and photosynthesis
Coupling with reaction 6
Reactions 6 and 7 together constitute an energy-coupling system, with 1,3-BPG as the common intermediate.
While the synthesis of 1,3-BPG is endergonic (ΔG°′ = +6.3 kJ/mol; +1.5 kcal/mol), the subsequent phosphoglycerate kinase reaction is strongly exergonic (ΔG°′ = −18.5 kJ/mol, −4.4 kcal/mol). The net ΔG°′ is −12.2 kJ/mol (−2.9 kcal/mol), sufficient to drive not only the preceding dehydrogenase step, but also the aldolase and triose phosphate isomerase reactions.
G3P + ADP + Pi + NAD+ ⇄ 3-PG + ATP + NADH + H+
The phosphoryl group of 3-phosphoglycerate has a relatively low transfer potential (ΔG°′ ≈ −12.5 kJ/mol; −3 kcal/mol), insufficient to directly drive ATP synthesis. Therefore, in the next steps of glycolysis, 3-phosphoglycerate is converted into phosphoenolpyruvate (PEP), a compound with much higher phosphoryl-transfer potential.[3]
Reaction 8
In the eighth step of glycolysis, 3-PG is converted into 2-phosphoglycerate (2-PG) in a reversible reaction catalyzed by phosphoglycerate mutase (EC 5.4.2.1). This reaction has a very small free energy change, with ΔG°′ = +4.4 kJ/mol (+1.1 kcal/mol) and ΔG ≈ +0.8 kJ/mol (+0.2 kcal/mol).[17]
Phosphoglycerate mutase belongs to the class of mutases, enzymes that catalyze intramolecular group transfers. In this case, it catalyzes the transfer of a phosphoryl group from the C-3 to the C-2 position of 3-PG. Mutases are a subclass of isomerases.[22]
3-PG ⇄ 2-PG
Mechanism and significance
The mechanism of this reaction varies among organisms. For example, in yeast and rabbit muscle, the reaction proceeds in two steps and involves the formation of phosphoenzyme intermediates.
In the first step, a phosphoryl group bound to a histidine residue in the enzyme’s active site is transferred to the hydroxyl group at C-2 of 3-PG, generating 2,3-bisphosphoglycerate.
In the second step, the enzyme acts as a phosphatase, converting 2,3-BPG into 2-phosphoglycerate, while the phosphoryl group at C-3 is transferred back to the histidine residue, regenerating the phosphorylated enzyme (enzyme–His–phosphate).
Schematically:
It is important to note that the phosphoryl group in 2-phosphoglycerate is not the same as the one originally present in 3-phosphoglycerate.[5]
Reaction 8 – Conversion of 3-phosphoglycerate to 2-phosphoglycerate
Property
Details
Reaction
3-PG ⇄ 2-PG
Enzyme
Phosphoglycerate mutase
Cofactor
Requires 2,3-bisphosphoglycerate for activation
ΔG°′
+4.4 kJ/mol (+1.1 kcal/mol)
ΔG
≈ +0.8 kJ/mol (+0.2 kcal/mol)
Mechanism
Proceeds via a phosphoenzyme intermediate and transient formation of 2,3-bisphosphoglycerate
Importance
Rearranges the phosphoryl group to prepare for the high-energy intermediate phosphoenolpyruvate
2,3-BPG and the Rapoport–Luebering shunt
Approximately once every 100 catalytic cycles, 2,3-BPG dissociates from the enzyme, leaving it unphosphorylated and inactive. The enzyme can be reactivated by binding a new molecule of 2,3-BPG, which must therefore be present in the cytosol to maintain optimal activity. Small but sufficient amounts of 2,3-BPG are found in most cells, with the notable exception of red blood cells, where it is synthesized through the Rapoport–Luebering shunt. In erythrocytes, 2,3-BPG also acts as an allosteric inhibitor of hemoglobin, lowering its affinity for oxygen.[23][24]
Note: 3-phosphoglycerate also serves as a precursor for the biosynthesis of serine, from which glycine and cysteine are derived. The first step in serine biosynthesis is catalyzed by phosphoglycerate dehydrogenase (EC 1.1.1.95), which oxidizes 3-phosphoglycerate to 3-phosphohydroxypyruvate while reducing NAD+ to NADH. This step is rate-limiting, as serine acts as a feedback inhibitor of the enzyme.[25]
Reaction 9
In the ninth step of the glycolytic pathway, 2-PG is dehydrated to form phosphoenolpyruvate, an enol, in a reversible reaction catalyzed by enolase (EC 4.2.1.11).
2-PG ⇄ PEP + H2O
This reaction requires Mg2+, which stabilizes the enolic intermediate formed during the process.[11]
The ΔG°’ of the reaction is +7.5 kJ/mol (+1.8 kcal/mol), while ΔG = –3.3 kJ/mol (–0.8 kcal/mol), indicating that the reaction proceeds readily in vivo.[17]
Phosphoryl transfer potential and tautomerization
Like 1,3-bisphosphoglycerate, phosphoenolpyruvate possesses a phosphoryl group with a very high transfer potential, sufficient to allow ATP synthesis.
But why is the free energy of hydrolysis of PEP so high?
Although 2-PG and PEP contain nearly the same total amount of metabolic energy relative to complete oxidation to CO2, H2O and Pi, the dehydration of 2-PG redistributes this energy, leading to very different standard free energies of hydrolysis:
–17.6 kJ/mol (–4.2 kcal/mol) for 2-phosphoglycerate (a phosphoric ester);
–61.9 kJ/mol (–14.8 kcal/mol) for phosphoenolpyruvate (an enol phosphate).
This difference arises because the phosphoryl group of PEP locks the molecule in its unstable enol form. In the final step of glycolysis, when PEP donates its phosphoryl group to ADP, ATP and the enol form of pyruvate are generated. The enol form of pyruvate is unstable and rapidly tautomerizes nonenzymatically into the more stable keto form, which predominates at physiological pH (≈7).
Thus, the extraordinarily high phosphoryl-transfer potential of PEP is due primarily to the subsequent enol–keto tautomerization of pyruvate, which provides a strong thermodynamic driving force.[5][26]
Reaction 9 – Dehydration of 2-phosphoglycerate to phosphoenolpyruvate
PEP stores energy in an unstable enol form; tautomerization of pyruvate (enol → keto) drives high phosphoryl-transfer potential
Reaction 10
In the final step of glycolysis, pyruvate kinase catalyzes the transfer of a phosphoryl group from PEP to ADP, producing pyruvate and ATP. This is the second example of substrate-level phosphorylation in the pathway.
PEP + ADP → Pyruvate + ATP
Pyruvate kinase is a tetrameric enzyme and, like PFK-1, it is highly regulated. It contains binding sites for several allosteric effectors. In vertebrates, at least three isozymes exist: the M isozyme (predominant in muscle and brain) and the L isozyme (predominant in liver) are the best characterized. Although they share many properties, they differ in their regulation by hormones such as glucagon, epinephrine, and insulin.
Enzyme activity is also stimulated by potassium ions (K⁺) and other monovalent cations.[1][11][27]
The reaction is essentially irreversible, with a ΔG°′ of –31.4 kJ/mol (–7.5 kcal/mol) and a cellular ΔG of ≈ –16.7 kJ/mol (–4.0 kcal/mol). This strong thermodynamic favorability is largely due to the spontaneous tautomerization of pyruvate from its unstable enol form to its stable keto form.[5]
Spontaneous Tautomerization of Pyruvate
Energetics and reversibility
Of the –61.9 kJ/mol (–14.8 kcal/mol) released from the hydrolysis of the phosphoryl group of PEP, nearly half is conserved in the formation of the phosphoanhydride bond between ADP and Pi, whose ΔG°’ is –30.5 kJ/mol (–7.3 kcal/mol). The remaining energy (–31.4 kJ/mol or –7.5 kcal/mol) serves as the driving force that pushes the reaction toward ATP production.[17]
While the reaction catalyzed by phosphoglycerate kinase (step 7) restores the ATP “debt” from the preparatory phase, the pyruvate kinase reaction yields a net gain of two ATP molecules per glucose.
Reaction 10 – Conversion of PEP to pyruvate
Property
Details
Reaction
PEP + ADP → Pyruvate + ATP
Enzyme
Pyruvate kinase
Cofactors / Activators
K+ and other monovalent cations; allosteric regulation (isozyme-specific)
ΔG°′
–31.4 kJ/mol (–7.5 kcal/mol)
ΔG
≈ –16.7 kJ/mol (–4.0 kcal/mol)
Isozymes
M isozyme (muscle, brain); L isozyme (liver); regulated differently by hormones
Importance
Second substrate-level phosphorylation; net gain of 2 ATP per glucose; irreversibility ensured by pyruvate tautomerization
Fate of NADH and pyruvate
Glycolysis yields 2 NADH, 2 ATP, and 2 pyruvate molecules per molecule of glucose.[1]
For glycolysis to continue, NADH must be reoxidized to NAD+. This coenzyme, derived from vitamin B3 (niacin), is present in the cytosol at a concentration of ≤ 10−5M, far lower than the amount of glucose metabolized within a few minutes, and therefore must be continuously regenerated. The regeneration of NAD+ from NADH constitutes the final step of the glycolytic pathway and can proceed through either aerobic or anaerobic routes, both of which involve pyruvate. These pathways are essential for maintaining the cell’s redox balance.[28]
Pyruvate itself is a versatile metabolite that can participate in several metabolic fates, both anabolic and catabolic, depending on the cell type, the energy status of the cell, and the availability of oxygen.[29]
Three Catabolic Pathways of Pyruvate from Glycolysis
With the exception of certain bacterial variations, exploited, for example, in the food industry for the production of specific fermented products such as cheese, pyruvate typically follows one of three catabolic routes:
reduction to lactate, via lactic acid fermentation;
reduction to ethanol, via alcoholic fermentation;
aerobic oxidation.
These pathways allow glycolysis to proceed under both anaerobic and aerobic conditions. Thus, the catabolic fate of glucose carbon skeletons depends on cell type, energetic state, and oxygen availability.[11]
Lactic acid fermentation
In animals, aside from a few exceptions, and in many microorganisms, when oxygen availability is insufficient to meet the cell’s energy demands, or when the cell lacks mitochondria, the pyruvate generated by glycolysis is reduced to lactate in the cytosol. This reaction is catalyzed by lactate dehydrogenase (EC 1.1.1.27).[11]
Pyruvate + NADH + H+ ⇄ Lactate + NAD+
Here, pyruvate acts as the electron acceptor and is reduced to lactate, while NAD+ is regenerated. The equilibrium strongly favors lactate formation, as indicated by the ΔG°′ of –25.1 kJ/mol (–6.0 kcal/mol).[30]
The overall equation for the conversion of glucose to lactate, known as lactic acid fermentation, is:
Glucose + 2 Pi + 2 ADP → 2 Lactate + 2 ATP + 2 H2O
Discovered by Louis Pasteur, who famously described it as “la vie sans l’air”, fermentation is a metabolic process that:
extracts energy from glucose, conserving it as ATP;
Although NAD+ and NADH do not appear in the overall reaction, both are essential intermediates. Thus, there is no net oxidation or reduction: the hydrogen-to-carbon ratio remains unchanged in the conversion of glucose (C6H12O6) to lactate (C3H6O3).[1]
However, from an energetic standpoint, fermentation captures only a small fraction of the total chemical energy stored in glucose.
Fate of lactic acid
In humans, much of the lactate produced is directed into the Cori cycle, where it is transported to the liver and used for glucose synthesis via gluconeogenesis. This process shifts part of the metabolic load from extrahepatic tissues, such as skeletal muscle during intense exercise (e.g., a 200-meter sprint, when glycolysis can increase up to 2,000-fold almost instantaneously), to the liver.[32]
Unlike skeletal muscle, which releases lactate into venous blood, cardiac muscle can take up and utilize lactate an energy substrate. This is due to its strictly aerobic metabolism and to the properties of its tissue-specific isozyme of lactate dehydrogenase, LDH-1. Consequently, a portion of the lactate released by active skeletal muscle is directly consumed by the heart.[33]
Note: in microorganisms, lactic acid fermentation produces lactate that contributes to the flavor and aroma of foods such as sauerkraut (fermented cabbage) and soured milk.[34]
Alcoholic fermentation
In microorganisms such as brewer’s and baker’s yeast, in certain plant tissues, and in some invertebrates and protists, pyruvate may be converted to ethanol under hypoxic or anaerobic conditions, with the concomitant release of CO2. This occurs in two enzymatic steps.[32]
In the first step, pyruvate undergoes non-oxidative decarboxylation to form acetaldehyde. This essentially irreversible reaction is catalyzed by pyruvate decarboxylase (EC 4.1.1.1), which requires Mg2+ and thiamine pyrophosphate, a coenzyme derived from thiamine (vitamin B1). Pyruvate decarboxylase is absent in vertebrates and organisms that carry out lactic acid fermentation.
In the second step, acetaldehyde is reduced to ethanol in a reaction catalyzed by alcohol dehydrogenase (EC 1.1.1.1). This enzyme contains a bound zinc ion at its active site. NADH provides the reducing equivalents and is oxidized to NAD⁺. At physiological pH, the equilibrium strongly favors ethanol formation.
The overall process, known as alcoholic fermentation, is summarized by the equation:
Glucose + 2 Pi + 2 ADP → 2 Ethanol + 2 CO2 + 2 ATP + 2 H2O
As in lactic acid fermentation, no net oxidation–reduction occurs.[35]
Alcoholic fermentation is the biochemical basis for the production of beer and wine. The CO2 released by brewer’s yeast generates the bubbles characteristic of beer, champagne, and sparkling wines, while the CO2 produced by baker’s yeast causes dough to rise.[36]
Fate of pyruvate and NADH under aerobic conditions
In cells that contain mitochondria and under aerobic conditions, the predominant situation in both multicellular organisms and many unicellular species, the oxidation of NADH and the catabolism of pyruvate proceed through distinct but interconnected pathways.
Within the mitochondrial matrix, pyruvate is first converted to acetyl-CoA by the pyruvate dehydrogenase complex, a large multienzyme complex. During this oxidative decarboxylation, pyruvate loses, as part of a carboxyl group, one carbon atom in the form of CO2, and the remaining two-carbon fragment is transferred to coenzyme A, forming acetyl-CoA.[37][38]
Pyruvate + NAD+ + CoA → Acetyl-CoA + CO2 + NADH + H+
The acetyl group of acetyl-CoA is then completely oxidized to CO2 via the citric acid cycle, with the concurrent production of NADH and FADH2. The pyruvate dehydrogenase complex thus constitutes a crucial metabolic link between glycolysis, which occurs in the cytosol, and the citric acid cycle, which takes place in the mitochondrial matrix.[32]
Electrons generated during glycolysis are transferred into the mitochondria indirectly: cytosolic NADH reduces specific shuttle intermediates, which are then reoxidized inside the mitochondrial matrix. In this way, NADH is effectively reoxidized to NAD+ in the cytosol, while the reduced intermediates deliver electrons to Complex I of the electron transport chain. From there, electrons are passed through the chain to oxygen, producing H2O. This electron transfer provides the free energy required for ATP synthesis via oxidative phosphorylation.
Electrons carried by NADH formed during the pyruvate dehydrogenase reaction and the citric acid cycle, as well as those derived from FADH2, follow a similar path toward oxidative phosphorylation.[39]
Note: FADH₂ does not transfer its reducing equivalents to Complex I but instead donates them to Complex II.[40]
Anabolic fates of pyruvate
Under anabolic conditions, the carbon skeleton of pyruvate can follow fates other than complete oxidation to CO2 or reduction to lactate. After its conversion to acetyl-CoA, for example, pyruvate may serve as a precursor for fatty acid biosynthesis or for the synthesis of the amino acid alanine.[41][42]
Glycolysis and ATP production
In the glycolytic pathway, one molecule of glucose is degraded into two molecules of pyruvate.
During the preparatory phase, two molecules of ATP are consumed per molecule of glucose in the reactions catalyzed by hexokinase and PFK-1.
During the payoff phase, four molecules of ATP are produced via substrate-level phosphorylation in the reactions catalyzed by phosphoglycerate kinase and pyruvate kinase.
Thus, the net gain is two ATP molecules per glucose molecule. In addition, the reaction catalyzed by glyceraldehyde 3-phosphate dehydrogenase produces two molecules of NADH per glucose.
The overall ΔG°′ of glycolysis is –85 kJ/mol (–20.3 kcal/mol). This value results from the difference between:
the ΔG°′ of glucose conversion into two molecules of pyruvate (–146 kJ/mol; –34.9 kcal/mol), and
the ΔG°′ required for ATP formation from ADP and Pi: 2 × 30.5 kJ/mol = 61 kJ/mol (2 × 7.3 kcal/mol = 14.6 kcal/mol).
The two reactions can be written as:
Glucose + 2 NAD+ → 2 Pyruvate + 2 NADH + 2 H+
2 ADP + 2 Pi → 2 ATP + 2 H2O
Summing these gives the overall glycolytic equation:
By canceling common terms on both sides, this reduces to the standard overall equation shown above.[17]
Free energy changes of glycolytic reactions
The direction and regulation of glycolysis depend on the free energy changes of its individual steps. The table below summarizes the standard and cellular ΔG values for each reaction, showing that only a few steps are highly exergonic and essentially irreversible under physiological conditions.[17]
A graphical version is shown below for quick reference.
Free energy changes of glycolytic reactions
Step
Reaction
ΔG°′ (kJ/mol, kcal/mol)
ΔG (kJ/mol, kcal/mol)
1
Glu + ATP → G6P + ADP
–16.7 (–4.0)
–33.5 (–8.0)
2
G6P ⇄ F6P
+1.7 (+0.4)
–2.5 (–0.6)
3
F6P + ATP → F1,6BP + ADP
–14.2 (–3.4)
–22.2 (–5.3)
4
F1,6P ⇄ DHAP + G3P
+23.8 (+5.7)
–1.3 (–0.3)
5
DHAP ⇄ G3P
+7.5 (+1.8)
+2.5 (+0.6)
6
G3P + NAD+ + Pi ⇄ 1,3-BPG + NADH + H+
+6.3 (+1.5)
+2.5 (+0.6)
7
1,3-BPG + ADP ⇄ 3-PG + ATP
–18.5 (–4.4)
+1.3 (+0.3)
8
3-PG ⇄ 2-PG
+4.4 (+1.1)
+0.8 (+0.2)
9
2-PG ⇄ PEP + H2O
+7.5 (+1.8)
–3.3 (–0.8)
10
PEP + ADP → Pyr + ATP
–31.4 (–7.5)
–16.7 (–4.0)
ΔG°′ values from: Nelson D.L., Cox M.M. Lehninger. Principles of biochemistry. 8th Edition. W.H. Freeman and Company, 2021.
ΔG values from: Berg J.M., Tymoczko J.L., Gregory J.G. Jr, Stryer L. Biochemistry. 9th Edition. W.H. Freeman and Company, 2019.
Energy Changes of Glycolytic Reactions
ATP production under anaerobic conditions
Under anaerobic conditions, there is no additional ATP production beyond glycolysis, regardless of the metabolic fate of pyruvate, whether it is converted to lactate, ethanol, or other molecule.[43]
Therefore, glycolysis extracts only a small fraction of the chemical energy contained in a glucose molecule, which has a total energy yield of approximately 2,840 kJ/mol (679 kcal/mol) when fully oxidized to CO2 and H2O. In contrast, the conversion of glucose to two molecules of pyruvate releases only 146 kJ/mol, corresponding to ≈ 5% [(146/2,840) × 100] of the total available chemical energy. As a result, pyruvate retains most of the energy of the original hexose. Likewise, the four electrons carried by the NADH molecules produced during step 6 of glycolysis cannot contribute to ATP production under anaerobic conditions.[17]
In lactic acid fermentation, the ΔG°′ for the conversion of one molecule of glucose to two molecules of lactate is –183.6 kJ/mol (–43.9 kcal/mol). Of this free energy, ≈ 33.2% [(61/183.6) × 100] is stored in the two molecules of ATP formed. This is lower than the ≈ 41.8% efficiency of energy storage observed during glycolysis when glucose is converted to pyruvate.[44]
It should be noted that under physiological conditions, the free energy required to synthesize ATP from ADP and Pi is significantly higher than under standard conditions. Consequently, only about 50% of the energy released during glycolysis is actually stored in ATP in vivo.[1]
ATP production under aerobic conditions
Under aerobic conditions, cells with mitochondria can extract far more chemical energy from glucose and conserve it as ATP than under anaerobic conditions.[14]
The two molecules of NADH produced during glycolysis carry four reducing equivalents. When these electrons are transferred through the mitochondrial electron transport chain via oxidative phosphorylation, they yield approximately 2 to 3 ATP per electron pair. Consequently, the conversion of one molecule of glucose into two molecules of pyruvate can generate a total of 6 to 8 ATP: 2 ATP via substrate-level phosphorylation during glycolysis and 4 to 6 ATP through oxidative phosphorylation.[40]
Note: the exact number of ATP molecules generated from cytosolic NADH depends on the shuttle system used to transfer reducing equivalents into the mitochondria.
Furthermore, if we consider the complete aerobic oxidation of glucose through the coordinated action of glycolysis, the pyruvate dehydrogenase complex, the citric acid cycle, the electron transport chain, and oxidative phosphorylation, the ATP yield is much higher. According to Lehninger’s Principles of Biochemistry, the total ATP yield per glucose molecule ranges from 30 to 32. More recent estimates suggest a net production of approximately 29.85 ATP per glucose molecule, or 29.38 ATP if the ATP derived from GTP in the citric acid cycle is exported to the cytosol. In either case, aerobic metabolism yields roughly 15 times more ATP than anaerobic metabolism.[1]
Feeder pathways of glycolysis
Carbohydrates other than glucose, both simple and complex, can also be catabolized via glycolysis after their enzymatic conversion into one of the glycolytic intermediates.
Among the most important are:
glycogen and starch, two major storage polysaccharides;
monosaccharides including glucose, galactose, fructose, and the less common mannose.[45]
In the intestine, starch and disaccharides are hydrolyzed by digestive enzymes during carbohydrate digestion. The resulting monosaccharides, released directly or derived from the diet, are absorbed and transported into the venous circulation. From there, they reach the liver through the portal vein, which serves as the primary site for their metabolic processing.[46]
Glycogen and starch
For details on the phosphorolytic degradation of starch and endogenous glycogen, refer to the dedicated sections.
Fructose
Under physiological conditions, the liver removes much of the ingested fructose from the bloodstream before it can reach extrahepatic tissues.[47]
The hepatic pathway for converting fructose into glycolytic intermediates consists of several steps.[32]
In the first step, fructose is phosphorylated to fructose 1-phosphate (F1P) at the expense of one ATP molecule. This reaction, catalyzed by fructokinase (EC 2.7.1.4), requires Mg2+.
Fructose + ATP → F1P + ADP
As with glucose, phosphorylation traps fructose inside the cell.
In the second step, fructose 1-phosphate aldolase catalyzes an aldol cleavage of fructose 1-phosphate, yielding dihydroxyacetone phosphate and glyceraldehyde.
F1P → DHAP + Glyceraldehyde
Dihydroxyacetone phosphate is a direct glycolytic intermediate and, once converted to glyceraldehyde 3-phosphate, can continue through the pathway.
By contrast, glyceraldehyde is not a glycolytic intermediate and must be phosphorylated to glyceraldehyde 3-phosphate at the expense of another ATP molecule. This reaction, catalyzed by triose kinase (EC 2.7.1.28), also requires Mg2+.
Glyceraldehyde + ATP → G3P + ADP
Thus, in hepatocytes, one molecule of fructose is converted into two molecules of glyceraldehyde 3-phosphate, at the cost of two ATP molecules, just as with glucose.[48]
Fructose + 2 ATP → 2 G3P + 2 ADP
Fructose and hexokinase
In addition to the hepatic fructokinase pathway, extrahepatic tissues can also metabolize fructose through the action of hexokinase, albeit with a markedly lower affinity for fructose than for glucose. In these tissues, such as skeletal muscle, kidney, and adipose tissue, fructokinase is absent. Instead, fructose enters glycolysis as fructose 6-phosphate, following its phosphorylation at C-6 catalyzed by hexokinase.
Fructose + ATP → F6P + ADP
However, the enzyme’s affinity for fructose is about 20 times lower than for glucose. Consequently, in hepatocytes, where glucose is abundant, or in skeletal muscle under anaerobic conditions, when glucose is the preferred fuel, only small amounts of fructose 6-phosphate are produced.[11][47]
In contrast, in adipose tissue, fructose levels can exceed those of glucose, and its phosphorylation by hexokinase is not significantly inhibited. Thus, in this tissue, the formation of fructose 6-phosphate represents the primary entry point of fructose into glycolysis.[49]
Metabolic implications
It is important to note that in the liver, fructose, being phosphorylated at C-1, enters glycolysis at the level of triose phosphates, downstream of the reaction catalyzed by PFK-1, the key regulatory enzyme of glycolytic flux.
Conversely, when fructose is phosphorylated at C-6, it enters glycolysis upstream of PFK-1.[9]
Sorbitol
Fructose represents the entry point into glycolysis for sorbitol, a sugar naturally present in many fruits and vegetables, and also widely used as a sweetener and stabilizer.
In the liver, sorbitol dehydrogenase (EC 1.1.1.14) catalyzes the oxidation of sorbitol to fructose in a reaction that requires zinc ions and NAD+ as a cofactor.[32] This enzyme also participates in the polyol pathway, which interconverts glucose, sorbitol, and fructose and plays an important role in tissues such as the liver, seminal vesicles, and retina.[48]
Sorbitol + NAD+ → Fructose + NADH + H+
Galactose
Galactose, primarily derived from the intestinal digestion of lactose, is metabolized in the liver via the Leloir pathway, which converts it into glucose 1-phosphate.[50]
The metabolic fate of glucose 1-phosphate depends on the energy status of the cell.
Under conditions favoring glucose storage, glucose 1-phosphate is directed toward glycogen synthesis.
Under conditions favoring glucose utilization as a fuel, glucose 1-phosphate is isomerized to glucose 6-phosphate in the reversible reaction catalyzed by phosphoglucomutase (EC 5.4.2.2):
G1P ⇄ G6P
Glucose 6-phosphate can then either enter glycolysis for energy production or be dephosphorylated by glucose 6-phosphatase (EC 3.1.3.9) to free glucose, which can be released into the bloodstream.[51][52]
Mannose
Mannose is found in various dietary polysaccharides, glycolipids, and glycoproteins. In the intestine, it is released from these macromolecules, absorbed, and then transported to the liver. There, it is phosphorylated at C-6 to form mannose 6-phosphate (M6P) in a reaction catalyzed by hexokinase.
Mannose + ATP → M6P + ADP
The resulting sugar phosphate is subsequently isomerized to fructose 6-phosphate by mannose 6-phosphate isomerase (EC 5.3.1.8).[53]
M6P ⇄ F6P
Regulation of glycolysis
The flux of carbon through the glycolytic pathway is tightly regulated in response to metabolic conditions, both intracellular and extracellular, in order to satisfy two major needs:
the production of ATP;
the supply of precursors for biosynthetic reactions.
In the liver, glycolysis and gluconeogenesis are reciprocally regulated to avoid a wasteful expenditure of energy: when one pathway is active, the other is inhibited. Evolutionarily, this control was achieved by selecting distinct enzymes to catalyze the essentially irreversible reactions of the two pathways. These enzymes are regulated independently, thereby avoiding the risk of a futile cycle (also known as a substrate cycle) that would result if both reactions occurred simultaneously at high rates. Such precise regulation would not be possible if a single enzyme catalyzed both directions of the reaction.[7]
The control of glycolysis primarily involves three enzymes: hexokinase, phosphofructokinase-1, and pyruvate kinase. Their activities are regulated through:
allosteric modifications, which occur on a millisecond timescale and are rapidly reversible;
covalent modifications (phosphorylation and dephosphorylation), which take place on a timescale of seconds;
changes in enzyme concentration, due to altered rates of synthesis and/or degradation, which occur over hours.
Note: the main regulatory enzymes of gluconeogenesis are pyruvate carboxylase (EC 6.4.1.1) and fructose 1,6-bisphosphatase (FBPasi-1; EC 3.1.3.11).[1][11]
Hexokinase
In humans, hexokinase exists as four tissue-specific isozymes, hexokinase I, II, III, and IV, each of which is encoded by a distinct gene.[16]
Hexokinase I is the predominant isozyme in the brain. In skeletal muscle, both hexokinase I and II are expressed, contributing approximately 70–75% and 25–30% of total hexokinase activity, respectively.[9]
Hexokinase IV, also known as glucokinase (EC 2.7.1.2), is primarily expressed in hepatocytes and pancreatic β-cells, where it is the predominant isozyme. In the liver, glucokinase participates, together with glucose 6-phosphatase, in the substrate cycle between glucose and glucose 6-phosphate. Glucokinase differs from the other hexokinase isozymes in both its kinetic and regulatory properties.[54]
Note: isozymes (or isoenzymes) are distinct proteins that catalyze the same reaction but generally differ in kinetic and regulatory properties, subcellular localization, or cofactor requirements. They may coexist within the same organism, the same tissue, or even the same cell.[55]
Kinetic properties of hexokinase isozymes
The kinetic properties of hexokinase I, II, and III are broadly similar.
Hexokinase I and II have Km values for glucose of 0.03 mM and 0.1 mM, respectively. These low Km values allow the enzymes to function efficiently at normal blood glucose concentrations (4–5 mM).
By contrast, glucokinase has a high Km for glucose (≈ 10 mM), meaning it is active primarily when blood glucose levels are elevated, such as after a carbohydrate-rich meal.[9]
Regulation of the activity of hexokinases I–III
Hexokinases I–III are allosterically inhibited by glucose 6-phosphate, the product of their reaction.[16] This feedback mechanism prevents the accumulation of glucose 6-phosphate in the cytosol when glucose is not required for:
At the same time, this regulation allows glucose to remain in the bloodstream, available to other tissues. For example, inhibition of phosphofructokinase-1 leads to the accumulation of fructose 6-phosphate, which, via the phosphoglucose isomerase reaction, increases glucose 6-phosphate levels. Consequently, inhibition of PFK-1 indirectly inhibits the activity of hexokinases I–III.[56]
Coordination of hexokinase and GLUT4 in skeletal muscle
In skeletal muscle, the activities of hexokinase I and II are tightly coordinated with those of GLUT4, a glucose transporter with a Km of ≈ 5 mM. Translocation of GLUT4 to the plasma membrane is stimulated by both insulin and physical activity. The combined action of GLUT4-mediated glucose uptake and cytosolic hexokinase activity maintains a balance between glucose entry and its phosphorylation.[9]
Since blood glucose concentrations typically range between 4 and 5 mM, GLUT4-mediated uptake increases intracellular glucose to levels sufficient to saturate, or nearly saturate, hexokinase, allowing the enzyme to operate at or near its Vmax.[57]
Hepatic glucokinase
Glucokinase differs in three key respects from hexokinases I–III and is particularly well-suited to the liver’s role in regulating blood glucose levels.[54][58]
Kinetic and functional properties
As previously mentioned, glucokinase has a Km for glucose of about 10 mM, much higher than that of hexokinases I–III and also higher than fasting blood glucose levels (4–5 mM). In the liver, where glucokinase is the predominant hexokinase isoenzyme, its role is to provide glucose 6-phosphate for the synthesis of glycogen and fatty acids. The activity of glucokinase is linked to that of GLUT2, the main glucose transporter in hepatocytes, which also has a high Km for glucose (approximately 10 mM).[16]
Hence, GLUT2 is highly active when blood glucose levels are elevated, rapidly equilibrating glucose concentrations between the cytosol of hepatocytes and the blood. Under such conditions, glucokinase is active and converts glucose into G6P. Due to its high Km, glucokinase activity continues to rise even as intracellular glucose concentrations reach or exceed 10 mM. Therefore, the rate of glucose uptake and phosphorylation is directly determined by blood glucose levels.[59]
Conversely, when glucose availability is low, its cytosolic concentration in hepatocytes is also low, much lower than the Km of glucokinase, which ensures that glucose produced through gluconeogenesis and/or glycogenolysis is not phosphorylated and can exit the cell.[60] A similar situation also occurs in pancreatic β-cells, where the GLUT2/glucokinase system aligns intracellular glucose 6-phosphate levels with blood glucose levels, allowing the cells to detect and respond to hyperglycemia.[61]
Regulation by glucokinase regulatory protein
Unlike hexokinases I–III, glucokinase is not inhibited by glucose 6-phosphate, that is, it is not subject to product inhibition, and continues to catalyze glucose phosphorylation even when glucose 6-phosphate accumulates. Glucokinase is inhibited by reversible binding to the glucokinase regulatory protein (GKRP), a liver-specific regulator. This inhibition involves the sequestration of glucokinase in the nucleus, separating it from other glycolytic enzymes.[60][62]
Regulation of Hepatic Glucokinase Activity
The binding between glucokinase and GKRP is strengthened by fructose 6-phosphate, whereas it is weakened by glucose and fructose 1-phosphate.
In the absence of glucose, glucokinase adopts its “super-open” conformation, which is capable of binding to GKRP. Rising cytosolic glucose concentrations trigger a concentration-dependent shift to the “closed” conformation, its active form, which cannot bind GKRP. As a result, glucokinase becomes active and is no longer inhibited.
Note that fructose 1-phosphate is present in the hepatocyte only when fructose is metabolized. Therefore, fructose relieves glucokinase inhibition by disrupting its interaction with GKRP.[63]
Physiological significance
After a carbohydrate-rich meal, blood glucose levels rise. Glucose enters hepatocytes via GLUT2 and then diffuses into the nucleus through nuclear pores. There, glucose promotes the transition of glucokinase to its closed, active conformation, which is no longer accessible to GKRP. This allows glucokinase to diffuse into the cytosol, where it phosphorylates glucose.
Conversely, when glucose concentration declines, such as during fasting when blood glucose levels may fall below 4 mM, glucose levels in hepatocytes also drop. Under these conditions, fructose 6-phosphate binds to GKRP, enhancing its affinity for glucokinase and resulting in strong inhibition of the enzyme. This mechanism ensures that, at low blood glucose levels, the liver does not compete with other organs, primarily the brain, for glucose.
Within the cell, fructose 6-phosphate is in equilibrium with glucose 6-phosphate due to the action of phosphoglucose isomerase. By binding to GKRP, fructose 6-phosphate contributes to the suppression of glucokinase activity, thereby preventing the accumulation of glycolytic intermediates.
To sum up, when blood glucose levels are within the normal range, glucose is phosphorylated primarily by hexokinases I–III. When blood glucose levels are high, glucokinase contributes to glucose phosphorylation as well.[9][64]
Regulation of phosphofructokinase-1 activity
Phosphofructokinase-1 is the key control point for carbon flow through glycolysis.[65]
In addition to substrate binding sites, the enzyme has several binding sites for allosteric effectors.
ATP, citrate, and hydrogen ions act as allosteric inhibitors of the enzyme, whereas AMP, Pi, and fructose 2,6-bisphosphate function as allosteric activators.[66][67][68]
Regulation of PFK 1 and Fructose 1,6-Bisphosphatase
It is worth noting that ATP, an end product of glycolysis, is also a substrate of phosphofructokinase-1. The enzyme possesses two binding sites for the nucleotide: a low-affinity regulatory site and a high-affinity substrate site.[9]
What allosteric effectors signal
ATP, AMP, and Pi signal the energy status of the cell.
PFK-1 activity increases when the energy charge of the cell is low, that is, when ATP is needed, and decreases when the energy charge is high, that is, when ATP levels are elevated.[69]
How this happens
When ATP is produced faster than it is consumed, its intracellular concentration becomes elevated. Under these conditions, ATP binds to its allosteric site and inhibits PFK-1 by reducing the enzyme’s affinity for fructose 6-phosphate.
From a kinetic perspective, increased ATP concentration alters the relationship between enzyme activity and substrate concentration, changing the hyperbolic velocity curve of fructose 6-phosphate into a sigmoidal one and thereby increasing the Km for the substrate.
However, under most physiological conditions, intracellular ATP concentration does not vary significantly. For example, during vigorous exercise, ATP concentration in muscle may decrease by about 10% compared to resting levels, whereas the glycolytic rate changes much more than would be expected from such a small reduction.
When ATP consumption exceeds its production, concentrations of ADP and AMP rise, particularly AMP, due to the reaction catalyzed by adenylate kinase (EC 2.7.4.3), which forms ATP and AMP from two ADP molecules.
ADP + ADP ⇄ ATP + AMP
The equilibrium constant of the reaction is:
Keq = [ATP][AMP]/[ADP]2 = 0.44
Under physiological conditions, the concentrations of ADP and AMP are approximately 10% and often less than 1% of the ATP concentration, respectively. Therefore, considering that the total adenylate pool remains constant over the short term, even a small decrease in ATP concentration leads, due to adenylate kinase activity, to a much larger relative increase in AMP concentration. In turn, AMP acts by reversing the inhibition caused by ATP.
Thus, the activity of phosphofructokinase-1 depends on the cellular energy status:
when ATP is plentiful, enzyme activity decreases;
when AMP levels increase and ATP levels fall, enzyme activity increases.[9]
Why ADP isn’t a positive effector of PFK-1
There are two reasons.
First, when the cell’s energy charge decreases, ADP is used to regenerate ATP via the reaction catalyzed by adenylate kinase.
Second, as previously mentioned, even a small decrease in ATP leads to proportionally larger changes in ADP levels, and, especially, in AMP levels.[70]
Role of hydrogen ions
Hydrogen ions also inhibit PFK-1. This inhibition helps regulate the rate of glycolysis, preventing excessive lactate accumulation and a consequent drop in cellular pH.[71]
Role of citrate
Citrate is an allosteric inhibitor of PFK-1 that acts by enhancing the inhibitory effect of ATP.
It is the product of the first step of the citric acid cycle, a metabolic pathway that provides building blocks for biosynthetic processes and directs electrons into the mitochondrial electron transport chain for ATP synthesis via oxidative phosphorylation.
High cytosolic citrate levels indicate that energy demands are met and an abundance of biosynthetic precursors is available (exported from the mitochondria); in other words, the citric acid cycle is saturated.
Under such conditions, glycolysis, which feeds the cycle under aerobic conditions, can slow down, sparing glucose.
Therefore, it should be noted that PFK-1 functionally couples glycolysis to the citric acid cycle.[65][72]
Regulation of PFK-1 and FBPase-1 in the liver
In the liver, the central control point of glycolysis and gluconeogenesis is the substrate cycle between F6P and F1,6BP, catalyzed by PFK-1 and fructose 1,6-bisphosphatase.
The liver plays a pivotal role in maintaining blood glucose levels within the normal range.
When blood glucose levels drop, glucagon stimulates hepatic glucose production via both glycogenolysis and gluconeogenesis, while simultaneously signaling the liver to stop consuming glucose for its own energy needs.
Conversely, when blood glucose levels are high, insulin promotes glucose utilization for energy and the synthesis of glycogen and triglycerides.
In this context, the regulation of glycolysis and gluconeogenesis is mediated by fructose 2,6-bisphosphate (F2,6BP), a molecule that enables the liver to play a major role in regulating blood glucose levels and whose concentration is controlled by insulin and glucagon.[56]
Role of fructose 2,6-bisphosphate
By binding to its allosteric site on PFK-1, fructose 2,6-bisphosphate increases the affinity of the enzyme for fructose 6-phosphate, its substrate, while counteracting the inhibitory effect citrate and ATP.
It is remarkable that under physiological concentrations of substrates and both positive and negative allosteric effectors, PFK-1 would be virtually inactive in the absence of fructose 2,6-bisphosphate.
On the other hand, the binding of fructose 2,6-bisphosphate to fructose 1,6-bisphosphatase inhibits the enzyme, even in the absence of AMP, another of its allosteric inhibitors.
As a result of these effects, fructose 2,6-bisphosphate increases the net flux of glucose through glycolysis.[66][67][73]
Role of xylulose 5-phosphate
Xylulose 5-phosphate also plays a role in controlling carbon flux through glycolysis and gluconeogenesis. It is a product of the pentose phosphate pathway, whose levels in hepatocytes rise after the ingestion of a carbohydrate-rich meal. By activating protein phosphatase 2A, this metabolite induces the dephosphorylation of the bifunctional enzyme PFK-2/FBPase-2. This dephosphorylation activates its kinase domain, ultimately increasing fructose 2,6-bisphosphate levels, thereby enhancing glycolytic flux and reducing gluconeogenic flux.[74]
Regulation of pyruvate kinase activity
Another key control point for carbon flux through glycolysis and gluconeogenesis is the substrate cycle between phosphoenolpyruvate and pyruvate, catalyzed by pyruvate kinase in glycolysis and by the combined action of pyruvate carboxylase and phosphoenolpyruvate carboxykinase (EC 4.1.1.32) in gluconeogenesis.[9]
Allosteric regulation
All pyruvate kinase isozymes are allosterically inhibited by high concentrations of ATP, long-chain fatty acids, and acetyl-CoA, all indicators that the cell is in a high-energy state. Alanine, which can be synthesized from pyruvate through a transamination reaction, is also an allosteric inhibitor; its accumulation signals that biosynthetic precursors are abundant.
Regulation of Pyruvate Kinase Activity
Conversely, pyruvate kinase is allosterically activated by fructose 1,6-bisphosphate, the product of the first committed step of glycolysis. F1,6BP thus ensures that pyruvate kinase activity keeps pace with the upstream flux of intermediates. It should be emphasized that, at physiological concentrations of PEP, ATP, and alanine, the enzyme would be almost completely inhibited in the absence of F1,6BP activation.[27][75]
Covalent regulation in the liver
The hepatic isoenzyme, but not the muscle isoenzyme, is also regulated by phosphorylation through:
primarily protein kinase A (PKA), activated by glucagon (or epinephrine via β-adrenergic receptors);
calcium/calmodulin dependent protein kinase (CAMK), activated by epinephrine via α1-adrenergic receptors.
Phosphorylation of the enzyme decreases its activity by increasing the Km for PEP, thereby slowing glycolysis.
For example, when blood glucose levels are low, glucagon-induced phosphorylation reduces pyruvate kinase activity. The phosphorylated enzyme is also less responsive to activation by fructose 1,6-bisphosphate and more sensitive to inhibition by alanine and ATP.
Conversely, the dephosphorylated form of pyruvate kinase is more responsive to F1,6BP, that is, it requires a lower concentration for activation, and less sensitive to ATP and alanine. This mechanism allows the liver, under low-glucose conditions, to limit its own glucose utilization, preserving glucose for other organs such as the brain.
It should be noted, however, that the powerful activation by F1,6BP overrides the inhibitory effects of phosphorylation by PKA.
An increase in the insulin/glucagon ratio promotes dephosphorylation and enzyme activation.[9]
References
^ abcdefghijkl Nelson D.L., Cox M.M. Lehninger. Principles of biochemistry. 8th Edition. W.H. Freeman and Company, 2021.
^ Alberts B., Johnson A., Lewis J., Morgan D., Raff M., Roberts K., Walter P. Molecular Biology of the Cell. 7th Edition. Garland Science, Taylor & Francis Group, 2022.
^ abcdefgh Heilman D., Woski S., Voet D., Voet J.G., Pratt C.W. Fundamentals of biochemistry: life at the molecular level. 6th Edition. Wiley, 2023.
^ Fruton J.S. A History of Biochemistry. Harvard University Press, 1982.
^ Buchner E., Rapp R. Alkoholische Gärung ohne Hefezellen. Berichte der Deutschen Chemischen Gesellschaft 1899;32(1):127-137. doi:10.1002/cber.18990320124
^ Kohler R. The background to Eduard Buchner’s discovery of cell-free fermentation. J Hist Biol 1971;4:35-61. doi:10.1007/BF00356976
^ abcdefghijk Stipanuk M.H., Caudill M.A. Biochemical, physiological, and molecular aspects of human nutrition. 4th Edition. St. Louis: Elsevier, 2018.
^ Lu Z., Imlay J.A. When anaerobes encounter oxygen: mechanisms of oxygen toxicity, tolerance and defence. Nat Rev Microbiol 2021;19(12):774-785. doi:10.1038/s41579-021-00583-y
^ abcdefghijkl Berg J.M., Tymoczko J.L., Gregory J.G. Jr, Stryer L. Biochemistry. 9th Edition. W.H. Freeman and Company, 2019.
^ Plaxton W.C., Podestá F.E. The functional organization and control of plant respiration. Crit Rev Plant Sci 2006;25(2):159-198. doi:10.1080/07352680600563876
^ Hochachka P.W., Somero G.N. Biochemical adaptation: mechanism and process in physiological evolution. Oxford University Press, 2002. doi:10.1093/oso/9780195117028.001.0001
^ ab Naifeh N., Dimri M., Varacallo M.A. Biochemistry, Aerobic Glycolysis. [Updated 2023 Apr 9]. In: StatPearls [Internet]. Treasure Island (FL): StatPearls Publishing; 2025 Jan-. Available from: https://www.ncbi.nlm.nih.gov/sites/books/NBK470170/
^ Lunt S.Y., Vander Heiden M.G. Aerobic glycolysis: meeting the metabolic requirements of cell proliferation. Annu Rev Cell Dev Biol 2011;27:441-64. doi:10.1146/annurev-cellbio-092910-154237
^ abcd Wilson J.E. Isozymes of mammalian hexokinase: structure, subcellular localization and metabolic function. J Exp Biol 2003;206(Pt 12):2049-57. doi:10.1242/jeb.00241
^ abcdefghij Atkins P.W., Ratcliffe R.G., Wormald M., De Paula J. Physical chemistry for the life sciences. 3rd Edition. Oxford University Press, 2023.
^ Mertens E. Pyrophosphate-dependent phosphofructokinase, an anaerobic glycolytic enzyme? FEBS Lett 1991;285(1):1-5. doi:10.1016/0014-5793(91)80711-b
^ Knowles J.R. Enzyme catalysis: not different, just better. Nature 1991;350(6314):121-4. doi:10.1038/350121a0
^ Sirover M.A. On the functional diversity of glyceraldehyde-3-phosphate dehydrogenase: biochemical mechanisms and regulatory control. Biochim Biophys Acta 2011;1810(8):741-51. doi:10.1016/j.bbagen.2011.05.010
^ Rojas-Pirela M., Andrade-Alviárez D., Rojas V., Kemmerling U., Cáceres A.J., Michels P.A., Concepción J.L., Quiñones W. Phosphoglycerate kinase: structural aspects and functions, with special emphasis on the enzyme from Kinetoplastea. Open Biol 2020;10(11):200302. doi:10.1098/rsob.200302
^ Levin S., Almo S.C., Satir B.H. Functional diversity of the phosphoglucomutase superfamily: structural implications. Protein Eng 1999;12(9):737-46. doi:10.1093/protein/12.9.737
^ Rapoport S., Luebering J. The formation of 2,3-diphosphoglycerate in rabbit erythrocytes: the existence of a diphosphoglycerate mutase. J Biol Chem 1950;183(2):507-516.
^ Webb K.L., Dominelli P.B., Baker S.E., Klassen S.A., Joyner M.J., Senefeld J.W., Wiggins C.C. Influence of high hemoglobin-oxygen affinity on humans during hypoxia. Front Physiol 2022;12:763933. doi:10.3389/fphys.2021.763933
^ Li M., Wu C., Yang Y., Zheng M., Yu S., Wang J., Chen L., Li H. 3-Phosphoglycerate dehydrogenase: a potential target for cancer treatment. Cell Oncol (Dordr) 2021;44(3):541-556. doi:10.1007/s13402-021-00599-9
^ Lebioda L., Stec B. Mechanism of enolase: the crystal structure of enolase-Mg2+-2-phosphoglycerate/phosphoenolpyruvate complex at 2.2-A resolution. Biochemistry 1991;30(11):2817-22. doi:10.1021/bi00225a012
^ ab Schormann N., Hayden K.L., Lee P., Banerjee S., Chattopadhyay D. An overview of structure, function, and regulation of pyruvate kinases. Protein Sci 2019;28(10):1771-1784. doi:10.1002/pro.3691
^ Yang Y., Sauve A.A. NAD+ metabolism: bioenergetics, signaling and manipulation for therapy. Biochim Biophys Acta 2016;1864(12):1787-1800. doi:10.1016/j.bbapap.2016.06.014
^ Gray L.R., Tompkins S.C., Taylor E.B. Regulation of pyruvate metabolism and human disease. Cell Mol Life Sci 2014;71(14):2577-604. doi:10.1007/s00018-013-1539-2
^ Rogatzki M.J., Ferguson B.S., Goodwin M.L., Gladden L.B. Lactate is always the end product of glycolysis. Front Neurosci 2015;9:22. doi:10.3389/fnins.2015.00022
^ Geison G.L. The Private Science of Louis Pasteur. Princeton University Press, 1995.
^ Dong S., Qian L., Cheng Z., Chen C., Wang K., Hu S., Zhang X., Wu T. Lactate and myocardiac energy metabolism. Front Physiol 2021;12:715081. doi:10.3389/fphys.2021.715081
^ National Research Council (US) Panel on the Applications of Biotechnology to Traditional Fermented Foods. Applications of Biotechnology to Fermented Foods: Report of an Ad Hoc Panel of the Board on Science and Technology for International Development. Washington (DC): National Academies Press (US); 1992. 5, Lactic Acid Fermentations. Available from: https://www.ncbi.nlm.nih.gov/books/NBK234703/
^ Dzialo M.C., Park R., Steensels J., Lievens B., Verstrepen K.J. Physiology, ecology and industrial applications of aroma formation in yeast. FEMS Microbiol Rev 2017;41(Supp_1):S95-S128. doi:10.1093/femsre/fux031
^ Maicas S. The role of yeasts in fermentation processes. Microorganisms 2020;8(8):1142. doi:10.3390/microorganisms8081142
^ Patel M.S., Nemeria N.S., Furey W., and Jordan F. The pyruvate dehydrogenase complexes: structure-based function and regulation. J Biol Chem 2014;289(24):16615-16623. doi:10.1074/jbc.R114.563148
^ Liu H., Wang S., Wang J., Guo X., Song Y., Fu K., Gao Z., Liu D., He W., Yang L.L. Energy metabolism in health and diseases. Signal Transduct Target Ther 2025;10(1):69. doi:10.1038/s41392-025-02141-x
^ Borst P. The malate-aspartate shuttle (Borst cycle): How it started and developed into a major metabolic pathway. IUBMB Life 2020;72(11):2241-2259. doi:10.1002/iub.2367
^ ab Ahmad M., Wolberg A., Kahwaji C.I. Biochemistry, Electron Transport Chain. [Updated 2023 Sep 4]. In: StatPearls [Internet]. Treasure Island (FL): StatPearls Publishing; 2025 Jan-. Available from: https://www.ncbi.nlm.nih.gov/books/NBK526105/
^ Chaudhry R., Varacallo M.A. Biochemistry, Glycolysis. [Updated 2023 Aug 8]. In: StatPearls [Internet]. Treasure Island (FL): StatPearls Publishing; 2025 Jan-. Available from: https://www.ncbi.nlm.nih.gov/books/NBK482303/
^ DeBerardinis R.J., Chandel N.S. Fundamentals of cancer metabolism. Sci Adv 2016;2(5):e1600200. doi:10.1126/sciadv.1600200
^ Kiela P.R., Ghishan F.K. Physiology of intestinal absorption and secretion. Best Pract Res Clin Gastroenterol 2016;30(2):145-59. doi:10.1016/j.bpg.2016.02.007
^ ab Dholariya S.J., Orrick J.A. Biochemistry, Fructose Metabolism. [Updated 2022 Oct 17]. In: StatPearls [Internet]. Treasure Island (FL): StatPearls Publishing; 2025 Jan-. Available from: https://www.ncbi.nlm.nih.gov/books/NBK576428/
^ ab Hannou S.A., Haslam D.E., McKeown N.M., Herman M.A. Fructose metabolism and metabolic disease. J Clin Invest 2018;128(2):545-555. doi:10.1172/JCI96702
^ Legeza B., Marcolongo P., Gamberucci A., Varga V., Bánhegyi G., Benedetti A., Odermatt A. Fructose, glucocorticoids and adipose tissue: implications for the metabolic syndrome. Nutrients 2017;9(5):426. doi:10.3390/nu9050426
^ Frey P.A. The Leloir pathway: a mechanistic imperative for three enzymes to change the stereochemical configuration of a single carbon in galactose. FASEB J 1996;10(4):461-70. doi:10.1096/fasebj.10.4.8647345
^ Conte F., van Buuringen N., Voermans N.C., Lefeber D.J. Galactose in human metabolism, glycosylation and congenital metabolic diseases: time for a closer look. Biochim Biophys Acta Gen Subj 2021;1865(8):129898. doi:10.1016/j.bbagen.2021.129898
^ Succoio M., Sacchettini R., Rossi A., Parenti G., Ruoppolo M. Galactosemia: biochemistry, molecular genetics, newborn screening, and treatment. Biomolecules 2022;12(7):968. doi:10.3390/biom12070968
^ Sharma V., Ichikawa M., Freeze H.H. Mannose metabolism: more than meets the eye. Biochem Biophys Res Commun 2014;453(2):220-8. doi:10.1016/j.bbrc.2014.06.021
^ ab de la Iglesia N., Mukhtar M., Seoane J., Guinovart J.J., Agius L. The role of the regulatory protein of glucokinase in the glucose sensory mechanism of the hepatocyte. J Biol Chem 2000;275(14):10597-10603. doi: 10.1074/jbc.275.14.10597
^ Zhang Y., Lin Z., Wang M., Lin H. Selective usage of isozymes for stress response. ACS Chem Biol 2018;13(11):3059-3064. doi:10.1021/acschembio.8b00767
^ ab Han H.S., Kang G., Kim J.S., Choi B.H., Koo S.H. Regulation of glucose metabolism from a liver-centric perspective. Exp Mol Med 2016;48(3):e218. doi:10.1038/emm.2015.122
^ Matschinsky F.M., Magnuson M.A., Zelent D., Jetton T.L., Doliba N., Han Y., Taub R., Grimsby J. The network of glucokinase-expressing cells in glucose homeostasis and the potential of glucokinase activators for diabetes therapy. Diabetes 2006;55(1):1-12. doi:diabetes.55.01.06.db05-0926
^ Sun B., Chen H., Xue J., Li P., Fu X. The role of GLUT2 in glucose metabolism in multiple organs and tissues. Mol Biol Rep 2023;50(8):6963-6974. doi:10.1007/s11033-023-08535-w
^ ab Adeva-Andany M.M., Pérez-Felpete N., Fernández-Fernández C., Donapetry-García C., Pazos-García C. Liver glucose metabolism in humans. Biosci Rep 2016;36(6):e00416. doi:10.1042/BSR20160385
^ Abu Aqel Y., Alnesf A., Aigha I.I., Islam Z., Kolatkar P.R., Teo A., Abdelalim E.M. Glucokinase (GCK) in diabetes: from molecular mechanisms to disease pathogenesis. Cell Mol Biol Lett. 2024 Sep 8;29(1):120. doi:10.1186/s11658-024-00640-3
^ Kaminski M.T., Schultz J., Waterstradt R., Tiedge M., Lenzen S., Baltrusch S. Glucose-induced dissociation of glucokinase from its regulatory protein in the nucleus of hepatocytes prior to nuclear export. Biochim Biophys Acta 2014;1843(3):554-564. doi:10.1016/j.bbamcr.2013.12.002
^ Sternisha S.M., Miller B.G. Molecular and cellular regulation of human glucokinase. Arch Biochem Biophys 2019;663:199-213. doi:10.1016/j.abb.2019.01.011
^ Matschinsky F.M., Wilson D.F. The central role of glucokinase in glucose homeostasis: a perspective 50 years after demonstrating the presence of the enzyme in islets of Langerhans. Front Physiol 2019;10:148. doi:10.3389/fphys.2019.00148
^ ab Mor I., Cheung E.C., Vousden K.H. Control of glycolysis through regulation of PFK1: old friends and recent additions. Cold Spring Harb Symp Quant Biol 2011;76:211-6. doi:10.1101/sqb.2011.76.010868
^ ab Van Schaftingen E., and Hers H-G. Inhibition of fructose-1,6-bisphosphatase by fructose-2,6-bisphosphate. Proc Natl Acad Sci USA 1981;78(5):2861-2863. doi:10.1073/pnas.78.5.2861
^ ab Van Schaftingen E., Jett M-F., Hue L., and Hers H-G. Control of liver 6-phosphofructokinase by fructose 2,6-bisphosphate and other effectors. Proc Natl Acad Sci USA 1981;78(6):3483-3486. doi:10.1073/pnas.78.6.3483
^ Lynch E.M., Hansen H., Salay L., Cooper M., Timr S., Kollman J.M., Webb B.A. Structural basis for allosteric regulation of human phosphofructokinase-1. Nat Commun 2024;15(1):7323. doi:10.1038/s41467-024-51808-6
^ Jenkins C.M., Yang J., Sims H.F., Gross R.W. Reversible high affinity inhibition of phosphofructokinase-1 by acyl-CoA: a mechanism integrating glycolytic flux with lipid metabolism. J Biol Chem 2011;286(14):11937-50. doi:10.1074/jbc.M110.203661
^ Atkinson D.E. The energy charge of the adenylate pool as a regulatory parameter. Interaction with feedback modifiers. Biochemistry 1968;7(11):4030-4. doi:10.1021/bi00851a033
^ Lešnik S., Konc J., Vodopivec T., Čamernik K., Karolina Potokar U., Legiša M. Small-molecule inhibitors of 6-phosphofructo-1-kinase simultaneously suppress lactate and superoxide generation in cancer cells. PLoS One 2025;20(5):e0321998. doi:10.1371/journal.pone.0321998
^ Usenik A., Legiša M. Evolution of allosteric citrate binding sites on 6-phosphofructo-1-kinase. PLoS One 2010;5(11):e15447. doi:10.1371/journal.pone.0015447
^ Chaekal O.K., Boaz J.C., Sugano T., Harris R.A. Role of fructose 2,6-bisphosphate in the regulation of glycolysis and gluconeogenesis in chicken liver. Arch Biochem Biophys 1983;225(2):771-8. doi:10.1016/0003-9861(83)90088-7
^ Kabashima T., Kawaguchi T., Wadzinski B.E., Uyeda K. Xylulose 5-phosphate mediates glucose-induced lipogenesis by xylulose 5-phosphate-activated protein phosphatase in rat liver. Proc Natl Acad Sci USA 2003;100:5107-5112. doi:10.1073/pnas.0730817100
^ Jurica M.S., Mesecar A., Heath P.J., Shi W., Nowak T., Stoddard B.L. The allosteric regulation of pyruvate kinase by fructose-1,6-bisphosphate. Structure 1998;6(2):195-210. doi:10.1016/s0969-2126(98)00021-5
Gluconeogenesis is a metabolic pathway that leads to the synthesis of glucose (Glu) from pyruvate (Pyr), the conjugate base of pyruvic acid, and other non-carbohydrate precursors, even in non-photosynthetic organisms.[1]
It occurs in all microorganisms, fungi, plants, and animals, and the reactions are essentially the same, leading to the synthesis of one glucose molecule from two pyruvate molecules. It is essentially glycolysis in reverse, sharing seven enzymes with it, but proceeding from pyruvate to glucose.[2]
Glycogenolysis is clearly distinct from gluconeogenesis, as it does not result in the de novo synthesis of glucose from non-carbohydrate precursors, as illustrated by its overall reaction:[3]
Glycogen or (glucose)n → n glucose 1-phosphate molecules.
The following discussion will focus on gluconeogenesis in higher animals, particularly in the mammalian liver.
Summary: Key Points
Definition: the metabolic pathway responsible for synthesizing glucose from non-carbohydrate precursors such as pyruvate, lactate, glycerol, and glucogenic amino acids.
Biological function: essential for maintaining stable blood glucose levels, particularly to supply glucose to the brain and red blood cells during prolonged fasting.
Mechanism: not a simple reversal of glycolysis; instead, it bypasses three irreversible glycolytic steps through the action of specific enzymes, including pyruvate carboxylase, phosphoenolpyruvate carboxykinase, and fructose-1,6-bisphosphatase.
Main sites: occurs primarily in the liver (≈90%) and, to a lesser extent, in the renal cortex, involving the mitochondria, cytosol, and endoplasmic reticulum.
Hormonal control: regulated mainly by the insulin-to-glucagon ratio and by allosteric effectors such as fructose-2,6-bisphosphate.
Gluconeogenesis is essential for two main reasons: it maintains appropriate blood glucose levels when glycogen stores are low and no carbohydrates are available, and it preserves metabolic intermediates, such as pyruvate, needed for energy production.[4]
Maintaining blood glucose between 3.3 and 5.5 mmol/L (60–99 mg/dL) is critical, as many cells rely on glucose to meet their ATP needs. These include red blood cells, neurons, the renal medulla, skeletal muscle under low oxygen, the testes, the lens and cornea, and embryonic tissues.[5]
For example, the brain alone requires about 120 g/day of glucose, which represents:
over 50% of the total body glucose stores (≈210 g), of which about 190 g are stored as liver and muscle glycogen, and 20 g are found free in body fluids;
about 75% of the daily glucose requirement (≈160 g).[4]
During fasting, such as between meals or overnight, blood glucose levels are maintained within the normal range primarily through hepatic glycogenolysis, as well as the release of fatty acids from adipose tissue and ketone body production by the liver.
Fatty acids and ketone bodies are preferentially used by skeletal muscle, thereby sparing glucose for cells that depend entirely on it, especially red blood cells and neurons.
However, after approximately 18 hours of fasting, or during intense and prolonged exercise, glycogen stores become insufficient. At this point, in the absence of carbohydrate intake, gluconeogenesis becomes critical.[6]
Its importance is further highlighted by the fact that blood glucose levels below 2 mmol/L can lead to unconsciousness.[7]
Additionally, without gluconeogenesis, pyruvate would be lost, reducing the body’s capacity to produce ATP via aerobic respiration (more than 10 ATP molecules per pyruvate oxidized), making its conservation essential during energy stress.[1]
Sites of gluconeogenesis
In higher animals, gluconeogenesis occurs in the liver, kidney cortex, and enterocytes.[4]
Quantitatively, the liver is the major site, producing about 90% of synthesized glucose, followed by the kidney cortex with around 10%. The liver’s key role is largely due to its size; in fact, on a wet weight basis, the kidney cortex produces more glucose than the liver.[8]
In the kidney, gluconeogenesis takes place in the proximal tubule cells. Much of the glucose produced is consumed by the renal medulla, while the kidney’s role in maintaining blood glucose becomes more prominent during prolonged fasting or liver failure. Unlike the liver, the kidney lacks significant glycogen stores and contributes to glucose homeostasis only through gluconeogenesis, not glycogenolysis.
Only limited portions of the gluconeogenic pathway are active in skeletal muscle, cardiac muscle, and the brain, and at very low rates.
However, these tissues cannot release free glucose into the bloodstream because they lack glucose 6-phosphatase (EC 3.1.3.9), the enzyme responsible for the final step of gluconeogenesis. As a result, glucose 6-phosphate (G6P) produced, either via gluconeogenesis or glycogenolysis, remains trapped in the cell and is used only for internal energy needs or glycogen resynthesis. In the brain, this occurs mainly in astrocytes. The only direct contribution of these tissues to blood glucose maintenance, particularly skeletal muscle, due to its large mass (approximately 18 times that of the liver), comes from the limited release of free glucose via the debranching enzyme (EC 3.2.1.33) during glycogenolysis.[4]
Most gluconeogenic reactions occur in the cytosol, though some steps take place in the mitochondria, and the final step, catalyzed by glucose 6-phosphatase, occurs within the endoplasmic reticulum cisternae.[3]
Irreversible steps in the pathway
As previously mentioned, gluconeogenesis is essentially glycolysis in reverse. Of the ten reactions that constitute gluconeogenesis, seven are shared with glycolysis. These reactions have a ΔG close to zero and are therefore easily reversible. However, under intracellular conditions, the overall ΔG of glycolysis is approximately –63 kJ/mol (–15 kcal/mol), while that of gluconeogenesis is about –16 kJ/mol (–3.83 kcal/mol). This indicates that both pathways are irreversiblein vivo.
Glycolysis and Gluconeogenesis Pathways
The irreversibility of glycolysis arises from three strongly exergonic reactions that cannot be used in gluconeogenesis.
Phosphorylation of glucose to glucose 6-phosphate, catalyzed by hexokinase (EC 2.7.1.1) or glucokinase (EC 2.7.1.2).
Phosphorylation of fructose 6-phosphate to fructose 1,6-bisphosphate (F1,6BP), catalyzed by phosphofructokinase-1 (PFK-1; EC 2.7.1.11).
Conversion of phosphoenolpyruvate (PEP) to pyruvate, catalyzed by pyruvate kinase (EC 2.7.1.40).
Irreversible reactions of glycolysis bypassed in gluconeogenesis
Reaction
Catalyzing enzyme
ΔG (kJ/mol) (kcal/mol)
ΔG°’ (kJ/mol) (kcal/mol)
Glu → G6P
Hexokinase or Glucokinase
–33.4 (–8.0)
–16.7 (–4.0)
F6P → F1,6BP
PFK-1
–22.2 (–5.3)
–14.2 (–3.4)
PEP → Pyr
Pyruvate kinase
–16.7 (–4.0)
–31.4 (–7.5)
In gluconeogenesis, these three steps are bypassed by enzymes that catalyze irreversible reactions in the direction of glucose synthesis.
These bypass reactions ensure that gluconeogenesis, like glycolysis, remains a thermodynamically irreversible pathway.[2]
The next sections will analyze these reactions in detail.
From pyruvate to phosphoenolpyruvate
The first step of gluconeogenesis that bypasses an irreversible step of glycolysis, namely the reaction catalyzed by pyruvate kinase, is the conversion of pyruvate to phosphoenolpyruvate.
This occurs through a two-step process catalyzed by:
Pyruvate carboxylase catalyzes the carboxylation of pyruvate to oxaloacetate, consuming one molecule of ATP in the process. The enzyme requires magnesium or manganese ions.
Pyr + HCO3–+ ATP → Oxaloacetate + ADP + Pi
Discovered in 1960 by Merton Utter, pyruvate carboxylase is a mitochondrial enzyme composed of four identical subunits, each containing a biotin prosthetic group. The biotin is covalently attached by an amide bond to the ε-amino group of a lysine residue and serves as a carrier of activated CO2 during the reaction. Each subunit also contains an allosteric site for acetyl-CoA, an essential activator of the enzyme.
In addition to its role in gluconeogenesis, this reaction also provides intermediates for the citric acid cycle.[10][11]
Phosphoenolpyruvate carboxykinase and PEP formation
Phosphoenolpyruvate carboxykinase catalyzes the decarboxylation and phosphorylation of oxaloacetate to form PEP. This reaction requires GTP as a phosphate donor and the presence of magnesium and manganese ions.[12]
Oxaloacetate + GTP → PEP + CO2 + GDP
The CO2 removed in this step is the same one added to pyruvate by pyruvate carboxylase. This carboxylation–decarboxylation sequence is crucial, as it facilitates the formation of PEP by making the reaction energetically favorable.[1]
More generally, such sequences are used to drive otherwise endergonic reactions and are also found in other metabolic pathways like the citric acid cycle, the pentose phosphate pathway, and fatty acid synthesis.[2]
Energetics of the overall conversion
The net reaction catalyzed by pyruvate carboxylase and PEPCK is:
Pyr + ATP + GTP + HCO3– → PEP + ADP + GDP + Pi + CO2
The ΔG°’ of this combined reaction is +0.9 kJ/mol (0.2 kcal/mol).
In contrast, the ΔG°’ for the reverse glycolytic reaction catalyzed by pyruvate kinase is +31.4 kJ/mol (7.5 kcal/mol).
Under intracellular conditions, however, the actual ΔG is highly negative (–25 kJ/mol, or –6 kcal/mol), due to rapid consumption of PEP, which keeps its concentration low.
Thus, the formation of PEP from pyruvate is effectively irreversible in vivo.[1]
Phosphoenolpyruvate precursors: pyruvate or alanine
Gluconeogenesis can proceed from various glucogenic precursors. This section examines the specific steps involved when pyruvate or alanine serve as the starting materials, highlighting how the pathway adapts according to the metabolic conditions.
Mitochondrial transport and conversion of pyruvate and alanine
The reactions described below predominate when pyruvate or alanine is the glucogenic precursor.
Since pyruvate carboxylase is a mitochondrial enzyme, pyruvate must first be transported from the cytosol into the mitochondrial matrix. This transport is mediated by specific proteins located in the inner mitochondrial membrane, namely MPC1 and MPC2. These two proteins associate to form a hetero-oligomeric complex that facilitates pyruvate import into mitochondria.[13]
Alternatively, pyruvate can be generated inside the mitochondrial matrix via transamination of alanine, catalyzed by alanine aminotransferase (EC 2.6.1.2). In this reaction, the amino group of alanine is transferred to α-ketoglutarate, producing glutamate and pyruvate. The resulting amino group is subsequently excreted as urea through the urea cycle.[14]
Oxaloacetate transport and conversion to PEP
Since most gluconeogenic enzymes (with the exception of glucose-6-phosphatase) are cytosolic, the oxaloacetate produced in the mitochondrial matrix must be transferred to the cytosol. However, oxaloacetate itself cannot cross the inner mitochondrial membrane directly.
To overcome this, it is reduced to malate in a reaction catalyzed by mitochondrial malate dehydrogenase (EC 1.1.1.37), an enzyme also involved in the citric acid cycle. This reaction uses NADH as a reducing agent, which is oxidized to NAD+.
Oxaloacetate + NADH + H+ ⇄ Malate + NAD+
Although the ΔG°’ of this reaction is strongly positive, under physiological conditions the ΔG is close to zero, making the reaction reversible and efficient in vivo.[2]
Malate is then transported into the cytosol via the malate-α-ketoglutarate transporter, a component of the malate-aspartate shuttle. Once in the cytosol, malate is re-oxidized to oxaloacetate by cytosolic malate dehydrogenase, regenerating NADH.
Malate + NAD+ → Oxaloacetate + NADH + H+
Note: the malate-aspartate shuttle is the most active mechanism for transferring reducing equivalents (NADH) from the cytosol into mitochondria. It operates in tissues such as the liver, kidney, and heart.[3]
The reverse use of this shuttle in gluconeogenesis allows NADH to be generated in the cytosol, which is essential for the reaction catalyzed by glyceraldehyde 3-phosphate dehydrogenase (EC 1.2.1.12). In fact, cytosolic NADH is normally present at very low concentrations, with a [NADH]/[NAD+] ratio of about 8 × 10−4, roughly 100,000 times lower than in mitochondria.[15]
Finally, the cytosolic oxaloacetate is converted to phosphoenolpyruvate by PEP carboxykinase.
Phosphoenolpyruvate precursor: lactate
Lactate is one of the major gluconeogenic precursors. It is produced, for example, by:
red blood cells, which rely entirely on anaerobic glycolysis for ATP production;
skeletal muscle during intense exercise, that is, under low-oxygen conditions when the rate of glycolysis exceeds that of the citric acid cycle and oxidative phosphorylation.[9]
When lactate serves as the gluconeogenic precursor, PEP synthesis proceeds through a different pathway than the one described for pyruvate or alanine.
In the hepatocyte cytosol, where the NAD+ concentration is high, lactate is oxidized to pyruvate by the liver isoenzyme of lactate dehydrogenase (EC 1.1.1.27). During this reaction, NAD+ is reduced to NADH.
Lactate + NAD+ → Pyr + NADH + H+
The generation of cytosolic NADH makes the export of reducing equivalents from mitochondria unnecessary.
Pyruvate then enters the mitochondrial matrix, where it is converted to oxaloacetate by pyruvate carboxylase. In this case, oxaloacetate is directly converted to PEP by the mitochondrial isoform of PEP carboxykinase. PEP is then transported out of the mitochondria via an anion transporter located in the inner mitochondrial membrane and continues along the gluconeogenic pathway in the cytosol.[3]
Note: the synthesis of glucose from lactate represents the hepatic phase of the Cori cycle, which links peripheral tissues to the liver in the recycling of lactate.[16]
From fructose 1,6-bisphosphate to fructose 6-phosphate
The second step of gluconeogenesis that bypasses an irreversible reaction of the glycolytic pathway, specifically the one catalyzed by phosphofructokinase-1, is the dephosphorylation of fructose 1,6-bisphosphate to fructose 6-phosphate.[5]
This reaction is catalyzed by fructose 1,6-bisphosphatase (FBPase-1; EC 3.1.3.11), a Mg2+-dependent enzyme located in the cytosol. It involves the hydrolysis of the phosphate group at the C-1 position of fructose 1,6-bisphosphate and does not generate ATP.
F1,6BP + H2O → F6P + Pi
The ΔG°’ for the reaction is –16.3 kJ/mol (–3.9 kcal/mol), indicating that it is irreversible under cellular conditions.[2]
From glucose 6-phosphate to glucose
The third step of gluconeogenesis that bypasses an irreversible reaction of the glycolytic pathway, specifically the one catalyzed by hexokinase or glucokinase, is the dephosphorylation of glucose 6-phosphate to glucose.[5]
This reaction is catalyzed by the catalytic subunit of glucose 6-phosphatase, part of a protein complex located in the endoplasmic reticulum membrane of hepatocytes, enterocytes, and the proximal tubule cells of the kidney.[8] The glucose 6-phosphatase complex consists of the catalytic subunit and a glucose 6-phosphate transporter known as T1 (glucose 6-phosphate translocase).
Importantly, the enzyme’s active site faces the lumen of the endoplasmic reticulum. This means that glucose is released inside the endoplasmic reticulum, not in the cytosol.[17]
Mechanism and regulation of glucose release
Glucose 6-phosphate, derived either from gluconeogenesis via the action of glucose 6-phosphate isomerase (EC 5.3.1.9), or from glycogenolysis via phosphoglucomutase (EC 5.4.2.2), is found in the cytosol and must be transported into the endoplasmic reticulum lumen to be dephosphorylated. This transport is mediated by T1 translocase.
Once inside the endoplasmic reticulum, the Mg2+-dependent catalytic subunit catalyzes the hydrolysis of the phosphate ester bond.[17]
G6P + H2O → Glu + Pi
As with the reaction catalyzed by FBPase-1, this is an irreversible reaction. The ΔG°′ is –13.8 kJ/mol (–3.3 kcal/mol). In contrast, the reverse reaction, catalyzed by hexokinase or glucokinase, would require the transfer of a phosphate group from glucose 6-phosphate to ADP, which would be highly endergonic (ΔG = +33.4 kJ/mol, or +8 kcal/mol).[2]
To prevent interference with glycolysis, which occurs in the cytosol, the glucose 6-phosphatase activity is spatially restricted to the endoplasmic reticulum lumen, ensuring compartmental separation of opposing pathways.[4]
Glucose and inorganic phosphate are exported from the endoplasmic reticulum to the cytosol by distinct transporters, likely T2, for glucose, and T3, an anion transporter for inorganic phosphate. Finally, glucose leaves the hepatocyte via the GLUT2 transporter, enters the bloodstream, and is delivered to tissues in need.[17]
Energy cost of gluconeogenesis
Like glycolysis, gluconeogenesis involves several energetically costly steps, particularly those that bypass the irreversible reactions of glycolysis.
In total, six high-energy phosphate bonds are consumed in the synthesis of one molecule of glucose from two molecules of pyruvate: four ATP and two GTP.
In addition, two molecules of NADH are required for the reduction of 1,3-bisphosphoglycerate to glyceraldehyde 3-phosphate, in the reaction catalyzed by glyceraldehyde 3-phosphate dehydrogenase.
The oxidation of NADH used in gluconeogenesis implies a loss of potential ATP that would otherwise be produced via oxidative phosphorylation, approximately five molecules of ATP are not synthesized due to the diversion of NADH from the electron transport chain.
These energetic demands reinforce the concept that gluconeogenesis is not simply glycolysis in reverse. If it were, it would require only the energy equivalent of two ATP molecules, as shown in the overall glycolytic equation.
In the liver, this energy is primarily provided by the oxidation of fatty acids. Under certain metabolic conditions, especially during prolonged fasting or high-protein intake, the oxidation of amino acid carbon skeletons can also contribute significantly to ATP and GTP production. The predominant source of energy depends on the available metabolic fuels at the time.[6]
Coordinated regulation of gluconeogenesis and glycolysis
If glycolysis and gluconeogenesis were simultaneously active at high rates within the same cell, the net result would be the consumption of ATP and the generation of heat, particularly at the irreversible steps of both pathways, with no productive metabolic outcome.
For example, consider the opposing reactions catalyzed by phosphofructokinase-1 and fructose 1,6-bisphosphatase-1.
PFK-1 reaction:
These two reactions, if occurring simultaneously in opposite directions, result in a futile cycle (also called a substrate cycle), leading to a wasteful dissipation of energy.[18]
To avoid this, the cell tightly regulates these pathways through three main mechanisms:
allosteric regulation
covalent modification (e.g., phosphorylation and dephosphorylation);
changes in enzyme concentration, regulated at the transcriptional or degradative level.
Allosteric regulation is rapid and reversible, occurring within milliseconds. In contrast, covalent modifications are typically triggered by extracellular signals, such as hormones like insulin, glucagon, or epinephrine, and occur over seconds to minutes. Regulation via enzyme synthesis or degradation takes even longer, on the order of hours.
This multi-layered regulation ensures that when pyruvate is directed into gluconeogenesis, glycolytic flux is simultaneously reduced, and vice versa, allowing for metabolic coordination in response to the cell’s energy status and systemic hormonal cues.[1]
Regulation of gluconeogenesis
The regulation of gluconeogenesis, like that of glycolysis, primarily targets the enzymes that are unique to each pathway, rather than those that are shared between them.
In glycolysis, the major regulatory control points are the reactions catalyzed by PFK-1 and pyruvate kinase. In contrast, gluconeogenesis is mainly regulated at the steps catalyzed by fructose 1,6-bisphosphatase and pyruvate carboxylase.
The other two enzymes unique to gluconeogenesis, glucose 6-phosphatase and phosphoenolpyruvate carboxykinase, are regulated primarily at the transcriptional level, in response to hormonal and metabolic signals.[4]
Pyruvate carboxylase
In mitochondria, pyruvate can be directed toward two major metabolic fates:
carboxylation to oxaloacetate via pyruvate carboxylase, initiating the gluconeogenic pathway.
The fate of pyruvate depends largely on the availability of acetyl-CoA, which in turn reflects the supply of fatty acids in the mitochondrion.
When fatty acids are abundant, their β-oxidation generates acetyl-CoA, which enters the citric acid cycle and produces GTP and NADH. If the cell’s energy needs are met, oxidative phosphorylation slows down, leading to an increase in the [NADH]/[NAD+] ratio. This elevated ratio inhibits the citric acid cycle, causing acetyl-CoA to accumulate in the mitochondrial matrix.
Acetyl-CoA acts as a key metabolic signal:
it is a positive allosteric effector of pyruvate carboxylase, promoting gluconeogenesis;
it is a negative allosteric effector of pyruvate kinase, inhibiting glycolysis;
it also inhibits the pyruvate dehydrogenase complex through feedback inhibition and via phosphorylation, activating a specific PDC kinase.
Thus, when the cellular energy charge is high, the conversion of pyruvate to acetyl-CoA slows down, while its conversion to oxaloacetate, and ultimately glucose, is promoted. In this context, acetyl-CoA acts as a metabolic signal indicating that further glucose oxidation is unnecessary, and that glucogenic precursors should be directed toward glucose synthesis and storage.
Conversely, when acetyl-CoA levels are low, pyruvate is preferentially directed toward energy production:
pyruvate kinase and the pyruvate dehydrogenase complex are more active;
the flow of carbon into the citric acid cycle increases;
cellular energy needs are met through oxidative metabolism.[10][20]
In summary, pyruvate carboxylase represents the first major control point of gluconeogenesis, determining whether pyruvate is used for energy production or diverted toward glucose synthesis, based on the energetic status of the cell.[21]
Fructose 1,6-bisphosphatase
The second major control point in gluconeogenesis is the reaction catalyzed by fructose 1,6-bisphosphatase. This enzyme is allosterically inhibited by AMP, meaning that when AMP levels are high, and consequently ATP levels are low, gluconeogenesis slows down. Thus, as previously mentioned, FBPase-1 is active only when the cellular energy charge is sufficiently high to support de novo glucose synthesis.[22]
In contrast, phosphofructokinase-1, the glycolytic counterpart, is allosterically activated by AMP and ADP, and inhibited by ATP and citrate, the latter being a product of acetyl-CoA and oxaloacetate condensation.[23]
Therefore:
when AMP levels are high, glycolysis is favored, and gluconeogenesis is inhibited;
when ATP, acetyl-CoA, or citrate levels are high, gluconeogenesis is promoted, and glycolysis slows down.
The accumulation of citrate, in particular, signals a slowdown in the citric acid cycle and facilitates the diversion of pyruvate toward glucose synthesis.[21][24]
PFK-1, FBPase-1, and fructose 2,6-bisphosphate
The liver plays a central role in maintaining blood glucose homeostasis, requiring tight coordination between glucose consumption and production. Two hormones are primarily responsible for this regulation: insulin and glucagon.[21]
Their intracellular effects are largely mediated through fructose 2,6-bisphosphate (F2,6BP), a potent allosteric activator of PFK-1 and inhibitor of FBPase-1. F2,6BP is structurally similar to fructose 1,6-bisphosphate but is not an intermediate in either glycolysis or gluconeogenesis.[1]
Discovered in 1980 by Emile Van Schaftingen and Henri-Gery Hers, F2,6BP was first identified as a powerful activator of PFK-1. The following year, it was also shown to be a strong inhibitor of FBPase-1.
F2,6BP binds to an allosteric site on PFK-1, reducing its affinity for ATP and citrate (inhibitors) while increasing its affinity for fructose 6-phosphate (its substrate). Without F2,6BP, and under physiological conditions with ATP and citrate present, PFK-1 is nearly inactive. The presence of F2,6BP activates PFK-1 and stimulates glycolysis, while simultaneously inhibiting FBPase-1, even in the absence of AMP. The effects of AMP and F2,6BP on FBPase-1 are synergistic.[25][26]
Regulation of F2,6BP levels
The cellular concentration of F2,6BP is regulated by the balance between its synthesis and degradation.
Synthesis: catalyzed by phosphofructokinase-2 (PFK-2), from fructose 6-phosphate (EC 2.7.1.105).
Degradation: catalyzed by fructose 2,6-bisphosphatase (FBPase-2), converting F2,6BP back to fructose 6-phosphate (EC 3.1.3.46).
These two enzymatic activities reside on a single bifunctional protein, often called the PFK-2/FBPase-2 tandem enzyme. In the liver, the balance of these two functions is hormonally regulated.[27]
Glucagon
After binding to its specific membrane receptors, glucagon stimulates adenylate cyclase (EC 4.6.1.1) to synthesize 3′,5′-cyclic adenosine monophosphate (cAMP). This second messenger activates cAMP-dependent protein kinase, also known as protein kinase A (PKA) (EC 2.7.11.11).
PKA catalyzes the phosphorylation of a specific serine residue (Ser32) on the bifunctional enzyme PFK-2/FBPase-2, using one molecule of ATP. Phosphorylation increases the enzyme’s fructose 2,6-bisphosphatase activity while decreasing its phosphofructokinase-2 activity. This shift is partly due to an increase in the Km for fructose 6-phosphate, which reduces the enzyme’s affinity for its substrate.
As a result, the intracellular concentration of fructose 2,6-bisphosphate decreases. Since this molecule is a potent activator of PFK-1 and inhibitor of FBPase-1, its reduction inhibits glycolysis and stimulates gluconeogenesis. Therefore, in response to glucagon, hepatic glucose production increases, helping the liver counteract the drop in blood glucose levels.[28][29]
Note: like adrenaline, glucagon also promotes gluconeogenesis by increasing the availability of key substrates such as glycerol and amino acids.[30]
Insulin
Insulin has the opposite effect. Upon receptor binding, it activates phosphoprotein phosphatase 2A (PP2A), which dephosphorylates PFK-2/FBPase-2:
this activates PFK-2
and inhibits FBPase-2
Insulin also stimulates cAMP phosphodiesterase, which degrades cAMP into AMP, further reducing PKA activity. The result is an increase in F2,6BP levels, which inhibits gluconeogenesis and stimulates glycolysis.
Additionally:
fructose 6-phosphate allosterically activates PFK-2 and inhibits FBPase-2;
both PFK-2 and FBPase-2 are subject to product inhibition.
However, the main regulatory factors are the level of fructose 6-phosphate and the phosphorylation state of the bifunctional enzyme.[31]
Glucose 6-phosphatase
Unlike pyruvate carboxylase and fructose-1,6-bisphosphatase, the catalytic subunit of glucose 6-phosphatase is not regulated allosterically or through covalent modification. Instead, its activity is modulated at the transcriptional level.[32]
Conditions that promote glucose production, such as low blood glucose, glucagon, and glucocorticoids, stimulate the expression of the enzyme. In contrast, insulin acts as a negative regulator, inhibiting its synthesis.[33]
Additionally, the Km of glucose 6-phosphatase for glucose 6-phosphate is significantly higher than the physiological concentration of the substrate. This means the enzyme’s activity is almost linearly dependent on the substrate concentration, making it effectively regulated by substrate availability rather than by allosteric effectors.[34]
PEP carboxykinase
PEP carboxykinase is expressed in both the cytosol and mitochondria of hepatocytes, encoded by separate nuclear genes. Its expression is tightly regulated, primarily through changes in its synthesis and degradation rates. For example, enzyme levels are low before birth but rise markedly within hours after delivery, coinciding with the activation of gluconeogenesis in the newborn.[35][36]
High levels of glucagon or fasting promote enzyme production by stabilizing its mRNA and enhancing gene transcription. Conversely, elevated blood glucose or insulin suppress transcription, thereby reducing enzyme levels.[34]
Xylulose 5-phosphate
Xylulose 5-phosphate, a product of the pentose phosphate pathway, is a relatively recently identified regulatory molecule. It stimulates glycolysis and inhibits gluconeogenesis by modulating the concentration of fructose 2,6-bisphosphate in the liver.[37]
When blood glucose levels rise, such as after a carbohydrate-rich meal, both glycolysis and the pentose phosphate pathway are activated in hepatocytes. The resulting production of xylulose 5-phosphate activates protein phosphatase 2A. As previously described, PP2A dephosphorylates PFK-2/FBPase-2, thereby inhibiting FBPase-2 and activating PFK-2. This leads to a rise in fructose 2,6-bisphosphate levels, which in turn inhibits gluconeogenesis and stimulates glycolysis. The increased glycolytic flux results in the production of acetyl-CoA, a key precursor for lipid synthesis.[38]
Simultaneously, the enhanced activity of the pentose phosphate pathway produces NADPH, which provides reducing power for fatty acid biosynthesis. Additionally, PP2A dephosphorylates carbohydrate-responsive element-binding protein (ChREBP), a transcription factor that upregulates the expression of hepatic genes involved in lipid synthesis.[39]
Thus, in response to elevated blood glucose levels, xylulose 5-phosphate acts as a crucial regulator, promoting lipid synthesis and coordinating carbohydrate and fat metabolism.[38]
Precursors
Besides the aforementioned pyruvate, the major gluconeogenic precursors are lactate, glycerol, most amino acids, and, more generally, any compound that can be converted into pyruvate or oxaloacetate.[40]
Glycerol
Glycerol is released by lipolysis in adipose tissue. With the exception of propionyl-CoA, it is the only part of the lipid molecule that can be used for glucose synthesis in animals.[5]
Glycerol enters gluconeogenesis, or glycolysis, depending on the cellular energy charge, as dihydroxyacetone phosphate (DHAP). Its synthesis occurs in two steps.
In the first step, glycerol is phosphorylated to glycerol 3-phosphate by the enzyme glycerol kinase (EC 2.7.1.30), with the consumption of one ATP.
Glycerol + ATP → Glycerol 3-phosphate + ADP
This enzyme is absent in adipocytes, but present in the liver. This means that glycerol must reach the liver to be further metabolized.
Glycerol 3-phosphate is then oxidized to DHAP in a reaction catalyzed by glycerol 3-phosphate dehydrogenase (EC 1.1.1.8), during which NAD+ is reduced to NADH.[9]
Glycerol 3-phosphate + NAD+ ⇄ DHAP + NADH + H+
During prolonged fasting, glycerol becomes the major gluconeogenic precursor, accounting for approximately 20% of total glucose production.[41]
Glucogenic amino acids
Pyruvate and oxaloacetate are the entry points for the glucogenic amino acids, that is, those whose carbon skeleton, or part of it, can be used for de novo glucose synthesis.
Amino acids are derived from the catabolism of proteins, whether dietary or endogenous, such as skeletal muscle proteins during fasting or intense, prolonged exercise.
The catabolic pathways of the twenty amino acids that make up proteins converge to form seven major metabolic products:
Among these, only acetyl-CoA and acetoacetyl-CoA cannot be used for gluconeogenesis. Therefore, glucogenic amino acids can be defined as those whose carbon skeleton (or a part of it) can be converted into pyruvate, oxaloacetate, α-ketoglutarate, succinyl-CoA, or fumarate.
Note: only leucine and lysine are exclusively ketogenic, as their carbon skeletons are broken down into acetyl-CoA and/or acetoacetyl-CoA, which cannot serve as gluconeogenic substrates.
Below are the entry points of the gluconeogenic amino acids.
The intermediates α-ketoglutarate, succinyl-CoA, and fumarate, all part of the citric acid cycle, enter the gluconeogenic pathway after conversion to oxaloacetate.[42]
Propionate
Propionate, a short-chain fatty acid, is a gluconeogenic precursor because its active form, propionyl-CoA, can be converted into succinyl-CoA.
It originates from several sources.
β-Oxidation of odd-chain fatty acids, such as margaric acid (C17:0). In the final β-oxidation step, a five-carbon fatty acid is split into acetyl-CoA and propionyl-CoA. These fatty acids, though less common, are found in lipids of marine organisms, ruminants, and some plants.[43]
Oxidation of branched-chain fatty acids, like phytanic acid, derived from phytol, a chlorophyll breakdown product.[44]
In ruminants, microbial fermentation of cellulose-derived glucose in the rumen produces propionate. Once absorbed, it can be used for gluconeogenesis, fatty acid synthesis, or energy production. In these animals, where gluconeogenesis is nearly constant, propionate is the major gluconeogenic precursor.[45]
It also derives from the catabolism of the amino acids valine, isoleucine, methionine, and threonine.[46]
In the colon, fermentation of non-digestible carbohydrates (e.g., resistant starch and fibers) by the gut microbiota produces propionate. After absorption by enterocytes, the portion not metabolized locally reaches the liver via the portal vein.[47]
Conversion of propionyl-CoA to succinyl-CoA involves three reactions:
^ abcdefg Nelson D.L., Cox M.M. Lehninger. Principles of biochemistry. 8th Edition. W.H. Freeman and Company, 2021.
^ abcde Heilman D., Woski S., Voet D., Voet J.G., Pratt C.W. Fundamentals of biochemistry: life at the molecular level. 6th Edition. Wiley, 2023.
^ abcdef Stipanuk M.H., Caudill M.A. Biochemical, physiological, and molecular aspects of human nutrition. 4th Edition. Elsevier health sciences, 2018.
^ abcde Chourpiliadis C., Mohiuddin S.S. Biochemistry, Gluconeogenesis. [Updated 2023 Jun 5]. In: StatPearls [Internet]. Treasure Island (FL): StatPearls Publishing; 2025 Jan-. Available from: https://www.ncbi.nlm.nih.gov/books/NBK544346/
^ ab Gerich J.E. Role of the kidney in normal glucose homeostasis and in the hyperglycaemia of diabetes mellitus: therapeutic implications. Diabet Med 2010;27(2):136-42. doi:10.1111/j.1464-5491.2009.02894.x
^ abc Melkonian E.A., Asuka E., Schury M.P. Physiology, Gluconeogenesis. [Updated 2023 Nov 13]. In: StatPearls [Internet]. Treasure Island (FL): StatPearls Publishing; 2025 Jan-. Available from: https://www.ncbi.nlm.nih.gov/books/NBK541119/
^ Adina-Zada A., Zeczycki T.N., Attwood P.V. Regulation of the structure and activity of pyruvate carboxylase by acetyl CoA. Arch Biochem Biophys 2012;519(2):118-30. doi:10.1016/j.abb.2011.11.015
^ Utter M.F., Keech D.B. Formation of oxaloacetate from pyruvate and carbon dioxide. J Biol Chem 1960;235:PC17-8. doi:10.1016/S0021-9258(18)69442-6
^ Case C.L., Mukhopadhyay B. Kinetic characterization of recombinant human cytosolic phosphoenolpyruvate carboxykinase with and without a His10-tag. Biochim Biophys Acta 2007;1770(11):1576-84. doi:10.1016/j.bbagen.2007.07.012
^ McCommis K.S. and Finck B.N. Mitochondrial pyruvate transport: a historical perspective and future research directions. Biochem J 2015;466(3):443-454. doi:10.1042/BJ20141171
^ Wu G. Amino acids: biochemistry and nutrition. CRC Press, 2010.
^ Holeček M. Roles of malate and aspartate in gluconeogenesis in various physiological and pathological states. Metabolism 2023;145:155614. doi:10.1016/j.metabol.2023.155614
^ abc van Schaftingen E., Gerin I. The glucose-6-phosphatase system. Biochem J 2002;362(Pt 3):513-32. doi:10.1042/0264-6021:3620513
^ Newsholme E.A. Substrate cycles: their metabolic, energetic and thermic consequences in man. Biochem Soc Symp 1978;43:183-205.
^ Patel M.S., Korotchkina L.G. Regulation of the pyruvate dehydrogenase complex. Biochem Soc Trans 2006;34(2):217-22. doi:10.1042/bst0340217
^ Jitrapakdee S., St Maurice M., Rayment I., Cleland W.W., Wallace J.C., Attwood P.V. Structure, mechanism and regulation of pyruvate carboxylase. Biochem J 2008;413(3):369-87. doi:10.1042/BJ20080709
^ abcd Rosenthal M.D., Glew R.H. Medical biochemistry – Human metabolism in health and disease. John Wiley & Sons, Inc., Publication, 2009.
^ Villeret V., Huang S., Zhang Y., Lipscomb W.N. Structural aspects of the allosteric inhibition of fructose-1,6-bisphosphatase by AMP: the binding of both the substrate analogue 2,5-anhydro-D-glucitol 1,6-bisphosphate and catalytic metal ions monitored by X-ray crystallography. Biochemistry 1995;34(13):4307-15. doi:10.1021/bi00013a020
^ Lynch E.M., Hansen H., Salay L., Cooper M., Timr S., Kollman J.M., Webb B.A. Structural basis for allosteric regulation of human phosphofructokinase-1. Nat Commun 2024;15(1):7323. doi:10.1038/s41467-024-51808-6
^ Rui L. Energy metabolism in the liver. Compr Physiol 2014;4(1):177-97. doi:10.1002/cphy.c130024
^ Van Schaftingen E., and Hers H-G. Inhibition of fructose-1,6-bisphosphatase by fructose-2,6-bisphosphate. Proc Natl Acad Sci USA 1981;78(5):2861-2863. doi:https://doi.org/10.1073/pnas.78.5.2861
^ Van Schaftingen E., Jett M-F., Hue L., and Hers H-G. Control of liver 6-phosphofructokinase by fructose 2,6-bisphosphate and other effectors. Proc Natl Acad Sci USA 1981;78(6):3483-3486. doi:https://doi.org/10.1073/pnas.78.6.3483
^ Okar DA., Lange A.J. Fructose-2,6-bisphosphate and control of carbohydrate metabolism in eukaryotes. Biofactors 1999;10(1):1-14. doi:https://doi.org/10.1002/biof.5520100101
^ Payne V.A., Arden C., Wu C., Lange A.J., Agius L. Dual role of phosphofructokinase-2/fructose bisphosphatase-2 in regulating the compartmentation and expression of glucokinase in hepatocytes. Diabetes 2005;54(7):1949-57. doi:https://doi.org/10.2337/diabetes.54.7.1949
^ Winther-Sørensen M., Galsgaard K.D., Santos A., et al. Glucagon acutely regulates hepatic amino acid catabolism and the effect may be disturbed by steatosis. Mol Metab 2020;42:101080. doi:https://doi.org/10.1016/j.molmet.2020.101080
^ Hatting M., Tavares C.D.J., Sharabi K., Rines A.K., Puigserver P. Insulin regulation of gluconeogenesis. Ann N Y Acad Sci 2018;1411(1):21-35. doi:https://doi.org/10.1111/nyas.13435
^ Soty M., Chilloux J., Delalande F., Zitoun C., Bertile F., Mithieux G., and Gautier-Stein A. Post-Translational regulation of the glucose-6-phosphatase complex by cyclic adenosine monophosphate is a crucial determinant of endogenous glucose production and is controlled by the glucose-6-phosphate transporter. J Proteome Res 2016;15(4):1342-1349. doi:https://doi.org/10.1021/acs.jproteome.6b00110
^ Schmoll D., Walker K.S., Alessi D.R., Grempler R., Burchell A., Guo S., Walther R., Unterman T.G. Regulation of glucose-6-phosphatase gene expression by protein kinase Balpha and the forkhead transcription factor FKHR. Evidence for insulin response unit-dependent and -independent effects of insulin on promoter activity. J Biol Chem 2000;275(46):36324-33. doi:https://doi.org/10.1074/jbc.M003616200
^ ab Rodwell V.W., Bender D.A., Botham K.M., Kennelly P.J., Weil P.A. Harper’s Illustrated Biochemistry. 31st Edition. McGraw-Hill, 2018.
^ Yabaluri N., Bashyam M.D. Hormonal regulation of gluconeogenic gene transcription in the liver. J Biosci 2010;35(3):473-84. doi:https://doi.org/10.1007/s12038-010-0052-0
^ Kabashima T., Kawaguchi T., Wadzinski B.E., Uyeda K. Xylulose 5-phosphate mediates glucose-induced lipogenesis by xylulose 5-phosphate-activated protein phosphatase in rat liver. Proc Natl Acad Sci USA 2003;100:5107-5112. doi:https://doi.org/10.1073/pnas.0730817100
^ Iizuka K., Takao K., Yabe D. ChREBP-mediated regulation of lipid metabolism: involvement of the gut microbiota, liver, and adipose tissue. Front Endocrinol (Lausanne) 2020;11:587189. doi:https://doi.org/10.3389/fendo.2020.587189
^ Baba H., Zhang X.J., Wolfe R.R. Glycerol gluconeogenesis in fasting humans. Nutrition 1995;11(2):149-53.
^ Moran L.A., Horton H.R., Scrimgeour K.G., Perry M.D. Principles of Biochemistry. 5th Edition. Pearson, 2012.
^ Ferrannini E., Barrett E.J., Bevilacqua S., DeFronzo R.A. Effect of fatty acids on glucose production and utilization in man. J Clin Invest 1983;72(5):1737-47. doi:https://doi.org/10.1172/JCI111133
^ Verhoeven N.M., Wanders R.J., Poll-The B.T., Saudubray J.M., Jakobs C. The metabolism of phytanic acid and pristanic acid in man: a review. J Inherit Metab Dis 1998;21(7):697-728. doi:https://doi.org/10.1023/a:1005476631419
^ Mann G., Mora S., Madu G., Adegoke O.A.J. Branched-chain amino acids: catabolism in skeletal muscle and implications for muscle and whole-body metabolism. Front Physiol 2021;12:702826. doi:https://doi.org/10.3389/fphys.2021.702826
^ Portincasa P., Bonfrate L., Vacca M., De Angelis M., Farella I., Lanza E., Khalil M., Wang D.Q.-H., Sperandio M., Di Ciaula A. Gut microbiota and short chain fatty acids: implications in glucose homeostasis. Int J Mol Sci 2022;23:1105. doi:https://doi.org/10.3390/ijms23031105
The glucose-alanine cycle, also known as the Cahill cycle, was first described independently by Mallette, Exton, and Park, and by Felig and colleagues between 1969 and 1970. It consists of a series of metabolic steps through which extrahepatic tissues export pyruvate and amino groups to the liver in the form of alanine, while receiving glucose from the liver via the bloodstream.[1][2]
Through this interorgan exchange, the glucose-alanine cycle provides a functional link between carbohydrate and amino acid metabolism, as schematically illustrated below.[3]
Glucose → Pyruvate → Alanine → Pyruvate → Glucose
Although originally described in skeletal muscle, the glucose-alanine cycle is not restricted to muscle–liver interactions, but also involves other extrahepatic tissues, including cells of the immune system.[4]
The glucose-alanine cycle shares functional similarities with the Cori cycle; however, unlike lactate, alanine transports both carbon and nitrogen, thereby directly linking energy metabolism with nitrogen metabolism.[3]
Summary: Key Points
Definition: a metabolic pathway in which extrahepatic tissues (mainly skeletal muscle) export nitrogen and the carbon skeleton of pyruvate, produced by glycolysis, to the liver in the form of alanine.
Physiological roles: transport of nitrogen in a non-toxic form and of the gluconeogenic substrate pyruvate to the liver, thereby shifting the metabolic burden associated with nitrogen disposal and glucose regeneration to the liver.
Energy cost: net energy cost to the liver of approximately 3–5 ATP per cycle, necessary to support gluconeogenesis and the urea cycle.
Comparison with the Cori cycle: unlike the Cori cycle, it requires oxygen and functional mitochondria and involves the transport of both carbon and nitrogen.
The principal steps of the glucose-alanine cycle can be outlined as follows.
When amino acids are oxidized for energy in extrahepatic tissues, pyruvate produced via glycolysis acts as an amino-group acceptor, leading to the formation of alanine, a nonessential amino acid.
Alanine is released into the bloodstream and transported to the liver.
In hepatocytes, the amino group of alanine is transferred to α-ketoglutarate, producing pyruvate and glutamate.
Most of the amino groups derived from glutamate enter the urea cycle, whereas a smaller fraction may serve as nitrogen donors in biosynthetic reactions.
The pyruvate generated in the liver enters gluconeogenesis and is used for glucose synthesis.
Newly synthesized glucose is released into the bloodstream and taken up by peripheral tissues, where it is converted back into pyruvate via glycolysis, thereby completing the cycle.
The Glucose-Alanine Cycle Between Muscle and Liver
Mechanisms and biochemical bases
The following section examines the biochemical basis of the glucose-alanine cycle, with particular emphasis on the metabolic interplay between skeletal muscle and the liver.
Under physiological conditions, both intracellular and extracellular proteins undergo continuous turnover, being hydrolyzed into their constituent amino acids and subsequently resynthesized. The rates of these opposing processes are tightly regulated, thereby preventing the loss of fat-free mass.[5]
Under catabolic conditions, such as prolonged fasting or intense and sustained exercise, muscle protein breakdown exceeds protein synthesis. This imbalance leads to the release of amino acids, some of which are oxidized for energy production, while others are diverted toward gluconeogenesis.[3]
The oxidation of amino acid carbon skeletons, particularly those of branched-chain amino acids (BCAAs) such as leucine, isoleucine, and valine, can represent a significant energy source for skeletal muscle. Depending on their catabolic fate, amino acids are classified as glucogenic or ketogenic, according to whether their carbon skeletons give rise to substrates for gluconeogenesis or ketone body synthesis, respectively.[6] For example, after approximately 90 minutes of strenuous exercise, amino acid oxidation may account for 10–15% of the total energy required for muscle contraction.[7]
The use of amino acid carbon skeletons for energy necessarily involves the removal of their amino groups, followed by the safe excretion of amino nitrogen in a non-toxic form.[8]
Removal of the α-amino group occurs primarily through transamination, which can be summarized by the following reversible reaction:
α-Keto acid + Amino acid ⇌ New amino acid + New α-keto acid
These reactions, catalyzed by enzymes known as aminotransferases or transaminases (EC 2.6.1.-), are freely reversible.[9]
In skeletal muscle, branched-chain amino acids commonly transfer their amino group to α-ketoglutarate (2-oxoglutarate), forming glutamate and the corresponding branched-chain α-keto acids. This reaction is catalyzed by branched-chain aminotransferase (BCAT, EC 2.6.1.42).[10]
Glucose-alanine cycle in skeletal muscle
In skeletal muscle, newly formed glutamate may react with ammonia to form glutamine, which serves as a major vehicle for the interorgan transport of nitrogen, particularly to tissues such as the brain.[11] This reaction is catalyzed by the cytosolic enzyme glutamine synthetase (EC 6.3.1.2) and requires the consumption of one molecule of ATP:
Glutamate + NH4+ + ATP → Glutamine + ADP + Pi
In this case, glutamate exits the Cahill cycle.[9]
Alternatively, and in contrast to what occurs in most other tissues, glutamate may transfer its amino group to pyruvate (derived from glycolysis) to form alanine and α-ketoglutarate. This transamination is catalyzed by alanine aminotransferase (ALT, EC 2.6.1.2), an enzyme widely distributed in both animal and plant tissues:[12]
Glutamate + Pyruvate ⇄ Alanine + α-Ketoglutarate
The alanine thus produced, along with that released directly from muscle protein breakdown (muscle proteins are relatively rich in alanine), can exit the cell and enter the bloodstream, ultimately reaching the liver. In this way, the amino group is efficiently transported to the liver.[13]
Moreover, the rate at which alanine formed by pyruvate transamination enters the circulation is proportional to intracellular pyruvate production.[14]
Note: alanine and glutamine are the major interorgan carriers of nitrogen and carbon derived from amino acid metabolism.[3]
Glucose-alanine cycle in the liver
Once in the liver, hepatic alanine aminotransferase catalyzes a transamination in which alanine, the major gluconeogenic amino acid, acts as an amino group donor, while α-ketoglutarate serves as the α-keto acid acceptor.[15] The products of this reaction are pyruvate (the carbon skeleton of alanine) and glutamate:
Alanine + α-Ketoglutarate ⇄ Glutamate + Pyruvate
In a subsequent reaction catalyzed by glutamate dehydrogenase (EC 1.4.1.2), an enzyme located in the mitochondrial matrix, glutamate is deaminated to produce an ammonium ion (NH4+), which enters the urea cycle, and α-ketoglutarate, which may re-enter the citric acid cycle. This reaction is considered anaplerotic, as it links amino acid metabolism with the citric acid cycle.[16]
Alternatively, glutamate can undergo transamination with oxaloacetate to form aspartate and α-ketoglutarate, in a reaction catalyzed by aspartate aminotransferase (EC 2.6.1.1).[17] Aspartate is not only involved in urea synthesis, but also plays a key role in the biosynthesis of purines and pyrimidines.[18]
The pyruvate generated from alanine may follow two alternative metabolic fates.
It can be oxidized for ATP production, in which case it exits the glucose-alanine cycle.
It can enter the gluconeogenesis pathway, continuing the cycle.[19]
The glucose synthesized in the liver is released into the bloodstream and delivered to peripheral tissues, such as skeletal muscle, where it is converted into pyruvate through glycolysis. This newly formed pyruvate may then accept an amino group from glutamate, thus completing the cycle.[20]
Transaminases
As noted above, the removal of amino groups from amino acids occurs via transamination. These reactions are catalyzed by enzymes known as aminotransferases or transaminases.[12]
Transaminases are cytosolic enzymes present in all cells, but are particularly abundant in the liver, kidney, intestine, and muscle. They require pyridoxal phosphate (PLP), the active form of vitamin B6 (pyridoxine), as a tightly bound coenzyme at their active site.[13]
During transamination, the amino group of most free amino acids (with the exceptions of threonine and lysine) is transferred to one of a small set of keto acids, primarily pyruvate, oxaloacetate, or α-ketoglutarate.[3]
Cells express multiple aminotransferases that share specificity for α-ketoglutarate as the amino-group acceptor but differ in their amino-acid substrates, from which they derive their names. Key examples include:
alanine aminotransferase, also known as alanine transaminase or glutamate-pyruvate transaminase (GPT);
aspartate aminotransferase (AST), also called glutamate-oxaloacetate transaminase (GOT).[9]
Importantly, transamination reactions do not result in net deamination; the amino group simply “swaps” from the amino acid to the keto acid, with no loss of amino groups overall.[12]
Physiological roles
The glucose-alanine cycle serves several important physiological functions.
It transports nitrogen in a non-toxic form from peripheral tissues to the liver in the form of alanine.[8]
It transports pyruvate, a key gluconeogenic substrate, to the liver for glucose synthesis.[8]
It removes pyruvate from peripheral tissues, promoting more efficient ATP production. By reducing cytosolic pyruvate, the NADH generated during glycolysis can be more effectively oxidized via mitochondrial oxidative phosphorylation.[13]
It helps maintain a relatively high concentration of alanine in hepatocytes, which may contribute to the inhibition of hepatic protein degradation.[15]
It may contribute to host defense mechanisms during infectious diseases, although the precise role is still under investigation.[21]
Summary: functions of the glucose-alanine cycle
Function
Description
Nitrogen transport
Safely carries nitrogen from peripheral tissues to the liver in the form of alanine.
Pyruvate transport
Delivers pyruvate (a gluconeogenic substrate) to the liver for glucose production.
ATP optimization
Enhances ATP yield in peripheral tissues by enabling full oxidation of glycolytic NADH via mitochondria.
Protein-sparing effect
Helps maintain high alanine levels in hepatocytes, potentially reducing hepatic protein degradation.
Support in host defense
May contribute to immune response during infections (mechanism under study).
No net glucose gain
The cycle does not result in net glucose synthesis.
Finally, it is important to emphasize that there is no net synthesis of glucose in the glucose-alanine cycle.[3]
Energy cost of the glucose-alanine cycle
Like the Cori cycle, the glucose-alanine cycle incurs an energy cost, estimated at approximately 3–5 ATP per cycle.[22]
The peripheral (extrahepatic) part of the cycle yields energy:
2 ATP are generated through glycolysis.
An additional 3–5 ATP are produced from the oxidation of NADH and FADH2.
In contrast, the hepatic part of the cycle (in the liver) consumes energy:
6 ATP are required for gluconeogenesis per molecule of glucose synthesized;
4 ATP are used in the urea cycle per molecule of urea formed.
Thus, the glucose-alanine cycle, like the Cori cycle, shifts part of the metabolic burden from extrahepatic tissues to the liver. However, the energy cost sustained by the liver is justified by the physiological benefits the cycle provides. It facilitates the breakdown of proteins in extrahepatic tissues, particularly skeletal muscle, under specific conditions (e.g., prolonged exercise or fasting). This, in turn, enables both the utilization of amino acids for energy and the supply of gluconeogenic substrates to the liver.[3]
Similarities with the Cori cycle
There are several similarities between the two cycles, summarized below.
The Cahill cycle partially overlaps with the Cori cycle when pyruvate is converted into glucose in the liver, and the resulting glucose is transported back to extrahepatic tissues, where it is reconverted into pyruvate via glycolysis.[3]
The entry point into the gluconeogenic pathway is similar in both cycles: both alanine and lactate are converted to pyruvate.[9]
Like the Cori cycle, the glucose-alanine cycle occurs between different cell types, unlike metabolic pathways such as glycolysis, the citric acid cycle, or gluconeogenesis, which take place within individual cells.[23]
Comparison Between the Glucose-Alanine and Cori Cycles
Differences from the Cori cycle
Here are some key differences between the two cycles.
The main difference lies in the three-carbon intermediate transported from peripheral tissues to the liver: lactate in the Cori cycle, and alanine in the glucose-alanine cycle.[15]
Another difference involves the fate of NADH produced by glycolysis in peripheral tissues.
In the Cori cycle, NADH is used to reduce pyruvate to lactate via the enzyme lactate dehydrogenase (EC 1.1.1.27).
In the glucose-alanine cycle, this reduction does not occur. Instead, electrons from NADH are transferred into the mitochondria via the malate–aspartate and glycerol-3-phosphate shuttles, generating NADH through the former and FADH2 through the latter. The ATP yields are approximately 2.5 per NADH and 1.5 per FADH2.[23]
As a result, unlike the Cori cycle, the glucose-alanine (Cahill) cycle requires the presence of both oxygen and functional mitochondria in peripheral tissues.[11]
Summary: Cori cycle vs. glucose-alanine cycle
Feature
Cori cycle
Glucose-alanine cycle
Three-carbon compound transported to liver
Lactate
Alanine
Source of 3-carbon compound
Reduction of pyruvate by NADH
Transamination of pyruvate with glutamate
NADH usage in peripheral tissues
Consumed to reduce pyruvate to lactate
Transferred to mitochondria via shuttles
Requirement for oxygen and mitochondria
Not required
Required
Nitrogen transport
None
Transports amino groups (as alanine) to liver
Occurs between different cell types
Yes
Yes
Entry into gluconeogenesis
Lactate → Pyruvate
Alanine → Pyruvate
Energy cost in liver
High (gluconeogenesis)
High (gluconeogenesis + urea cycle)
References
^ Felig P., Pozefsky T., Marlis E., Cahill G.F. Alanine: key role in gluconeogenesis. Science 1970;167(3920):1003-1004. doi:10.1126/science.167.3920.1003
^ Mallette L.E., Exton J.H., and Park C.R. Control of gluconeogenesis from amino acids in the perfused rat liver. J Biol Chem 1969;244(20):5713-5723. doi:10.1016/S0021-9258(18)63618-X
^ abcdefgh Nelson D.L., Cox M.M. Lehninger. Principles of biochemistry. 8th Edition. W.H. Freeman and Company, 2021.
^ Zhao H., Raines L.N., Huang S.C. Carbohydrate and amino acid metabolism as hallmarks for innate immune cell activation and function. Cells 2020;9(3):562. doi:10.3390/cells9030562
^ Lecker S.H., Goldberg A.L. and Mitch W.E. Protein degradation by the ubiquitin–proteasome pathway in normal and disease states. J Am Soc Nephrol 2006;17(7):1807-1819. doi:10.1681/ASN.2006010083
^ Rennie M.J., Tipton K.D. Protein and amino acid metabolism during and after exercise and the effects of nutrition. Annu Rev Nutr 2000;20:457-83. doi:10.1146/annurev.nutr.20.1.457
^ Witard O.C., Hearris M., Morgan P.T. Protein nutrition for endurance athletes: a metabolic focus on promoting recovery and training adaptation. Sports Med 2025;55(6):1361-1376. doi:10.1007/s40279-025-02203-8
^ abc Moran L.A., Horton H.R., Scrimgeour K.G., Perry M.D. Principles of Biochemistry. 5th Edition. Pearson, 2012.
^ abcd Heilman D., Woski S., Voet D., Voet J.G., Pratt C.W. Fundamentals of biochemistry: life at the molecular level. 6th Edition. Wiley, 2023.
^ Nong X., Zhang C., Wang J., Ding P., Ji G., Wu T. The mechanism of branched-chain amino acid transferases in different diseases: research progress and future prospects. Front Oncol 2022;12:988290. doi:10.3389/fonc.2022.988290
^ ab Wu G. Amino acids: biochemistry and nutrition. CRC Press, 2010.
^ abc Berg J.M., Tymoczko J.L., Gatto J.G., Stryer L. Biochemistry. 9th Edition. W.H. Freeman and Company, 2019.
^ Kurmi K., Haigis M.C. Nitrogen metabolism in cancer and immunity. Trends Cell Biol 2020;30(5):408-424. doi:10.1016/j.tcb.2020.02.005
^ Gray L.R., Tompkins S.C., Taylor E.B. Regulation of pyruvate metabolism and human disease. Cell Mol Life Sci 2014;71(14):2577-604. doi:10.1007/s00018-013-1539-2
^ Petersen K.F., Dufour S., Cline G.W., Shulman G.I. Regulation of hepatic mitochondrial oxidation by glucose-alanine cycling during starvation in humans. J Clin Invest 2019;129(11):4671-4675. doi:10.1172/JCI129913
^ Newsholme E.A., Parry-Billings M. Properties of glutamine release from muscle and its importance for the immune system. JPEN J Parenter Enteral Nutr 1990;14(4 Suppl):63S-67S. doi:10.1177/014860719001400406
The Cori cycle was discovered in the 1930s and 1940s by Carl Ferdinand Cori and Gerty Theresa Radnitz, a husband-and-wife research team. They demonstrated the existence of a metabolic cooperation between skeletal muscle, operating under hypoxic conditions, and the liver.[1]
The cycle enables the conversion of lactate, the conjugate base of lactic acid and its predominant form at physiological pH, back into glucose, thereby ensuring a continuous supply of this monosaccharide to peripheral tissues. Its physiological importance is underscored by the fact that it accounts for up approximately 36% of plasma glucose turnover.[2][3]
From a biochemical perspective, the Cori cycle connects gluconeogenesis and anaerobic glycolysis, using different tissues to compartmentalize these opposing metabolic pathways.[4]
This metabolic cooperation also occurs between the liver and other extrahepatic tissues. Indeed, like the glucose-alanine cycle, the Cori cycle is active between the liver and all tissues that do not fully oxidize glucose to CO2 and H2O.[5]
Summary: Key Points
Metabolic cooperation: it connects extrahepatic tissues, primarily hypoxic skeletal muscle and red blood cells, with the liver, ensuring a continuous energy supply to peripheral tissues.
Lactate recycling: it converts lactate, produced via extrahepatic anaerobic glycolysis, back into glucose through hepatic and renal gluconeogenesis.
Energy cost: the cycle cannot run indefinitely as it requires a net consumption of 4 high-energy bonds; specifically, 6 ATP/GTP are spent in the liver to yield only 2 ATP in muscles.
Physiological role: it prevents intracellular lactic acidosis during intense exercise and helps maintain blood glucose levels during fasting and starvation.
The steps of the Cori cycle are typically analyzed by considering the lactate produced by red blood cells and muscle fibers.
The Cori Cycle
The cycle begins with the conversion of glucose to lactate via anaerobic glycolysis, followed by the action of lactate dehydrogenase (LDH; EC 1.1.1.27), which catalyzes the reduction of pyruvate, the conjugate base of pyruvic acid.[6]
Lactate then diffuses out of the cell and into the bloodstream, through which it is transported to the liver, its primary site of utilization, and to the renal cortex, particularly the proximal tubules, another site where gluconeogenesis occurs.[6]
In both the liver and renal cortex, lactate is oxidized back to pyruvate in a reaction also catalyzed by lactate dehydrogenase. Pyruvate is subsequently converted into glucose via the gluconeogenic pathway.[7]
Finally, glucose enters the bloodstream and is delivered to red blood cells and muscle fibers, thereby completing the cycle.[8]
Red blood cells
Mature red blood cells, lacking a nucleus, ribosomes, and mitochondria, are smaller than most other cells. Their small size allows them to pass through narrow capillaries, but the absence of mitochondria makes them completely dependent on anaerobic glycolysis for ATP production. As a result, these cells continuously produce lactic acid.[8]
The availability of NAD+ is essential not only for glycolysis to proceed but also to sustain its rate. The oxidized form of this coenzyme is required for the oxidation of glyceraldehyde 3-phosphate to 1,3-bisphosphoglycerate, a reaction catalyzed by glyceraldehyde 3-phosphate dehydrogenase (EC 1.2.1.12).[3]
The accumulation of NADH is prevented by the reduction of pyruvate to lactate, in a reaction catalyzed by lactate dehydrogenase, in which NADH acts as the reducing agent, being oxidized back to NAD+.[9][10]
Muscle fibers
Fast-twitch muscle fibers contain relatively few mitochondria and, under hypoxic conditions, such as during intense exercise, produce significant amounts of lactic acid.[3] In these conditions:
the rate of pyruvate production via glycolysis exceeds the rate of its oxidation through the citric acid cycle, so that less than 10% of the pyruvate enters the cycle;[7]
the rate of oxygen uptake by the cells is insufficient to support the aerobic oxidation of all the NADH produced.[11]
As a result, anaerobic glycolysis leads to the production of 2 ATP per molecule of glucose (or 3 ATP if the glucose is derived from muscle glycogen), a much lower yield compared to the 29–30 ATP generated through complete oxidation of glucose.[10]
However, the rate of ATP production via anaerobic glycolysis is higher than that of complete aerobic oxidation.[8]
Finally, as in red blood cells, the reaction catalyzed by lactate dehydrogenase, which regenerates NAD+, enables glycolysis to continue, though it results in lactate production.[3]
Lactate
Lactic acid is a metabolic end product that must be converted back into pyruvate in order to be reutilized.[7]
The plasma membrane of most cells is freely permeable to both pyruvate and lactate, allowing them to enter the bloodstream.[12]
In skeletal muscle, for example, the amount of lactate that leaves the cell is greater than that of pyruvate. This is due to the high NADH/NAD+ ratio in the cytosol and the catalytic properties of the lactate dehydrogenase isozyme expressed in muscle fibers.[13]
Once in the bloodstream, lactate reaches, among other tissues, the liver and the renal cortex, where it is oxidized back to pyruvate by tissue-specific LDH isozymes.[14]
In the hepatocyte, this oxidation is favored by the low NADH/NAD+ ratio in the cytosol. The resulting pyruvate then enters gluconeogenesis, the next step in the Cori cycle, and is converted into glucose.[7]
Glucose subsequently enters the bloodstream and is delivered to muscle fibers and red blood cells, thus completing the cycle. Naturally, the monosaccharide also reaches all other tissues and cells that require it.[15]
Energy cost of the Cori cycle
The Cori cycle results in a net consumption of 4 ATP per cycle.
The gluconeogenic phase of the cycle consumes 2 GTP and 4 ATP per molecule of glucose synthesized, totaling 6 high-energy phosphate bonds. >The ATP- (or GTP-) consuming reactions are catalyzed by the following enzymes:
glyceraldehyde 3-phosphate dehydrogenase (EC 1.2.1.12): 1 ATP.
Since two molecules of lactate are needed to synthesize one molecule of glucose, the net energy cost is:
2 x 3 = 6 high energy bonds per molecule of glucose.
In contrast, the glycolytic phase of the cycle yields only 2 ATP per molecule of glucose.
Therefore, more energy is required to convert lactate back into glucose than is gained from the initial anaerobic glycolysis in extrahepatic tissues. This explains why the Cori cycle cannot be sustained indefinitely.[15]
Is the Cori cycle a futile cycle?
The continuous breakdown and resynthesis of glucose, characteristic of the Cori cycle, might initially appear to be a waste of energy. In reality, however, this cycle enables many extrahepatic cells to function effectively, at the energetic expense of the liver and renal cortex.
Therefore, it is more accurate to describe the Cori cycle as a substrate cycle, rather than a futile cycle.[8]
Below are some illustrative examples.
The Cori cycle contributes to the disposal of lactic acid produced continuously by red blood cells.[3]
During intense exercise, anaerobic glycolysis is a major source of ATP for muscle fibers. This process, however, could lead to the accumulation of lactate and a subsequent decrease in intracellular pH.
This accumulation is largely prevented by the Cori cycle, in which gluconeogenic tissues (mainly liver and renal cortex) bear the energy cost of removing excess muscle lactate.[16]
Furthermore, the oxygen debt incurred after intense exercise is largely due to the increased oxygen demand of hepatocytes, where the oxidation of fatty acids, their primary fuel, supplies the ATP needed for gluconeogenesis.[15][17]
In conditions such as trauma, sepsis, burns, or major surgery, intense cell proliferation occurs in the wound (a hypoxic environment) and in the bone marrow. This leads to increased lactic acid production, a greater flux through the Cori cycle, and thus increased ATP consumption by the liver.[18] As previously mentioned, this demand is met by enhanced fatty acid oxidation.
A similar situation seems to occur in cancer patients experiencing progressive weight loss.[19]
The Cori cycle also plays an important role during overnight fasting and starvation, helping maintain blood glucose levels.[5][17]
Similarities with the glucose-alanine cycle
These two metabolic pathways, which operate across different organs via the bloodstream, contribute to maintaining a continuous supply of glucose to peripheral tissues.
In both cycles, entry into gluconeogenesis involves the conversion of alanine or lactate into pyruvate.
Finally, in both cycles, the glucose produced is delivered to peripheral tissues, where it is metabolized via glycolysis, regenerating pyruvate.[15]
Differences from the glucose-alanine cycle
The main difference between the two cycles lies in the three-carbon intermediate that is recycled:
in the Cori cycle, carbon is returned to the liver as pyruvate.
in the glucose-alanine cycle, it is returned as alanine.[20]
Additionally, the metabolic fate of NADH also differs:
in the Cori cycle, NADH acts as a reducing agent in the reaction catalyzed by lactate dehydrogenase;
in the glucose-alanine cycle, the electrons from NADH are used to synthesize ATP in the mitochondria.[15]
As a result, another key difference is that the glucose-alanine cycle requires oxygen, whereas the Cori cycle can function under anaerobic conditions.[3]
Key differences between the Cori cycle and the glucose-alanine cycle.
^ Katz J., Tayek J.A. Gluconeogenesis and the Cori cycle in 12-, 20-, and 40-h-fasted humans. Am J Physiol 1998;275(3):E537-42. doi:10.1152/ajpendo.1998.275.3.E537
^ abcdef Nelson D.L., Cox M.M. Lehninger. Principles of biochemistry. 8th Edition. W.H. Freeman and Company, 2021.
^ ab Rui L. Energy metabolism in the liver. Compr Physiol 2014;4(1):177-97. doi:10.1002/cphy.c130024
^ ab Stipanuk M.H., Caudill M.A. Biochemical, physiological, and molecular aspects of human nutrition. 3rd Edition. Elsevier health sciences, 2012.
^ abcd Berg J.M., Tymoczko J.L., and Stryer L. Biochemistry. 5th Edition. W. H. Freeman and Company, 2002.
^ abcd Rosenthal M.D., Glew R.H. Medical biochemistry – Human metabolism in health and disease. John Wiley J. & Sons, Inc., Publication, 2009.
^ Spinelli S., Marino A., Morabito R., Remigante A. Interplay between metabolic pathways and increased oxidative stress in human red blood cells. Cells 2024;13(23):2026. doi:10.3390/cells13232026
^ Rich P.R. The molecular machinery of Keilin’s respiratory chain. Biochem Soc Trans 2003;31(Pt 6):1095-105. doi:10.1042/bst0311095
^ Halestrap A.P. The monocarboxylate transporter family — Structure and functional characterization. IUBMB Life 2012;64(1):1-9. doi:10.1002/iub.573
^ Gleeson T.T. Post-exercise lactate metabolism: a comparative review of sites, pathways, and regulation. Annu Rev Physiol 1996;58:565-81. doi:10.1146/annurev.ph.58.030196.003025
^ Gladden L.B. Lactate metabolism: a new paradigm for the third millennium. J Physiol 2004;558(Pt 1):5-30. doi:10.1113/jphysiol.2003.058701
^ abcde Voet D. and Voet J.D. Biochemistry. 4th Edition. John Wiley J. & Sons, Inc. 2011.
^ van Hall G. Lactate kinetics in human tissues at rest and during exercise. Acta Physiol (Oxf) 2010;199(4):499-508. doi:10.1111/j.1748-1716.2010.02122.x
^ ab Moran L.A., Horton H.R., Scrimgeour K.G., Perry M.D. Principles of Biochemistry. 5th Edition. Pearson, 2012.
^ Liu S., Yang T., Jiang Q., Zhang L., Shi X., Liu X., Li X. Lactate and lactylation in sepsis: a comprehensive review. J Inflamm Res 2024;17:4405-4417. doi:10.2147/JIR.S459185
^ Li X., Yang Y., Zhang B., Lin X., Fu X., An Y., Zou Y., Wang J.X., Wang Z., Yu T. Lactate metabolism in human health and disease. Signal Transduct Target Ther 2022;7(1):305. doi:10.1038/s41392-022-01151-3
^ Felig P., Pozefsk T., Marlis E., Cahill G.F. Alanine: key role in gluconeogenesis. Science 1970;167(3920):1003-1004. doi:10.1126/science.167.3920.1003
Bile salts have similarities and differences with cholesterol molecule.
Like the steroid, they have a nucleus composed of four fused rings: three cyclohexane rings, labeled A, B and C, and a cyclopentane ring, labeled D. This structure is the perhydrocyclopentanophenanthrene, more commonly known as steroid nucleus.
Bile Acids and Their Conjugates
In higher vertebrates, they have 24 carbon atoms, as the side chain is three carbons shorter than the original. In lower vertebrates, bile acids have 25, 26, or 27 carbon atoms. The side chain ends with a carboxyl group, ionized at pH 7, that can be linked to the amino acid glycine or taurine.
In addition to the hydroxyl group at position 3, they have hydroxyl groups at positions 7 and/or 12.
All this makes them much more polar than cholesterol.
Since A and B rings are fused in cis configuration, the planar structure of the steroid nucleus is curved, and it is possible to identify:
a concave side, which is hydrophilic because the hydroxyl groups and the carboxyl group of the side chain, with or without the linked amino acid, are oriented towards it;
a convex side, which is hydrophobic because the methyl groups present at position 18 and 19 are orientated towards it.
Cholic Acid Structure
Therefore, having both polar and nonpolar groups, they are amphiphilic molecules and excellent surfactants. However, their chemical structure makes them different from many other surfactants, often composed of a polar head region and a nonpolar tail.
Primary, conjugated and secondary bile salts
Primary bile acids are those synthesized directly from cholesterol in the hepatocytes. In humans, the most important are cholic acid and chenodeoxycholic acid, which make up 80 percent of all bile acids.
Before being secreted into the biliary tree, they are almost completely conjugated, up to 98 percent, with the glycine or taurine, to form glycoconjugates and tauroconjugates, respectively. In particular, approximately 75 percent of cholic acid and chenodeoxycholic acid are conjugated with glycine, to form glycocholic acid and glycochenodeoxycholic acid, the remaining 25 percent with taurine, to form taurocholic acid and taurochenodeoxycholic.
Synthesis of Conjugated Bile Acids
Conjugated bile acids are molecules with more hydrophilic groups than unconjugated bile acids, therefore they are much more effective emulsifiers. In fact, conjugation decreases the pKa of bile acids, from about 6, a value typical of non-conjugated molecules, to about 4 for glycocholic acid, and about 2 for taurocholic acid. This makes that conjugated bile acids are ionized in a broader range of pH to form the corresponding salts.
The hydrophilicity of the common acid and bile salts decreases in the following order: glycine-conjugated < taurine-conjugated < lithocholic acid < deoxycholic acid < chenodeoxycholic acid < cholic acid < ursodeoxycholic acid.
Finally, conjugation also decreases the cytotoxicity of primary bile acids.
Secondary bile acids are formed from primary bile acids which have not been reabsorbed from the small intestine. Once they reach the colon, they can undergo several modifications by bacteria of the gut microbiota, which is part of the larger human microbiota, to form secondary bile acids, which, along with short-chain fatty acids, are two major type of bacterial metabolites produced in the gut. They make up the remaining 20 percent of the body’s bile acid pool.
Another way of categorizing bile salts is based on their conjugation with glycine and taurine and their degree of hydroxylation. On this basis, three categories are identified.
Trihydroxy conjugates, such as taurocholic acid and glycocholic acid.
Dihydroxy conjugates, such as glycodeoxycholic acid, glycochenodeoxycholic acid, taurochenodeoxycholic acid, and taurodeoxycholic acid. They account for about 60 percent of bile salts present in the bile.
Unconjugated forms, such as cholic acid, deoxycholic acid, chenodeoxycholic acid, and lithocholic acid.
Function of bile acids
All their physiological functions are performed in the conjugated form.
They are the major route for the elimination of cholesterol from human body.
Indeed, humans do not have the enzymes to break open the cyclohexane rings or the cyclopentane ring of the steroid nucleus, nor to oxidize cholesterol to CO2 and water.
The other mechanism to eliminate the steroid from the body is as cholesterol per se in the bile.
Bile salts are strong surfactants. And in particular, di- and trihydroxy conjugates are the best surfactants among bile acids, much more effective than unconjugated counterparts, since they have more polar groups.
Once in contact with apolar lipids in the lumen of the small intestine, the convex apolar surface interacts with the apolar lipids, such as triglycerides, cholesterol esters, and ester of fat-soluble vitamins, whereas the concave polar surface interacts with the surrounding aqueous medium. This increases the dispersion of apolar lipids in the aqueous medium, as it allows the formation of tiny lipid droplets, increasing the surface area for lipase activity, mainly pancreatic lipase, (bile salts also play a direct role in the activation of this enzyme), andintestinal esterase activity. Subsequently, they facilitate lipid absorption, as well as absorption of fat soluble vitamins by the intestinal mucosa, thanks to the formation of mixed micelles.
Bile acids perform a similar function in the gallbladder where, forming mixed micelles with phospholipids, they prevent the precipitation of cholesterol.
Note: as a consequence of the arrangement of polar and nonpolar groups, bile acids form micelles in aqueous solution, usually made up of less than 10 monomers, as long as their concentration is above the so-called critical micellar concentration or CMC.
At the intestinal level, they modulate the secretion of pancreatic enzymes and cholecystokinin.
In the small and large intestine, they have a potent antimicrobial activity, mainly deoxycholic acid, in particular against Gram-positive bacteria. This activity may be due to oxidative DNA damage, and/or to the damage of the cell membrane. Therefore, they play an important role in the prevention of bacterial overgrowth, but also in the regulation of gut microbiota composition.
In the last few years, it becomes apparent their regulatory role in the control of energy metabolism, and in particular for the hepatic glucose handling.
Enterohepatic circulation
After fat intake, enteroendocrine cells of the duodenum secrete cholecystokinin into the blood stream. Hormone binding to receptors on smooth muscle cells of the gallbladder promotes their contraction; the hormone also causes the relaxation of the sphincter of Oddi. All this results in the secretion of the bile, and therefore of bile acids into the duodenum.
Under physiological conditions, human bile salt pool is constant, and equal to about 3-5 g. This is made possible by two processes:
their intestinal reabsorption;
their de novo synthesis.
Up to 95 percent of the secreted bile salts is reabsorbed from the gut, not together with the products of lipid digestion, but through a process called enterohepatic circulation.
It is an extremely efficient recycling system, which seems to occur at least two times for each meal, and includes the liver, the biliary tree, the small intestine, the colon, and the portal circulation through which reabsorbed molecules return to the liver. Such recirculation is necessary since liver’s capacity to synthesize bile acids is limited and insufficient to satisfy intestinal needs if the bile salts were excreted in the feces in high amounts.
Most of the bile salts are reabsorbed into the distal ileum, the lower part of the small intestine, by a sodium-dependent transporter within the brush border of the enterocytes, called sodium-dependent bile acid transporter or ASBT, which carries out the cotransport of a molecule of bile acid and two sodium ions.
Within the enterocyte, it is thought that bile acids are transported across the cytosol to the basolateral membrane by the ileal bile acid-binding protein or IBABP. They cross the basolateral membrane by the organic solute transporter alpha-beta or OSTalpha/OSTbeta, pass into the portal circulation, and, bound to albumin, reach the liver.
It should be noted that a small percentage of bile acids reach the liver through the hepatic artery.
A hepatic level, their extraction is very efficient, with a first-pass extraction fraction ranging from 50 to 90 percent, a percentage that depends on bile acid structure. The uptake of conjugated bile acids is mainly mediated by a Na+-dependent active transport system, that is, the sodium-dependent taurocholate cotransporting polypeptide or NTCP. However, a sodium-independent uptake can also occur, carried out by proteins of the family of organic anion transporting polypeptides or OATP, mainly OATP1B1 and OATP1B3.
The rate limiting step in the enterohepatic circulation is their canalicular secretion, largely mediated by the bile salt export pump or BSEP, in an ATP-dependent process. This pump carries monoanionic bile salts, which are the most abundant. Bile acids conjugated with glucuronic acid or sulfate, which are dianionic, are transported by different carriers, such as MRP2 and BCRP.
Note: Serum levels of bile acids vary on the basis of the rate of their reabsorption, and therefore they are higher during meals, when the enterohepatic circulation is more active.
Intestinal metabolism
Bile acids which escape ileal absorption pass into the colon where they partly undergo modifications by intestinal microbiota and are converted to secondary bile acids.
The main reactions are listed below.
Deconjugation
On the side chain, hydrolysis of the C24 N-acyl amide bond can occur, with release of unconjugated bile acids and glycine or taurine. This reaction is catalyzed by bacterial hydrolases present both in the small intestine and in the colon.
7alpha-Dehydroxylation
Quantitatively, it is the most important reaction, carried out by colonic bacterial dehydratases that remove the hydroxyl group at position 7 to form 7-deoxy bile acids. In particular, deoxycholic acid is formed from cholic acid, and lithocholic acid, a toxic secondary bile acid, from chenodeoxycholic acid.
It should be noted that 7alpha-dehydroxylation, unlike oxidation and epimerization, can only occur on unconjugated bile acids, and therefore, deconjugation is an essential prerequisite.
Oxidation and epimerization
They are reactions involving the hydroxyl groups at positions 3, 7 and 12, catalyzed by bacterial hydroxysteroid dehydrogenases. For example, ursodeoxycholic acid derives from the epimerization of chenodeoxycholic acid.
Intestinal Metabolism of Bile Acids
Some of the secondary bile acids are then reabsorbed from the colon and return to the liver. In the hepatocytes, they are reconjugated, if necessary, and resecreted. Those that are not reabsorbed, are excreted in the feces.
While oxidations and deconjugations are carried out by a broad spectrum of anaerobic bacteria, 7alpha-dehydroxylations is carried out by a limited number of colonic anaerobes.
7alpha-Dehydroxylations and deconjugations increase the pKa of the bile acids, and therefore their hydrophobicity, allowing a certain degree of passive absorption across the colonic wall.
The increase of hydrophobicity is also associated with an increased toxicity of these molecules. And a high concentration of secondary bile acids in the bile, blood, and feces has been associated to the pathogenesis of colon cancer.
Soluble fibers and reabsorption
The reabsorption of bile salts can be reduced by chelating action of soluble fibers, such as those found in fresh fruits, legumes, oats and oat bran, which bind them, decreasing their uptake. In turn, this increases bile acid de novo synthesis, up-regulating the expression of the 7alpha-hydroxylase and sterol 12alpha-hydroxylase, and thereby reduces hepatocyte cholesterol concentration.
The depletion of hepatic cholesterol increases the expression of the LDL receptor, and thus reduces plasma concentration of LDL cholesterol. On the other hand, it also stimulates the synthesis of HMG-CoA reductase, the key enzyme in cholesterol biosynthesis.
Note: Some anti-cholesterol drugs act by binding bile acids in the intestine, thereby preventing their reabsorption.
Synthesis
Quantitatively, bile acids are the major product of cholesterol metabolism.
As previously said, enterohepatic circulation and their de novo synthesis maintain a constant bile acid pool size. In particular, de novo synthesis allows the replacement of bile salts excreted in the faces, about 5-10 percent of the body pool, namely ~ 0.5 g/day.
Below, the synthesis of cholic acid and chenodeoxycholic acid, and their conjugation with the amino acids taurine and glycine, is described.
There are two main pathways for bile acid synthesis: the classical pathway and the alternative pathway. In addition, some other minor pathways will also be described.
De Novo Synthesis of Primary Bile Acids and Their Conjugates
The classical or neutral pathway
In humans, up to 90 percent of bile salts are produced via the classical pathway, also referred to as “neutral” pathway since intermediates are neutral molecules.
It is a metabolic pathway present only in the liver, that consists of reactions catalyzed by enzymes localized in the cytosol, endoplasmic reticulum, peroxisomes, and mitochondria, and whose end products are the conjugates of cholic acid and chenodeoxycholic acid.
The first reaction is the hydroxylation at position 7 of cholesterol, to form 7alpha-hydroxycholesterol. The reaction is catalyzed by cholesterol 7alpha-hydroxylase or CYP7A1 (E.C. 1.14.14.23). It is an enzyme localized in the endoplasmic reticulum, and catalyzes the rate-limiting step of the pathway.
7alpha-Hydroxycholesterol undergoes oxidation of the 3beta-hydroxyl group and the shift of the double bond from the 5,6 position to the 4,5 position, to form 7alpha-hydroxy-4-cholesten-3-one. The reaction is catalyzed by 3beta-hydroxy-Δ5-C27-steroid oxidoreductase or HSD3B7 (E.C. 1.1.1.181), an enzyme localized in the endoplasmic reticulum.
7alpha-Hydroxy-4-cholesten-3-one can follow two routes:
to enter the pathway that leads to the synthesis of cholic acid, through the reaction catalyzed by 7alpha-hydroxy-4-cholesten-3-one12alpha-monooxygenase or sterol 12alpha-hydroxylase or CYP8B1 (E.C. 1.14.18.8), an enzyme localized in the endoplasmic reticulum;
to enter the pathway that leads the synthesis of chenodeoxycholic acid, through the reaction catalyzed by 3-oxo-Δ4-steroid 5beta-reductase or AKR1D1 (E.C. 1.3.1.3), a cytosolic enzyme.
It should be underlined that the activity of sterol 12alpha-hydroxylase determines the ratio of cholic acid to chenodeoxycholic acid, and, ultimately, the detergent capacity of bile acid pool. And in fact, the regulation of sterol 12alpha-hydroxylase gene transcription is one of the main regulatory step of the classical pathway.
Therefore, if 7alpha-hydroxy-4-cholesten-3-one proceeds via the reaction catalyzed by sterol 12alpha-hydroxylase, the following reactions will occur.
7alpha-Hydroxy-4-cholesten-3-one is hydroxylated at position 12 by sterol 12alpha-hydroxylase, to form 7alpha,12alpha-dihydroxy-4-cholesten-3-one.
7alpha,12alpha-Dihydroxy-4-cholesten-3-one undergoes reduction of the double bond at 4,5 position, in the reaction catalyzed by 3-oxo-Δ4-steroid5beta-reductase, to form 5beta-cholestan-7alpha,12alpha-diol-3-one.
5beta-Cholestan-7alpha,12alpha-diol-3-one undergoes reduction of the hydroxyl group at position 4, in the reaction catalyzed by 3 alpha-hydroxysteroid dehydrogenase or AKR1C4 (EC 1.1.1.213), a cytosolic enzyme, to form 5beta-cholestan-3 alpha,7alpha,12alpha-triol.
5beta-Cholestan-3alpha,7alpha,12alpha-triol undergoes oxidation of the side chain via three reactions catalyzed by sterol 27-hydroxylase or CYP27A1 (EC 1.14.15.15). It is a mitochondrial enzyme also present in extrahepatic tissues and macrophages, which introduces a hydroxyl group at position 27. The hydroxyl group is oxidized to aldehyde, and then to carboxylic acid, to form 3 alpha,7 alpha,12 alpha-trihydroxy-5 beta-cholestanoic acid.
3alpha,7alpha,12alpha-Trihydroxy-5beta-cholestanoic acid is activated to its coenzyme A ester, 3alpha,7alpha,12alpha-trihydroxy-5beta-cholestanoyl-CoA, in the reaction catalyzed by either very long chain acyl-CoA synthetase or VLCS (EC 6.2.1.-), or bile acid CoA synthetase or BACS (EC 6.2.1.7), both localized in the endoplasmic reticulum.
3alpha,7alpha,12alpha-Trihydroxy-5beta-cholestanoyl-CoA is transported to peroxisomes where it undergoes five successive reactions, each catalyzed by a different enzyme. In the last two reactions, the side chain is shortened to four carbon atoms, and finally cholylCoA is formed.
In the last step, the conjugation, via amide bond, of the carboxylic acid group of the side chain with the amino acid glycine or taurine occurs. The reaction is catalyzed by bile acid-CoA:amino acid N-acyltransferase or the BAAT (EC 2.3.1.65), which is predominantly localized in peroxisomes.
The reaction products are thus the conjugated bile acids: glycocholic acid and taurocholic acid.
If 7alpha-hydroxy-4-cholesten-3-one does not proceed via the reaction catalyzed by sterol 12alpha-hydroxylase, it enters the pathway that leads to the synthesis of chenodeoxycholic acid conjugates, through the reactions described below.
7alpha-Hydroxy-4-cholesten-3-one is converted to 7alpha-hydroxy-5beta-cholestan-3-one in the reaction catalyzed by 3-oxo-Δ4-steroid 5 beta-reductase.
7alpha-Hydroxy-5beta-cholestan-3-one is converted to 5beta-cholestan-3alpha,7alpha-diol in the reaction catalyzed by 3alpha-hydroxysteroid dehydrogenase.
Then, the conjugated bile acids glycochenodeoxycholic acid and taurochenodeoxycholic acid are formed by modifications similar to those seen for the conjugation of cholic acid, and catalyzed mostly by the same enzymes.
Note: Unconjugated bile acids formed in the intestine must reach the liver to be reconjugated.
The alternative or acidic pathway
It is prevalent in the fetus and neonate, whereas in adults it leads to the synthesis of less than 10 percent of the bile salts.
This pathway differs from the classical pathway in that:
the intermediate products are acidic molecules, from which the alternative name “acidic pathway”;
the oxidation of the side chain is followed by modifications of the steroid nucleus, and not vice versa;
the final products are conjugates of chenodeoxycholic acid.
The first step involves the conversion of cholesterol into 27-hydroxycholesterol in the reaction catalyzed by sterol 27-hydroxylase.
27-Hydroxycholesterol can follow two routes.
Route A
27-hydroxycholesterol is converted to 3beta-hydroxy-5-cholestenoic acid in a reaction catalyzed by sterol 27-hydroxylase.
3beta-Hydroxy-5-cholestenoic acid is hydroxylated at position 7 in the reaction catalyzed by oxysterol 7alpha-hydroxylase or CYP7B1 (EC 1.14.13.100), an enzyme localized in the endoplasmic reticulum, to form 3beta-7alpha-dihydroxy-5-colestenoic acid.
3beta-7alpha-Dihydroxy-5-cholestenoic acid is converted to 3-oxo-7alpha-hydroxy-4-cholestenoic acid, in the reaction catalyzed by 3beta-hydroxy-Δ5-C27-steroid oxidoreductase.
3-Oxo-7alpha-hydroxy-4-cholestenoic acid, as a result of side chain modifications, forms chenodeoxycholic acid, and then its conjugates.
Route B
27-Hydroxycholesterol is converted to 7alpha,27-dihydroxycholesterol in the reaction catalyzed by oxysterol 7alpha-hydroxylase and cholesterol 7alpha-hydroxylase.
7alpha,27-Dihydroxycholesterol is converted to 7alpha,26-dihydroxy-4-cholesten-3-one in the reaction catalyzed by 3beta-hydroxy-Δ5-C27-steroid oxidoreductase;
7alpha, 26-Dihydroxy-4-cholesten-3-one can be transformed directly to conjugates of chenodeoxycholic acid, or can be converted to 3-oxo-7alpha-hydroxy-4-colestenoic acid, and then undergo side chain modifications and other reactions that lead to the synthesis of the conjugates of chenodeoxycholic acid.
Minor pathways
There are also minor pathways that contribute to bile salt synthesis, although to a lesser extent than classical and alternative pathways.
For example:
A cholesterol 25-hydroxylase (EC 1.14.99.38) is expressed in the liver.
A cholesterol 24-hydroxylase or CYP46A1 (EC 1.14.14.25) is expressed in the brain, and therefore, although the organ cannot export cholesterol, it exports oxysterols.
A nonspecific 7alpha-hydroxylase has also been discovered. It is expressed in all tissues and appears to be involved in the generation of oxysterols, which may be transported to hepatocytes to be converted to chenodeoxycholic acid.
Additionally, sterol 27-hydroxylase is expressed in various tissues, and therefore its reaction products must be transported to the liver to be converted to bile salts.
Bile salts: regulation of synthesis
Regulation of bile acid synthesis occurs via a negative feedback mechanism, particularly on the expression of cholesterol 7alpha-hydroxylase and sterol 12alpha-hydroxylase.
When an excess of bile acids, both free and conjugated, occurs, these molecules bind to the nuclear receptor farnesoid X receptor or FRX, activating it: the most efficacious bile acid is chenodeoxycholic acid, while others, such as ursodeoxycholic acid, do not activate it.
FRX induces the expression of the transcriptional repressor small heterodimer partner or SHP, which in turn interacts with other transcription factors, such as liver receptor homolog-1 or LRH-1, and hepatocyte nuclear factor-4alpha or HNF-4alpha. These transcription factors bind to a sequence in the promoter region of 7alpha-hydroxylase and 12alpha-hydroxylase genes, region called bile acid response elements or BAREs, inhibiting their transcription.
One of the reasons why bile salt synthesis is tightly regulated is because many of their metabolites are toxic.
References
Chiang J.Y.L. Bile acids: regulation of synthesis. J Lipid Res 2009;50(10):1955-1966. doi:10.1194/jlr.R900010-JLR200
Gropper S.S., Smith J.L. Advanced nutrition and human metabolism. 6th Edition. Cengage Learning, 2012
Moghimipour E., Ameri A., and Handali S. Absorption-enhancing effects of bile salts. Molecules 2015;20(8); 14451-14473. doi:10.3390/molecules200814451
Monte M.J., Marin J.J.G., Antelo A., Vazquez-Tato J. Bile acids: Chemistry, physiology, and pathophysiology. World J Gastroenterol 2009;15(7):804-816. doi:10.3748/wjg.15.804
Rosenthal M.D., Glew R.H. Medical biochemistry – Human metabolism in health and disease. John Wiley J. & Sons, Inc., Publication, 2009
Sundaram S.S., Bove K.E., Lovell M.A. and Sokol R.J. Mechanisms of Disease: inborn errors of bile acid synthesis. Nat Clin Pract Gastroenterol Hepatol 2008;5(8):456-468. doi:10.1038/ncpgasthep1179
The human gastrointestinal tract is one of the most highly competitive ecological niches in the human body. It harbors a complex ecosystem composed of viruses, eukaryotes, bacteria, and members of the Archaea, including Methanobrevibacter smithii. This ecosystem, collectively referred to as the gut microbiota, represents a major component of the broader human microbiota.[1][2]
The gut microbiota is characterized by a remarkable taxonomic and functional complexity. It comprises hundreds of microbial species organized into structured communities, shaped by ecological interactions among microorganisms, including bacteria, bacteriophages, and other components of the gut ecosystem. Together, these interactions contribute to both community stability and inter-individual variability.[3][4]
Beyond its compositional features, the gut microbiota is a highly dynamic entity whose structure changes profoundly over time. Microbial communities are established early in life, undergo rapid remodeling during infancy and childhood, and progressively evolve through adulthood and aging. Early-life events, particularly the mode of delivery, play a pivotal role in its initial assembly and may influence immune system development and long-term microbial trajectories.[5][6][7]
After this early developmental phase, additional factors progressively shape gut microbiota composition and function. These include spatial differences along the gastrointestinal tract, driven by variations in pH, oxygen availability, digestive enzymes, and bile salts, as well as external modulators such as diet and geographical location. Together, these pressures contribute to the diversification of microbial communities and to their functional specialization.[8][9][10]
As a result, the gut microbiota emerges as a dynamic, spatially organized, and temporally regulated ecosystem. As a central component of the human microbiota, it plays a fundamental role in host physiology and represents a key link between environmental exposures, host biology, and health and disease.[11]
Bacterial abundance and composition vary along the gastrointestinal tract and are particularly high in the colon.
The adult human colon contains more than 400 bacterial species, belonging to nine major phyla out of the approximately 30 currently recognized. However, metagenomic approaches suggest that the actual diversity is substantially higher.[12]
The most abundant bacterial phyla of the Western adult gut microbiota and their representative genera are summarized in the table below.[13][14]
Major bacterial phyla of the Wester adult gut microbiota
The adult gut harbors a large and diverse community of DNA and RNA viruses, collectively known as the virome, comprising thousands of viral genotypes, none of which is dominant. Indeed, the most abundant virus accounts for only about 6% of the community, whereas in infants the most abundant virus accounts for over 40%.[15][16][17]
The majority of DNA viruses are bacteriophages (or phages), namely viruses that infect bacteria. They are the most abundant biological entities on Earth, with an estimated population of approximately 1031 particles, whereas many RNA viruses detected are plant viruses.[18]
Selective pressure and individual variability
The presence of only a small subset of the bacterial world in the colon is the result of strong selective pressures that have acted during evolution on both microbial colonizers, selecting organisms highly adapted to this environment, and the intestinal niche itself.[3][7] Nevertheless, each individual harbors a unique bacterial community in the gut. This individual specificity coexists with recurrent ecological patterns observed across populations.[19]
Despite the high variability observed both among taxa and between individuals, it has been proposed, although not universally accepted, that in most adults the gut microbiota can be classified into variants, or enterotypes, based on the relative abundance of the genera Bacteroides and Prevotella.[20] This suggests the existence of a limited number of well-balanced symbiotic states, which may respond differently to factors such as intestinal environment, diet, age, genetics, health status, and drug intake.[21]
Gut microbiota composition throughout life
The development of the intestinal microbial ecosystem is a complex and crucial process in human life, and is highly variable among individuals.[6][7]
Development and Life-Course Modifications of the Gut Microbiota
In utero, the gut has traditionally been considered sterile; however, it is rapidly colonized by microbes at birth, as the infant is born with an immunological tolerance shaped by the mother.[22]
Recent studies, however, have reported the presence of bacteria in placental tissue, umbilical cord blood, fetal membranes, and amniotic fluid from healthy newborns without signs of infection or inflammation.[23] For example, the meconium of premature infants born to healthy mothers contains a specific microbiota, with Firmicutes as the main phylum and a predominance of staphylococci. In contrast, Proteobacteria, particularly species such as Escherichia coli, Klebsiella pneumoniae, and Serratia marcescens, as well as enterococci, are more abundant in feces.[24]
It appears that both vaginal and gut bacteria may gain access to the fetus, although through different routes of entry: vaginal bacteria via ascending pathways, and gut bacteria via immune system dendritic cells. Therefore, the existence of a fetal microbiota has been proposed.[6]
Mode of delivery
The first major determinant of postnatal microbial colonization is the mode of delivery.[25] Colonization occurs during delivery through a maternal inoculum, generally composed of aerobic and facultative bacteria, as the newborn gut initially contains oxygen. These are later replaced by obligate anaerobes, which are typically found in adulthood and for which a suitable environment is gradually established.[26]
The maternal vaginal and fecal microbiotas are the primary sources of inoculum in vaginally delivered infants. Accordingly, infants harbor microbial communities dominated by species of the genera Lactobacillus, the most abundant genus in the vaginal microbiota and early gut microbiota, Bifidobacterium, Prevotella, and Sneathia.[27] Anaerobic bacteria, such as members of the phyla Firmicutes and Bacteroidetes, which cannot grow outside the host, likely rely on close mother–infant contact for transmission. Moreover, due to the presence of oxygen in the infant gut, the transmission of strict anaerobes may not occur directly at birth but later, possibly via spores.[28]
In infants born by caesarean section, the first bacteria encountered originate from the skin and hospital environment. Their gut microbiota is dominated by species of the genera Corynebacterium, Staphylococcus, and Propionibacterium, with a lower bacterial load and diversity during the first weeks of life compared with vaginally delivered infants.[29][30]
Further evidence supporting vertical transmission comes from the similarity between meconium microbiota and samples obtained from potential maternal sources. These maternal bacteria do not persist indefinitely and are replaced by other microbial populations within the first year of life.[31]
Objects, animals, the mouths and skin of relatives, as well as breast milk, serve as secondary sources of inoculum. Among these, breast milk appears to play a primary role in determining microbial succession in the gut. Inter-individual variation among children reflects the uniqueness of these microbial exposures.[32]
Mode of delivery and immune system
Mode of delivery also appears to influence immune system development during the first year of life, possibly through its effects on gut microbiota.[33]
Infants born by caesarean section show:
a lower bacterial load in stool samples at one month of age, largely due to reduced bifidobacterial abundance;
a higher number of antibody-secreting cells, potentially reflecting excessive antigen exposure due to increased intestinal permeability.
Together, these findings support the concept that early alterations in microbial colonization associated with caesarean delivery may influence immune maturation during a critical developmental window.[30][34][35]
From birth to first month
Within a few days after birth, a thriving microbial community is established. This community is less stable and more variable than that of adults and soon becomes more numerous than the host’s own cells. Its development follows a highly individual temporal pattern.[5]
During the first month of life, a limited number of taxa, mainly belonging to the phyla Actinobacteria and Proteobacteria, remain relatively stable. In subsequent months, however, there is a marked increase in variability and the emergence of new genetic variants.[6] Numerous studies emphasize that early microbial exposure plays a critical role in shaping the “trajectories” leading to the adult ecosystem. These early communities may also act as sources of either protective or pathogenic microorganisms.[17]
Viruses, absent at birth, reach about 108 particles per gram of wet fecal weight by the end of the first week of life, becoming a dynamic and abundant component of the developing gut ecosystem. Although viral diversity is initially low, the virome is dominated by bacteriophages, which likely influence bacterial abundance and diversity. The origin of these viruses remains unclear, although maternal and environmental sources are plausible.[36] Notably, early viruses may arise from prophage induction within the newborn gut microbiota, as suggested by the observation that over 25% of phage sequences closely resemble those infecting Lactococcus, Lactobacillus, Enterococcus, and Streptococcus, genera abundant in breast milk.[37][38]
From first month to first year
By the end of the first month of life, the initial phase of rapid microbial acquisition is thought to be complete. In 1-month-old infants, the most abundant bacteria belong to the genera Bacteroides and Escherichia. Subsequently, Bifidobacterium, together with Ruminococcus, increases and becomes dominant in the gut of breastfed infants between 1 and 11 months of age.[39][40]
Bifidobacteria, such as Bifidobacterium longum subsp. infantis:
are closely associated with breastfeeding;
are among the best-characterized commensal bacteria;
are considered probiotics, capable of conferring health benefits to the host.[41]
Their abundance also provides protection through competitive exclusion, limiting pathogen colonization. In contrast, Escherichia (e.g., E. coli), Clostridium (e.g., C. difficile), Bacteroides (e.g., B. fragilis), and Lactobacillus are present at higher levels in formula-fed infants than in breastfed infants.[42]
Although breastfed infants receive only breast milk until weaning, their microbiota may exhibit considerable inter-individual variability in both taxonomic abundance and temporal dynamics. These differences may arise from disease, antibiotic exposure, lifestyle changes, stochastic colonization events, and variations in immune responses. However, the relative contribution of each factor remains unclear.[5][43]
The virome also changes rapidly after birth: most viral sequences detected during the first week of life are absent after the second week, and diversity expands markedly during the first three months.[17][44] This contrasts with the adult virome, in which approximately 95% of sequences remain stable over time.[15][45]
From first year to 2.5 years
Under normal conditions, by the end of the first year of life, infants have consumed a diversified, family-type diet for a sufficient period and develop a microbial community resembling that of adults, characterized by:[5]
increased stability and phylogenetic complexity, with greater similarity among individuals;[46]
dominance of Firmicutes and Bacteroidetes, followed by Verrucomicrobia and low levels of Proteobacteria;[47]
increased fecal bacterial load and production of short-chain fatty acids, mainly acetate, propionate, and butyrate;[48]
enrichment of genes involved in xenobiotic degradation, vitamin biosynthesis, and carbohydrate metabolism.[49]
Despite the substantial taxonomic turnover from birth to one year of age, overall functional capacity remains remarkably constant.[50] By this stage, early viral colonizers are also replaced by a child-specific virome.[44]
The gut microbiota reaches full maturity at approximately 2.5 years of age, closely resembling that of adults. This maturation results from several factors:
transition to an adult diet;
greater fitness of adult-associated taxa compared with early colonizers;
developmental changes in the intestinal mucosa;
ecological effects exerted by the microbiota itself.
Consequently, the first 2–3 years of life represent a critical window during which targeted interventions may optimize microbiota development and support healthy growth.[7]
Adulthood
From an initially chaotic state, the gut ecosystem evolves into a relatively stable adult configuration, persisting until old age. This ecosystem includes viral, archaeal, and eukaryotic components and, in Western populations, is dominated by Firmicutes (approximately 60%), followed by Bacteroidetes and Actinobacteria, mainly Bifidobacterium, each representing about 10%, with lower proportions of Proteobacteria and Verrucomicrobia. The genera Bacteroides, Clostridium, Faecalibacterium, Ruminococcus, and Eubacterium, together with Methanobrevibacter smithii, constitute the majority of the adult gut microbiota.[51][52]
Representative composition of the Western adult gut microbiota
Different patterns have been observed in rural African populations.[53] Nevertheless, the gut microbiota is sufficiently conserved across individuals to allow identification of a shared core microbiome.[54]
Stability and resilience are influenced by numerous variables, among which diet appears to be one of the most important. Maintaining microbiota stability therefore requires minimizing disruptive factors and preventing disease, including through vaccination. However, stability may be detrimental if the dominant microbial community is pathogenic.[55][56]
Older age
In elderly individuals, the gut microbiota undergoes significant changes.[57] A study conducted in Ireland on 161 healthy subjects aged 65 years and older showed that, in most individuals, the microbiota differs substantially from that of younger adults. It is dominated by Bacteroidetes and Firmicutes, with nearly inverted proportions compared with younger subjects, although considerable inter-individual variability exists. Faecalibacterium accounts for approximately 6% of dominant genera, followed by Ruminococcus, Roseburia, and Bifidobacterium, the latter representing about 0.4%.[58]
Microbiota variability is also greater in the elderly, possibly due to increased comorbidities, higher medication use, and age-related dietary changes.[51][59]
Gut microbiota and intestinal environment
Due to its low pH, the stomach represents a hostile environment for bacteria, which are present in relatively low numbers, approximately 102–103 bacterial cells per gram of tissue. In addition to Helicobacter pylori, which can cause gastritis and gastric ulcers, microorganisms belonging to the genus Lactobacillus are also detected.[8][60]
Upon reaching the duodenum, bacterial numbers increase to approximately 104−105 cells per gram of tissue, with similar concentrations in the jejunum and proximal ileum.[61] The relatively low microbial load of the small intestine is due to its inhospitable environment, resulting from the opening of the ampulla of Vater in the descending portion of the duodenum, which releases pancreatic juice and bile. Pancreatic enzymes and bile salts exert antimicrobial effects that limit bacterial growth.[10]
In the terminal ileum, where the activity of pancreatic enzymes and bile salts is reduced, bacterial numbers rise to approximately 107 cells per gram of tissue, reaching up to 1012−1014 cells per gram in the colon. As a consequence, bacteria account for a large proportion, about 40%, of fecal mass.[62]
Bacterial distribution along the intestine
The intestinal environment, defined by pH gradients, bile salts, digestive enzymes, oxygen availability, and nutrient distribution, exerts a major selective pressure on the gut microbiota.[63]
The distribution of bacteria along the intestine is strategic. In the duodenum and jejunum, nutrient availability is high, whereas in the terminal ileum and colon only water, fiber, and electrolytes remain. Therefore, high bacterial densities in the distal gut are not problematic.[64] Conversely, elevated bacterial concentrations in the duodenum, jejunum, and proximal ileum are pathological and characterize a condition known as small intestinal bacterial overgrowth (SIBO), in which bacterial numbers increase by one or more orders of magnitude compared with physiological levels. This results in competition with the host for nutrients and leads to gastrointestinal symptoms such as diarrhea.[65]
Gut microbiota and diet
Diet is widely recognized as the most influential factor shaping the composition and metabolic activity of the gut microbiota.[66] Both the quality and the temporal pattern of nutrient intake exert strong selective pressures, affecting microbial diversity from early life through adulthood. Dietary effects can be observed at multiple levels, ranging from initial colonization to long-term enterotype configuration and modulation of the gut virome.[15][55][67]
Role of breast milk
Traditionally considered sterile, human milk harbors a rich microbiota consisting of more than 700 species, dominated by staphylococci, streptococci, bifidobacteria, and lactic acid bacteria.[68] It therefore represents a major source for the colonization of the breastfed infant gut.[32] This mode of colonization has been suggested to be closely correlated with infant health status, as it may protect against infections and contribute to immune system maturation.[69] Breast milk also affects the intestinal microbiota indirectly through the presence of oligosaccharides with prebiotic activity, which stimulate the growth of specific bacterial groups, including bifidobacteria.[70]
Dietary patterns in different populations
A study compared the intestinal microbiota of European and African children, aged between 1 and 6 years, from Florence and a rural village in Burkina Faso, respectively. The study highlighted the dominant role of diet over variables such as climate, geography, hygiene, and health services.[53]
A relative functional convergence has been reported, with no major differences in key immune-related pathways between the two groups. Indeed, as widely reported in the literature, infants, as long as they are breastfed, display a very similar gut microbiota, rich in Actinobacteria, mainly Bifidobacterium.[71]
The subsequent introduction of solid foods, namely, a Western diet rich in animal fats and proteins in European children, and a diet low in animal proteins but rich in complex carbohydrates in African children, leads to a differentiation in the Firmicutes/Bacteroidetes ratio between the two groups. Gram-positive bacteria, mainly Firmicutes, were more abundant in European children, whereas Gram-negative bacteria, mainly Bacteroidetes, prevailed in African children.[72]
Long-term and short-term dietary effects
Long-term dietary patterns are strongly associated with enterotype partitioning. Specifically:
a diet high in animal fats and proteins (a Western-type diet) leads to a gut microbiota dominated by the Bacteroides enterotype;
a diet high in complex carbohydrates, typical of agrarian societies, leads to the prevalence of the Prevotella enterotype.[67]
Similar results emerged from the aforementioned study in children. In European subjects, the gut microbiota was enriched in taxa typical of the Bacteroides enterotype, whereas in children from Burkina Faso the Prevotella enterotype prevails.[72]
Short-term dietary changes (approximately 10 days), particularly macronutrient shifts and fiber-driven interventions, result in rapid alterations of gut microbiota composition, detectable within 24 hours. However, these changes do not lead to stable modifications in enterotype partitioning, indicating that long-term dietary patterns are required to induce sustained enterotype transitions.[73]
Diet and virome
Dietary interventions can also induce changes in the gut virome, leading to a new equilibrium state. These changes involve shifts in the relative proportions of pre-existing viral populations, toward which individuals consuming the same diet tend to converge.[15][16]
Gut microbiota, health status, and disease
The health status of both the infant and the mother represents a major determinant of gut microbiota composition.[50] For example, in mothers affected by inflammatory bowel disease (IBD), a condition characterized by chronic intestinal inflammation, the gut microbiota shows a marked depletion of Faecalibacterium prausnitzii, a butyric acid–producing bacterium with well-established anti-inflammatory properties. This reduction is accompanied by an increased abundance of adherent Escherichia coli, a microbial signature commonly associated with intestinal dysbiosis.[74][75]
Gut microbiota, bacteriocins, and bacteriophages
Bacteriocins are proteins with antibacterial activity, whereas bacteriophages play a key role in controlling the abundance and composition of the gut microbiota. In particular, bacteriophages may influence newborn colonization by infecting dominant bacterial populations, thereby allowing other bacterial strains to become prevalent.[76]
This predator–prey dynamic, known as the kill-the-winner model, suggests that blooms of a specific bacterial species are followed by blooms of their corresponding bacteriophages, leading to a subsequent decline in bacterial abundance. Consequently, the most abundant bacteriophage genotype changes over time. Although some gene sequences in the infant gut virome remain stable during the first three months of life, dramatic shifts in the overall viral community composition occur between the first and second week of life. During this period, the bacterial community is also extremely dynamic.[17][37][77]
Gut microbiota and geographical location
Geographical location has been shown to influence gut microbiota composition from early life. In European infants, for example, Northern infants tend to harbor higher levels of Bifidobacterium species and some Clostridium, whereas Southern infants exhibit higher levels of Bacteroides, Lactobacillus, and Eubacterium.[6][78]
More broadly, cross-population studies indicate that geographical location, together with lifestyle factors such as diet, subsistence patterns, and environmental exposures, contributes substantially to variation in gut microbiota composition and diversity across human populations.[79] These findings suggest that both regional environmental influences and culturally driven dietary habits play a key role in shaping the early-life microbiome.
References
^ Afzaal M., Saeed F., Shah Y.A., et al. Human gut microbiota in health and disease: unveiling the relationship. Front Microbiol 2022;13:999001. doi:10.3389/fmicb.2022.999001
^ Dekaboruah E., Suryavanshi M.V., Chettri D., Verma A.K. Human microbiome: an academic update on human body site specific surveillance and its possible role. Arch Microbiol 2020;202(8):2147-2167. doi:10.1007/s00203-020-01931-x
^ ab Ley R.E., Peterson D.A., and Gordon J.I. Ecological and evolutionary forces shaping microbial diversity in the human intestine. Cell 2006;124(4):837-848. doi:10.1016/j.cell.2006.02.017
^ Hitch T.C.A., Hall L.J., Walsh S.K., Leventhal G.E., Slack E., de Wouters T., Walter J., Clavel T. Microbiome-based interventions to modulate gut ecology and the immune system. Mucosal Immunol 2022;15(6):1095-1113. doi:10.1038/s41385-022-00564-1
^ abcd Palmer C., Bik E.M., DiGiulio D.B., Relman D.A., and Brown P.O. Development of the human infant intestinal microbiota. PLoS Biol 2007;5(7):e177. doi:10.1371/journal.pbio.0050177
^ abcde Rodríguez J.M., Murphy K., Stanton C., et al. The composition of the gut microbiota throughout life, with an emphasis on early life. Microb Ecol Health Dis 2015;26:26050. doi:10.3402/mehd.v26.26050
^ abcd Schoultz I., Claesson M.J., Dominguez-Bello M.G., et al. Gut microbiota development across the lifespan: disease links and health-promoting interventions. J Intern Med 2025;297(6):560-583. doi:10.1111/joim.20089
^ ab Maurer J.M., Schellekens R.C., van Rieke H.M., et al. Gastrointestinal pH and transit time profiling in healthy volunteers using the IntelliCap system confirms ileo-colonic release of ColoPulse tablets. PLoS One 2015;10(7):e0129076. doi:10.1371/journal.pone.0129076
^ Zhang J., Huang Y.J., Yoon J.Y., et al. Primary human colonic mucosal barrier crosstalk with super oxygen-sensitive Faecalibacterium prausnitzii in continuous culture. Med 2021;2(1):74-98.e9. doi:10.1016/j.medj.2020.07.001
^ ab Ma H., Wang K., Jiang C. Microbiota-derived bile acid metabolic enzymes and their impacts on host health. Cell Insight 2025;4(5):100265. doi:10.1016/j.cellin.2025.100265
^ Zeng Q., Feng X., Hu Y., Su S. The human gut microbiota is associated with host lifestyle: a comprehensive narrative review. Front Microbiol 2025;16:1549160. doi:10.3389/fmicb.2025.1549160
^ Qin J., Li R., Raes J., et al. A human gut microbial gene catalogue established by metagenomic sequencing. Nature 2010;464(7285):59-65. doi:10.1038/nature08821
^ Thursby E., Juge N. Introduction to the human gut microbiota. Biochem J 2017;474(11):1823-1836. doi:10.1042/BCJ20160510
^ Almeida A., Nayfach S., Boland M., et al. A unified catalog of 204,938 reference genomes from the human gut microbiome. Nat Biotechnol 2021;39(1):105-114. doi:10.1038/s41587-020-0603-3
^ abcd Minot S., Sinha R., Chen J., Li H., Keilbaugh S.A., Wu G.D., Lewis J.D., and Bushman F.D. The human gut virome: inter-individual variation and dynamic response to diet. Genome Res 2011;21:1616-1625. doi:10.1101/gr.122705.111
^ ab Cao Z., Sugimura N., Burgermeister E., Ebert M.P., Zuo T., Lan P. The gut virome: a new microbiome component in health and disease. EBioMedicine 2022;81:104113. doi:10.1016/j.ebiom.2022.104113
^ abcd Lim E.S., Zhou Y., Zhao G., Bauer I.K., et al. Early life dynamics of the human gut virome and bacterial microbiome in infants. Nat Med 2015;21(10):1228-34. doi:10.1038/nm.3950
^ Batinovic S., Wassef F., Knowler S.A., et al. Bacteriophages in natural and artificial environments. Pathogens 2019;8(3):100. doi:10.3390/pathogens8030100
^ Morgan X.C., Segata N., Huttenhower C. Biodiversity and functional genomics in the human microbiome. Trends Genet 2013;29(1):51-8. doi:10.1016/j.tig.2012.09.005
^ Arumugam M., Raes J., Pelletier E., et al. Enterotypes of the human gut microbiome. Nature 2011;473(7346):174-80. doi:10.1038/nature09944
^ Costea P.I., Hildebrand F., Arumugam M., et al. Enterotypes in the landscape of gut microbial community composition. Nat Microbiol 2018;3(1):8-16. doi:10.1038/s41564-017-0072-8
^ Francino M.P. Early development of the gut microbiota and immune health. Pathogens 2014;3(3):769-90. doi:10.3390/pathogens3030769
^ Gil A., Rueda R., Ozanne S.E., et al. Is there evidence for bacterial transfer via the placenta and any role in the colonization of the infant gut? – a systematic review. Crit Rev Microbiol 2020;46(5):493-507. doi:10.1080/1040841X.2020.1800587
^ Moles L., Gómez M., Heilig H., et al. Bacterial diversity in meconium of preterm neonates and evolution of their fecal microbiota during the first month of life. PLoS One 2013;8(6):e66986. doi:10.1371/journal.pone.0066986
^ Dominguez-Bello M.G., Costello E.K., Contreras M., Magris M., Hidalgo G., Fierer N., and Knight R. Delivery mode shapes the acquisition and structure of the initial microbiota across multiple body habitats in newborns. Proc Natl Acad Sci 2010;107:11971-11975. doi:10.1073/pnas.1002601107
^ Browne H.P., Neville B.A., Forster S.C., Lawley T.D. Transmission of the gut microbiota: spreading of health. Nat Rev Microbiol. 2017;15(9):531-543. doi:10.1038/nrmicro.2017.50
^ Liu T., Kress A.M., Debelius J., et al. Maternal vaginal and fecal microbiota in later pregnancy contribute to child fecal microbiota development in the ECHO cohort. iScience 2025;28(4):112211. doi:10.1016/j.isci.2025.112211
^ Rosenberg E., Zilber-Rosenberg I. Reconstitution and transmission of gut microbiomes and their genes between generations. Microorganisms 2021;10(1):70. doi:10.3390/microorganisms10010070
^ Goedert J.J. Intestinal microbiota and health of adults who were born by cesarean delivery. JAMA Pediatr 2016;170(10):1027. doi:10.1001/jamapediatrics.2016.2310
^ ab Zhang C., Li L., Jin B., Xu X., Zuo X., Li Y., Li Z. The effects of delivery mode on the gut microbiota and health: state of art. Front Microbiol 2021;12:724449. doi:10.3389/fmicb.2021.724449
^ Asnicar F., Manara S., Zolfo M., et al. Studying vertical microbiome transmission from mothers to infants by strain-level metagenomic profiling. mSystems 2017;2(1):e00164-16. doi:10.1128/mSystems.00164-16
^ ab Pannaraj P.S., Li F., Cerini C., et al. Association between breast milk bacterial communities and establishment and development of the infant gut microbiome. JAMA Pediatr 2017;171(7):647-654. doi:10.1001/jamapediatrics.2017.0378
^ Donald K., Finlay B.B. Early-life interactions between the microbiota and immune system: impact on immune system development and atopic disease. Nat Rev Immunol 2023;23(11):735-748. doi:10.1038/s41577-023-00874-w
^ Huurre A., Kalliomäki M., Rautava S., Rinne M., Salminen S., Isolauri E. Mode of delivery-effects on gut microbiota and humoral immunity. Neonatology 2008;93:236-240. doi:10.1159/000111102
^ Lai C., Huang L., Wang Y., Huang C., Luo Y., Qin X., Zeng J. Effect of different delivery modes on intestinal microbiota and immune function of neonates. Sci Rep 2024;14(1):17452. doi:10.1038/s41598-024-68599-x
^ Breitbart M., Haynes M., Kelley S., et al. Viral diversity and dynamics in an infant gut. Res Microbiol 2008;159:367-373. doi:10.1016/j.resmic.2008.04.006
^ ab Mills S., Shanahan F., Stanton C., Hill C., Coffey A., Ross R.P. Movers and shakers: influence of bacteriophages in shaping the mammalian gut microbiota. Gut Microbes 2013;4(1):4-16. doi:10.4161/gmic.22371
^ Redgwell T.A., Thorsen J., Petit M.A., et al. Prophages in the infant gut are pervasively induced and may modulate the functionality of their hosts. NPJ Biofilms Microbiomes 2025;11(1):46. doi:10.1038/s41522-025-00674-1
^ Koenig J.E., Spor A., Scalfone N., Fricker A.D., Stombaugh J., Knight R., Angenent L.T., and Ley R.E. Succession of microbial consortia in the developing infant gut microbiome. Proc Natl Acad Sci 2011;108(1):4578-4585. doi:10.1073/pnas.1000081107
^ Tarracchini C., Milani C., Lugli G.A., Mancabelli L., Turroni F., van Sinderen D., Ventura M. The infant gut microbiota as the cornerstone for future gastrointestinal health. Adv Appl Microbiol 2024;126:93-119. doi:10.1016/bs.aambs.2024.02.001
^ Saturio S., Nogacka A.M., Alvarado-Jasso G.M., Salazar N., de Los Reyes-Gavilán C.G., Gueimonde M., Arboleya S. Role of Bifidobacteria on infant health. Microorganisms 2021;9(12):2415. doi:10.3390/microorganisms9122415
^ Dargenio V.N., Cristofori F., Brindicci V.F., Schettini F., Dargenio C., Castellaneta S.P., Iannone A., Francavilla R. Impact of Bifidobacterium longum Subspecies infantis on pediatric gut health and nutrition: current evidence and future directions. Nutrients 2024;16(20):3510. doi:10.3390/nu16203510
^ Stinson L.F., Norrish I., Mhembere F., Cheema A.S., Mullally C.A., Payne M.S., Geddes D.T. Seeding and feeding: nutrition and birth-associated exposures shape gut microbiome assembly in breastfed infants. Gut Microbes 2025;17(1):2557981. doi:10.1080/19490976.2025.2557981
^ ab Kennedy E.A., Holtz L.R. Gut virome in early life: origins and implications. Curr Opin Virol 2022;55:101233. doi:10.1016/j.coviro.2022.101233
^ Shkoporov A.N., Clooney A.G., Sutton T.D.S., et al. The human gut virome is highly diverse, stable, and individual specific. Cell Host Microbe 2019;26(4):527-541.e5. doi:10.1016/j.chom.2019.09.009
^ Sekirov I., Russell S.L., Antunes L.C., Finlay B.B. Gut microbiota in health and disease. Physiol Rev 2010;90(3):859-904. doi:10.1152/physrev.00045.2009
^ Vallès Y., Artacho A., Pascual-García A., Ferrús M.L., Gosalbes M.J., Abellán J.J., Francino M.P. Microbial succession in the gut: directional trends of taxonomic and functional change in a birth cohort of Spanish infants. PLoS Genet 2014;10(6):e1004406. doi:10.1371/journal.pgen.1004406
^ Fusco W., Lorenzo M.B., Cintoni M., et al. Short-chain fatty-acid-producing bacteria: key components of the human gut microbiota. Nutrients 2023;15(9):2211. doi:10.3390/nu15092211
^ Derrien M., Alvarez A.S., de Vos W.M. The gut microbiota in the first decade of life. Trends Microbiol 2019;27(12):997-1010. doi:10.1016/j.tim.2019.08.001
^ ab Yao Y., Cai X., Ye Y., Wang F., Chen F., Zheng C. The role of microbiota in infant health: from early life to adulthood. Front Immunol 2021;12:708472. doi:10.3389/fimmu.2021.708472
^ ab Hou K., Wu Z.X., Chen X.Y., et al. Microbiota in health and diseases. Signal Transduct Target Ther 2022;7(1):135. doi:10.1038/s41392-022-00974-4
^ Augustynowicz G., Lasocka M., Szyller H.P., Dziedziak M., Mytych A., Braksator J., Pytrus T. The role of gut microbiota in the development and treatment of obesity and overweight: a literature review. J Clin Med 2025;14(14):4933. doi:10.3390/jcm14144933
^ ab De Filippo C., Cavalieri D., Di Paola M., et al. Impact of diet in shaping gut microbiota revealed by a comparative study in children from Europe and rural Africa. Proc Natl Acad Sci 2010;107(33):14691-14696. doi:10.1073/pnas.1005963107
^ Sharon I., Quijada N.M., Pasolli E., et al. The core human microbiome: does it exist and how can we find it? A critical review of the concept. Nutrients 2022;14(14):2872. doi:10.3390/nu14142872
^ ab David L.A., Maurice C.F., Carmody R.N., et al. Diet rapidly and reproducibly alters the human gut microbiome. Nature 2014;505(7484):559-63. doi:10.1038/nature12820
^ Sommer F., Anderson J.M., Bharti R., Raes J., Rosenstiel P. The resilience of the intestinal microbiota influences health and disease. Nat Rev Microbiol 2017;15(10):630-638. doi:10.1038/nrmicro.2017.58
^ Mangiola F., Nicoletti A., Gasbarrini A., Ponziani F.R. Gut microbiota and aging. Eur Rev Med Pharmacol Sci 2018;22(21):7404-7413. doi:10.26355/eurrev_201811_16280
^ Claesson M.J., Cusack S., O’Sullivan O., et al. Composition, variability, and temporal stability of the intestinal microbiota of the elderly. Proc Natl Acad Sci USA 2011;108(Suppl 1);4586-4591. doi:10.1073/pnas.1000097107
^ Salazar N., Valdés-Varela L., González S., Gueimonde M., de Los Reyes-Gavilán C.G. Nutrition and the gut microbiome in the elderly. Gut Microbes. 2017;8(2):82-97. doi:10.1080/19490976.2016.1256525
^ Santacroce L., Topi S., Bottalico L., Charitos I.A., Jirillo E. Current knowledge about gastric microbiota with special emphasis on Helicobacter pylori-related gastric conditions. Curr Issues Mol Biol 2024;46(5):4991-5009. doi:10.3390/cimb46050299
^ Yang K., Li G., Li Q., et al. Distribution of gut microbiota across intestinal segments and their impact on human physiological and pathological processes. Cell Biosci 2025;15(1):47. doi:10.1186/s13578-025-01385-y
^ Portincasa P., Bonfrate L., Khalil M., Angelis M., Calabrese F.M., D’Amato M., Wang D.Q., Di Ciaula A. Intestinal barrier and permeability in health, obesity and NAFLD. Biomedicines 2021;10(1):83. doi:10.3390/biomedicines10010083
^ Kastl A.J. Jr, Terry N.A., Wu G.D., Albenberg L.G. The structure and function of the human small intestinal microbiota: current understanding and future directions. Cell Mol Gastroenterol Hepatol 2020;9(1):33-45. doi:10.1016/j.jcmgh.2019.07.006
^ Donaldson G.P., Lee S.M., Mazmanian S.K. Gut biogeography of the bacterial microbiota. Nat Rev Microbiol 2016;14(1):20-32. doi:10.1038/nrmicro3552
^ Leite G., Morales W., Weitsman S., Celly S, et al. The duodenal microbiome is altered in small intestinal bacterial overgrowth. PLoS One 2020;15(7):e0234906. doi:10.1371/journal.pone.0234906
^ Zhang L., Tuoliken H., Li J., Gao H. Diet, gut microbiota, and health: a review. Food Sci Biotechnol 2024;34(10):2087-2099. doi:10.1007/s10068-024-01759-x
^ ab Wu G.D., Chen J., Hoffmann C., et al. Linking long-term dietary patterns with gut microbial enterotypes. Science 2011;334:105-108. doi:10.1126/science.1208344
^ Consales A., Cerasani J., Sorrentino G., Morniroli D., Colombo L., Mosca F., Giannì M.L. The hidden universe of human milk microbiome: origin, composition, determinants, role, and future perspectives. Eur J Pediatr 2022;181(5):1811-1820. doi:10.1007/s00431-022-04383-1
^ Fernández L., Langa S., Martín V., Maldonado A., Jiménez E., Martín R., Rodríguez J.M. The human milk microbiota: origin and potential roles in health and disease. Pharmacol Res 2013;69(1):1-10. doi:10.1016/j.phrs.2012.09.001
^ Newburg D.S., Morelli L. Human milk and infant intestinal mucosal glycans guide succession of the neonatal intestinal microbiota. Pediatr Res 2015;77:115-120. doi:10.1038/pr.2014.178
^ Donald K., Finlay B.B. Early-life interactions between the microbiota and immune system: impact on immune system development and atopic disease. Nat Rev Immunol 2023;23(11):735-748. doi:10.1038/s41577-023-00874-w
^ ab De Filippo C., Di Paola M., Ramazzotti M., et al. Diet, environments, and gut microbiota. A preliminary investigation in children living in rural and urban Burkina Faso and Italy. Front Microbiol 2017;8:1979. doi:10.3389/fmicb.2017.01979
^ Rodriguez C.I., Isobe K., Martiny J.B.H. Short-term dietary fiber interventions produce consistent gut microbiome responses across studies. mSystems 2024;9(6):e0013324. doi:10.1128/msystems.00133-24
^ Cao Y., Shen J., Ran Z.H. Association between Faecalibacterium prausnitzii reduction and inflammatory bowel disease: a meta-analysis and systematic review of the literature. Gastroenterol Res Pract 2014;2014:872725. doi:10.1155/2014/872725
^ Lavelle A., Sokol H. Gut microbiota-derived metabolites as key actors in inflammatory bowel disease. Nat Rev Gastroenterol Hepatol 2020;17(4):223-237. doi:10.1038/s41575-019-0258-z
^ Emencheta S.C., Olovo C.V., Eze O.C., et al. The role of bacteriophages in the gut microbiota: implications for human health. Pharmaceutics 2023;15(10):2416. doi:10.3390/pharmaceutics15102416
^ Mills S., Ross R.P., Hill C. Bacteriocins and bacteriophage; a narrow-minded approach to food and gut microbiology. FEMS Microbiol Rev 2017;41(1):S129-S153. doi:10.1093/femsre/fux022
^ Fallani M., Young D., Scott J., et al. Intestinal microbiota of 6-week-old infants across Europe: geographic influence beyond delivery mode, breast-feeding, and antibiotics. J Pediatr Gastroenterol Nutr 2010;51(1):77-84. doi:10.1097/MPG.0b013e3181d1b11e
^ Gupta V.K., Paul S., Dutta C. Geography, ethnicity or subsistence-specific variations in human microbiome composition and diversity. Front Microbiol 2017;8:1162. doi:10.3389/fmicb.2017.01162
It has been known for almost a century that humans harbor a microbial ecosystem, known as human microbiota, remarkably dense and diverse, made up of a number of viruses and cells much higher than those of the human body, and that accounts for one to three percent of body weight.
All the genes encoded by the human body’s microbial ecosystem, which are about 1,000 times more numerous than those of our genome, make up the human microbiome.
Microorganisms colonize all the surfaces of the body that are exposed to the environment. Indeed, distinct microbial communities are found on the skin, in the vagina, in the respiratory tract, and along the whole intestinal tract, from the mouth up to rectum, the last part of the intestine.
The human microbiota consists of organisms from all taxa, namely, bacteria, viruses, archaea, and eukaryotes.
Bacteria
Bacteria are at least 100 trillion (1014) cells, a number ten times greater than that of the human body.
They are found in very high concentration in the intestinal tract, up to 1012-1014/gram of tissue, where they form one of the most densely populated microbial habitats on Earth. In the gut, bacteria mainly belong to the Firmicutes, Bacteroidetes and Actinobacteria phyla. Fusobacteria (oropharynx), Tenericutes, Proteobacteria, and Verrucomicrobia are other phyla present in our body.
Note: Bacterial communities in a given body region resemble themselves much more across individuals than those from different body regions of the same individual; for example, bacterial communities of the upper respiratory tract are much more similar across individuals than those of the skin or intestine of the same individual.
Viruses
They are by far the most numerous organisms, being present with quadrillion units. The genomes of all the viruses harbored in the human body make up the human virome.
In the past, viruses and eukaryotes have been studied focusing on pathogenic microorganisms, but in recent years the attention has also shifted on many non-pathogenic members of these groups. And many of the viral gene sequences found are new, which suggests that there is still much to learn about the human virome.
Finally, just like for bacteria, there is considerable interpersonal variability.
Archaebacteria
Archaebacteria or Archaea are mainly those belonging to the order Methanobacteriales. Among the latter, Methanobrevibacter smithii is predominant in the human gut, representing up to 10 percent of all anaerobes.
Eukaryotes
Eukaryotes are also present, and the parasites of the genera Giardia and Entamoeba have probably been among the first to be identified. But there is also a great abundance and diversity of fungal species, belonging to genera such as Candida, Penicillium, Aspergillus, Hemispora, Fusarium, Geotrichum, Hormodendrum, Cryptococcus, Saccharomyces, and Blastocystis.
Candida albicans
Function of the human microbiota
Sometimes referred to as “the forgotten organ”, human microbiota, mainly with its intestinal bacterial members, plays many important functions that can lead to nutritional, immunological, and developmental benefits, but can also cause diseases. Here are some examples.
It is involved in the development of the gastrointestinal system of the newborn, as shown by experiments carried out on germ-free animals in which, for example, the thickness of the intestinal mucosa is thinner than that of colonized animals, therefore more easily subject to rupture.
It contributes to energy harvest from nutrients, due to its ability to ferment indigestible carbohydrates, promote the absorption of monosaccharides and the storage of the derived energy. This has probably been a very strong evolutionary force that has played a major role in favor of the fact that these bacteria became our symbionts.
It contributes to the maintenance of the acidic pH of the skin and in the colon.
It is involved in the metabolism of xenobiotics and several polyphenols.
It improves water and mineral absorption in the colon.
It increases the speed of intestinal transit, slower in germ-free animals.
It has an important role in resistance to colonization by pathogens, primarily in the vagina and gut.
It is involved in the biosynthesis of isoprenoids and vitamins through the methylerythritol phosphate pathway.
It stimulates angiogenesis.
In the intestinal tract, it interacts with the immune system, providing signals for promoting the maturation of immune cells and the normal development of immune functions. And this is perhaps the most important effect of the symbiosis between the human host and microorganisms. Experiments carried out on germ-free animals have shown, for example, that:
macrophages, the cells that engulf pathogens and then present their antigens to the immune system, are found in much smaller amounts than those present in the colonized intestine, and if placed in the presence of bacteria they fail to find and therefore engulf them, unlike macrophages extracted from a colonized intestine;
there is not the chronic non-specific inflammation, present in the normal intestine as a result of the presence of bacteria (and of what we eat).
Changes in its composition can contribute to the development of obesity and metabolic syndrome.
It protects against the development of type I diabetes.
Many diseases, both in children and adults, such as stomach cancer, lymphoma of mucosa-associated lymphoid tissue, necrotizing enterocolitis, an important cause of morbidity and mortality in premature babies, or chronic intestinal diseases, are, and others seem to be, related to the gut microbiota.
In conclusion, it seems very likely that the human body represents a superorganism, result of years of evolution and made up of human cells, and the resulting metabolic and physiological capacities, as well as an additional organ, the microbiota.
Commensals and pathogens
Based on the relationships with the human host, microorganisms may be classified as commensals or pathogens.
Commensals cause no harm to the host, with which they establish a symbiotic relationship that generally brings benefits to both.
On the contrary, pathogens are able to cause diseases, but fortunately represent a small percentage of the human microbiota.
These microorganisms establish a symbiosis with the human host and benefit from it at the expense of the host. They can cause disease:
if they move from their niche, such as the intestine, into another one where they do not usually reside, such as the vagina or bladder, as in the case of Candida albicans, normally present in the intestine, but in very small quantities;
in patients with impaired immunological defenses, such as after an immunosuppressive therapy.
Human Microbiome Project
The bacterial component of the human microbiota is the subject of most studies including a large-scale project started in 2008 called “Human Microbiome Project”, whose aim is to characterize the microbiome associated with multiple body sites, such as the skin, mouth, nose, vagina and intestine, in 242 healthy adults.
These studies have shown a great variability in the composition of the human microbiota. For example, twins share less than 50 percent of their bacterial taxa at the species level, and an even smaller percentage of viruses.
The factors that shape the composition of bacterial communities begin to be understood: for example, the genetic characteristics of the host play an important, although this is not true for the viral community. And metagenomic studies have shown that, despite the great interpersonal variability in microbial community composition, there is a core of shared genes encoding signaling and metabolic pathways. It appears namely that the assembly and the structure of the microbial community does not occur according to the species but the more functional set of genes.
Therefore, disease states of these communities might be better identified by atypical distribution of functional classes of genes.
Effect of antibiotics
The microbiota in healthy adult humans is generally stable over time. However, its composition can be altered by factors such as dietary changes, urbanization, travel, and especially the use of broad-spectrum antibiotics. Here are some examples of the effect of antibiotic treatments.
There is a long-term reduction in microbial diversity.
The taxa affected vary from individual to individual, even up to a third of the taxa.
Several taxa do not recover even after 6 months from treatment.
Once the bacterial communities have reshaped, a reduced resistance to colonization occurs. This allows foreign and/or pathogen bacteria, able to grow more than the commensals, to cause permanent changes in human microbiota structure, as well as acute diseases, such as the dangerous pseudomembranous colitis, and chronic diseases, as it is suspected for asthma following the use and abuse of antibiotics in childhood. Moreover, their repeated use has been suggested to increase the pool of antibiotic-resistance genes in our microbiome. In support of this hypothesis, a decrease in the number of antibiotic-resistant pathogens has been observed in some European countries following the reduction in the number of antibiotics prescribed.
Finally, you must not underestimate the fact that the intestinal microflora is involved in many chemical transformations, and its alteration could be implicated in the development of cancer and obesity. However, regarding use of antibiotics, you should be underlined that if western population has a life expectancy higher than in the past is also because you do not die of infectious diseases!
References
Burke C., Steinberg P., Rusch D., Kjelleberg S., and Thomas T. Bacterial community assembly based on functional genes rather than species. Proc Natl Acad Sci USA 2011;108:14288-14293. doi:10.1073/pnas.1101591108
Clemente J.C., Ursell L.K., Wegener Parfrey L., and Knight R. The impact of the gut microbiota on human health: an integrative view. Cell 2012;148:1258-1270. doi:10.1016/j.cell.2012.01.035
Gill S.R., Pop M., Deboy R.T., Eckburg P.B., Turnbaugh P.J., Samuel B.S., Gordon J.I., Relman D.A., Fraser-Liggett C.M., and Nelson K.E. Metagenomic analysis of the human distal gut microbiome. Science 2006;312:1355-1359. doi:10.1126/science.1124234
Palmer C., Bik E.M., DiGiulio D.B., Relman D.A., and Brown P.O. Development of the human infant intestinal microbiota. PLoS Biol 2007;5(7):e177. doi:10.1371/journal.pbio.0050177
Turnbaugh P.J., Gordon J.I. The core gut microbiome, energy balance and obesity. J Physiol 2009;587:4153-4158. doi:10.1113/jphysiol.2009.174136
Zhang, T., Breitbart, M., Lee, W., Run, J.-Q., Wei, C., Soh, S., Hibberd, M., Liu, E., Rohwer, F., Ruan, Y. Prevalence of plant viruses in the RNA viral community of human feces. PLoS Biol 2006;4(1):e3. doi:10.1371/journal.pbio.0040003
Flavonoid biosynthesis, probably the best characterized pathway of plant secondary metabolism, is part of the phenylpropanoid pathway that, in addition to flavonoids, leads to the formation of a wide range of phenolic compounds, such as hydroxycinnamic acids, stilbenes, lignans and lignins.
Flavonoid biosynthesis is linked to primary metabolism through both mitochondria- and plastid-derived molecules. Since it seems that most of the involved enzymes characterized to date operate in protein complexes located in the cell cytosol, these molecules must be exported to the cytoplasm to be used.
The end products are transported to different intracellular or extracellular locations, with flavonoids involved in pigmentation usually transported into the vacuoles.
The biosynthesis of this group of polyphenols requires one p-coumaroyl-CoA and three malonyl-CoA molecules as initial substrates.
p-Coumaroyl-CoA is the pivotal branch-point metabolite in the phenylpropanoid pathway, being the precursor of a wide variety of phenolic compounds, both flavonoid and non-flavonoid polyphenols.
It is produced from phenylalanine via three reactions catalyzed by cytosolic enzymes collectively called group I or early-acting enzymes, in order of action:
phenylalanine ammonia lyase (EC 4.3.1.24);
trans-cinnamate 4-monooxygenase (EC:1.14.14.91);
4-coumarate-CoA ligase (EC 6.2.1.12).
Biosynthesis of p-coumaroyl-CoA
They seems to be associated in a multienzyme complex anchored to the endoplasmic reticulum membrane. The anchoring is probably ensured by cinnamate 4-hydroxylase that inserts its N-terminal domain into the membrane of the endoplasmic reticulum itself. These complexes, referred to as “metabolons”, allow the product of a reaction to be channeled directly as substrate to the active site of the enzyme that catalyzes the consecutive reaction in the metabolic pathway.
With the exception of cinnamate 4-hydroxylase, the enzymes which act downstream of phenylalanine ammonia lyase are encoded by small gene families in all species analyzed so far.
The different isoenzymes show distinct temporal, tissue, and elicitor-induced patterns of expression. It seems, in fact, that each member of each family can be used mainly for the synthesis of a specific compound, thus acting as a control point for carbon flux among the metabolic pathways leading to lignan, lignin, and flavonoid biosynthesis.
Note: Phenylalanine is a product of the shikimic acid pathway, which converts simple precursors derived from the metabolism of carbohydrates, phosphoenolpyruvate and erythrose-4-phosphate, intermediates of glycolysis and the pentose phosphate pathway, respectively, into the aromatic amino acids phenylalanine, tyrosine and tryptophan. Unlike plants and microorganisms, animals do not possess the shikimic acid pathway, and are not able to synthesize the three above-mentioned amino acids, which are therefore essential nutrients.
Phenylalanine ammonia lyase (PAL)
It is one of the most studied and best characterized enzymes of plant secondary metabolism. It requires no cofactors and catalyzes the reaction that links primary and secondary metabolism: the reversible deamination of phenylalanine to trans-cinnamic acid, with the release of nitrogen as ammonia and introduction of a trans double bond between carbon atoms 7 and 8 of the side chain.
Phenylalanine ⇄ trans-Cinnamic Acid + NH3
Therefore, it directs the flow of carbon from the shikimic acid pathway to the different branches of the phenylpropanoid pathway. The released ammonia is probably fixed in the reaction catalyzed by glutamine synthetase.
The enzyme from monocots is also able to act as tyrosine ammonia lyase (EC 4.3.1.25), converting tyrosine to p-coumaric acid directly, (therefore without the 4-hydroxylation step), but with a lower efficiency.
In all plant species investigated, several copies of phenylalanine ammonia lyase gene are found, copies that probably respond differentially to internal and external stimuli. Indeed, gene transcription, and then enzyme activity, are under the control of both internal developmental and external environmental stimuli.
Here are some examples that require increased enzyme activity.
The flowering.
The production of lignin to strengthen the secondary wall of xylem cells.
The production of flower pigments that attract pollinators.
Pathogen infections, that require the production of phenylpropanoid phytoalexins, or exposure to UV rays.
trans-Cinnamate 4-monooxygenase
It belongs to the cytochrome P450 superfamily (EC 1.14.-.-), is a microsomal monooxygenase containing a heme cofactor, and dependent on both O2 and NADPH.
It catalyzes the formation of p-coumaric acid through the introduction of a hydroxyl group in 4-position of trans-cinnamic acid (this hydroxyl group is present in most flavonoids).
This reaction is also part of the biosynthesis of hydroxycinnamic acids.
Increases in transcription rates and enzyme activity are observed in correlation with the synthesis of phytoalexins (in response to fungal infections), lignification as well as wounding.
4-Coumarate:CoA ligase (4CL)
With Mg2+ as a cofactor, it catalyzes the ATP-dependent activation of the carboxyl group of p-coumaric acid and other hydroxycinnamic acids, metabolically rather inert molecules, through the formation of the corresponding CoA-thioester.
p-Coumaric Acid + ATP + CoA ⇄ p-Coumaroyl-CoA + AMP + PPi
Generally, p-coumaric acid and caffeic acid are the preferred substrates, followed by ferulic acid and 5-hydroxyferulic acid, low activity against trans-cinnamic acid and none against sinapic acid. These CoA-thioesters are able to enter various reactions such as:
reduction to alcohol (monolignols) or aldehydes;
stilbene and flavonoid biosynthesis;
transfer to acceptor molecules.
It should finally be pointed out that the activation of the carboxyl group can also be obtained through an UDP-glucose-dependent transfer to glucose.
Biosynthesis of malonyl-CoA
Malonyl-CoA does not derived from the phenylpropanoid pathway, but from the reaction catalyzed by acetyl-CoA carboxylase (EC 6.4.1.2, the cytosolic form, see below).
The enzyme, with biotin and Mg2+ as cofactors, catalyzes the ATP-dependent carboxylation of acetyl-CoA, using bicarbonate as a source of carbon dioxide (CO2).
Acetyl-CoA + HCO3– + ATP → Malonyl-CoA + ADP + Pi
It is found both in the plastids, where it participates in the synthesis of fatty acids, and the cytoplasm, and is the latter that catalyzes the formation of malonyl-CoA that is used in the biosynthesis of flavonoids and other compounds.
Increases in the transcription rate of the gene and enzyme activity are induced in response to stimuli that increase the biosynthesis of these polyphenols, such as exposure to pathogenic fungi or UV-rays.
In turn, acetyl-CoA is produced in plastids, mitochondria, peroxisomes and cytosol through different metabolic pathways. The molecules used in the biosynthesis of malonyl-CoA, and therefore of the flavonoids, are the cytosolic ones, produced in the reaction catalyzed by ATP-citrate lyase (EC 2.3.3.8) that cleaves citrate, in the presence of CoA and ATP, to form oxaloacetate and acetyl-CoA, plus ADP and inorganic phosphate.
First steps in flavonoid biosynthesis
The first step in flavonoid biosynthesis is catalyzed by chalcone synthase (EC 2.3.1.74), an enzyme anchored to the endoplasmic reticulum and with no known cofactors.
From one p-coumaroyl-CoA and three malonyl-CoA, it catalyzes sequential condensation and decarboxylation reactions in the course of which a polyketide intermediate is formed. The polyketide undergoes cyclizations and aromatizations leading to the formation of the A ring. The product of the reactions is naringenin chalcone (2′,4,4′,6′-tetrahydroxychalcone), a 6′-hydroxychalcone and the first flavonoid to be synthesized by plants.
p-Coumaroyl-CoA + 3 Malonyl-CoA → Naringenin Chalcone + 4 CoA + 3 CO2
The reaction, cytosolic, is irreversible due to the release of three CO2 and 4 CoA.
B ring and the three-carbon bridge of the molecule originate from p-coumaroyl-CoA (and therefore from phenylalanine), the A ring from the three malonyl-CoA units.
The Origin of the Flavonoid Skeleton
Also 6’-deoxychalcone can be produced; its synthesis is thought to involve an additional reduction step catalyzed by polyketide reductase (EC. 1.1.1.-).
Chalcone synthase from some plant species, such as barley (Hordeum vulgare), accepts as substrates also caffeoil-CoA, feruloil-CoA and cinnamoyl-CoA. It is the most abundant enzyme of the phenylpropanoid pathway, probably because it has a low catalytic activity, and, in fact, is considered to be the rate-limiting enzyme in flavonoid biosynthesis.
As for phenylalanine ammonia lyase, chalcone synthase gene expression is under the control of both internal and external factors. In some plants, one or two isoenzymes are found, while in others up to 9.
Chalcone synthase belongs to polyketide synthase group, present in bacteria, fungi and plants. These enzymes are able to catalyze the production of polyketide chains through sequential condensations of acetate units provided by malonyl-CoA units. They also includes stilbene synthase (EC 2.3.1.146), which catalyzes the formation of resveratrol, a non flavonoid polyphenol compound that has attracted much interest because of its potential health benefits.
Generally, chalcones do not accumulate in plants because naringenin chalcone is converted to (2S)-naringenin, a flavanone, in the reaction catalyzed by chalcone isomerase (EC 5.5.1.6).
The enzyme, the first of the flavonoid biosynthesis to be discovered, catalyzes a stereospecific isomerization and closes the C ring. Two types of chalcone isomerases are known, called type I and II. Type I enzymes use only 6′-hydroxychalcone substrates, like naringenin chalcone, while type II, prevalent in legumes, use both 6′-hydroxy- and 6′-deoxychalcone substrates.
It should be noted that with 6′-hydroxychalcones, isomerization can also occur nonenzymically to form a racemic mixture, both in vitro and in vivo, enough to allow a moderate synthesis of anthocyanins. On the contrary, under physiological conditions 6′-deoxychalcones are stable, and so the activity of type II chalcone isomerases is required to form flavanones.
The enzyme increases the rate of the reaction of 107 fold compared to the spontaneous reaction, but with a higher kinetics for the 6′-hydroxychalcones than 6′-deoxychalcones. Finally, it produces (2S)-flavanones, which are the biosynthetically required enantiomers.
As other enzymes in flavonoid biosynthesis, also chalcone isomerase gene expression is subject to strict control. And, as phenylalanine ammonia lyase and chalcone synthase, it is induced by elicitors.
In the reaction catalysed by flavanone-3β-hydroxylase (EC 1.14.11.9), (2S)-flavanones undergo a stereospecific isomerization that converts them into the respective (2R,3R)-dihydroflavonols. In particular, naringenin is converted into dihydrokaempferol.
The enzyme is a cytosolic non-heme-dependent dioxygenase, dependent on Fe2+ and 2-oxoglutarate, and therefore belonging to the family of 2-oxoglutarate-dependent dioxygenase (which distinguishes them from the other hydroxylases of the flavonoid biosynthetic pathway which are cytochrome P450 enzymes).
Naringenin chalcone, (2S)-naringenin, and dihydrokaempferol are central intermediates in flavonoid biosynthesis, since they act as branch-point compounds from which the synthesis of distinct flavonoid subclasses can occur. For example, directly or indirectly:
Not all of these side metabolic pathways are present in every plant species, or are active within each tissue type of a given plant.
Like enzymes previously seen, the activity of those involved in these “side-routes” is subject to strict control, resulting in a tissue-specific profile of flavonoid compounds. For example, grape seeds, flesh and skin have distinct anthocyanin, catechin, flavonol and condensed tannin profiles, whose synthesis and accumulation are strictly and temporally coordinated during the ripening process.
References
Andersen Ø.M., Markham K.R. Flavonoids: chemistry, biochemistry, and applications. CRC Press Taylor & Francis Group, 2006
de la Rosa L.A., Alvarez-Parrilla E., Gonzàlez-Aguilar G.A. Fruit and vegetable phytochemicals: chemistry, nutritional value, and stability. 1th Edition. Wiley J. & Sons, Inc., Publication, 2010
They are widely distributed in the plant kingdom, being present in more than 55 plant families, where they act as antioxidants and defense molecules against pathogenic fungi and bacteria.
In humans, epidemiological and physiological studies have shown that they can exert positive effects in the prevention of lifestyle-related diseases, such as type II diabetes and cancer. For example, an increased dietary intake of these polyphenols correlates with a reduction in the occurrence of certain types of estrogen-related tumors, such as breast cancer in postmenopausal women.
In addition, some lignans have also aroused pharmacological interest. Examples are:
podophyllotoxin, obtained from plants of the genus Podophyllum (Berberidaceae family); it is a mitotic toxin whose derivatives have been used as chemotherapeutic agents;
arctigenin and tracheologin, obtained from tropical climbing plants; they have antiviral properties and have been tested in the search for a drug to treat AIDS .
Their basic chemical structure consists of two phenylpropane units linked by a C-C bond between the central atoms of the respective side chains (position 8 or β), also called β-β’ bond. 3-3′, 8-O-4′, or 8-3′ bonds are observed less frequently; in these cases the dimers are called neolignans. Hence, their chemical structure is referred to as (C6-C3)2, and they are included in the phenylpropanoid group, as well as their precursors: the hydroxycinnamic acids.
Phenylpropanoid unit
Based on their carbon skeleton, cyclization pattern, and the way in which oxygen is incorporated in the molecule skeleton, they can be divided into 8 subgroups: furans, furofurans, dibenzylbutanes, dibenzylbutyrolactones, dibenzocyclooctadienes, dibenzylbutyrolactols, aryltetralins and arylnaphthalenes. Furthermore, there is considerable variability regarding the oxidation level of both the propyl side chains and the aromatic rings.
They are not present in the free form in nature, but linked to other molecules, mainly as glycosylated derivatives.
Among the most common lignans, secoisolariciresinol (the most abundant one), lariciresinol, pinoresinol, matairesinol and 7-hydroxymatairesinol are found.
Note: They occur not only as dimers but also as more complex oligomers, such as dilignans and sesquilignans.
Biosynthesis
In this section, we will examine the biosynthesis of some of the most common lignans.
The pathway starts from 3 of the 4 most common dietary hydroxycinnamic acids: p-coumaric acid, sinapic acid, and ferulic acid (caffeic acid is not a precursor of this subgroup of polyphenols). Therefore, they arise from the shikimic acid pathway, via phenylalanine.
Lignan Biosynthesis
The first three reactions reduce the carboxylic group of the hydroxycinnamates to alcohol group, with formation of the corresponding alcohols, called monolignols, that is, p-coumaric alcohol, sinapyl alcohol and coniferyl alcohol. These molecules also enter the pathway of lignin biosynthesis.
The first step, which leads to the activation of the hydroxycinnamic acids, is catalysed by hydroxycinnamate:CoA ligases, commonly called p-coumarate:CoA ligases (EC 6.2.1.12), with formation of the corresponding hydroxycinnamate-CoAs, namely, feruloil-CoA, p- coumaroyl-CoA and sinapil-CoA.
In the second step, a NADPH-dependent cinnamoyl-CoA: oxidoreductase, also called cinnamoyl-CoA reductase (EC1.2.1.44) catalyzes the formation of the corresponding aldehydes, and the release of coenzyme A.
In the last step, a NADPH-dependent cinnamyl alcohol dehydrogenase, also called monolignol dehydrogenase (EC 1.1.1.195), catalyzes the reduction of the aldehyde group to an alcohol group, with the formation of the aforementioned monolignols.
The next step, the dimerization of monolignols, involves the intervention of stereoselective mechanisms, or, more precisely, enantioselective mechanisms.In fact, most of the plant lignans exists as (+)- or (-)-enantiomers, that is, isomers with property of chirality, whose relative amounts can vary from species to species, but also in different organs on the same plant, depending on the type of reactions involved.
The dimerization can occur through enzymatic reactions involving laccases (EC 1.10.3.2). These enzymes catalyze the formation of radicals that, dimerizing, form a racemic mixture. However, this does not explain how the racemic mixtures found in plants are formed. The most accepted mechanism to explain the stereospecific synthesis involves the action of the laccase and of a protein able to direct the synthesis toward one or the other of the two enantiomeric forms: the dirigent protein. The reaction scheme might be: the enzyme catalyzes the synthesis of phenylpropanoid radicals that are orientated in such a way to obtain the desired stereospecific coupling by the dirigent protein.
(-)-Matairesinol
For example, pinoresinol synthase, consisting of laccase and dirigent protein, catalyzes the stereospecific synthesis of (+)-pinoresinol from two units of coniferyl alcohol. (+)-Pinoresinol, in two consecutive stereospecific reactions catalyzed by NADPH-dependent pinoresinol/lariciresinol reductase (EC 1.23.1.2), is first reduced to (+)-lariciresinol, and then to (-)-secoisolariciresinol. (-)-Secoisolariciresinol, in the reaction catalyzed by NAD(P)-dependent secoisolariciresinol dehydrogenase (EC 1.1.1.331) is oxidized to (-)-matairesinol.
Metabolism by human gut microbiota
Their importance to human health is due largely to their metabolism by gut microbiota, which is part of the larger human microbiota, and that carries out deglycosylations, para-dehydroxylations, and meta-demethylations without enantiomeric inversion.
Indeed, this metabolization leads to the formation molecules with a modest estrogen-like activity (phytoestrogens), a situation similar to that observed with some isoflavones, such as those of soybean, some coumarins, and some stilbenes. These active metabolites are the so-called “mammalian lignans or enterolignans”, such as the aglycones of enterodiol and enterolactone, formed from secoisolariciresinol and matairesinol, respectively.
Studies conducted on animals fed diets rich in lignans have shown their presence as intact molecules, in low concentrations, in serum, suggesting that they may be absorbed as such from the intestine. These molecules exhibit estrogen-independent actions, both in vivo and in vitro, such as inhibition of angiogenesis, reduction of diabetes, and suppression of tumor growth.
Note: The term “phytoestrogen” refers to molecules with estrogenic or antiandrogenic activity, at least in vitro.
Once absorbed, they enter the enterohepatic circulation, and, in the liver, may undergo phase II reactions and be sulfated or glucuronidated, and finally excreted in the urine.
Food sources
The richest dietary source is flaxseed (linseed), that contains mainly secoisolariciresinol, but also lariciresinol, pinoresinol and matairesinol in good quantity (for a total amount of more than 3.7 mg/100 g dry weight). They are also found in sesame seeds.
(-)-Secoisolariciresinol
Another important source is whole grains.
They are also present in other foods, but in concentrations from one hundred to one thousand times lower than those of flaxseed. Examples are:
beverages, generally more abundant in red wine, followed in descending order by black tea, soy milk and coffee;
fruits, such as apricots, pears, peaches, strawberries;
among vegetables, Brassicaceae, garlic, asparagus and carrots;
lentils and beans.
Their presence in grains and, to a lesser extent in red wine and fruit, makes them, at least in individuals who follow a mediterranean diet, the main source of phytoestrogens.
References
Andersen Ø.M., Markham K.R. Flavonoids: chemistry, biochemistry, and applications. CRC Press Taylor & Francis Group, 2006
de la Rosa L.A., Alvarez-Parrilla E., Gonzàlez-Aguilar G.A. Fruit and vegetable phytochemicals: chemistry, nutritional value, and stability. 1th Edition. Wiley J. & Sons, Inc., Publication, 2010
Manach C., Scalbert A., Morand C., Rémésy C., and Jime´nez L. Polyphenols: food sources and bioavailability. Am J Clin Nutr 2004;79(5):727-747. doi:10.1093/ajcn/79.5.727
Satake H, Koyama T., Bahabadi S.E., Matsumoto E., Ono E. and Murata J. Essences in metabolic engineering of lignan biosynthesis. Metabolites 2015;5:270-290. doi:10.3390/metabo5020270
Tsao R. Chemistry and biochemistry of dietary polyphenols. Nutrients 2010;2:1231-1246. doi:10.3390/nu2121231
van Duynhoven J., Vaughan E.E., Jacobs D.M., Kemperman R.A., van Velzen E.J.J, Gross G., Roger L.C., Possemiers S., Smilde A.K., Doré J., Westerhuis J.A.,and Van de Wiele T. Metabolic fate of polyphenols in the human superorganism. PNAS 2011;108(suppl. 1):4531-4538. doi:10.1073/pnas.1000098107
Wink M. Biochemistry of plant secondary metabolism – 2nd Edition. Annual plant reviews (v. 40), Wiley J. & Sons, Inc., Publication, 2010
Hydroxycinnamic acids or hydroxycinnamates are phenolic compounds belonging to non-flavonoid polyphenols.
They are present in all parts of fruits and vegetables although the highest concentrations are found in the outer part of ripe fruits, concentrations that decrease during ripening, while the total amount increases as the size of the fruits increases.
Their dietary intake has been associated with the prevention of:
cardiovascular diseases;
cancer;
type-2 diabetes.
These effects do seem to be due not only to their high antioxidant activity, that depends upon the hydroxylation pattern of the aromatic ring, but also to other mechanisms of action such as, e.g., the reduction of intestinal absorption of glucose or the modulation of secretion of some gut hormones.
Their basic structure is a benzene ring to which a three carbon chain is attached, structure that is referred to as C6-C3. Therefore they can be included in the phenylpropanoid group.
Basic Skeleton of Hydroxycinnamates
The main dietary hydroxycinnamates are:
caffeic acid or 3,4-dihydroxycinnamic acid;
ferulic acid or 4-hydroxy-3-methoxycinnamic acid;
sinapic acid or 4-hydroxy-3,5-dimethoxycinnamic acid;
p-coumaric acid or 4-coumaric acid or 4-hydroxycinnamic acid.
In nature, they are associated with other molecules to form, e.g., glycosylated derivatives or esters of tartaric acid, quinic acid, or shikimic acid. In addition, several hundreds of anthocyanins acylated with the aforementioned hydroxycinnamates have been identified (in descending order with p-coumaric acid, more than 150, caffeic acid, about 100, ferulic acid, about 60, and sinapic acid, about 25).
They are rarely present in the free form, except in processed foods that have undergone fermentation, sterilization or freezing. For example, an overlong storage of blood orange fruits causes a massive hydrolysis of hydroxycinnamic derivatives to free acids, and this in turn could lead to the formation of malodorous compounds such as vinyl phenols, indicators of too advanced senescence of the fruit.
Biosynthesis
Hydroxycinnamate biosynthesis consists of a series of enzymatic reactions subsequent to that catalyzed by phenylalanine ammonia lyase (PAL).
Phenylalanine ⇄ trans-Cinnamic acid + NH3
This enzyme catalyzes the deamination of phenylalanine to yield trans-cinnamic acid, so linking the aromatic amino acid to the hydroxycinnamic acids and their activated forms.
Biosynthesis of Hydroxycinnamates
In the first step, a hydroxyl group is attached at the 4-position of the aromatic ring of trans-cinnamic acid to form p-coumaric acid. The reaction catalysed by trans-cinnamate 4-monooxygenase (EC:1.14.14.91).
The addition of a second hydroxyl group at the 3-position of the ring of p-coumaric acid leads to the formation of caffeic acid. The reaction catalysed by p-coumarate 3-hydroxylase (EC 1.14.13.-).
The O-methylation of the hydroxyl group at the 3-position yields ferulic acid. The reaction catalyzed by caffeate 3-O-methyltransferase (EC:2.1.1.68).
Caffeic acid + SAM ⇄ Ferulic acid + SAH
Ferulic acid is converted into sinapic acid through two reactions: a hydroxylation at the 5-position to form 5-hydroxy ferulic acid, in a reaction catalyzed by ferulate 5-hydroxylase (EC:1.14.-.-), and the subsequent O-methylation of the same hydroxyl group in a reaction catalyzed by caffeate 3-O-methyltransferase.
5-Hydroxy ferulic acid + SA from M ⇄ Sinapic acid + SAH
Hydroxycinnamic acids are not present in high quantities since they are rapidly converted to glucose esters or coenzyme A (CoA) esters, in reactions catalyzed by O-glucosyltransferases and hydroxycinnamate:CoA ligases, respectively. These activated intermediates are branch points, being able to participate in a wide range of reactions such as condensation with malonyl-CoA to form flavonoids, or the NADPH-dependent reduction to form lignans, which are precursors of lignin.
Food sources
Kiwis, blueberries, plums, cherries, apples, pears, chicory, artichokes, carrots, lettuce, eggplant, wheat and coffee are among the richest sources.
Caffeic acid
It is generally, both in the free form and bound to other molecules, the most abundant hydroxycinnamic acid in vegetables and most of the fruits, where it represents between 75 and 100 percent of the hydroxycinnamates.
The richest sources are coffee (drink), carrots, lettuce, potatoes, even sweet ones, and berries such as blueberries, cranberries and blackberries.
Smaller quantities are present in grapes and grape-derived products, orange juice, apples, plums, peaches, and tomatoes.
Caffeic acid and quinic acid bind to form chlorogenic acid, present in many fruit and in high concentration in coffee.
Ferulic acid
It is the most abundant hydroxycinnamic acid in cereals, which are also its main dietary source.
In wheat grain, its content is between 0.8 and 2 g/kg dry weight, which represents up to 90 percent of the total polyphenols. It is found chiefly, up to 98 percent of the total content, in the aleurone layer and pericarp, namely, the outer parts of the grain, and therefore its content in wheat flours depends upon the degree of refining, while the main source is obviously the bran. The molecule is present mainly in the trans form, and esterified with arabinoxylans and hemicelluloses. And in fact, in wheat bran the soluble free form represents only about 10 percent of its total amount. Dimers were also found, which form bridge structures between chains of hemicellulose.
In fruits and vegetables, ferulic acid is much less common than caffeic acid. The main sources are asparagus, eggplant and broccoli; lower quantities are found in blackberries, blueberries, cranberries, apples, carrots, potatoes, beets, coffee and orange juice.
Sinapic acid
The highest amounts are found in citrus peel and seeds (in orange juice, the amount is much lower); appreciable quantities in Chinese cabbage and in some varieties of cranberries.
p-Coumaric acid
High amounts are present in eggplant, the richest source, broccoli and asparagus; other sources are sweet cherries, plums, blueberries, cranberries, citrus peel and seeds, and orange juice.
References
Andersen Ø.M., Markham K.R. Flavonoids: chemistry, biochemistry, and applications. CRC Press Taylor & Francis Group, 2006
de la Rosa L.A., Alvarez-Parrilla E., Gonzàlez-Aguilar G.A. Fruit and vegetable phytochemicals: chemistry, nutritional value, and stability. 1th Edition. Wiley J. & Sons, Inc., Publication, 2010
Manach C., Scalbert A., Morand C., Rémésy C., and Jime´nez L. Polyphenols: food sources and bioavailability. Am J Clin Nutr 2004;79(5):727-747. doi:10.1093/ajcn/79.5.727
Preedy V.R. Coffee in health and disease prevention. Academic Press, 2014
Zhao Z., Moghadasian M.H. Bioavailability of hydroxycinnamates: a brief review of in vivo and in vitro studies. Phytochem Rev 2010;9(1):133-145. doi:10.1007/s11101-009-9145-5
The consumption of grapes and grape-derived products, particularly red wine but only at meals, has been associated with numerous health benefits, which include, in addition to the antioxidant/antiradical effect, also anti-inflammatory, cardioprotective, anticancer, antimicrobial, and neuroprotective activities.
Grapes contain many nutrients such as sugars, vitamins, minerals, fiber and phytochemicals. Among the latter, polyphenols from grapes are the most important compounds in determining the health effects of the fruit and derived products. Indeed, grapes are among the fruits with highest content in polyphenols, whose composition is strongly influenced by several factors such as:
cultivar;
climate;
exposure to disease;
processing
Nowadays, the main species of grapes cultivated worldwide are: European grapes, Vitis vinifera, North American grapes, Vitis rotundifolia and Vitis labrusca, and French hybrids.
Note: Grapes are not a fruit but an infructescence, that is, an ensemble of fruits (berries): the bunch of grapes. In turn, it consists of a peduncle, a rachis, cap stems or pedicels, and berries.
Polyphenols from red grapes and wine are significantly higher, both in quantity and variety, than in white ones. This, according to many researchers, would be the basis of the more health benefits related to the consumption of red grapes and wine than white grapes and derived products.
Polyphenols from grapes and wine are a complex mixture of flavonoid compounds, the most abundant group, and non-flavonoid compounds.
Among flavonoids, they are found:
Most of the flavonoids present in wine derive from the epidermal layer of the berry skin, while 60-70 percent of the total polyphenols are present in the grape seeds. It should be noted that more than 70 percent of grape polyphenols are not extracted and remain in the pomace.
The complex chemical interactions that occur between these compounds, and between them and the other compounds of different nature present in grapes and wine, are probably essential in determining both the quality of the grapes and wine and the broad spectrum of therapeutic effects of these foods.
In wine, the mixture of polyphenols play important functions being able to influence:
bitterness;
astringency;
red color, of which they are among the main responsible;
sensitivity to oxidation, being molecules easily oxidizable by atmospheric oxygen.
Finally, they act as wine preservatives, and are the basis of its long aging.
Anthocyanins
They are flavonoids widely distributed in fruits and vegetables.
They are primarily located in the berry skin, in the outer layers of the hypodermal tissue, to which they confer color, having a hue that varies from red to blue. In some varieties, called “teinturier”, they also accumulate in the flesh of the berry.
There is a close relationship between berry development and the biosynthesis of anthocyanins. The synthesis starts at veraison (when the berry stops growing and changes its color), causes a color change of the berry that turns purple, and reaches the maximum levels at complete ripening.
Among wine flavonoids, they are one of the most potent antioxidants.
Each grape species and cultivars has a unique composition of anthocyanins. Moreover, in grapes of Vitis vinifera, due to a mutation in the gene coding for 5-O-glucosyltransferase, mutation that determines the synthesis of an inactive enzyme, only 3-monoglucoside derivatives are synthesized, while in other species the glycosylation at position 5 also occurs. Interestingly, 3-monoglucoside derivatives are more intensely colored than 3,5-diglucoside derivatives.
Malvidin-3-glucoside
In red grapes and wine, the most abundant anthocyanins are the 3-monoglucosides of malvidin, the most abundant one both in grapes and wine, petunidin, delphinidin, peonidin, and cyanidin. In turn, the hydroxyl group at position 6 of the glucose can be acylated with an acetyl, caffeic or coumaric group, acylation that further enhances the stability.
Anthocyanidins, namely the non-conjugated molecules, are not present in grapes and in wine, except as traces.
Anthocyanins are scarcely present in white grapes and wine.
The composition of anthocyanins in wine is highly influenced both by the type of cultivar and by processing techniques, since they are present in wine as a result of extraction by maceration/fermentation processes. For this reason, wines deriving from similar varieties of grapes can have very different anthocyanin compositions.
Together with proanthocyanidins, they are the most important polyphenols in contributing to some organoleptic properties of red wine, as they are primarily responsible for astringency, bitterness, chemical stability against oxidation, as well as of the color of the young wine. In this regard, it should be underscored that with time their concentration decreases, while the color is due more and more to the formation of polymeric pigments produced by condensation of anthocyanins both among themselves and with other molecules. During wine aging, proanthocyanidins and anthocyanins react to produce more complex molecules that can partially precipitate.
Catechins
They are, together with condensed tannins, the most abundant flavonoids, representing up to 50 percent of the total polyphenols in white grapes and between 13 percent and 30 percent in red ones.
Their levels in wine depend on the type of cultivar.
Catechin
Typically, the most abundant flavanol in wine is catechin, but epicatechin and epicatechin-3-gallate are also present.
Proanthocyanidins
Composed of catechin monomers, they are present in the berry skin, seeds and rachis of the bunch of grapes as:
dimers: the most common are procyanidins B1-B4, but also procyanidins B5-B8 can be present;
trimers: procyanidin C1 is the most abundant;
tetramers;
polymers, containing up to 8 monomers.
Procyanidin C1
Their levels in wine depend on the type of grape varieties and wine-making technology, and, like anthocyanins, are much more abundant in red wines, in particular in aged wines, compared to white ones.
In addition, as previously said, together with anthocyanins, condensed tannins are important in determining some organoleptic properties of the wine.
Flavonols
Flavonols are present in a large variety of fruit and vegetables, even if in low concentrations.
They are the third most abundant group of flavonoids from grapes, after proanthocyanidins and catechins.
They are mainly present in the outer epidermis of the berry skin, where they play a role both in providing protection against UV-A and UV-B radiations and in copigmentation together with anthocyanins.
Flavanol synthesis begins in the sprout; the highest concentration is reached a few weeks after veraison, then it decreases as the berry increases in size.
Their total amount is very variable, with the red varieties often richer than the white ones.
In grapes, they are present as 3-glucosides and their composition depends on the type of grapes and cultivar:
the derivatives of quercetin, kaempferol and isorhamnetin are found in white grapes;
the derivatives of myricetin, laricitrin and syringetin are found, together with the previous ones, only in red grapes, due to the lack of expression in white grapes of the gene coding for flavonoid-3′,5′-hydroxylase.
Quercetin-3-glucoside
In general, the 3-glucosides and 3-glucuronides of quercetin are the major flavonols in most of the grape varieties. Conversely, quercetin-3-rhamnoside and quercetin aglycone are the major flavonols in muscadine grapes.
In wine and grape juice, unlike grapes, they are also found as aglycones, as a result of the acid hydrolysis that occurs during processing and storage. They are present in wine in a variable amount, and the major molecules are the glycosides of quercetin and myricetin, which alone represent 20-50 percent of the total flavonols in red wine.
Hydroxycinnamic acids
Hydroxycinnamic acids are the main class of non-flavonoid polyphenols from grapes and the major polyphenols in white wine.
The most important are p-coumaric, caffeic, sinapic, and ferulic acids, present in wine as esters with tartaric acid.
They have antioxidant activity and in some white varieties of Vitis vinifera, together with flavonols, are the polyphenols mainly responsible for absorbing UV radiation in the berry.
Stilbenes
They are phytoalexins which are produced in low concentrations only by a few edible species, including grapevine (on the contrary, flavonoids are present in all higher plants).
Together with the other polyphenols from grapes and wine, also stilbenes, particularly resveratrol, have been associated with health benefits resulting from the consumption of wine.
trans-Resveratrol
Their content increases from the veraison to the ripening of the berry, and is influenced by the type of cultivar, climate, wine-making technology, and fungal pressure.
The main stilbenes present in grapes and wine are:
cis- and trans-resveratrol (3,5,4′-trihydroxystilbene);
piceid or resveratrol-3-glucopyranoside and astringin or 3′-hydroxy-trans-piceid;
piceatannol;
dimers and oligomers of resveratrol, called viniferins, of which the most important are:
α-viniferin, a trimer;
β-viniferin, a cyclic tetramer;
γ-viniferin, a highly polymerized oligomer;
ε-viniferin, a cyclic dimer.
In grapes, other isomers and glycosylated forms of resveratrol and piceatannol, such as resveratroloside, hopeaphenol, or resveratrol di- and tri-glucoside derivatives, have been found in trace amounts.
Glycosylation of stilbenes is important for the modulation of antifungal activity, protection from oxidative degradation, and storage of the wine.
The synthesis of dimers and oligomers of resveratrol, both in grapes and wine, represents a defense mechanism against exogenous attacks or, on the contrary, the result of the action of extracellular enzymes released from pathogens in an attempt to eliminate undesirable compounds.
Hydroxybenzoates
The hydroxybenzoic acid derivatives are a minor component in grapes and wine.
In grapes, gentisic, gallic, p-hydroxybenzoic and protocatechuic acids are the main ones.
Gallic Acid
Unlike hydroxycinnamates, which are present in wine as esters with tartaric acid, they are found in their free form.
Together with flavonols, proanthocyanidins, catechins, and hydroxycinnamates they are among the responsible of astringency of wine.
References
Andersen Ø.M., Markham K.R. Flavonoids: chemistry, biochemistry, and applications. CRC Press Taylor & Francis Group, 2006
Basli A, Soulet S., Chaher N., Mérillon J.M., Chibane M., Monti J.P.,1 and Richard T. Wine polyphenols: potential agents in neuroprotection. Oxid Med Cell Longev 2012. doi:10.1155/2012/805762
de la Rosa L.A., Alvarez-Parrilla E., Gonzàlez-Aguilar G.A. Fruit and vegetable phytochemicals: chemistry, nutritional value, and stability. 1th Edition. Wiley J. & Sons, Inc., Publication, 2010
Flamini R., Mattivi F., De Rosso M., Arapitsas P. and Bavaresco L. Advanced knowledge of three important classes of grape phenolics: anthocyanins, stilbenes and flavonols. Int J Mol Sci 2013;14:19651-19669. doi:10.3390/ijms141019651
Georgiev V., Ananga A. and Tsolova V. Recent advances and uses of grape flavonoids as nutraceuticals. Nutrients 2014;6: 391-415. doi:10.3390/nu6010391
Guilford J.M. and Pezzuto J.M. Wine and health: a review. Am J Enol Vitic 2011;62(4):471-486. doi:10.5344/ajev.2011.11013
He S., Sun C. and Pan Y. Red wine polyphenols for cancer prevention. Int J Mol Sci 2008;9:842-853. doi:10.3390/ijms9050842
Xia E-Q., Deng G-F., Guo Y-J. and Li H-B. Biological activities of polyphenols from grapes. Int J Mol Sci 2010;11:622-646. doi:10.3390/ijms11020622
Olive oil is a liquid fat obtained by pressing whole olives, the fruit of the olive tree (Olea europaea).[1][2]
It is a staple ingredient in Mediterranean diet and is widely used for cooking, salad dressings, and other culinary purposes. Olive oil is also known for its health benefits, as it is rich in monounsaturated fats and antioxidants.[3]
From a chemical point of view, two fractions can be identified in olive oil, depending on their behavior in the presence of heat and strong alkaline solutions:
the saponifiable fraction, which represents 98−99% of the total weight, is composed of lipids that form soaps under the above conditions;
the unsaponifiable fraction, which represents the remaining 1−2% of the total weight, composed of substances that do not form soaps under the above conditions.[4][5]
It is composed of saturated and unsaturated fatty acids, esterified almost entirely to glycerol to form triglycerides or triacylglycerols. To a much lesser extent, diglycerides (or diacylglycerols), monoglycerides (or monoacylglycerols), and free fatty acids are also present.[4]
IOOC Requirements: Allowable fatty acid ranges in olive oil
Fatty acid
Number of carbons
Allowable range (%)
Myristic acid
C14:0
<0.03
Palmitic acid
C16:0
7.5−20
Palmitoleic acid
C16:1
0.3−3.5
Heptadecanoic acid
C17:0
≤0.3
Heptadecenoic acid
C17:1
≤0.3
Stearic acid
C18:0
0.5−5.0
Oleic acid
C18:1
55.0−83.0
Linoleic acid
C18:2
2.5−21.0
α-Linolenic acid
C18:3
≤1.0
Arachidic acid
C20:0
≤0.6
Gadoleic acid
C20:1
≤0.4
Behenic acid
C22:0
≤0.2
Lignoceric acid
C24:0
≤0.2
Unsaturated and saturated fatty acids
Oleic acid is the major fatty acid in olive oil.[7] According to the rules laid down by the International Olive Oil Council (IOOC), its concentration must range from 55 to 83% of total fatty acids.
Linoleic acid is the most abundant polyunsaturated fatty acid in olive oil; its concentration must vary between 2.5 and 21% (IOOC). Because of its high degree of unsaturation, it is prone to oxidation; this means that an oil rich in linoleic acid becomes rancid more easily and therefore has a shorter shelf life.[8]
In Mediterranean cuisine, olive oil is the main source of fat; therefore, oleic acid (among monounsaturated fatty acids) and linoleic acid (among polyunsaturated fatty acids) are the most abundant fatty acids.
α-Linolenic acid must be present in very small amounts, according to IOOC standards (≤1 percent). It is an omega-3 polyunsaturated fatty acid that may have health benefits. However, because of its high degree of unsaturation, higher than that of linoleic acid, it is very susceptible to oxidation and therefore promotes rancidity in olive oil containing it.
The presence of fatty acids that should be absent or are found in abnormal amounts is a marker of adulteration with other vegetable oils. In this regard, particular attention is paid to myristic, arachidic, behenic, lignoceric, gadoleic, and α-linolenic acids, whose limits are set by the IOOC.[6]
Factors influencing fatty acid profile
Fatty acid composition is influenced by several factors:
the climate;
the latitude;
the zone of production.
Italian, Spanish, and Greek olive oils are high in oleic acid and low in palmitic and linoleic acids, while Tunisian olive oils are high in palmitic and linoleic acids but lower in oleic acid. Therefore, oils can be divided into two groups:
those rich in oleic acid and low in palmitic and linoleic acids;
those high in palmitic and linoleic acids and low in oleic acid.[9][10]
Other influencing factors include:
the cultivar;
the degree of olive ripeness at the time of oil extraction.[7][11]
It should be noted that oleic acid is formed first in the fruit, and data seem to indicate a competitive relationship between oleic acid and palmitic, palmitoleic, and linoleic acids.[8]
Triglycerides
As previously mentioned, fatty acids in olive oil are almost entirely present as triglycerides.
In small percentages, they are also present as diglycerides, monoglycerides, and in free form.[12]
The sn Positions of Triglycerides
During triglyceride biosynthesis, thanks to the action of specific enzymes, only about 2% of glycerol molecules bind palmitic acid at the sn-2 position. The percentage of stearic acid in the sn-2 position is also very low. For the most part, the sn-2 position is occupied by oleic acid.[4][13]
Conversely, in oils that have undergone nonenzymatic esterification, the percentage of palmitic acid in the sn-2 position increases significantly.[11]
Note: sn = stereospecific numbering
The relative abundance of olive oil triglycerides is well characterized and standardized by the International Olive Oil Council. Among the triglycerides present in significant proportions in olive oil, the following are the most abundant:
OOO: 40−59%;
POO: 12−20%;
OOL: 12.5−20%;
POL: 5.5−7%;
SOO: 3−7%.
POP, POS, OLnL, OLnO, PLL, and PLnO are present in smaller amounts.[6]
Trilinolein (LLL) is a triglyceride that contains three molecules of linoleic acid; its low content is an indicator of good-quality oil.
Triglycerides containing three saturated fatty acids or three molecules of α-linolenic acid have not been reported.[14]
Diglycerides and monoglycerides
Their presence is due to incomplete synthesis and/or partial hydrolysis of triglycerides.
The content of diglycerides in virgin olive oil ranges from 1 to 2.8%. 1,2-Diglycerides prevail in fresh olive oil, representing over 80% of total diglycerides.[15]
During storage, isomerization occurs with a progressive increase in the more stable 1,3-isomers, which after about 10 months become the predominant form. Therefore, the 1,2/1,3-diglyceride ratio may be used as an indicator of the age of the oil.
Monoglycerides are present in amounts lower than diglycerides (<0.25%), with 1-monoglycerides being far more abundant than 2-monoglycerides.[16]
Unsaponifiable fractions
This fraction is composed of a large number of different molecules, which play a key nutritional role, as they contribute significantly to the health benefits of olive oil. Furthermore, they are responsible for the stability and taste of olive oil and are also used to detect adulteration with other vegetable oils.[4]
It includes tocopherols, sterols, polyphenols, pigments, hydrocarbons, aromatic and aliphatic alcohols, triterpene acids, waxes, and other minor constituents.[17]
Their content is influenced by factors similar to those affecting fatty acid composition, such as:
It should be noted that many of these compounds are not present in refined olive oils, as they are removed during the refining process.[11]
Polyphenols
Polyphenols make up 18 to 37% of the unsaponifiable fraction.
They are a very heterogeneous group of molecules with nutritional and organoleptic properties; for example, oleuropein and hydroxytyrosol give olive oil its bitter and pungent taste.[5][18]
For a more detailed discussion, see the article Polyphenols in olive oil.
Hydrocarbons
Hydrocarbons make up 30 to 50% of the unsaponifiable fraction.
Squalene and β-carotene are the main compounds.[19]
Squalene, first isolated from shark liver, is the major constituent of the unsaponifiable fraction, accounting for more than 90% of the hydrocarbons. Its concentration ranges from 200 to 7,500 mg/kg of olive oil.[20]
It is an intermediate in the biosynthesis of the four-ring structure of steroids and appears to be responsible for several of the health benefits attributed to olive oil.[21]
In the hydrocarbon fraction of virgin olive oil, n-paraffins, diterpene and triterpene hydrocarbons, and isoprenoid polyolefins are also found.[22]
Sterols
Sterols are important lipids of olive oil. They are:
linked to many health benefits for consumers;
important for the quality of the oil;
widely used to verify its authenticity.
In this regard, it should be emphasized that sterols are species-specific molecules. For example, the presence of high concentrations of brassicasterol, a sterol typically found in the Brassicaceae (Cruciferae) family, such as rapeseed, indicates adulteration of olive oil with canola oil.[11]
Four classes of sterols are present in olive oil: common sterols, 4-methylsterols, triterpene alcohols, and triterpene dialcohols.[22]
Their total content ranges from 1,000 mg/kg (the minimum value required by IOOC standards) to 2,000 mg/kg. The lowest values are found in refined oils, since the refining process may cause losses of up to 25%.[6][23][24]
Common sterols or 4-α-desmethylsterols
Common sterols are present mainly in free and esterified forms; however, they have also been detected as lipoproteins and steryl glucosides.
The main molecules are β-sitosterol, which makes up 75–90% of the total sterols; Δ5-avenasterol, 5–20%, and campesterol, about 4%.
Other components found in smaller or trace amounts include stigmasterol (≈ 2%), cholesterol, brassicasterol, and ergosterol.[24]
4-Methylsterols
These compounds are intermediates in sterol biosynthesis and are present in both free and esterified forms.[24]
They occur in small amounts, much lower than those of common sterols and triterpene alcohols, ranging from 50 to 360 mg/kg.
The main molecules are obtusifoliol, cycloeucalenol, citrostadienol, and gramisterol.[22]
Triterpene alcohols or 4,4-dimethylsterols
This is a complex class of sterols, present in both free and esterified forms.
They are found in amounts ranging from 350 to 1,500 mg/kg. The main components are β-amyrin, 24-methylenecycloartanol, cycloartenol, and butyrospermol. Other molecules present in lower or trace amounts include cyclosadol, cyclobranol, germanicol, and dammaradienol.[22]
Triterpene dialcohols
The main triterpene dialcohols found in olive oil are erythrodiol and uvaol.
Erythrodiol occurs in both free and esterified forms; in virgin olive oil, its content ranges from 19 to 69 mg/kg, and the free form is generally lower than 50 mg/kg.[22][23]
Tocopherols
Tocopherols make up 2 to 3% of the unsaponifiable fraction and include vitamin E.[4]
Of the eight E-vitamers, α-tocopherol represents about 90% of total tocopherols in virgin olive oil. It is present in the free form and in variable amounts, generally exceeding 100 mg/kg of olive oil.[25]
Thanks to its in vivo antioxidant properties, its presence is a protective factor for health.[26]
The α-tocopherol concentration appears to be related to the high levels of chlorophylls and the concurrent need for singlet oxygen deactivation.[27]
β-Tocopherol, δ-tocopherol, and γ-tocopherol are usually present in small amounts.[22]
Pigments
In this group we find chlorophylls and carotenoids.
In olive oil, chlorophylls are present as pheophytins, mainly pheophytin A, a chlorophyll molecule in which magnesium has been replaced by two hydrogen ions, and they confer the characteristic green color to olive oil.
They act as photosensitizers, contributing to the photooxidation of the oil itself.[28][29]
β-Carotene and lutein are the main carotenoids in olive oil. Several xanthophylls are also present, such as antheraxanthin, β-cryptoxanthin, luteoxanthin, mutatoxanthin, neoxanthin, and violaxanthin.[30]
The color of olive oil results from the presence of chlorophylls and carotenoids and from their combined green and yellow hues.[31]
Triterpene acids
These are important components of olives and are present in trace amounts in the oil. Oleanolic and maslinic acids are the main triterpene acids in virgin olive oil; they are found in the olive husk and are extracted in small quantities during processing.[32]
Aliphatic and aromatic alcohols
The most important are fatty alcohols and diterpene alcohols.
Aliphatic alcohols contain between 20 and 30 carbon atoms and are found mainly inside the olive stones, from which they are partially extracted during milling.[4]
Fatty alcohols
These are linear saturated alcohols containing more than 16 carbon atoms.
They occur in both free and esterified forms and, in virgin olive oil, are generally present at concentrations not exceeding 250 mg/kg.
Docosanol, tetracosanol, hexacosanol, and octacosanol are the main fatty alcohols in olive oil, with tetracosanol and hexacosanol being the most abundant.
Waxes, which are minor constituents of olive oil, are esters of fatty alcohols with fatty acids, mainly palmitic and oleic acids.
They can be used as a criterion to distinguish between different types of oils; for example, according to IOOC standards, they must be present in virgin and extra virgin olive oil at levels below 150 mg/kg.[11]
Diterpene alcohols
Geranylgeraniol and phytol are two acyclic diterpene alcohols, present in both free and esterified forms.
Among the esters present in the wax fraction of extra virgin olive oil, oleate, eicosenoate, eicosanoate, docosanoate, and tetracosanoate have been identified, mainly as phytyl derivatives.[11]
Volatile compounds
More than 280 volatile compounds have been identified in olive oil, including hydrocarbons (the most abundant fraction), alcohols, aldehydes, ketones, esters, acids, ethers, and many others.
However, only about 70 compounds are present at levels above the perception threshold, beyond which they contribute to the aroma of virgin olive oil.[33][34]
Minor components
Among the minor components of olive oil are phospholipids, mainly phosphatidylserine, phosphatidylethanolamine, phosphatidylcholine, and phosphatidylinositol.
In unfiltered oils, trace amounts of proteins may also be found.[4]
^ Mazzocchi A., Leone L., Agostoni C., Pali-Schöll I. The secrets of the Mediterranean diet. Does [only] olive oil matter? Nutrients 2019;11(12):2941. doi:10.3390/nu11122941
^ abcdefg Gunstone F.D. Vegetable oils in food technology: composition, properties and uses. 2nd Edition. Wiley J. & Sons, Inc., Publication, 2011.
^ ab Bulotta S., Celano M., Lepore S.M., Montalcini T., Pujia A., Russo D. Beneficial effects of the olive oil phenolic components oleuropein and hydroxytyrosol: focus on protection against cardiovascular and metabolic diseases. J Transl Med 2014;12:219. doi:10.1186/s12967-014-0219-9
^ ab Tomé-Rodríguez S., Barba-Palomeque F., Ledesma-Escobar C.A., Miho H., Díez C.M., Priego-Capote F. Influence of genetic and interannual factors on the fatty acids profile of virgin olive oil. Food Chem 2023;422:136175. doi:10.1016/j.foodchem.2023.136175
^ ab Hernández M.L., Sicardo M.D., Belaj A., Martínez-Rivas J.M. The oleic/linoleic acid ratio in olive (Olea europaea L.) fruit mesocarp is mainly controlled by OeFAD2-2 and OeFAD2-5 genes together with the different specificity of extraplastidial acyltransferase enzymes. Front Plant Sci 2021;12:653997. doi:10.3389/fpls.2021.653997
^ Cetinkaya H., Kulak M. Soil characteristics influence the fatty acid profile of olive oils. Scientific Papers. Series B, Horticulture. 2016;60:53-57. Available at: https://www.researchgate.net/publication/387363822
^ Ben Hmida R., Gargouri B., Chtourou F., Sevim D., Bouaziz M. Fatty acid and triacyglycerid as markers of virgin olive oil from mediterranean region: traceability and chemometric authentication. Eur Food Res Technol 2022;248:1-16. doi:10.1007/s00217-022-04002-1
^ abcdefg Boskou D. Olive oil: chemistry and technology. 3rd Edition, AOCS Press, 2015.
^ Lukić I., Da Ros A., Guella G., Camin F., Masuero D., Mulinacci N., Vrhovsek U., Mattivi F. Lipid profiling and stable isotopic data analysis for differentiation of extra virgin olive oils based on their origin. Molecules 2019;25(1):4. doi:10.3390/molecules25010004
^ Karupaiah T., Sundram K. Effects of stereospecific positioning of fatty acids in triacylglycerol structures in native and randomized fats: a review of their nutritional implications. Nutr Metab (Lond) 2007;4:16. doi:10.1186/1743-7075-4-16
^ Jawad M.A., Jawhar A., Dakah A., Ejbara M.G. Effect of maturity stages on triglyceride and fatty acid profiles in olive oil from Zaity and Kaissy varieties grown in Syria. Sci Rep 2025;15(1):35935. doi:10.1038/s41598-025-20162-y
^ Caponio F., Bilancia M.T., Pasqualone A., Sikorska E., Gomes T. Influence of the exposure to light on extra virgin olive oil quality during storage. Eur Food Res Technol 2005;221:92-98. doi:10.1007/s00217-004-1126-8
^ Talarico I.R., Bartella L., Rocio-Bautista P., Di Donna L., Molina-Diaz A., Garcia-Reyes J.F. Paper spray mass spectrometry profiling of olive oil unsaponifiable fraction for commercial categories classification. Talanta 2024;267:125152. doi:10.1016/j.talanta.2023.125152
^ Servili M., Sordini B., Esposto S., Urbani S., Veneziani G., Di Maio I., Selvaggini R. and Taticchi A. Biological activities of phenolic compounds of extra virgin olive oil. Antioxidants 2014;3:1-23. doi:10.3390/antiox3010001
^ Barp L., Miklavčič Višnjevec A., Moret S. Analytical determination of Squalene in extra virgin olive oil and olive processing by-products, and its valorization as an ingredient in functional food – A critical review. Molecules 2024;29(21):5201. doi:10.3390/molecules29215201
^ Hernández M.L., Muñoz-Ocaña C., Posada P., et al. Functional characterization of four olive squalene synthases with respect to the squalene content of the virgin olive oil. J Agric Food Chem 2023;71(42):15701-15712. doi:10.1021/acs.jafc.3c05322
^ Ibrahim N., Fairus S., Zulfarina M.S., Naina Mohamed I. The efficacy of squalene in cardiovascular disease risk – A systematic review. Nutrients 2020;12(2):414. doi:10.3390/nu12020414
^ abcdef Jimenez-Lopez C., Carpena M., Lourenço-Lopes C., Gallardo-Gomez M., Lorenzo J.M., Barba F.J., Prieto M.A., Simal-Gandara J. Bioactive compounds and quality of extra virgin olive oil. Foods 2020;9(8):1014. doi:10.3390/foods9081014
^ abc Lukić M., Lukić I., Krapac M., Sladonja B., Piližota V. Sterols and triterpene diols in olive oil as indicators of variety and degree of ripening. Food Chem 2013;136(1):251-8. doi:10.1016/j.foodchem.2012.08.005
^ Beltrán G., Jiménez A., del Rio C., Sánchez S., Martínez L. Variability of vitamin E in virgin olive oil by agronomical and genetic factors. J Food Compos Anal 2010;23(6):633-639. doi:10.1016/j.jfca.2010.03.003
^ Sánchez-Villegas A., Sánchez-Tainta A. Virgin olive oil. In the prevention of cardiovascular disease through the
Mediterranean diet. Academic Press. Cambridge, MA, USA, 2018;59-87.
^ Grams G.W., Eskins K. Dye-sensitized photooxidation of tocopherols. Correlation between singlet oxygen reactivity and vitamin E activity. Biochemistry 1972;11(4):606-8. doi:10.1021/bi00754a020
^ Giuliani A., Cerretani L., Cichelli A. Chlorophylls in olive and in olive oil: chemistry and occurrences. Crit Rev Food Sci Nutr 2011;51(7):678-90. doi:10.1080/10408391003768199
^ Díez-Betriu A., Bustamante J., Romero A., Ninot A., Tres A., Vichi S., Guardiola F. Effect of the storage conditions and freezing speed on the color and chlorophyll profile of premium extra virgin olive oils. Foods 2023;12(1):222. doi:10.3390/foods12010222
^ Gandul-Rojas B., Roca M., Gallardo-Guerrero L. Chlorophylls and carotenoids in food products from olive tree. In: Boskou D., Clodoveo M.L. Products from Olive Tree. IntechOpen, London, 2016. doi:10.5772/64688
^ Borello E., Roncucci D., Domenici V. Study of the evolution of pigments from freshly pressed to ‘on-the-shelf’ extra-virgin olive oils by means of near-UV visible spectroscopy. Foods 2021;10(8):1891. doi:10.3390/foods10081891
^ Sánchez-Quesada C., López-Biedma A., Warleta F., Campos M., Beltrán G., Gaforio J.J. Bioactive properties of the main triterpenes found in olives, virgin olive oil, and leaves of Olea europaea. J Agric Food Chem 2013;61(50):12173-82. doi:10.1021/jf403154e
^ Nardella M., Moscetti R., Bedini G., Bandiera A., Chakravartula S.S.N., Massantini R. Impact of traditional and innovative malaxation techniques and technologies on nutritional and sensory quality of virgin olive oil – A review. Food Chem Adv
Volume 2023;2:100163. doi:10.1016/j.focha.2022.100163
^ Angerosa F., Servili M., Selvaggini R., Taticchi A., Esposto S., Montedoro G. Volatile compounds in virgin olive oil: occurrence and their relationship with the quality. J Chromatogr A 2004;1054(1-2):17-31. doi:10.1016/j.chroma.2004.07.093
Gluten is not a single protein but a mixture of cereal proteins, about 80 percent of its dry weight, for example gliadins and glutenins in wheat grains, lipids, 5-7 percent, starch, 5-10 percent, water, 5-8 percent, and mineral substances, <2 percent.
It forms when components naturally present in the grain of cereals, the caryopsis, and in their flours, are joined together by means of mechanical stress in aqueous environment, i.e. during the formation of the dough.
The term is also related to the family of proteins that cause problems for celiac patients.
Isolated for the first time in 1745 from wheat flour by the Italian chemist Jacopo Bartolomeo Beccari, it can be extracted from the dough by washing it gently under running water: starch, albumins and globulins, that are water-soluble, are washed out, and a sticky and elastic mass remains, precisely the gluten, which means glue in Latin.
durum wheat (Triticum durum); groats and semolina for dry pasta making are obtained from it;
common wheat or bread wheat (Triticum aestivum), so called because it is used in bread and fresh pasta making, and in bakery products;
khorasan wheat (Triticum turanicum); a variety of it is Kamut®;
triticale (× Triticosecale Wittmack), which is a hybrid of rye and common wheat;
bulgur, which is whole durum wheat, sprouted and then processed;
seitan, which is not a cereal, but a wheat derivative, also defined by some as “gluten steak”.
Given that most of the dietary intake of gluten comes from wheat flour, of which about 700 million tons per year are harvested, representing about 30 percent of the global cereal production, the following discussion will focus on wheat gluten, and mainly on its proteins.
Note: The term gluten is also used to indicate the protein fraction that remains after removal of starch and soluble proteins from the dough obtained with corn flour: however, this “corn gluten” is “functionally” different from that obtained from wheat flour.
Cereal grain proteins
The study of cereal grain proteins, as seen, began with the work of Beccari. 150 years later, in 1924, the English chemist Osborne T.B., which can rightly be considered the father of plant protein chemistry, developed a classification based on their solubility in various solvents.
The classification, still in use today, divides plant proteins into 4 families.
Albumins, soluble in water.
Globulins, soluble in saline solutions; for example avenalin of oat.
Prolamins, soluble in 70 percent alcohol solution, but not in water or absolute alcohol.
They include:
gliadins of wheat;
zein of corn;
avenin of oats;
hordein of barley;
secalin of rye.
They are the toxic fraction of gluten for celiac patients.
Glutelins, insoluble in water and neutral salt solutions, but soluble in acidic and basic solutions.
They include glutenins of wheat.
Approximate percentage composition of protein fractions in common cereals
Cereals
Albumins
Globulins
Prolamins*
Glutelins**
Wheat
9
5
40
46
Corn
4
2
55
39
Barley
13
12
52
23
Oats
11
56
9
23
Rice
5
10
5
80
* Gliadins in wheat ** Glutenins in wheat
Albumins and globulins are cytoplasmic proteins, often enzymes, rich in essential amino acids, such as lysine, tryptophan and methionine. They are found in the aleurone layer and embryo of the caryopsis.
Prolamins and glutelins are the storage proteins of cereal grains. They are rich in glutamine and proline, but very low in lysine, tryptophan and methionine. They are found in the endosperm, and are the vast majority of the proteins in the grains of wheat, corn, barley, oat, and rye.
Although Osborne classification is still widely used, it would be more appropriate to divide cereal grain proteins into three groups: structural and metabolic proteins, storage proteins, and defense proteins.
Wheat gluten proteins
Proteins represent 10-14 percent of the weight of the wheat caryopsis, whereas about 80 percent of its weight consists of carbohydrates.
According to the Osborne classification, albumins and globulins represent 15-20 percent of the proteins, while prolamins and glutelins are the remaining 80-85 percent, composed respectively of gliadins, 30-40 percent, and glutenins, 40-50 percent. Therefore, and unlike prolamins and glutelins in the grains of other cereals, gliadins and glutenins are present in similar amounts, about 40 percent.
Wheat Grain Proteins
Technologically, gliadins and glutenins are very important. Why?
These proteins are insoluble in water, and in the dough, that contains water, they bind to each other through a combination of intermolecular bonds, such as:
covalent bonds, i.e. disulfide bridges;
noncovalent bonds, such as hydrophobic interactions, van der Waals forces, hydrogen bonds, and ionic bonds.
Thanks to the formation of these intermolecular bonds, a three-dimensional lattice is formed. This structure entraps starch granules and carbon dioxide bubbles produced during leavening, and gives strength and elasticity to the dough, two properties of gluten widely exploited industrially.
In the usual diet of the European adult population, and in particular in Italian diet that is very rich in derivatives of wheat flour, gliadin and glutenin are the most abundant proteins, about 15 g per day. What does this mean? It means that gluten-free diet engages celiac patients both from a psychological and social point of view.
Note: The lipids of the gluten are strongly associated with the hydrophobic regions of gliadins and glutenins and, unlike what you can do with the flour, they are extracted with more difficulty. The lipid content of the gluten depends on the lipid content of the flour from which it was obtained.
Gliadins: extensibility and viscosity
Gliadins are hydrophobic monomeric prolamins, of globular nature and with low molecular weight. On the basis of electrophoretic mobility in low pH conditions, they are separated into the following types:
alpha/beta, and gamma, rich in sulfur, containing cysteines, that are involved in the formation of intramolecular disulfide bonds, and methionines;
omega, low in sulfur, given the almost total absence of cysteine and methionine.
They have a low nutritional value and are toxic to celiac patients because of the presence of particular amino acid sequences in the primary structure, such as proline-serine-glutamine-glutamine and glutamine-glutamine-glutamine-proline.
Gliadins are associated with each other and with glutenins through noncovalent interactions; thanks to that, they act as “plasticizers” in dough making. Indeed, they are responsible for viscosity and extensibility of gluten, whose three-dimensional lattice can deform, allowing the increase in volume of the dough as a result of gas production during leavening. This property is important in bread-making.
Their excess leads to the formation of a very extensible dough.
Glutenins: elasticity and toughness
Glutenins are polymeric proteins, that is, formed of multiple subunits, of fibrous nature, linked together by intermolecular disulfide bonds. The reduction of these bonds allows to divide them, by SDS-PAGE, into two groups.
High molecular weight (HMW) subunits, low in sulfur, that account for about 12 percent of total gluten proteins. The noncovalent bonds between them are responsible for the elasticity and tenacity of the gluten protein network, that is, of the viscoelastic properties of gluten, and so of the dough.
Low molecular weight (LMW) subunits, rich in sulfur, namely, cysteine residues.
These proteins form intermolecular disulfide bridges to each other and with HMW subunits, leading to the formation of a glutenin macropolymer.
Glutenins allow dough to hold its shape during mechanical (kneading) and not mechanical stresses (increase in volume due to both the leavening and the heat of cooking that increases the volume occupied by gases present) which is submitted. This property is important in pasta making.
If in excess, glutenins lead to the formation of a strong and rigid dough.
Properties of wheat gluten
From the nutritional point of view, gluten proteins do not have a high biological value, being low in lysine, an essential amino acid. Therefore, a gluten-free diet does not cause any important nutritional deficiencies.
On the other hand, it is of great importance in food industry. The combination, in aqueous solution, of gliadins and glutenins to form a three-dimensional lattice, provides viscoelastic properties, that is, extensibility-viscosity and elasticity-tenacity, to the dough, and then, a good structure to bread, pasta, and in general, to all foods made with wheat flour.
It has a high degree of palatability and a high fermenting power in the small intestine.
It is an exorphin: some peptides produced from intestinal digestion of gluten proteins may have an effect in central nervous system.
Gluten-free cereals
The following is a list of gluten-free cereals, minor cereals, and pseudocereals used as foods.
Cereals
corn or maize (Zea mays)
rice (Oryza sativa)
Minor cereals
They are defined “minor” not because they have a low nutritional value, but because they are grown in small areas and in lower quantities than wheat, rice and maize.
Fonio (Digitaria exilis)
Millet (Panicum miliaceum)
Panic (Panicum italicum)
Sorghum (Sorghum vulgare)
Teff (Eragrostis tef)
Teosinte; it is a group of four species of the genus Zea. They are plants that grow in Mexico (Sierra Madre), Guatemala and Venezuela.
Pseudocereals.
They are so called because they combine in their botany and nutritional properties characteristics of cereals and legumes, therefore of another plant family.
Buckwheat (Fagopyrum esculentum)
Quinoa (Chenopodium quinoa), a pseudocereal with excellent nutritional properties, containing fibers, iron, zinc and magnesium. It belongs to Chenopodiaceae family, such as beets.
Cassava, also known as tapioca, manioc, or yuca (Manihot useful). It is grown mainly in the south of the Sahara and South America. It is an edible root tuber from which tapioca starch is extracted.
It should be noted that naturally gluten-free foods may not be truly gluten-free after processing. Indeed, the use of derivatives of gliadins in processed foods, or contamination in the production chain may occur, and this is obviously important because even traces of gluten are harmful for celiac patients.
Oats and gluten
Oats (Avena sativa) is among the cereals that celiac patients can eat. Recent studies have shown that it is tolerated by celiac patients, adult and child, even in subjects with dermatitis herpetiformis. Obviously, oats must be certified as gluten-free from contamination.
References
Beccari J.B. De Frumento. De bononiensi scientiarum et artium instituto atque Academia Commentarii, II. 1745:Part I.,122-127
Bender D.A. “Benders’ dictionary of nutrition and food technology”. 8th Edition. Woodhead Publishing. Oxford, 2006
Berdanier C.D., Dwyer J., Feldman E.B. Handbook of nutrition and food. 2th Edition. CRC Press. Taylor & Francis Group, 2007
Phillips G.O., Williams P.A. Handbook of food proteins. 1th Edition. Woodhead Publishing, 2011
Shewry P.R. and Halford N.G. Cereal seed storage proteins: structures, properties and role in grain utilization. J Exp Bot 2002:53(370);947-958. doi:10.1093/jexbot/53.370.947
Yildiz F. Advances in food biochemistry. CRC Press, 2009
Olive oil, which is obtained from the pressing of the olives, the fruits of olive tree (Olea europaea), is the main source of lipids in the mediterranean diet, and a good source of polyphenols.
Polyphenols, natural antioxidants, are present in olive pulp and, following pressing, they pass into the oil.
Note: olives are also known as drupes or stone fruits.
The concentration of polyphenols in olive oil is the result of a complex interaction between various factors, both environmental and linked to the extraction process of the oil itself, such as:
the place of cultivation;
the cultivars (variety);
the level of ripeness of the olives at the time of harvesting.
Their level usually decreases with over-ripening of the olives, although there are exceptions to this rule. For example, in warmer climates, olives produce oils richer in polyphenols, in spite of their faster maturation.
the climate;
the extraction process. In this regard, it is to underscore that the content of polyphenol in refined olive oil is not significant.
Any variation of the concentration of different polyphenols influence the taste, nutritional properties and stability of olive oil. For example, hydroxytyrosol and oleuropein (see below) give extra virgin olive oil a pungent and bitter taste.
Among polyphenols in olive oil, there are molecules with simple structure, such as phenolic acids and alcohols, and molecules with complex structure, such as flavonoids, secoiridoids, and lignans.
Flavonoids
Flavonoids include glycosides of flavonols (rutin, also known as quercetin-3-rutinoside), flavones (luteolin-7-glucoside), and anthocyanins (glycosides of delphinidin).
Phenolic acids and phenolic alcohols
Among phenolic acids, the first polyphenols with simple structure observed in olive oil, they are found:
hydroxybenzoic acids, such as, gallic, protocatechuic, and 4-hydroxybenzoic acids (all with C6-C1 structure).
hydroxycinnamic acids, such as caffeic, vanillin, syringic, p-coumaric, and o-coumaric acids (all with C6-C3 structure).
Among phenolic alcohols, the most abundant are hydroxytyrosol, also known as 3,4-dihydroxyphenyl-ethanol, and tyrosol, also known as 2-(4-hydroxyphenyl)-ethanol.
Hydroxytyrosol
It can be present as:
simple phenol;
phenol esterified with elenolic acid, forming oleuropein and its aglycone;
part of the molecule verbascoside.
Hydroxytyrosol
It can also be present in different glycosidic forms, depending on the –OH group to which the glucoside, i.e. elenolic acid plus glucose, is bound.
It is one of the main polyphenols in olive oil, extra virgin olive oil, and olive vegetable water.
In nature, its concentration, such as that of tyrosol, increases during fruit ripening, in parallel with the hydrolysis of compounds with higher molecular weight, while the total content of phenolic molecules and alpha-tocopherol decreases. Therefore, it can be considered as an indicator of the degree of ripeness of the olives.
In fresh extra virgin olive oil, hydroxytyrosol is mostly present in esterified form, while in time, due to hydrolysis reactions, the non-esterified form becomes the predominant one.
Finally, the concentration of hydroxytyrosol is correlated with the stability of olive oil.
Secoiridoids
They are the polyphenols in olive oil with the more complex structure, and are produced from the secondary metabolism of terpenes.
They are glycosylated compounds and are characterized by the presence of elenolic acid in their structure (both in its aglyconic or glucosidic form). Elenolic acid is the molecule common to glycosidic secoiridoids of Oleaceae.
Unlike tocopherols, flavonoids, phenolic acids, and phenolic alcohols, that are found in many fruits and vegetables belonging to different botanical families, secoiridoids are present only in plants of the Oleaceae family.
Ligstroside, oleuropein, demethyloleuropein, and nuzenide are the main secoiridoids.
In particular, oleuropein and demethyloleuropein (as verbascoside) are abundant in the pulp, but they are also found in other parts of the fruit. Nuzenide is only present in the seeds.
Oleuropein
Oleuropein, the ester of hydroxytyrosol and elenolic acid, is the most important secoiridoid, and the main olive oil polyphenol.
It is present in very high quantities in olive leaves, as also in all the constituent parts of the olive, including peel, pulp and kernel.
Oleuropein accumulates in olives during the growth phase, up to 14% of the net weight; when the fruit turns greener, its quantity reduces. Finally, when the olives turns dark brown, color due to the presence of anthocyanins, the reduction in its concentration becomes more evident.
It was also shown that its content is greater in green cultivars than in black ones.
During the reduction of oleuropein levels (and of the levels of other secoiridoids), an increase of compounds such as flavonoids, verbascosides, and simple phenols can be observed.
The reduction of its content is also accompanied by an increase in its secondary glycosylated products, that reach the highest values in black olives.
Lignans
Lignans, in particular (+)-1- acetoxypinoresinol and (+)-pinoresinol, are another group of polyphenols in olive oil.
(+)-pinoresinol is a common molecule in the lignin fraction of many plants, such as sesame (Sesamun indicum) and the seeds of the species Forsythia, belonging to the family Oleaceae. It has been also found in the olive kernel.
(+)-1- acetoxypinoresinol and (+)-1-hydroxypinoresinol, and their glycosides, have been found in the bark of the olive tree.
Lignans in Olive Oil
Lignans are not present in the pericarp of the olives, nor in leaves and sprigs that may accidentally be pressed with the olives.
Therefore, how they can pass into the olive oil becoming one of the main phenolic fractions is not yet known.
(+)-1- acetoxypinoresinol and (+)-pinoresinol are absent in seed oils, are virtually absent from refined virgin olive oil, while they may reach a concentration of 100 mg/kg in extra-virgin olive oil.
As seen for simple phenols and secoiridoids, there is considerable variation in their concentration among olive oils of various origin, variability probably related to differences between olive varieties, production areas, climate, and oil production techniques.
References
Cicerale S., Lucas L. and Keast R. Biological activities of phenolic compounds present in virgin olive oil. Int. J. Mol. Sci. 2010;11: 458-479. doi:10.3390/ijms11020458
de la Rosa L.A., Alvarez-Parrilla E., Gonzàlez-Aguilar G.A. Fruit and vegetable phytochemicals: chemistry, nutritional value, and stability. 1th Edition. Wiley J. & Sons, Inc., Publication, 2010
Manach C., Scalbert A., Morand C., Rémésy C., and Jime´nez L. Polyphenols: food sources and bioavailability. Am J Clin Nutr 2004;79(5):727-747. doi:10.1093/ajcn/79.5.727
Owen R.W., Mier W., Giacosa A., Hull W.E., Spiegelhalder B. and Bartsch H. Identification of lignans as major components in the phenolic fraction. Clin Chem 2000;46:976-988.
Tripoli E., Giammanco M., Tabacchi G., Di Majo D., Giammanco S. and La Guardia M. The phenolic compounds of olive oil: structure, biological activity and beneficial effects on human health. Nutr Res Rev 2005:18;98-112. doi:10.1079/NRR200495
During running, athletes burn calorie, and lose water and salts in amounts depending on various factors such as the technique, training level, environmental conditions, and physiological characteristics of each runner. The knowledge of these factors allows to plan an adequate diet both during workout and recovery, with the aim of optimizing performance. Below we will analyze the energy expenditure of runners engaged in workouts on various distances, the amounts of carbohydrates, lipids, and proteins oxidized to meet the energy requirements, and which minerals are lost in sweat.
During running energy expenditure is equal to 0.85-1.05 kcal per kilogram per kilometer.
This range is due to the fact that athletes with a good technique spend less than those with a poor technique.
A 70 kilogram (154 pound) athlete has an energy expenditure per kilometer between:
70 x 0.85 x 1 = 59.5 kcal
and
70 x 1.05 x 1 = 73.5 kcal
The table shows the calculations to determine the energy expenditure of the athlete to run 10, 20, 30, and 40 kilometers.
Estimated energy expenditure (kcal) during running , based on a 70 kg body weight and average calories burned per kg over different distances (km)
Distance
Energy expenditure
10
0.85 x 70 x 10 = 595
1.05 x 70 x 10 = 735
20
0.85 x 70 x 20 = 1190
1.05 x 70 x 20 = 1470
30
0.85 x 70 x 30 = 1785
1.05 x 70 x 30 = 2205
40
0.85 x 70 x 40 = 2380
1.05 x 70 x 40 = 2940
Note: who has started running for a short time ago has an energy expenditure even higher than 1.05 kcal per kilogram per kilometer.
During running, the energy for muscle work derives from the oxidation of carbohydrates, lipids, and proteins. Carbohydrates and lipids are the main energy source, and their oxidation rate depends on the intensity of exercise: as it increases, the percentage of lipid oxidation decreases whereas that of carbohydrates increases, as summarized below.
Energy source utilization during running as a function of exercise intensity (% VO2max)
Intensity
Fuel
30% VO2max
Mainly fats
40-60% VO2max
Fats and carbohydrates
75% VO2max
Mainly carbohydrates
80% VO2max
Almost exclusively carbohydrates
Note: The failure to use the suitable fuel can promote fatigue and lead to overtraining.
Then, when running above the anaerobic threshold, the oxidation of carbohydrates can provide the entire energy requirement. At marathon pace, carbohydrates provide 60-70 percent of the energy requirement, whereas at lower pace they provide less than 50 percent of energy requirement.
Below, the amounts of carbohydrates, lipids, and proteins oxidized during workout are analyzed. During workout ,the energy expenditure is covered for about 60 percent by carbohydrates, for about 40 percent by lipids, whereas the residual percentage, between 3 and 5 percent, by proteins.
Carbohydrate oxidation during workout
For a 70 kilogram runner the amount of carbohydrates oxidized per kilometer is between:
(0.6 x 59.5) /4 = 8.9 g/km
and
(0.6 x 73.5) /4 = 11 g/km
Note: carbohydrates provide, on average, 4 kcal per gram.
The table shows the calculations to determine the amount of carbohydrates oxidized when the athlete runs 10, 20, 30, and 40 kilometers.
Estimated carbohydrate expenditure (g) during running, based on energy expenditure (60% supported by carbohydrates ) and a body weight of 70 kg over various distances (km)
Distance
Carbohydrate expenditure
10
[(0.85 x 70 x 10) x 0.6 ] / 4 = 89
[(1.05 x 70 x 10) x 0.6 ] / 4 = 110
20
[(0.85 x 70 x 20) x 0.6] / 4 = 179
[(1.05 x 70 x 20) x 0.6] / 4 = 221
30
[(0.85 x 70 x 30) x 0.6] / 4 = 268
[(1.05 x 70 x 30) x 0.6] / 4 = 331
40
[(0.85 x 70 x 40) x 0.6] / 4 = 357
[(1.05 x 70 x 40) x 0.6] / 4 = 441
Lipid oxidation during workout
By calculations similar to those for carbohydrates, we determine the amount of lipids oxidized per kilometer, which is between:
(0.4 x 59.5) / 9 = 2.6 g/km
and
(0.4 x 73.5) / 9 = 3.3 g/km
Note: lipids provide, on average, 9 kcal per gram.
The table shows the calculations to determine the amount of lipids oxidized when the athlete runs 10, 20, 30, and 40 kilometers.
Estimated lipid expenditure (g) during running, based on energy expenditure (40% supported by lipids) and a body weight of 70 kg over various distances (km)
Distance
Lipid expenditure
10
[(0.85 x 70 x 10) x 0.4] / 9 = 26
[(1.05 x 70 x 10) x 0.4] / 9 = 33
20
[(0.85 x 70 x 20) x 0.4] / 9 = 53
[(1.05 x 70 x 20) x 0.4] / 9 = 65
30
[(0.85 x 70 x 30) x 0.4] / 9 = 79
[(1.05 x 70 x 30) x 0.4] / 9 = 98
40
[(0.85 x 70 x 40) x 0.4] / 9 = 106
[(1.05 x 70 x 40) x 0.4] / 9 = 131
Protein oxidation during workout
Protein requirements of adults are equal to 0.9 grams per kilogram of body weight, and, for a 70 kilogram athlete is:
70 x 0.9 = 63 g
During workout the energy expenditure is covered for about 3-5 percent by protein oxidation.
The table shows the calculations to determine the amount of proteins oxidized when the athlete runs 10, 20, 30, and 40 kilometers, and proteins provide 3 percent of the energy requirement.
Estimated protein expenditure (g) during running , based on energy expenditure (3% supported by proteins) and a body weight of 70 kg over various distances (km)
Distance
Protein expenditure
10
[(0.85 x 70 x 10) x 0.03)] / 4 = 4.5
[(1.05 x 70 x 10) x 0.03)] / 4 = 5.5
20
[(0.85 x 70 x 20) x 0.03)] / 4 = 8.9
[(1.05 x 70 x 20) x 0.03)] / 4 = 11
30
[(0.85 x 70 x 30) x 0.03)] / 4 = 13.4
[(1.05 x 70 x 30) x 0.03)] / 4 = 16.5
40
[(0.85 x 70 x 40) x 0.03)] / 4 = 17.9
[(1.05 x 70 x 40) x 0.03)] / 4 = 22.1
Note: proteins provide, on average, 4 kcal per gram.
For energy expenditure of 0.85 and 1.05 kcal per kilogram per kilometer, the average additional protein oxidation per kilogram to run 10, 20, 30, and 40 kilometers, rounded to the second decimal place, is:
10 km: [(4.5 + 5.5) / 2] / 70 = 0.07 g
20 km: [(4.5 + 5.5) / 2] / 70 = 0.14 g
30 km: [(4.5 + 5.5) / 2] / 70 = 0.21 g
40 km: [(4.5 + 5.5) / 2] / 70 = 0.29 g
Finally, adding the daily protein requirement of adults, the total protein requirement of a 70 kilogram runner, for the four distances, is:
10 km: 0.07 + 0.9 = 0.97 g
20 km: 0.14 + 0.9 = 1.04 g
30 km: 0.21 + 0.9 = 1.11 g
40 km: 0.29 + 0.9 = 1.19 g
By calculations similar to the previous ones, we determine the overall protein requirement when proteins provide 5 percent of the energy requirement.
10 km: 0.12 + 0.9 = 1.02 g
20 km: 0.24 + 0.9 = 1.14 g
30 km: 0.36 + 0.9 = 1.26 g
40 km: 0.48 + 0.9 = 1.38 g
Excluding athletes who run 30 kilometers or more every day, the values are slightly higher than 0.9 grams per kilogram of body weight.
In reality, the daily protein requirement is just slightly higher because a certain amount of nitrogen, hence proteins, is lost, as well as in the urine, also through sweating.
Water and minerals loss during running
Water losses depend on the amount of sweat produced, that depends on:
air temperature and humidity;
solar radiation.
The loss will be greater the higher these values are.
Finally, the amount of sweat produced is different from person to person.
Minerals lost in sweat are mostly:
sodium and chlorine, about 1 gram per liter of sweat in heat acclimatized athletes;
potassium, in an amount equal to about 15 percent of the sodium lost;
magnesium, in an amount equal to about 1 percent of the sodium lost.
The amount of minerals lost depends on how much sweat is produced, and it increases in non-heat acclimatized athletes.
The table shows the values, in grams per liter, of the minerals lost in sweat for non-heat and heat-acclimated athletes.
Values (grams per liter) of minerals lost in sweat in non-heat-acclimated and heat-acclimated athletes
Mineral
Non-heat acclimated athletes
Heat acclimated athletes
Sodium
1.38
0.92
Chlorine
1.5
1.00
Potassium
0.20
0.15
Magnesium
0.01
0.01
Total
3.09
2.08
Therefore, during physical activity, sodium is the mineral we need most of all.
After physical activity, runner, or who sweats heavily, tends to eat saltier food. This effect, known as selective hunger, was discovered, for sodium, in studies conducted on foundry workers. Probably, the selective hunger doesn’t not exist for potassium and magnesium.
References
Sawka M.N., Burke L.M., Eichner E.R., Maughan, R.J., Montain S.J., Stachenfeld N.S. American College of Sports Medicine position stand: exercise and fluid replacement. Med Sci Sport Exercise 2007;39(2):377-390. doi:10.1249/mss.0b013e31802ca597
Shirreffs S., Sawka M.N. Fluid and electrolyte needs for training, competition and recovery. J Sport Sci 2011;29:sup1, S39-S46. doi:10.1080/02640414.2011.614269
Alpha-amylase (α-amylase; EC 3.2.1.1) is an enzyme that catalyzes the hydrolysis of α-(1→4) glycosidic bonds present in the linear chains of amylose and amylopectin, the two major components of starch granules.[1][2]
It is widely distributed in animals, plants, fungi (including Ascomycota and Basidiomycota), bacteria (notably species of Bacillus), and Archaea. This broad distribution highlights its central role in carbohydrate metabolism.[3][4]
In humans, alpha-amylase is encoded by two genes and is synthesized mainly in the parotid glands and the exocrine pancreas.[5] In plants, the alpha-amylase gene family consists of six members.[6]
In animals, it initiates starch digestion, producing the disaccharide maltose, the oligosaccharides maltotriose and alpha-limit dextrins, and small amounts of glucose.[7]
Since starch is the primary dietary source of carbohydrates, and thus of glucose and energy, alpha-amylase activity may influence postprandial blood glucose levels.[8]
α-Amylase also has applications in various industrial sectors as well as in clinical diagnostics.[9][10]
In plants, particularly in grasses such as wheat, barley, and rice, it plays a crucial role in seed germination and grain maturation.[6][11]
The first evidence of amylase activity dates back to 1811, when the Russian chemist Konstantin Sigizmundovich Kirchhoff, working with wheat, discovered an enzymatic activity capable of breaking down starch.[12]
In 1831, the German chemist Erhard Friedrich Leuchs observed starch degradation when mixed with human saliva, and named the responsible agent “ptyalin”.
In 1833, French chemists Anselme Payen and Jean-François Persoz, working in a sugar factory, isolated from barley an enzyme able to degrade starch, which they named diastase.[7]
The term alpha-amylase was introduced by Richard Kuhn in 1925, after he discovered that the hydrolysis products were in the alpha configuration.[13]
In 1894, alpha-amylase became the first enzyme to be produced industrially. Initially extracted from a fungal source, it was used to treat digestive disorders. Starting in 1917, it was also extracted from Bacillus subtilis and Bacillus mesentericus. Today, it is mainly produced using genetically modified organisms.[3][14]
Amylases in general, including α-amylase, beta-amylase (EC 3.2.1.2), and gamma-amylase (EC 3.2.1.3), are widely applied in industries such as textiles, detergents, animal feed, food processing, brewing (beer and whiskey), cosmetics, pharmaceuticals, and clinical diagnostics.[9]
Alpha-amylases can be classified according to the degree of substrate hydrolysis: as liquefying enzymes, when they cleave 30–40% of starch glycosidic bonds, or saccharifying enzymes, when they cleave 50–60% of the bonds.[3]
Human alpha-amylase genes
In many mammals, including humans, alpha-amylase is encoded by two distinct but closely related genes located on the short arm of chromosome 1:
AMY1, which encodes the enzyme present in saliva, the mammary gland, and certain tumors, such as lung cancer;[15]
AMY2, which encodes the pancreatic enzyme. AMY2 occurs in two forms, AMY2A and AMY2B, whose copy number varies among populations, although two copies of each gene appear to be common. Copy numbers of AMY2 may also be associated with those of AMY1.[5][16]
Activity of alpha-amylase
Alpha-amylase catalyzes the first step of starch digestion, the hydrolysis of α-(1→4) glycosidic bonds in the linear chains of amylose and amylopectin, by acting at random sites along α-glucans. As an endoglycosidase, it requires calcium ions, has an optimal pH around 7, and produces disaccharides and oligosaccharides in the alpha configuration. Specifically, it generates maltose and maltotriose from amylose, and maltose, alpha-limit dextrins, and small amounts of glucose from amylopectin.[17][18]
Alpha-amylase
Like other enzymes involved in starch metabolism, such as pullulanase (EC 3.2.1.41), isoamylase (EC 3.2.1.68), starch-branching enzymes (EC 2.4.1.18), and starch-debranching enzymes, alpha-amylase belongs to glycoside hydrolase family 13 (GH13), a group of enzymes that act on substrates containing alpha-glycosidic bonds.[4]
Two enzymes involved in trehalose metabolism also fall within this family: trehalose synthase (EC 5.4.99.16), which catalyzes the interconversion of maltose and trehalose, and trehalose 6-phosphate hydrolase (EC 3.2.1.93), which hydrolyzes trehalose 6-phosphate to yield one molecule of glucose and one molecule of glucose 6-phosphate.[7][19]
Salivary alpha-amylase
Salivary alpha-amylase, also known as ptyalin, is synthesized mainly by the parotid glands and, to a lesser extent, by the submandibular glands.[20]
It occurs in both glycosylated and non-glycosylated forms and contributes to the initial, limited phase of starch digestion in the oral cavity.[21]
This enzyme is among the most abundant salivary proteins, accounting for 40–50% of total salivary protein content. Along with lingual lipase (EC 3.1.1.3), which hydrolyzes triglycerides and cholesterol esters during lipid digestion, salivary alpha-amylase is one of the principal enzymes in saliva.[22]
Pancreatic alpha-amylase
Pancreatic alpha-amylase is synthesized by the acinar cells of the pancreas.[23][24]
It is one of the major components of pancreatic juice and, upon entering the duodenum, hydrolyzes amylose and amylopectin, completing the first stage of amylolysis. The resulting products are subsequently cleaved by alpha-glucosidases located in the brush border of enterocytes, namely sucrase-isomaltase (EC 3.2.1.48) and maltase-glucoamylase (EC 3.2.1.20), which can also hydrolyze the α-(1→2) glycosidic bond of sucrose.[25]
Mammalian pancreatic α-amylase can bind to N-linked glycans on brush-border membrane glycoproteins.[26] This interaction enhances cooperation with sucrase-isomaltase, leading to a substantial increase in glucose production, up to 240%. However, high concentrations of alpha-amylase in the intestinal lumen have been observed to inhibit glucose uptake via SGLT1, an intestinal monosaccharide transporter involved in the absorption of monosaccharides. This inhibition has been hypothesized to represent an innate regulatory mechanism that prevents sudden spikes in glucose uptake and contributes to the regulation of postprandial blood glucose levels.[27]
Blood sugar control
Postprandial glycemic control is considered an effective strategy to prevent the development of type II diabetes. Among non-pharmacological approaches are interventions that reduce the ability of alpha-amylase to hydrolyze starch, either through food processing that induces starch retrogradation or through molecules naturally present in foods that, via different mechanisms, inhibit its activity.[8]
Food processing
Starch-rich foods are often subjected to hydrothermal treatments, such as boiling, which cause starch granule gelatinization: the granules absorb water, swell, and lose most of their crystalline structures, which are replaced by amorphous forms that are more easily hydrolyzed by alpha-amylase.[1] If gelatinized starch is subsequently cooled, recrystallization may occur, leading to the formation of retrograded starch, a type of starch resistant to α-amylase activity. This starch reaches the colon largely intact, where it is fermented by gut microbiota into short-chain fatty acids, similarly to soluble fiber.[28]
Role of polyphenols
Starch digestion by alpha-amylase is influenced by various food components, including non-starch cell wall polysaccharides, proteins, lipids, and, among phytochemicals, different classes of polyphenols.[1] These compounds can limit the action of alpha-amylase through at least four mechanisms.
Proteins and non-starch polysaccharides can limit the loss of the ordered structure of native starch during the hydrothermal processing of foods.
Lipids, polyphenols, proteins and non-starch polysaccharides can form ordered complexes with starch.
Proteins, non-starch polysaccharides, and polyphenols can create physical barriers that reduce the accessibility of hydrolytic enzymes to alpha-glucan chains.
Polyphenols and non-starch polysaccharides can directly reduce the activity of alpha-amylases and alpha-glucosidases.[8]
Among polyphenols, flavonoids, particularly proanthocyanidins (condensed tannins), appear to play a key role. For this inhibitory effect to be significant, the consumption of polyphenol-rich foods, such as black tea or green tea, should coincide with a carbohydrate-rich meal. Gluten however, may interfere with the interaction between polyphenols and starch granules, thereby reducing their inhibitory capacity.[8][29]
Amylase activity in clinical biochemistry
The measurement of serum α-amylase activity is a commonly used diagnostic laboratory test.
Increased serum amylase activity may result from:
acute pancreatitis or an exacerbation of chronic pancreatitis;
inflammation of the parotid glands;
obstruction of the secretory ducts of the parotid glands or the pancreatic duct.
Current assays do not distinguish between salivary and pancreatic isoforms. However, when elevated amylase activity is accompanied by increased lipase activity, the underlying pathology is most likely of pancreatic origin.[10][30][31]
Wheat alpha-amylase
In plants, particularly in wheat, alpha-amylase plays a key role in germination and in malting, a controlled germination process that converts grain into malt, used for the production of beer and whiskey.[32]
In wheat grains, the enzyme is mainly synthesized during the early stages of germination, which are heterotrophic and rely heavily on stored resources, especially starch in the endosperm. Its synthesis occurs in the aleurone layer and initiates the mobilization of starch reserves.[11]
Alpha-amylase is also implicated in one of the major quality defects of wheat: pre-harvest sprouting.[33]
References
^ abc Butterworth P.J., Bajka B.H., Edwards C.H., Warren F.J., Ellis P.R. Enzyme kinetic approach for mechanistic insight and predictions of in vivo starch digestibility and the glycaemic index of foods. Trends Food Sci Technol 2022;120:254-264. doi:10.1016/j.tifs.2021.11.015
^ Nelson D.L., Cox M.M. Lehninger. Principles of biochemistry. 8th Edition. W.H. Freeman and Company, 2021.
^ abc Tiwari S.P., Srivastava R., Singh C.S., Shukla K., Singh R.K., Singh P., Singh R., Singh N.L., and Sharma R. Amylases: an overview with special reference to alpha amylase. Journal of Global Biosciences 2015;4(SI1):1886-1901.
^ ab Janeček Š., Svensson B., MacGregor E.A. α-Amylase: an enzyme specificity found in various families of glycoside hydrolases. Cell Mol Life Sci 2014;71(7):1149-70. doi:10.1007/s00018-013-1388-z
^ ab Iafrate A.J., Feuk L., Rivera M.N., Listewnik M.L., Donahoe P.K., Qi Y., Scherer S.W, Lee C. Detection of large-scale variation in the human genome. Nat Genet 2004;36:949–951. doi:10.1038/ng1416
^ ab Ju L., Pan Z., Zhang H., Li Q., Liang J., Deng G., Yu M., Long H. New insights into the origin and evolution of α-amylase genes in green plants. Sci Rep 2019;9(1):4929. doi:10.1038/s41598-019-41420-w
^ abc Butterworth P.J., Warren F.J. and Ellis P.R. Human α-amylase and starch digestion: an interesting marriage. Starch/Stärke 2011;63:395-405. doi:10.1002/star.201000150
^ abcd Gong L., Feng D., Wang T., Ren Y., Liu Y., Wang J. Inhibitors of α-amylase and α-glucosidase: potential linkage for whole cereal foods on prevention of hyperglycemia. Food Sci Nutr 2020;8(12):6320-6337. doi:10.1002/fsn3.1987
^ ab de Souza P.M., de Oliveira Magalhães P. Application of microbial α-amylase in industry – A review. Braz J Microbiol 2010;41(4):850-61. doi:10.1590/S1517-83822010000400004
^ ab Erta G., Gersone G., Jurka A., Tretjakovs P. Salivary α-amylase as a metabolic biomarker: analytical tools, challenges, and clinical perspectives. Int J Mol Sci 2025;26(15):7365. doi:10.3390/ijms26157365
^ Zhang Q., Pritchard J., Mieog J., Byrne K., Colgrave M.L., Wang J.R., Ral J.F. Over-expression of a wheat late maturity alpha-amylase type 1 impact on starch properties during grain development and germination. Front Plant Sci 2022;13:811728. doi:10.3389/fpls.2022.811728
^ Zakowski J.J., Bruns D.E. Biochemistry of human alpha amylase isoenzymes. Crit Rev Clin Lab Sci 1985;21(4):283-322. doi:10.3109/10408368509165786
^ Kuhn R. Mechanism of the action of amylases. Constitution of starch. Justus Liebigs Annalen der Chemie 1925;443:1-71.
^ Pandey A., Nigam P., Soccol C.R., Soccol V.T., Singh D., Mohan R. Advances in microbial amylases. Biotechnol Appl Biochem 2000;31(2):135-52.
^ Perry G.H., Dominy N.J., Claw K.G., et al. Diet and the evolution of human amylase gene copy number variation. Nat Genet 2007;39(10):1256-60. doi:10.1038/ng2123
^ Carpenter D., Mitchell L.M., Armour J.A. Copy number variation of human AMY1 is a minor contributor to variation in salivary amylase expression and activity. Hum Genomics 2017;11(1):2. doi:10.1186/s40246-017-0097-3^
^ Benjamin S., Smitha R.B., Jisha V.N., Pradeep S., Sajith S., Sreedevi S., Priji P., Unni K.N., Sarath Josh M.K. A monograph on amylases from Bacillus spp. Adv biosci biotechnol 2013;4:No.2. doi:10.4236/abb.2013.42032
^ van der Maarel M.J., van der Veen B., Uitdehaag J.C., Leemhuis H., Dijkhuizen L. Properties and applications of starch-converting enzymes of the alpha-amylase family. J Biotechnol 2002;94(2):137-55. doi:10.1016/s0168-1656(01)00407-2
^ Agarwal N., Singh S.P. A novel trehalose synthase for the production of trehalose and trehalulose. Microbiol Spectr 2021;9(3):e0133321. doi:10.1128/Spectrum.01333-21
^ Schneyer L.H. Amylase content of separate salivary gland secretions of man. J Appl Physiol 1956;9(3):453-5. doi:10.1152/jappl.1956.9.3.453
^ Yang Z.M., Chen L.H., Zhang M., Lin J., Zhang J., Chen W.W., Yang X.R. Age differences of salivary alpha-amylase levels of basal and acute responses to citric acid stimulation between chinese children and adults. Front Physiol 2015;6:340. doi:10.3389/fphys.2015.00340
^Boehlke C., Zierau O., Hannig C. Salivary amylase – The enzyme of unspecialized euryphagous animals. Arch Oral Biol 2015;60(8):1162-76. doi:10.1016/j.archoralbio.2015.05.008
^ Keller P.J., Allan B.J. The protein composition of human pancreatic juice. J Biol Chem 1967;242(2):281-7. doi:10.1016/S0021-9258(19)81461-8
^ Basnet S., Ghimire M.P., Lamichhane T.R., Adhikari R., Adhikari A. Identification of potential human pancreatic α-amylase inhibitors from natural products by molecular docking, MM/GBSA calculations, MD simulations, and ADMET analysis. PLoS One 2023;18(3):e0275765. doi:10.1371/journal.pone.0275765
^ Nichols B.L., Avery S., Sen P., Swallow D.M., Hahn D., Sterchi E. The maltase-glucoamylase gene: common ancestry to sucrase-isomaltase with complementary starch digestion activities. Proc Natl Acad Sci U S A. 2003 Feb 4;100(3):1432-7. doi:10.1073/pnas.0237170100
^ Asanuma-Date K., Hirano Y., Le N., et al. Functional regulation of sugar assimilation by N-glycan-specific interaction of pancreatic α-amylase with glycoproteins of duodenal brush border membrane. J Biol Chem 2012;287(27):23104-18. doi:10.1074/jbc.m111.314658
^ Date K., Satoh A., Lida K., Ogawa H. Pancreatic α-amylase controls glucose assimilation by duodenal retrieval through N-glycan-specific binding, endocytosis, and degradation. J Biol Chem 2015;290(28):17439-50. doi:10.1074/jbc.M114.594937
^ Holtug K., Clausen M.R., Hove H., Christiansen J., Mortensen P.B. The colon in carbohydrate malabsorption: short-chain fatty acids, pH, and osmotic diarrhoea. Scand J Gastroenterol 1992;27(7):545-52. doi:10.3109/00365529209000118
^ Forester S.C., Gu Y., Lambert J.D. Inhibition of starch digestion by the green tea polyphenol, (-)-epigallocatechin-3-gallate. Mol Nutr Food Res 2012;56(11):1647-54. doi:10.1002/mnfr.201200206
^ Ismail O.Z., Bhayana V. Lipase or amylase for the diagnosis of acute pancreatitis? Clin Biochem 2017;50(18):1275-1280. doi:10.1016/j.clinbiochem.2017.07.003
^ Ekka N.M., Kujur A.D., Guria R., Mundu M., Mishra B., Sekhar S., Kumar A., Prakash J., Birua H. Serum lipase amylase ratio as an indicator to differentiate alcoholic from non-alcoholic acute pancreatitis: a systematic review and meta-analysis. Cureus 2023;15(2):e35618. doi:10.7759/cureus.35618
^ Fincher G.B. Molecular and cellular biology associated with endosperm mobilization in germinating cereal grains. Annu Rev Plant Physiol Plant Mol Biol 1989;40:305-46. doi:10.1146/annurev.pp.40.060189.001513
^ Gubler F., Millar A.A., Jacobsen J.V. Dormancy release, ABA and pre-harvest sprouting. Curr Opin Plant Biol 2005;8(2):183-7. doi:10.1016/j.pbi.2005.01.011
gamma-Linolenic acid (GLA), one of the omega-6 polyunsaturated fatty acids, like its precursor linoleic acid (the most abundant polyunsaturated fatty acid in human skin epidermis, where it’s involved in the maintenance of the epidermal water barrier), plays important roles in the physiology and pathophysiology of the skin.
Studies conducted on humans revealed that gamma-linolenic acid:
improves skin moisture, firmness, roughness;
decreases transepidermal water loss (one of the abnormalities of the skin in essential fatty acid deficiency animals).
Prostaglandin E1
Using guinea pig skin epidermis as a model of human epidermis (they are functionally similar), it was demonstrated that supplementation of animals with gamma-linolenic acid-rich foods results in a major production of PGE1 and 15-HETrE in the skin (as previously demonstrated in in vitro experiments).
Because these molecules have both anti-inflammatory/anti-proliferative properties supplementation of diet with gamma-linolenic acid acid-rich foods may be an adjuncts to standard therapy for inflammatory/proliferative skin disorders.
Supplemental sources of GLA
The main supplemental sources of gamma-linolenic acid are oils of the seeds of:
black currant (from 15% to 19% of the total fatty acids);
evening primrose (from 7% to 14% of the total fatty acids), and
Role of gamma-linolenic acid in lowering blood pressure
The relationship between dietary fatty acid intake and blood pressure mainly comes from studies conducted on genetically modified rats that spontaneously develops hypertension (a commonly used animal model for human hypertension).
In these studies many membrane abnormalities were seen so hypertension in rat model may be related to change in polyunsaturated fatty acid metabolism at cell membrane level.
About polyunsaturated fatty acids, several research teams have reported that gamma-linolenic acid reduces blood pressure in normal and genetically modified rats (greater effect) and it was purported by interfering with Renin-Angiotensin System (that promote vascular resistance and renal retention) altering the properties of the vascular smooth muscle cell membrane and so interfering with the action of angiotensin II.
Another possible mechanism of action of gamma-linolenic acid to lower blood pressure could be by its metabolite dihomo-gamma-linolenic acid: it may be incorporated in vascular smooth muscle cell membrane phospholipids, then released by the action of phospholipase A2 and transformed by COX-1 in PGE1 that induces vascular smooth muscle relaxation.
Role gamma-linolenic acid in treatment of rheumatoid arthritis
In a study conducted by Leventhal et al. on 1993 it was demonstrated the dietary intake of higher concentration of borage oil (about 1400 mg of gamma-linolenic acid/day) for 24 weeks resulted in clinically significant reductions in signs and symptoms of rheumatoid arthritis activity.
In a subsequent study by Zurier et al. on 1996 the dietary intake of an higher dose (about 2.8 g/day gamma-linolenic acid) for 6 months reduced, in a clinically relevant manner, signs and symptoms of the disease activity; patients who remained for 1 year on the 2.8 g/day dietary gamma-linolenic acid exhibited continued improvement in symptoms (the use of gamma-linolenic acid also at the above higher dose is well tolerated, with minimal deleterious effects). These data underscore that the daily amount and the duration of gamma-linolenic acid dietary intake do correlate with the clinical efficacy.
References
Akoh C.C. and Min D.B. “Food lipids: chemistry, nutrition, and biotechnology” 3th ed. 2008
Chow Ching K. “Fatty acids in foods and their health implication” 3th ed. 2008
Fan Y.Y. and Chapkin R.S. Importance of dietary γ-linolenic acid in human health and nutrition. J Nutr 1998;128:1411-1414. doi:10.1093/jn/128.9.1411
Leventhal L.J., Boyce E.G. and Zurier R.B. Treatment of rheumatoid arthritis with gammalinolenic acid. Ann Intern Med 1993;119:867-873. doi:10.7326/0003-4819-119-9-199311010-00001
Miller C.C. and Ziboh V.A. Gammalinolenic acid-enriched diet alters cutaneous eicosanoids. Biochem Biophys Res Commun 1988;154:967-974. doi:10.1016/0006-291X(88)90234-3
Zurier R.B., Rossetti R.G., Jacobson E.W., DeMarco D.M., Liu N.Y., Temming J.E., White B.M. and Laposata M. Gamma-linolenic acid treatment of rheumatoid arthritis. A randomized, placebocontrolled trial. Arthritis Rheum 1996;39:1808-1817. doi:10.1002/art.1780391106
Many studies have shown a direct, dose-dependent relationship between alcohol intake and blood pressure, particularly for intake above two drinks per day.
This relationship is independent of:
age;
salt intake;
obesity;
finally, it persists regardless of beverage type.
Furthermore, heavy consumption of alcoholic beverages for long periods of time is one of the factors predisposing to hypertension: from 5 to 7% of hypertension cases is due to an excessive alcohol consumption.
A meta-analysis of 15 randomized controlled trials has shown that decreasing alcoholic beverage intake intake has therapeutic benefit to hypertensive and normotensive with similar systolic and diastolic blood pressure reductions (in hypertensive reduction occurs within weeks).
Guidelines on the primary prevention of hypertension recommend that alcohol (ethanol) consumption in most men, in absence of other contra, should be less than 28 g/day, the limit in which it may reduce coronary heart disease risk. The consumption limited to these quantities must be obtained by intake of drinks with low ethanol content, preferably at meals (drinking even lightly to moderately outside of meals increases the probability to have hypertension). This means no more than 680 ml or 24 oz of regular beer or 280 ml or 10 oz of wine (12% ethanol), especially in hypertension; for women and thinner subjects consumption should be halved1.
To avoid intake of drinks with high ethanol content even though the total ethanol content not exceeding 28 g/day.
Relationship between ethanol intake and blood pressure
Anyway, uncertainty remains regarding benefits or risks attributable to light-to-moderate alcoholic beverage intake on the risk of hypertension.
In a study published on April 2008, the authors examined the association between ethanol intake and the risk of developing hypertension in 28848 women from “The Women’s Health Study” and 13455 men from the “Physicians’ Health Study”, (the follow-up lasted respectively for 10.9 and 21.8 years).
The study confirms that heavy ethanol intake (exceeding 2 drinks/day) increases hypertension risk in both men and women but, surprisingly, found that the association between light-to-moderate alcohol intake (up to 2 drinks/day) and the risk of developing hypertension is different in women and men. Women have a potential reduced risk of hypertension from a light-to-moderate ethanol consumption with a J-shaped association2; men have no benefits of light-to-moderate ethanol consumption but an increased risk of hypertension.
However, guidelines for the primary prevention of hypertension limit alcohol consumption to less 2 drinks/day in men and less 1 drink/day in thinner subjects and women.
1. A standard drink contains approximately 14 g of ethanol i.e. a 340 ml or 12 oz of regular beer, 140 ml or 5 oz wine (12% alcohol), or 42 ml or 1,5 oz of distilled spirits (inadvisable).
2. Many studies have shown a J-shaped relationship between ethanol intake and blood pressure. Light drinker (no more than 28 g of ethanol/day) have lower blood pressure than teetotalers; instead, who consumes more than 28 g ethanol/day have higher blood pressure than non drinker. So alcohol is a vasodilator at low doses but a vasoconstrictor at higher doses.
Sesso H.D., Cook N.R., Buring J.E., Manson J.E. and Gaziano J.M. Alcohol consumption and the risk of hypertension in women and men. Hypertension 2008;51:1080-1087. doi:10.1161/HYPERTENSIONAHA.107.104968
Writing Group of the PREMIER Collaborative Research Group. Effects of comprehensive lifestyle modification on blood pressure control: main results of the PREMIER Clinical Trial. JAMA 2003;289:2083-2093. doi:10.1001/jama.289.16.2083
World Health Organization, International Society of Hypertension Writing Group. 2003 World Health Organization (WHO)/International Society of Hypertension (ISH) statement on management of hypertension. Guidelines and recommendations. J Hyperten 2003;21:1983-1992.
Trans fatty acids or TFA or trans-unsaturated fatty acids or trans fats are unsaturated fatty acids, a subclass of lipids, with at least one a double bond in the trans configuration.
Carbon-carbon double bonds show planar conformation, and so they can be considered as planes from whose opposite sides carbon chain attaches and continues. “The entry” and “the exit” of the carbon chain from the plain may occur on the same side of the plain, and in this case double bond is in cis configuration, or on opposite side, and in that case it is in trans configuration. This is an example of geometric isomerism, also called cis-trans isomerism.
C18:1 cis/trans Isomers
Unsaturated fatty acids most commonly have their double bonds in cis configuration; the other, less common configuration is trans.
Cis bond causes a bend in the fatty acid chain, whereas the geometry of trans bond straightens the fatty acid chain, imparting a structure more similar to that of saturated fatty acids.
Below, some distinctive characteristics of the fats rich in trans fats, that make them particularly suited for the production of margarines and vegetable shortening used in home and commercial cooking, and manufacturing processes.
Bent molecules can’t pack together easily, but linear ones can do it.
This means that trans fatty acids contribute, together with the geometrically similar saturated fatty acids, to the hardness of the fats in which they are, giving them a higher melting point.
Heightening the melting point of fats means that it is possible to convert them from liquid form to semi-solids and solids at room temperature.
Note: trans fats tend to be less solid than saturated fatty acids.
They have a melting point, consistency and “mouth feel” similar to those of butter, a long shelf life at room temperature, and a flavor stability.
They are stable during frying.
Types of trans fatty acids
Dietary TFA come from different sources briefly reviewed below.
In industrialized countries, greater part of the consumed trans fatty acids, in USA about 80 percent of the total, are produced industrially, in varying amounts, during partial hydrogenation of edible oils containing unsaturated fatty acids.
They are produced at home during frying with vegetable oils containing unsaturated fatty acids.
They come from bacterial transformation of unsaturated fatty acids ingested by ruminants in their rumen.
Another natural source is represented by some plant species, such as leeks, peas, lettuce and spinach, that contain trans-3-hexadecenoic acid, and rapeseed oil, that contains brassidic acid (22:1∆13t) and gondoic acid (20:1∆11t). In these sources trans fatty acids are present in small amounts.
Very small amounts, less than 2 percent, are formed during deodorization of vegetable oils, a process necessary in the refining of edible oils. During this process trans fatty acids with more than one double bond are formed in small amounts. These isomers are also present in fried foods and in considerable amounts in some partially hydrogenated vegetable oils.
Industrial trans fatty acids
Hydrogenation is a chemical reaction in which hydrogen atoms react, in the presence of a catalyst, with a molecule.
The hydrogenation of unsaturated fatty acids involves the addition of hydrogen atoms to double bonds on the carbon chains of fatty acids. The reaction occurs in presence of metal catalyst and hydrogen, and is favored by heating vegetable oils containing unsaturated fatty acids.
Partial hydrogenation of vegetable oils
The process of hydrogenation was first discovered in 1897 by French Nobel prize in Chemistry, jointly with fellow Frenchman Victor Grignard, Paul Sabatier using a nickel catalyst.
Partially hydrogenated vegetable oils were developed in 1903 by a German chemist, Wilhelm Normann, who files British patent on “Process for converting unsaturated fatty acids or their glycerides into saturated compounds”. The term trans fatty acids or trans fats appeared for the first time in the Remark column of the 5th edition of the “Standard Tables of Food Composition” in Japan.
During partial hydrogenation, an incomplete saturation of the unsaturated sites on the carbon chains of unsaturated fatty acids occurs. For example, with regard to fish oil, trans fatty acid content in non-hydrogenated oils and in highly hydrogenated oils is 0.5 and 3.6 percent, respectively, whereas in partially hydrogenated oils is 30 percent.
From Oleic Acid to Vaccenic Acid
But, most importantly, some of the remaining cis double bonds may be moved in their positions on the carbon chain, producing geometrical and positional isomers, that is, double bonds can be modified in both conformation and position.
Below, other changes that occur during partial hydrogenation are listed.
Cyclic monomers, as well as intramolecular linear dimmers, are also formed.
Partially hydrogenated vegetable oils were developed for the production of vegetable fats, a cheaper alternative to animal fats. In fact, through hydrogenation, oils such as soybean, safflower and cottonseed oils, which are rich in unsaturated fatty acids, are converted into semi-solid fats.
The first hydrogenated oil was cottonseed oil in USA in 1911 to produce vegetable shortening.
In the 1930’s, partial hydrogenation became popular with the development of margarine.
Currently, per year in USA, 6-8 billion tons of hydrogenated vegetable oil are produced.
Ruminant trans fatty acids
Ruminant trans fats are produced by bacteria in the rumen of the animals, for example cows, sheep and goats, using as a substrate a proportion of the relatively small amounts of unsaturated fatty acids present in their feedstuffs, that is, feed, plants and herbs.
And, considering an animal that lives at least a year, and has the opportunity to graze and/or eat hay, there is a season variability in unsaturated fatty acids intake, and trans fats produced. In fact, in summer and spring, pasture plants and herbs may contain more unsaturated fatty acids than the winter feed supply.
Then, TFA are present at low levels in meat and full fat dairy products, typically <5 percent of total fatty acids, and are located in the sn-1 and sn-3 positions of the triacylglycerols, whereas in margarines and other industrially hydrogenated products they appear to be concentrated in the sn-2 position of the triacylglycerols.
Ruminant trans fatty acids are mainly monounsaturated fatty acids, with 16 to 18 carbon atoms, and constitute a small percentage of the trans fatty acids in the diet.
Isomers
The most important cluster of trans fatty acids is trans-C18:1 isomers, that is, fatty acids containing 18 carbon atoms plus one double bond, whose position varies between Δ6 and Δ16 carbon atoms. In both sources, the most common isomers are those with double bonds between positions Δ9 and Δ11.
However, even if these molecules are present both in industrial and ruminant TFA, there is a considerable quantitative difference. For example, vaccenic acid (C18:1 Δ11t) represents over 60 percent of the trans-C18:1 isomers in ruminant trans fatty acids, whereas in industrial ones elaidic acid (C18:1Δ9t) comprises 15-20 percent and C18:1 Δ10t and vaccenic acid over 20 percent each others.
trans-C18:1 Isomers
Effects on human health
Ruminant trans fatty acids, in amounts actually consumed in diets, are not harmful for human health.
Conversely, consumption of industrial trans fats has neither apparent benefit nor intrinsic value, above their caloric contribution, and, from human health standpoint they are only harmful, having adverse effects on:
serum lipid levels;
endothelial cells;
systemic inflammation;
other risk factors for cardiovascular disease.
Moreover, they are positively associated with the risk of coronary heart disease (CHD), and sudden death from cardiac causes and diabetes.
Note: further in the text, we will refer to industrial trans fatty acids as trans fats or trans fatty acids.
Effects at plasmatic level
Low-density lipoprotein cholesterol (LDL-C) and high-density lipoprotein cholesterol (HDL-C) plasma levels are well-documented risk markers for the development of coronary heart disease or CHD.
High LDL-C levels are associated with an increased incidence of ischemic heart disease.
High HDL-C levels are associated with a reduced incidence of the risk.
For this reason, the ratio between total cholesterol level and HDL-C is often used as a combined risk marker for these two components in relation to the development of heart disease: the higher the ratio, the higher the risk.
TFA have adverse effects on serum lipids.
These effects have been evaluated in numerous controlled dietary trials by isocaloric replacement of saturated fatty acids or cis-unsaturated fatty acids with trans fats. It was demonstrated that such replacement:
raises LDL-C levels;
lowers HDL-C levels, in contrast to saturated fatty acids that increase HDL-C levels when used as replacement in similar study;
increases the ratio of total cholesterol to HDL-C, approximately twice that for saturated fatty acids, and, on the basis of this effect alone, trans fatty acids has been estimated to cause about 6% of coronary events in the USA.
Furthermore, trans fats:
produce a deleterious increase in small, dense LDL-C subfractions, that is associated with a marked increased in the risk of CHD, even in the presence of relatively normal LDL-C;
increase the blood levels of triglycerides, and this is an independent risk factor for CHD;
increase levels of Lp(a)lipoprotein, another important coronary risk factor.
But on 2004 prospective studies have shown that the relation between the intake of trans fatty acids and the incidence of CHD is greater than that predicted by changes in serum lipid levels alone. This suggests that trans fats influence other risk factors for CHD, such as inflammation and endothelial-cell dysfunction.
Inflammation and endothelial-cell dysfunction
The role of inflammation in atherosclerosis, and consequently in CHD, is burgeoned in the last decade.
Interleukin-6, C-reactive protein (CRP), and an increased activity of tumor necrosis factor (TNF) system are markers of inflammation.
In women greater intake of trans fatty acids is associated with increased activity of TNF system, and in those with a higher body mass index with increased levels of interleukin-6 and CRP. For example, the difference in CRP seen with an average intake of trans fats of 2.1 percent of the total daily energy intake, as compared with 0.9 percent, correspond to an increased risk of cardiovascular disease of 30 percent. Similar results have been reported in patients with established heart disease, in randomized, controlled trials, in in vitro studies, and in studies in which it has been analyzed membrane levels of trans fatty acids, a biomarker of their dietary intake.
So, trans fats promote inflammation, and their inflammatory effects may account at least in part for their effects on CHD that, as seen above, are greater than would be predicted by effects on serum lipoproteins alone.
Attention: the presence of inflammation is an independent risk factor not only for CHD but also for insulin resistance, diabetes, dyslipidemia, and heart failure.
Another site of action of TFA may be endothelial function.
Several studies have suggested the association between greater intake of trans fats and increased levels of circulating biomarkers of endothelial dysfunction, such as E-selectin, sICAM-1, and sVCAM-1.
Other effects
In vitro studies have demonstrate that trans fats affect lipid metabolism through several pathways.
They alter secretion, lipid composition, and size of apolipoprotein B-100 (apo B-100).
They increase cellular accumulation and secretion of free cholesterol and cholesterol esters by hepatocytes.
They alter expression in adipocytes of genes for peroxisome proliferator-activated receptor-gamma (PPAR-gamma), lipoprotein lipase, and resistin, proteins having a central roles in the metabolism of fatty acids and glucose.
Coronary heart disease
Industrial trans fats are independent cardiovascular risk factor.
Since the early 1990s attention has been focused on the effect of trans fatty acids on plasma lipid and lipoprotein concentrations.
Furthermore, four major prospective studies covering about 140,000 subjects, monitored for 6-14 years, have all found positive epidemiological evidence relating their levels in the diet, assessed with the aid of a detailed questionnaire on the composition of the diet, to the risk of CHD. These four studies are:
The Health Professionals Follow-up study;
The Alpha-Tocopherol Beta-Carotene Cancer Prevention Study;
The Nurses’ Health Study;
The Zutphen Elderly Study.
These studies cover such different populations that the results very probably hold true for the populations as a whole.
A meta-analysis of these studies have shown that a 2 percent increase in energy intake from industrial TFA was associated with a 23 percent increase in the incidence of CHD. The relative risk of heart disease was 1.36 in “The Health Professionals Follow-up Study”, 1.14 in “The Alpha-Tocopherol Beta-Carotene Cancer Prevention Study”; 1.93 (1.43-2.61) in “The Nurses’ Health Study”, and 1.28 (1.01-1.61) in “The Zutphen Elderly Study”.
So, there is a substantially increased risk even at low levels of intake: 2 percent of total energy intake, for a 2,000 Kcal diet is 40 Kcal or about 4-5 g of fat corresponding to a teaspoonful of fat!
Moreover, in three of the studies, the association between the intake of industrial trans fats and the risk of CHD was stronger than a corresponding association between the intake of saturated fatty acids and the risk of heart disease. In “The Zutphen Elderly Study”, this association was not investigated. Because of the adverse effects of industrial trans fatty acids, for the same authors are unethical conducting randomized long-term trials to test their effects on the incidence of CHD.
So, avoidance of industrial trans fats, or a consumption of less 0.5% of total daily energy intake is necessary to avoid their adverse effects, far stronger on average than those of food contaminants or pesticide residues.
Further evidence
A study conducted in an Australia population with a first heart attack and no preceding history of CHD or hyperlipidemia has showed a positive association between levels of trans fatty acids in adipose tissue and the risk of nonfatal myocardial infarction.
It was shown that adipose tissue C18:1Δ7t, found in both animal and vegetable fats, was an independent predictor of a first myocardial infarction, that is, its adipose tissue level is still a predictor for heart disease after adjustment for total cholesterol. Again, it appears that only a minor part of the negative effects of trans fats occurs via plasma lipoproteins.
During the course of this study, mid-1996, TFA were eliminated from margarines sold in Australia. This was a unique opportunity to investigate the temporal relationship between trans fat intake and their adipose tissue levels. It was demonstrated that trans fats disappear from adipose tissue of both case-patients and controls with a rate about 15 percent of total trans fats/y.
Another study conduct in Costa Rica have found a positive association between myocardial infarction and trans fatty acids.
Interestingly, in a larger, community-based case-control study, levels of trans fats in red blood cell membranes were associated, after adjustment for other risk factors, with an increase in the risk of sudden cardiac death. Moreover, the increased risk appeared to be related to trans-C18:2 levels, that were associated with a tripling of the risk, but not with cell membrane levels of trans-C18:1, the major trans fatty acids in foods (see above).
Diabetes
In a prospective study covering 84,204 female nurses, from “The Nurses’ Health Study”, aged 34–59 y, analyzed from the 1980 to 1996, with no cancer, diabetes, or cardiovascular disease at base line, the intake of trans fatty acids was significantly related to the risk of developing type 2 diabetes. And, after adjustment for other risk factors trans fat intake was positively associated with the incidence of diabetes with a risk up to 39 percent greater.
Data from controlled intervention studies showed that TFA could impair insulin sensitivity in subjects with insulin resistance and type 2 diabetes (saturated fatty acids do the analogous response, with no significant difference between TFA and them) more than unsaturated fatty acids, in particular the isomer of conjugated linoleic acid (CLA) trans-10, cis-12-CLA.
Be careful because some dietary supplements contain CLA isomers and may be diabetogenic and proatherogenic in insulin-resistant subjects.
No significant effect was seen in insulin sensitivity of lean, healthy subjects.
Ruminant trans fatty acids and the risk of CHD
Four prospective studies have evaluated the relation between the intake of ruminant trans fatty acids and the risk of CHD: no significant association was identified.
In another study published on 2008 was analyzed data from four Danish cohort studies that cover 3,686 adults enrolled between 1974 and 1993, and followed for a median of 18 years. In Denmark, consumption of dairy products is relatively high and the range of ruminant trans fat intake is relatively broad, up to 1.1 percent of energy. Conversely, in the other countries, ruminant trans fatty acid consumption for most people is substantially lower than 1 percent of energy, in USA about 0.5 percent of energy.
After adjustment for other risk factors, no significant associations between ruminant TFA consumption and incidence of CHD were found, confirming, in a population with relatively high intake of ruminant trans fatty acids, conclusions of four previous prospective studies.
So ruminant trans fats, in amounts actually consumed in diets, do not raise CHD risk.
The absence of risk of CHD with trans fats from ruminants as compared with industrial trans fatty acids may be due to a lower intake. In the USA, greater part of trans fats have industrial origin; moreover trans fat levels in milk and meats are relatively low, 1 to 8 percent of total fats.
The absence of a higher risk of CHD may be due also to the presence of different isomers. Ruminant and industrial sources share many common isomers, but there are some quantitative difference:
vaccenic acid level is higher in ruminant fats, 30-50 percent of trans isomers;
trans-C18:2 isomers, present in deodorized and fried vegetable oils, as well as in some partially hydrogenated vegetable oils, are not present in appreciable amounts in ruminants fats.
Finally other, still unknown, potentially protective factors could outweigh harmful effects of ruminant trans fats.
Trans fatty acids: legislation regulating their content
USA
Until 1985 no adverse effects of trans fatty acids on human health was demonstrated, and in 1975 a Procter & Gamble study showed no effect of trans fats on cholesterol.
Their use in fast food preparation grew up from 1980’s, when the role of dietary saturated fats in increasing cardiac risk began clear. Then, it was led a successful campaign to get McDonald’s to switch from beef tallow to vegetable oil for frying its French fries. Meanwhile, studies began to raise concerns about their effects on health.
On 1985 Food and Drug Administration (FDA) concluded that TFA and oleic acid affected serum cholesterol level similarly, but from the second half of 1985 their harmful began clear, and the final proof came from both controlled feeding trials and prospective epidemiologic studies.
On 2003 FDA ruled that food labels, for conventional foods and supplements, show their content beginning January 1, 2006. Notably, this ruling was the first substantive change to food labeling since the requirement for per-serving food labels information was added in 1990.
On 2005 The US Department of Agriculture made a minimized intake of trans fatty acids a key recommendation of the new food-pyramid guidelines.
The American Heart Association, on 2006, recommended to limit their intake to 1% of daily calorie consumption, and suggested food manufacturers and restaurants switch to other fats.
On 2006 New York City Board of Health announced trans fat ban in its 40,000 restaurants within July 1, 2008, followed by the state of California in 2010-2011.
Australia
After June 1996 they were eliminated from margarine sold in Australia, that before contributed about 50% of their dietary intake.
Europe
On March 11, 2003 the Danish government, after a debate started in 1994 and two new reports in 2001 and 2003, decided to phase out the use of industrial trans fats in food before the end of 2003.
Two years later, however, the European Commission (EC) asked Denmark to withdraw this law, which was not accepted on the European Community level, unfortunately.
However, in 2007, EC decided to closes its infringement procedure against Denmark because of increasing scientific evidence of the danger of this type of fatty acids.
The Danish example was followed by Austria and Switzerland in 2009, Iceland, Norway, and Hungary in 2011, and most recently, Estonia and Georgia in 2014. So, about 10 percent of the European Union population, about 500 million people, lives in countries where it is illegal to sell food high in industrial trans fats.
Governments of other European Union countries instead rely on the willingness of food producers to reduce trans fatty acid content in their products. This strategy has proved effective only for Western European countries.
Canada
Canada is considering legislation to eliminate them from food supplies, and, in 2005, ruled that pre-packaged food labels show their content.
Therefore, with the exception of the countries where the use of trans fats in the food industry was banned, the only way to reduce their intake in the other countries is consumer’s decision to choose foods free in such fatty acids, avoiding those known containing them, and always reading nutrition facts and ingredients because they may come from margarine, vegetable oil and frying. Indeed, for example in the USA, the producers of foods that contain less than 0.5 g of industrial trans fatty acids per serving can list their content as 0 on the packaging. This content is low but if a consumer eats multiple servings, he consumes substantial amount of them.
Be careful: food labels are not obligatory in restaurants, bakeries, and many other retail food outlets.
Food reformulation
Public health organizations, including the World Health Organization in September 2006, have recommended reducing the consumption of industrial trans fatty acids; only in USA the near elimination of these fatty acids might avoid between 72,000 and 280,000 of the 1.2 million of CHD events every year.
Food manufacturers and restaurants may reduce industrial TFA use choosing alternatives to partially hydrogenated oils.
In Denmark, their elimination from vegetable oils did not increase consumption of saturated fatty acids because they were mostly replaced with cis-unsaturated fatty acids. Moreover, there were no noticeable effects for the consumer: neither increase in the cost nor reduction in availability and quality of foods.
In 2009, Stender et al. have shown that industrial trans fatty acids in food such as French fries, cookies, cakes, and microwave-oven popcorn purchased in USA, South Africa, and many European Country can be replaced, at similar prices, with a mixture of saturated, monounsaturated, and polyunsaturated fatty acids. Such substitution has even greater nutritional benefit than one-to-one substitution of industrial trans fats with saturated fatty acids alone.
However, be careful because only in French fries with low industrial trans fats the percentage of saturate fatty acids remains constant, whereas in cookies and cakes is in average +33 percentage points and microwave-oven popcorn +24 percentage points: saturated fatty acids are less dangerous than industrial trans fats but more than mono- and polyunsaturated fatty acids.
The same research group, analyzing some popular foods in Europe, purchased in supermarkets, even of the same supermarket chain, and fast food, namely, McDonald’s and Kentucky Fried Chicken (KFC), from 2005 to 2014, showed that their TFA content was reduced or even absent in several Western European countries while remaining high in Eastern and Southeastern Europe.
In 2010 Mozaffarian et al. evaluated the levels of industrial trans fats and saturated fatty acids in major brand-name U.S. supermarket and restaurant foods after reformulation to reduce industrial trans fatty acid content, in two time: from 1993 through 2006 and from 2008 through 2009. They found a generally reduction in industrial trans fat content without any substantial or equivalent increase in saturated fatty acid content.
Foods sources
Many foods high in trans fats are popularly consumed worldwide.
In USA greater part of these fatty acids comes from partially hydrogenated vegetable oils, with an average consumption from this source that has been constant since the 1960′s.
It should be noted that the following trans fatty acid values must be interpreted with caution because, as previously said, many fast food establishments, restaurants and industries may have changed, or had to change the type of fat used for frying and cooking since the analysis were done.
The reported values, unless otherwise specified, refer to percentage in trans fatty acids/ 100 g of fatty acids.
Margarine
Among foods with trans fats, stick or hard margarine had the highest percentage of them, but levels of these fatty acids have declined as improved technology allowed the production of softer margarines which have become popular. But there are difference in trans fatty acid content of margarine from different countries. Below some examples.
The highest content, 13-16.5 percent, is found in soft margarine from Iceland, Norway, and the UK.
Less content is found in Italy, Germany, Finland, and Greece, 5.1 percent, 4.8 percent, 3.2 percent, and 2.9 percent respectively).
In Portugal, The Netherlands, Belgium, Denmark, France, Spain, and Sweden margarine trans fat content is less than 2 percent.
USA and Canada lag behind Europe, but in the USA, with the advent of trans fat labeling of foods and the greater knowledge of the risk associated with their consumption by the buyers, change is occurring. For this reason, at now, in the USA margarine is considered to be a minor contributor to the intake of TFA, whereas the major sources are commercially baked and fast food products like cake, cookies, wafer, snack crackers, chicken nuggets, French fries or microwave-oven popcorn (see below).
Vegetable shortenings
Trans fatty acid content of vegetable shortenings ranges from 6% to 50 percent, and varies in different country: in Germany, Austria and New Zealand it is less than France or USA.
However, like margarines, their trans fat content is decreasing. In Germany it decreased from 12% in 1994 to 6 percent in 1999, in Denmark is 7 percent (1996) while in New Zealand is about 6 percent (1997).
Vegetable oils
At now, non-hydrogenated vegetable oils for salad and cooking contain no or only small amounts of trans fats.
Processing of these oils can produce minimal level of them, ranged from 0.05g/100 food for extra virgin olive oil to 2.42 g/100 g food for canola oil. So, their contribution to trans fat content of the current food supply is very little.
One exception is represented by Pakistani hydrogenated vegetable oils whose TFA content ranges from 14% to 34%.
Prepared soups
Among foods with trans fats, prepared soups contain significant amount of them, ranging from 10 percent of beef bouillon to 35 percent of onion cream. So, they contribute great amount of such fatty acids to the diet if frequently consumed.
Processed foods
Thanks to their properties, trans fatty acids are used in many processed foods as cookies, cakes, croissants, pastries and other baked goods. And, baked goods are the greatest source of these fats in the North American diet. Of course, their trans fat content depends on the type of fat used in processing.
Sauces
Mayonnaise, salad dressings and other sauces contain only small or no-amounts of trans fats.
Human milk and infant foods
Trans fat content of human milk reflects the trans fat content of maternal diet in the previous day, is comprised between 1 and 7%, and is decreasing from 7.1 percent in 1998 to 4.6 percent in 2005/2006.
Infant formulas have trans fat values on average 0.1-4.5 percent, with a brand up to 15.7 percent.
Baby foods contain greater than 5 percent of trans fats.
Fast foods and restaurant’s foods
Vegetable shortenings high in trans fats are used as frying fats, so fast foods and many restaurant’s foods may contain relatively large amounts of them. Foods are fried pies, French fries, chicken nuggets, hamburgers, fried fish as well as fried chicken.
In articles published by Stender et al. from 2006 to 2009, it is showed that for French fries and chicken nuggets their content varies largely from nation to nation, but also within the same fast food chain in the same country, and even in the same city, because of the cooking oil used. For example, oil used in USA and Peru outlets of a famous fast food chain contained 23-24% of trans fats, whereas oil used in many European countries of the same fast food chain contained about 10 percent, with some countries, such as Denmark, as low as 5 percent and 1 percent.
And, considering a meal of French fries and chicken nuggets, in serving size of 171 and 160 g respectively, purchased at McDonald‘s in New York City, it contained over 10 g of TFA, while if purchased at KFC in Hungary they were almost 25 g.
Below, again from the work of Stender et al. it can see a cross-country comparison of trans fat contents of chicken nuggets and French fries purchased at McDonald ‘s or KFC.
Chicken nuggets and French fries from McDonald’s:
less than 1 g only if the meals were purchased in Denmark;
1-5 g in Portugal, the Netherlands, Russia, Czech Republic, or Spain;
5-10 g in the United States, Peru, UK, South Africa, Poland, Finland, France, Italy, Norway, Spain, Sweden, Germany, or Hungary.
Chicken and French fries from KFC:
less than 2 g if the meals were purchased UK (Aberdeen), Denmark, Russia, or Germany (Wiesbaden);
2-5 in Germany (Hamburg), France, UK (London or Glasgow), Spain, or Portugal;
5-10 in the Bahamas, South Africa, or USA;
10-25 g in Hungary, Poland, Peru, or Czech Republic.
References
Akoh C.C. and Min D.B. Food lipids: chemistry, nutrition, and biotechnology. 3rd Edition. CRC Press Taylor & Francis Group, 2008
Ascherio A., Katan M.B., Zock P.L., Stampfer M.J., Willett W.C. Trans fatty acids and coronary heart disease. N Engl J Med 1999;340:1994-1998. doi:10.1056/NEJM199906243402511
Ascherio A., Rimm E.B., Giovannucci E.L., Spiegelman D., Stampfer M., Willett W.C. Dietary fat and risk of coronary heart disease in men: cohort follow up study in the United States. BMJ 1996; 313:84-90. doi:10.1080/17482970601069094
Asp N-G. Fatty acids in focus – the good and the bad ones. Scand J Food Nutr 2006;50:155-160. doi:10.1080/17482970601069094
Baylin A., Kabagambe E.K., Ascherio A., Spiegelman D., Campos H. High 18:2 trans-fatty acids in adipose tissue are associated with increased risk of nonfatal acute myocardial infarction in Costa Rican adults. J Nutr 2003;133:1186-1191. doi:10.1093/jn/133.4.1186
Chow C.K. Fatty acids in foods and their health implication. 3rd Edition. CRC Press Taylor & Francis Group, 2008.
Clifton P.M., Keogh J.B., Noakes M. Trans fatty acids in adipose tissue and the food supply are associated with myocardial infarction. J Nutr 2004;134:874-879. doi:10.1093/jn/134.4.874
Costa N., Cruz R., Graça P., Breda J., and Casal S. Trans fatty acids in the Portuguese food market. Food Control 2016;64:128-134. doi:10.1016/j.foodcont.2015.12.010
Eckel R.H., Borra S., Lichtenstein A.H., Yin-Piazza D.Y. Understanding the Complexity of Trans fatty acid reduction in the American diet. American Heart Association trans fat conference 2006 report of the trans fat conference planning group. Circulation 2007;115:2231-2246. doi:10.1161/CIRCULATIONAHA.106.181947
Hu F.B., Manson J.E., Stampfer M.J., Colditz G., Liu S., Solomon C.G., and Willett W.C. Diet, lifestyle, and the risk of type 2 diabetes mellitus in women. N Engl J Med 2001;345:790-797. doi:10.1056/NEJMoa010492
Hu F.B., Willett W.C. Optimal diet for prevention of coronary heart disease JAMA 2002;288:2569-2578. doi:10.1001/jama.288.20.2569
Lemaitre R.N., King I.B., Raghunathan T.E., Pearce R.M., Weinmann S., Knopp R.H., Copass M.K., Cobb L.A., Siscovick D.S. Cell membrane trans-fatty acids and the risk of primary cardiac arrest. Circulation 2002;105:697-701. doi:10.1161/hc0602.103583
Lemaitre R.N, King I.B, Mozaffarian D., Sootodehnia N., Siscovick D.S. Trans-fatty acids and sudden cardiac death. Atheroscler Suppl 2006; 7(2):13-5. doi:10.1016/j.atherosclerosissup.2006.04.003
Lichtenstein A.H. Dietary fat, carbohydrate, and protein: effects on plasma lipoprotein patterns J. Lipid Res. 2006;47:1661-1667. doi:10.1194/jlr.R600019-JLR200
Lichtenstein A.H., Ausman L., Jalbert S.M., Schaefer E.J. Effect of different forms of dietary hydrogenated fats on serum lipoprotein cholesterol levels. N Engl J Med 1999;340:1933-1940. doi:10.1056/NEJM199906243402501
Lopez-Garcia E., Schulze M.B., Meigs J.B., Manson J.E, Rifai N., Stampfer M.J., Willett W.C. and Hu F.B. Consumption of trans fatty acids is related to plasma biomarkers of inflammation and endothelial dysfunction. J Nutr 2005;135:562-566. doi:10.1093/jn/135.3.562
Masanori S. Trans Fatty Acids: Properties, Benefits and Risks J Health Sci 2002;48(1):7-13.
Mensink R.P., Katan M.B. Effect of dietary trans fatty acids on high-density and low-density lipoprotein cholesterol levels in healthy subjects. N Engl J Med 1990;323:439-445. doi:10.1056/NEJM199008163230703
Mozaffarian D. Commentary: Ruminant trans fatty acids and coronary heart disease-cause for concern? Int J Epidemiol 2008;37(1):182-184. doi:10.1093/ije/dym263
Mozaffarian D., Jacobson M.F., Greenstein J.S. Food Reformulations to reduce trans fatty acids. N Eng J Med 2010;362:2037-2039. doi:https://doi.org/10.1056/NEJMc1001841
Mozaffarian D., Katan M.B., Ascherio A., Stampfer M.J., Willett W.C. Trans fatty acids and cardiovascular disease. N Engl J Med 2006;354:1601-1613. doi:10.1056/NEJMra054035
Mozaffarian D., Pischon T., Hankinson S.E., Joshipura K., Willett W.C., and Rimm E.B. Dietary intake of trans fatty acids and systemic inflammation in women. Am J Clin Nutr 2004;79:606-612. doi:https://doi.org/10.1093/ajcn/79.4.606
Oh K., Hu F.B., Manson J.E., Stampfer M.J., Willett W.C. Dietary fat intake and risk of coronary heart disease in women: 20 years of follow-up of the Nurses’ Health Study. Am J Epidemiol 2005;161(7):672-679. doi:10.1093/aje/kwi085
Okie S. New York to Trans Fats: You’re Out! N Engl J Med 2007;356:2017-2021. doi:10.1056/NEJMp078058
Oomen C.M., Ocke M.C., Feskens E.J., van Erp-Baart M.A., Kok F.J., Kromhout D. Association between trans fatty acid intake and 10-year risk of coronary heart disease in the Zutphen Elderly Study: a prospective population-based study. Lancet 2001; 357(9258):746-751. doi:10.1016/S0140-6736(00)04166-0
Pietinen P., Ascherio A., Korhonen P., Hartman A.M., Willett W.C., Albanes D., VirtamO J.. Intake of fatty acids and risk of coronary heart disease in a cohort of Finnish men: the Alpha-Tocopherol, Beta-Carotene Cancer Prevention Study. Am J Epidemiol 1997;145(10):876-887. doi:10.1093/oxfordjournals.aje.a009047
Risérus U. Trans fatty acids, insulin sensitivity and type 2 diabetes. Scand J Food Nutr 2006;50(4):161-165. doi:10.1080/17482970601133114
Salmerón J., Hu F.B., Manson J.E., Stampfer M.J., Colditz G.A., Rimm E.B., and Willett W.C. Dietary fat intake and risk of type 2 diabetes in women. Am J Clin Nutr 2001;73:1019-1026 doi:10.1093/ajcn/73.6.1019
Stender S., Astrup A., and Dyerberg J. A trans European Union difference in the decline in trans fatty acids in popular foods: a market basket investigation. BMJ Open 2012;2(5):e000859. doi:10.1136/bmjopen-2012-000859
Stender S., Astrup A., and Dyerberg J. Artificial trans fat in popular foods in 2012 and in 2014: a market basket investigation in six European countries. BMJ Open 2016;6(3):e010673. doi:10.1136/bmjopen-2015-010673
Stender S., Astrup A.,and Dyerberg J. Tracing artificial trans fat in popular foods in Europe: a market basket investigation. BMJ Open 2014;4(5):e005218. doi:10.1136/bmjopen-2014-005218
Stender S., Astrup A., Dyerberg J. What went in when trans went out?. N Engl J Med 2009;361:314-316. doi:10.1056/NEJMc0903380
Stender S., Dyerberg J. The influence of trans fatty acids on health. Fourth edition. The Danish Nutrition Council; publ. no. 34, 2003.
Stender S., Dyerberg J., Astrup A. Consumer protection through a legislative ban on industrially produced trans fatty acids in Denmark. Scand J Food Nutr 2006;50(4):155-160. doi:10.1080/17482970601069458
Stender S., Dyerberg J., Astrup A. High levels of trans fat in popular fast foods. N Engl J Med 2006;354:1650-1652. doi:10.1056/NEJMc052959
Willett W., Mozaffarian D. Ruminant or industrial sources of trans fatty acids: public health issue or food label skirmish? Am J Clin Nutr 2008;87(3): 515-516. doi:10.1093/ajcn/87.3.515
Black tea, like the other types of tea, is an infusion of dried and processed leaves of Camellia sinensis, a shrub belonging to the Theaceae family.
Unlike what happens during green tea production, during black tea production the almost complete oxidation of the substances contained in the leaves occurs, particularly catechins, polyphenols of the flavonoid group.
The color of the processed leaves is dark, whereas the beverage is brown-red in color.
Black tea is prepared with one tea bag per person, or one teaspoon per person in case of loose tea leaves, with an infusion time of 3-4 minutes in water at 95-100 °C.
Tea is a beverage with ancient origins, dating back to almost 4,000 years ago. It is one of the most-consumed beverages, particularly in Asia, where the favorite tea is green tea, especially in Japan and China, whereas black tea is preferred by Western populations and at global level, accounting for about 78 percent of the tea consumed.
The oxidation of the compounds present in the leaves during processing reduces the potential beneficial effects ascribed to the polyphenols initially present.
All the types of teas are produced from fresh leaves of Camellia sinensis. During harvesting, young leaves are preferred, as the older ones are considered inferior in quality.
The processing that leads to the production of loose dried tea leaves ready for brewing black tea proceeds through four steps: withering, rolling, oxidation, and drying. Such processing leads to the near complete oxidation of the substances present, particularly catechins.
Withering is the process by which the water present in the leaves, about 75 percent of the leaf’s weight, is removed, thus causing sap concentration. Withering, which makes the next step easier, can be achieved in three different ways:
by exposing leaves to sunlight;
by appropriately heating the rooms where the leaves are stored;
by machineries that ventilate the leaves.
The rolling step follows the withering of the leaves, and, breaking the leaf tissues, facilitates the outflow of lymph thus promoting the subsequent oxidation of polyphenols.
The oxidation step is also improperly called fermentation. In this step, the oxidation by atmospheric oxygen and polyphenol oxidase (EC 1.10.3.1) of 90-95 percent of the polyphenols occurs, accompanied by other changes that color the leaves with a red color. Temperature, typically 25°C, pH, relative humidity, 95 percent or more, ventilation, and duration are crucial factors, too. This step is crucial in determining the quality of the tea, as it gives it its organoleptic characteristics and composition in polyphenols, quite different from those of green tea, which is produced in such a way as to minimize oxidation processes.
Note that caffeine content does not vary significantly.
Drying is the last step. It is carried out at a temperature of 80-90 °C for about 20-25 minutes. The high temperature inactivates polyphenol oxidase, and then stops enzymatic oxidation processes.
Thearubigins and theaflavins
The oxidative processes that occur during black tea production affect monomeric and gallate catechins, to a lesser extent catechins glycosides, especially myricetin, and non-flavonoid compounds, such as teagallin, and leads to the formation of complex polyphenols such as thearubigins, theaflavins and theaflavic acids.
Thearubigins, brownish in color, are polymers of catechins not yet well characterized and the major polyphenols in black tea, accounting for about 20 percent of the dry leaf weight. They contribute to the richness in taste and color.
Theaflavins, red-orange in color, are dimers of catechins and account for about 3-5 percent of the dry leaf weight. They contribute to the astringent and brisk taste, as well as the red-orange in color.
The main theaflavins are:
theaflavin 3-gallate;
theaflavin 3′-gallate;
theaflavin 3,3’-digallate, the most abundant.
Theaflavins
Health benefits
The health benefits of black tea are largely due to its complex polyphenols, thearubigins and theaflavins, being catechins largely oxidized during leaf processing.
Here are three examples.
Theaflavins have been highlighted as having antiviral activity which, similarly to catechins, appears to be particularly effective against positive single-stranded RNA viruses. These viruses also include SARS-CoV-1 and SARS-CoV-2, viruses belonging to the Coronaviridae family.
Like catechins, the galloyl groups appear to be important for the antiviral activity of theaflavins.
The phytochemicals present in black tea, like those in green tea, seem to be able to reduce the glycemic index of starchy foods. The effect appears to be due to the inhibition of the activity of pancreatic alpha-amylase and other digestive enzymes, and to the direct interaction with starch, that would reduce the surface available to enzyme activity. The inhibition is greater on gluten free foods; this seems to be due to the action of gluten on complex polyphenols that would not be able to interact with the polysaccharide. For more information, see the article on tea polyphenols.
Thearubigins and theaflavins seem to have anticariogenic effects due to the inhibitory action on salivary and bacterial amylase, and seem to be more effective than green tea catechins.
Moreover, black tea seems to be able to inhibit acid production in the oral cavity.
References
Asil M.H., Rabiei B., Ansari R.H. Optimal fermentation time and temperature to improve biochemical composition and sensory characteristics of black tea. Aust J Crop Sci 2012;6(3):550-8.
Kan L., Capuano E., Fogliano V., Oliviero T. and Verkerk R. Tea polyphenols as a strategy to control starch digestion in bread: the effects of polyphenol type and gluten. Food Funct 2020;11:5933-5943. doi:10.1039/D0FO01145B
Kuhnert N. Unraveling the structure of the black tea thearubigins. Arch Biochem Biophys 2010;501(1):37-51. doi:10.1016/j.abb.2010.04.013
Li S., Lo C-Y., Pan M-H., Lai C-S. and Ho C-T. Black tea: chemical analysis and stability. Food Funct 2013;4:10-18. doi:10.1039/C2FO30093A
Mhatre S., Srivastava T., Naik S., Patravale V. Antiviral activity of green tea and black tea polyphenols in prophylaxis and treatment of COVID-19: a review. Phytomedicine 2020;153286. doi:10.1016/j.phymed.2020.153286
Menet M-C., Sang S., Yang C.S., Ho C-T., and Rosen R.T. Analysis of theaflavins and thearubigins from black tea extract by MALDI-TOF mass spectrometry. J Agric Food Chem 2004;52:2455-61. doi:10.1021/jf035427e
Sharma V.K., Bhattacharya A., Kumar A. and Sharma H.K. Health benefits of tea consumption. Trop J Pharm Res 2007;6(3):785-792.
Green tea, like the other types of tea, is an infusion of dried and processed leaves of Camellia sinensis, a member of the Theaceae family.
The processing of the leaves leading to the product ready for use is such as to minimize the oxidation of the compounds contained in them, particularly phytochemicals such as catechins, which are polyphenols belonging to the class of flavonoids and the most responsible for the health benefits of green tea.
Having undergone no significant chemical modifications, leaves retain green color, whereas the beverage, prepared with one tea bag per person, or in case of loose tea, one teaspoon per person, for an infusion time of about 3 minutes in water at 75 °C, is golden yellow in color.
Some organoleptic properties of green tea, such as the flavor, that is more delicate and lighter than that of black tea, and the health properties, which have always been recognized in East Asia cultures, depend on leaf processing.
Only recently scientists started studying the health benefits of tea consumption, highlighting its role in preventing many diseases, such as cardiovascular diseases and some types of cancer.
It has been shown that tea polyphenols, particularly catechins, are able to activate intracellular signaling pathways by binding to membrane receptors and/or entering the cell and binding to cytoplasmic, mitochondrial or nuclear receptors. Then, depending on the cell type, they activate or inhibit some cellular processes.
Given the high consumption of tea in the world, even small effects on health could have significant effects on public health.
Camellia sinensis is an evergreen plant native to South, East, and Southeast Asia, which is now cultivated in at least 30 countries, mostly in tropical or subtropical climates, although some varieties grow in Cornwall and Washington State.
In nature, Camellia sinensis can grow up to 15-20 meters (49-65 ft), whereas in plantations it is pruned to less than 1,5 meters to facilitate leaf harvesting.
It can grow up to altitude of 1,500-2,000 meters (4,900-6,550 ft), and many of the high-quality teas are produced from such crops, as the plant grows slowly and the leaves acquire a better flavor.
The most cultivated varieties, of the four known, are Camellia sinensis var. sinensis, native to China, and Camellia sinensis var. assamica, native to India.
The different types of tea are produced from fresh leaves. Young leaves are preferred over older leaves that are considered to be inferior in quality.
Fresh leaves are rich in water-soluble polyphenols, especially catechins and glycosylated catechins. The major catechins in green tea are epigallocatechin-3-gallate or EGCG, the most active, epigallocatechin, epicatechin 3-gallate, epicatechin. Catechin, gallocatechin, catechin gallate, and gallocatechin gallate are also present, although in lower amount.
Gallocatechin gallate
These polyphenols account for 30-42 percent of the dry leaf weight. Caffeine accounts for 1,5-4,5 percent of the dry leaf weight.
In addition to leaf processing, the organoleptic properties of the beverage are influenced by cultivar, characteristics of the soil where the plant grown up, methods of cultivation, altitude, climate, and time of year in which leaf harvest occurs.
How green tea is made
The differences in leaf processing, which lead to the different types of tea ready for consumption, cause different degrees of oxidation of the compounds present in them, especially catechins.
During green tea manufacturing, oxidative processes, both enzymatic and chemical, are minimized.
After harvesting, leaves are exposed to sunlight for 2-3 hours and withered/dried. Then, the processing proceeds through three steps:
heat treatment;
rolling;
drying.
Heat treatment, short and gentle, is crucial for the quality and properties of the beverage. It can done either with a steam, the traditional Japanese method, or by dry cooking in hot pans, that is similar to a roasting method and is the traditional Chinese method. Heat treatment inactivates enzymes and then prevents the enzymatic oxidation processes, particularly those involving polyphenols. It also removes the grassy smell, and evaporates, in the case of the traditional Chinese method, part of the water of the leaf, which constitutes about 75 percent of its weight, making it softer, thus facilitating the next step.
Heat treatment is followed by the rolling step, that facilitates the subsequent drying step and, destroying the leaf tissue, favors the release of aromas, thus improving the quality of the product.
The drying, the last step, improves the appearance of beverage and leads to the production of new compounds.
Health benefits
In East Asia cultures, mainly in China and Japan, tea drinking has always been associated with health benefits. Below is a brief review of the results of epidemiological and laboratory studies that have analyzed the effects that green tea consumption can play in preventing many diseases. EGCG, which is the most abundant catechin in green tea accounting for about 60 percent of the polyphenols present in dried leaves, seems to play the main role.
At the molecular level, the galloyl groups at positions 3 and/or 3′ appear to be essential for many of the effects exerted by catechins.
Cardiovascular disease
Cardiovascular disease is the main cause of deaths worldwide, particularly in low- and middle-income countries, with an estimate of about 17 million deaths in 2008 that could increase up to 23.3 million by 2030.
Daily tea consumption, especially green tea, seems to be associated with a reduced risk of developing cardiovascular disease, such as hypertension and stroke.
Among the proposed mechanisms, the improved bioactivity of the endothelium-derived vasodilator nitric oxide, due to the action of tea polyphenols that could enhance nitric oxide synthesis and/or decrease its breakdown by superoxide anions, seem to be important.
Cancer
Several epidemiological and laboratory studies have shown encouraging results with respect to the preventive role of tea consumption, especially green tea, against the development of some cancers such as those of the oral cavity, digestive tract, and lung among those who have never smoked.
Tea polyphenols seem to act not only as antioxidants, but also as compounds that, directly, can influence gene expression and various metabolic pathways.
Antiviral activity
Recent studies have highlighted antiviral effects of catechins, particularly EGCG of green tea and theaflavins of black tea, especially against positive single-stranded RNA viruses, to which the Coronaviridae family, and then SARS-CoV-1 and SARS-CoV-2, belongs.
The antiviral properties of EGCG appear to be due to its structural characteristics, namely, the presence of pyrogallic and galloyl groups.
Starch digestion
In vitro studies have shown that green tea and black tea polyphenols can reduce the glycemic index of starchy foods. Hence, they could be useful in controlling their glycemic index in vivo. This effect seems to be due to the inhibition of pancreatic alpha-amylase and other digestive enzymes, and to a direct interaction between starch and phytochemicals that would reduce the surface area of starch granules available for enzyme activity. Green tea appears to be equally effective against both gluten-containing foods, against which black tea appears less effective, and gluten free foods.
Weight loss
During weight loss and weight-loss maintenance it is important to keep as constant as possible the daily energy expenditure.
Since the 90s, it has been proposed that green tea, by virtue of its content of caffeine and catechins could be of help for:
maintaining, or even increasing, daily energy expenditure;
increasing fat oxidation.
In addition to these potential lipolytic and thermogenic effects, catechins and caffeine could act on other targets, such as lipid absorption and energy intake, perhaps through their effect on gut microbiota, which is part of the larger human microbiota, and gene expression.
And products for weight loss and weight maintenance based on green tea extracts have been marketed. It should be noted that these products contain catechins and caffeine in much higher amount than beverage.
How much truth is there in green tea’s fat burning effect?
The issue seems to have been resolved by a meta-analysis of 15 studies on weight loss and intake of these products. The study showed that green tea-based products induces, in overweight and obese adults, a weight loss that is:
not statistically significant;
very small;
probably not clinically important.
Hence, on the basis of scientific evidence, green tea does not seem to be helpful in fat loss nor in weight maintenance.
Anticariogenic activity
Animal and in vitro studies have shown that tea, and particularly its polyphenols, seem to possess:
antibacterial activity against cariogenic bacteria, such as Streptococcus mutans, as in the case of green tea EGCG;
inhibitory action on salivary and bacterial amylase, in which black tea thearubigins and theaflavins are more effective than green tea catechins;
inhibitory action on acid production in the oral cavity.
All these properties make green tea and black tea beverages with potential anticariogenic activity.
References
Arab L., Khan F., and Lam H. Tea consumption and cardiovascular disease risk. Am J Clin Nutr 2013;98:1651S-1659S. doi:10.3945/ajcn.113.059345
Clifford M.N., van der Hooft J.J.J., and Crozier A. Human studies on the absorption, distribution, metabolism, and excretion of tea polyphenols. Am J Clin Nutr 2013;98:1619S-1630S. doi:10.3945/ajcn.113.058958
Dwyer J.T. and Peterson J. Tea and flavonoids: where we are, where to go next. Am J Clin Nutr 2013;98:1611S-1618S. doi:10.3945/ajcn.113.059584
Goenka P., Sarawgi A., Karun V., Nigam A.G., Dutta S., Marwah N. Camellia sinensis (Tea): implications and role in preventing dental decay. Phcog Rev 2013;7:152-156. doi:10.4103/0973-7847.120515
Green R.J., Murphy A.S., Schulz B., Watkins B.A. and Ferruzzi M.G. Common tea formulations modulate in vitro digestive recovery of green tea catechins. Mol Nutr Food Res 2007;51(9):1152-1162. doi:10.1002/mnfr.200700086
Grassi D., Desideri G., Di Giosia P., De Feo M., Fellini E., Cheli P., Ferri L., and Ferri C. Tea, flavonoids, and cardiovascular health: endothelial protection. Am J Clin Nutr 2013;98:1660S-1666S. doi:10.3945/ajcn.113.058313
Huang W-Y., Lin Y-R., Ho R-F., Liu H-Y., and Lin Y-S. Effects of water solutions on extracting green tea leaves. Sci World J 2013;Article ID 368350. doi:10.1155/2013/368350
Hursel R. and Westerterp-Plantenga M.S. Catechin- and caffeine-rich teas for control of body weight in humans. Am J Clin Nutr 2013;98:1682S-1693S. doi:10.3945/ajcn.113.058396
Hursel R., Viechtbauer W. and Westerterp-Plantenga M.S. The effects of green tea on weight loss and weight maintenance: a meta-analysis. Int J Obesity 2009;33:956-961. doi:10.1038/ijo.2009.135
Jurgens T.M., Whelan A.M., Killian L., Doucette S., Kirk S., Foy E. Green tea for weight loss and weight maintenance in overweight or obese adults. Editorial group: Cochrane Metabolic and Endocrine Disorders Group. 2012:12 Art. No.: CD008650. doi:10.1002/14651858.CD008650.pub2
Lambert J.D. Does tea prevent cancer? Evidence from laboratory and human intervention studies. Am J Clin Nutr 2013;98:1667S-1675S. doi:10.3945/ajcn.113.059352
Lorenz M. Cellular targets for the beneficial actions of tea polyphenols. Am J Clin Nutr 2013;98:1642S-1650S. doi:10.3945/ajcn.113.058230
Mathur A., Gopalakrishnan D., Mehta V., Rizwan S.A., Shetiya S.H., Bagwe S. Efficacy of green tea-based mouthwashes on dental plaque and gingival inflammation: a systematic review and meta-analysis. Indian J Dent Res 2018;29(2):225-232. doi:10.4103/ijdr.IJDR_493_17
Mhatre S., Srivastava T., Naik S., Patravale V. Antiviral activity of green tea and black tea polyphenols in prophylaxis and treatment of COVID-19: a review. Phytomedicine 2020;153286. doi:10.1016/j.phymed.2020.153286
Sharma V.K., Bhattacharya A., Kumar A. and Sharma H.K. Health benefits of tea consumption. Trop J Pharm Res 2007;6(3):785-792.
Yang Y-C., Lu F-H., Wu J-S., Wu C-H., Chang C-J. The protective effect of habitual tea consumption on hypertension. Arch Intern Med 2004;164:1534-1540. doi:10.1001/archinte.164.14.1534
Yuan J-M. Cancer prevention by green tea: evidence from epidemiologic studies. Am J Clin Nutr 2013;98:1676S-1681S. doi:10.3945/ajcn.113.058271
Xu J., Xu Z., Zheng W. A review of the antiviral role of green tea catechins. Molecules 2017;22(8):1337. doi:10.3390/molecules22081337
Together with catechins and proanthocyanidins, anthocyanins and their oxidation products are the most abundant flavonoids in the human diet.
Examples of anthocyanin rich foods are:
certain varieties of grains, such as some types of pigmented rice (e.g. black rice) and maize (purple corn);
in certain varieties of root and leafy vegetables such as aubergine, red cabbage, red onions and radishes, beans;
but especially in red fruits.
Anthocyanins are also present in red wine; as the wine ages, they are transformed into various complex molecules.
Anthocyanin content in vegetables and fruits is generally proportional to their color: it increases during maturation, and it reaches values up to 4 g/kg fresh weight (FW) in cranberries and black currants.
These polyphenols are found primarily in the skin, except for some red fruits, such as cherries and red berries, e.g. strawberries, in which they are present both in the skin and flesh.
Glycosides of cyanidin are the most common anthocyanins in foods.
Berries are the main source of anthocyanins, with values ranging between 67 and 950 mg/100 g FW.
Other fruits, such as red grapes, cherries and plums, have content ranging between 2 and 150 mg/100 g FW.
Finally, in fruits such as nectarines, peaches, and some types of apples and pears, anthocyanins are poorly present, with a content of less than 10 mg/100 g FW.
Cranberries, besides their very high content of anthocyanins, are one of the rare food that contain glycosides of the six most commonly anthocyanidins present in foods: pelargonidin, delphinidin, cyanidin, petunidin, peonidin, and malvidin. The main anthocyanins are the 3-O-arabinosides and 3-O-galactosides of peonidin and cyanidin. A total of 13 anthocyanins have been detected, mainly 3-O-monoglycosides.
Anthocyanin absorption
Until recently, it was believed that anthocyanins, together with proanthocyanidins and gallic acid ester derivatives of catechins, were the least well-absorbed polyphenols, with a time of appearance in the plasma consistent with the absorption in the stomach and small intestine. Indeed, some studies have shown that their bioavailability has been underestimated since, probably, all of their metabolites have not been yet identified.
In this regard, it should be underlined that only a small part of the food anthocyanins is absorbed in their glycated forms or as hydrolysis products in which the sugar moiety has been removed.
Therefore, a large amount of these ingested polyphenols enters the colon, where they can also suffer methylation, sulphatation, glucuronidation and oxidation reactions.
Anthocyanins and colonic microbiota
Few studies have examined the metabolism of anthocyanins by the gut microbiota in the colon, which is part of the larger human microbiota.
Within two hours, it seems that all the anthocyanins lose their sugar moieties, thus producing anthocyanidins.
Anthocyanidins are chemically unstable in the neutral pH of the colon. They can be metabolized by colonic microbiota or chemically degraded producing a set of new molecules that have not yet fully identified, but which include phenolic acids such as gallic acid, syringic acid, protocatechuic acid, vanillic acid and phloroglucinol or 1,3,5-trihydroxybenzene. These molecules, thanks to their higher microbial and chemical stability, might be the main responsible for the antioxidant activities and the other physiological effects that have been observed in vivo and attributed to anthocyanins.
References
de la Rosa L.A., Alvarez-Parrilla E., Gonzàlez-Aguilar G.A. Fruit and vegetable phytochemicals: chemistry, nutritional value, and stability. 1th Edition. Wiley J. & Sons, Inc., Publication, 2010
de Pascual-Teresa S., Moreno D.A. and García-Viguera C. Flavanols and anthocyanins in cardiovascular health: a review of current evidence. Int J Mol Sci 2010;11:1679-1703. doi:10.3390/ijms11041679
Escribano-Bailòn M.T., Santos-Buelga C., Rivas-Gonzalo J.C. Anthocyanins in cereals. J Chromatogr A 2004:1054;129-141. doi:10.1016/j.chroma.2004.08.152
Han X., Shen T. and Lou H. Dietary polyphenols and their biological significance. Int J Mol Sci 2007;9:950-988. doi:10.3390/i8090950
Manach C., Scalbert A., Morand C., Rémésy C., and Jime´nez L. Polyphenols: food sources and bioavailability. Am J Clin Nutr 2004;79(5):727-747. doi:10.1093/ajcn/79.5.727
Tsao R. Chemistry and biochemistry of dietary polyphenols. Nutrients 2010;2:1231-1246. doi:10.3390/nu2121231
The leaves of the tea plant, Camellia sinensis, are rich in compounds with many biological activities, ranging from preventing the development of chronic diseases to reducing the glycemic index of starchy foods.
More than 4000 different molecules have been found in the beverage, of which about one third of these are polyphenols, the most important phytochemicals in determining the nutritional values and health benefits of the tea.
Tea polyphenols are mostly flavonoids. Examples are catechins in green tea, among which epigallocatechin-3-gallate or EGCG is the most important and abundant, and thearubigins and theaflavins in black tea. Their galloyl groups at positions 3 and/or 3′ appear to be particularly important for their effects.
Epigallocatechin Gallate
Other bioactive compounds present in tea leaves are:
alkaloids, such as caffeine, theophylline and theobromine;
amino acids, and among them, theanine or R-glutamylethylamide, that is also a brain neurotransmitter and one of the most important amino acids in green tea;
Polyphenols, both in vivo and in vitro, have a broad spectrum of biological activities, such as:
antioxidant and prooxidant properties;
a protective role against the development of diabetes, hyperlipidemia, and various types of tumors;
inhibition of inflammation;
antiviral activities;
anticariogenic activity.
Hence, there has been a growing interest in recent years toward the possible preventive effects of tea against many diseases, particularly cardiovascular disease, for example in the development and progression of atherosclerosis.
Mechanisms of action
Currently, knowledge is accumulating on the effects of tea polyphenols at cellular and molecular level.
It seems, at least in vitro, that catechins, and theaflavins and thearubigins are the compounds responsible for the physiological effects and health benefits of green tea and black tea, respectively.
Among the molecular mechanisms by which tea polyphenols seem to exert their effects, it has been observed, after binding to specific cell membrane receptors, a change in the activity of various protein kinases that then phosphorylate target proteins, such as transcription factors, that, in turn, translocate into the nucleus and modify the gene expression. This appears to be the mechanism of action of EGCG, and the mechanism proposed for thearubigins, polymeric polyphenols that, due to their large dimensions, may not be able to cross the plasma membrane.
In addition, some polyphenols could be able to cross the plasma membrane, then binding to specific cytoplasmic, mitochondrial or nuclear targets.
And, depending on the cell type and their amount, tea polyphenols can activate or inhibit certain cellular processes.
Starch digestion
Tea polyphenols exert an inhibitory effect on starch digestion. In vitro studies have shown that green tea extracts, which contain monomeric polyphenols, have an equal inhibitory effect on starch digestibility of wheat bread and gluten free bread, whereas black tea extracts, rich in tannins, namely, polymeric polyphenols, are less effective against wheat bread. Therefore, it seems that the inhibitory effect of tannins is negatively influenced by gluten, whereas gluten has a lower inhibitory effect on monomeric polyphenols.
The inhibitory effect of these phytochemicals has been attributed to various molecular mechanisms briefly described below.
A competitive inhibition on pancreatic alpha-amylase. The galloyl groups are thought to be important for this effect.
The inhibition of other digestive enzymes present in the gastrointestinal tract.
The direct interaction with starch. Tea polyphenols can interact with starch granules through hydrogen bonds and hydrophobic forces, thus reducing the available surface to react with digestive enzymes.
Conversely, gluten could reduce the amount of polyphenols able to interact with starch and therefore able to inhibit its digestion.
Tea polyphenols could represent a means for controlling the glycemic index of starchy foods. However, it should be emphasized that, for example in the case of bread, to achieve an inhibitory effect, 100 g of bread must be co-digested with 2.5 cups of green tea or 2 cups of black tea.
References
Arab L., Khan F., and Lam H. Tea consumption and cardiovascular disease risk. Am J Clin Nutr 2013;98:1651S-1659S. doi:10.3945/ajcn.113.059345
Dwyer J.T. and Peterson J. Tea and flavonoids: where we are, where to go next. Am J Clin Nutr 2013;98:1611S-1618S. doi:10.3945/ajcn.113.059584
Grassi D., Desideri G., Di Giosia P., De Feo M., Fellini E., Cheli P., Ferri L., and Ferri C. Tea, flavonoids, and cardiovascular health: endothelial protection. Am J Clin Nutr 2013;98:1660S-1666S. doi:10.3945/ajcn.113.058313
Kan L., Capuano E., Fogliano V., Oliviero T. and Verkerk R. Tea polyphenols as a strategy to control starch digestion in bread: the effects of polyphenol type and gluten. Food Funct 2020;11:5933-5943. doi: 10.1039/D0FO01145B
Lambert J.D. Does tea prevent cancer? Evidence from laboratory and human intervention studies. Am J Clin Nutr 2013;98:1667S-1675S. doi:10.3945/ajcn.113.059352
Lenore Arab L., Khan F., and Lam H. Tea consumption and cardiovascular disease risk. Am J Clin Nutr 2013;98:1651S-1659S. doi:10.3945/ajcn.113.059345
Lorenz M. Cellular targets for the beneficial actions of tea polyphenols. Am J Clin Nutr 2013;98:1642S-1650S. doi:10.3945/ajcn.113.058230
Mathur A., Gopalakrishnan D., Mehta V., Rizwan S.A., Shetiya S.H., Bagwe S. Efficacy of green tea-based mouthwashes on dental plaque and gingival inflammation: a systematic review and meta-analysis. Indian J Dent Res 2018;29(2):225-232. doi:10.4103/ijdr.IJDR_493_17
Mhatre S., Srivastava T., Naik S., Patravale V. Antiviral activity of green tea and black tea polyphenols in prophylaxis and treatment of COVID-19: a review. Phytomedicine 2020;153286. doi:10.1016/j.phymed.2020.153286
Sharma V.K., Bhattacharya A., Kumar A. and Sharma H.K. Health benefits of tea consumption. Trop J Pharm Res 2007;6(3):785-792.
Yuan J-M. Cancer prevention by green tea: evidence from epidemiologic studies. Am J Clin Nutr 2013;98:1676S-1681S. doi:10.3945/ajcn.113.058271
Xu J., Xu Z., Zheng W. A review of the antiviral role of green tea catechins. Molecules 2017;22(8):1337. doi:10.3390/molecules22081337
Isoflavones are colorless polyphenols belonging to the flavonoid family.
Unlike the majority of the other flavonoids, they have a restricted taxonomic distribution, being present almost exclusively in the Leguminosae or Fabaceae plant family, mainly in soy.
Since legumes, soy in primis, are a major part of the diet in many cultures, these flavonoids may have a great impact on human health.
They are also present in beans and broad beans, but in much lower concentrations than those found in soy and soy products.
Also red clover or meadow clover (Trifolium pratense), another member of Leguminosae family, is a good source.
Currently, they are not found in fruits and vegetables.
Together with phenolic acids, such as caffeic acid and gallic acid, and quercetin glycosides, they are the most well-absorbed polyphenols, followed by flavanones and catechins,but not gallocatechins.
In plants, some isoflavones have antimicrobial activity and are synthesized in response to attacks by bacteria or fungi; thus they act as phytoalexins.
While most flavonoids have B ring attached to position 2 of C ring, isoflavones have B ring attached to position 3 of C ring.
Basic Skeleton of Isoflavones
Even if they are not steroids, they have structural similarities to estrogens, particularly estradiol. This confers them pseudohormonal properties, such as the ability to bind estrogen receptors; therefore, they are classified as phytoestrogens or plant estrogens. The benefits often ascribed to soy and soy products, for example tofu, are believed to result from the ability of isoflavones to act as estrogen mimics .
It should be underlined that the binding to estrogen receptors seems to lose strength with time, therefore their potential efficacy should not be overestimated.
In foods, they are present in four forms:
aglycone;
7-O-glucoside;
6′-O-acetyl-7-O-glucoside;
6′-O-malonyl-7-O-glucoside.
Soy isoflavones: genistein, daidzein and glycitein
Soy and soy products, such as soy milk, tofu, tempeh and miso, are the main source of isoflavones in the human diet.
The isoflavone content of soy and soy products varies greatly as a function of growing conditions, geographic zone, and processing; for example, in soy it ranges between 580 and 3800mg/kg fresh weight, while in soy milk it range between 30 and 175 mg/L.
The most abundant isoflavones in soy and soy products are genistein, daidzein and glycitein, generally present in a concentration ratio of 1:1:0,2. Biochanin A and formononetin are other isoflavones present in less concentrations.
Isoflavones
The 6′-O-malonyl derivatives have a bitter, unpleasant, and astringent taste; therefore they give a bad flavor to the food in which they are contained. However, being sensitive to temperature, they are often hydrolyzed to glycosides during processing, such as the production of soy milk.
The fermentation processes needed for the preparation of certain foods, such as tempeh and miso, determines in turn the hydrolysis of glycosides to aglycones, i.e. the sugar-free molecule.
Isoflavone glycosides present in soy and soy products can also be deglycosylated by β-glucosidases in the small intestine.
The aglycones are very resistant to heat.
Although many compounds present in the diet are converted by intestinal bacteria to less active molecules, other compounds are converted to molecules with increased biological activity. This is the case of isoflavones, but also of prenylflavonoids from hops (Humulus lupulus), and lignans, that are other phytoestrogens.
Phytoestrogens and menopause
Vasomotor symptoms, such as night sweats and hot flashes, and bone loss are very common in perimenopause, also called menopausal transition, and menopause.
Hormone replacement therapy (HRT) has proved to be a highly effective treatment for the prevention of menopausal bone loss and vasomotor symptoms.
The use of alternative therapies based on phytoestrogens is increased as a result of the publication of the “Women’s Health Initiative” study, that suggests that hormone replacement therapy could lead to more risks than benefits, in particular an increased risk of developing some chronic diseases.
Soy isoflavones are among the most used phytoestrogens by menopausal women, often taken in the form of isoflavone fortified foods or isoflavone supplements. However, many studies have highlighted the lack of efficacy of soy isoflavones, and red clover isoflavones, even in large doses, in the prevention of vasomotor symptoms, such as hot flushes and night sweats, and bone loss during menopause.
References
de la Rosa L.A., Alvarez-Parrilla E., Gonzàlez-Aguilar G.A. Fruit and vegetable phytochemicals: chemistry, nutritional value, and stability. 1th Edition. Wiley J. & Sons, Inc., Publication, 2010
Han X., Shen T. and Lou H. Dietary polyphenols and their biological significance. Int J Mol Sci 2007;9:950-988. doi:10.3390/i8090950
Lagari V.S., Levis S. Phytoestrogens for menopausal bone loss and climacteric symptoms. J Steroid Biochem Mol Biol 2014;139:294-301 doi:10.1016/j.jsbmb.2012.12.002
Lethaby A., Marjoribanks J., Kronenberg F., Roberts H., Eden J., Brown J. Phytoestrogens for menopausal vasomotor symptom. Cochrane Database of Systematic Reviews 2013, Issue 12. Art. No.: CD001395. doi:10.1002/14651858.CD001395.pub4
Levis S., Strickman-Stein N., Ganjei-Azar P., Xu P., Doerge D.R., Krischer J. Soy isoflavones in the prevention of menopausal bone loss and menopausal symptoms: a randomized, double-blind trial. Arch Intern Med 2011:8;171(15):1363-1369 doi:10.1001/archinternmed.2011.330
Manach C., Scalbert A., Morand C., Rémésy C., and Jime´nez L. Polyphenols: food sources and bioavailability. Am J Clin Nutr 2004;79(5):727-747. doi:10.1093/ajcn/79.5.727
Tsao R. Chemistry and biochemistry of dietary polyphenols. Nutrients 2010;2:1231-1246. doi:10.3390/nu2121231
The interest on proanthocyanidins, and their content in foods, has increased as a result of the discovery, due to clinical and laboratory studies, of their anti-infectious, anti-inflammatory, cardioprotective and anticarcinogenic properties. These protective effects have been attributed to their ability to:
constituent catechin units and bonds between units.
In some foods, such as black beans and cashew nuts, only dimers are present, called A-type procyanidins and B-type procyanidins, whereas in most of the foods proanthocyanidins are found in a wide range of polymerizations, from 2 to 10 units or more.
Foods with the highest proanthocyanidin content are cinnamon and sorghum, which contain respectively about 8,000 and up to 4,000 mg/100 g of fresh weight (FW).
Grape seeds (Vitis vinifera) are another rich source, with a content of about 3,500 mg/100 g dry weight.
Other important sources are fruits and berries, some legumes, namely, peas and beans, red wine and to a less extent beer, hazelnuts, pistachios, almonds, walnuts and cocoa.
The coffee is not a good source.
Proanthocyanidins are not detectable in the majority of vegetables; they have been found in small concentrations in Indian pumpkin. They are not detectable also in maize, rice and wheat, while there are present in barley.
Although many food plants contain high amounts of proanthocyanidins, only a few, such as plums, avocados, peanuts or cinnamon, contain A-type procyanidins, and none in amounts equal to cranberries (Vacciniun macrocarpon).
A-type procyanidins exhibit, in vitro, a capacity of inhibition of P-fimbriated Escherichia coli adhesion to uroepithelial cells greater than B-type procyanidins, adhesion which is the initial step of urogenital infections.
B-type procyanidins in foods
B-type procyanidins, consisting of catechin and/or epicatechin as constituent units, are the exclusive proanthocyanidins in at least 20 kinds of foods including blueberries (Vaccinium myrtillus), blackberries, marion berries, choke berries, grape seeds, apples, peaches, pears, nectarines, kiwi, mango, dates, bananas, Indian pumpkin, sorghum, barley, black eye peas, beans blacks, walnuts and cashews.
Proanthocyanidins in fruits
In the Western diet, fruit is the most important source of proanthocyanidins.
The major sources are some berries, namely, blueberries, cranberries, and black currant, and plums, with a content of about 200 mg/100 g FW.
Intermediate sources are apples, chokeberries, strawberries, and green and red grapes (60-90 mg/100 g FW).
In other fruits the content is less than 40 mg/100 g FW.
In fruit, the most common proanthocyanidins are tetramers, hexamers, and polymers.
Good sources of proanthocyanidins are also some fruit juices.
Proanthocyanidins in grape seeds
A particularly rich source of proanthocyanidins is the seeds of grape.
Proanthocyanidins in grape seeds are only B-type procyanidins, for the most part present in the form of dimers, trimers and highly polymerized oligomers.
Grape seed proanthocyanidins are potent antioxidants and free radical scavenger, being the more effective either than vitamin E and vitamin C or ascorbic acid.
In vivo and in vitro experiments support the idea that proanthocyanidins, and in particular those from grape seeds, can act as anti-carcinogenic agents; it seems that they are involved, in cancer cells, in:
reduction of cell proliferation;
increase of apoptosis;
cell cycle arrest;
modulation of the expression and activity of NF-kB and NF-kB target genes.
References
de la Rosa L.A., Alvarez-Parrilla E., Gonzàlez-Aguilar G.A. Fruit and vegetable phytochemicals: chemistry, nutritional value, and stability. 1th Edition. Wiley J. & Sons, Inc., Publication, 2010
Gu L., Kelm M.A., Hammerstone J.F., Beecher G., Holden J., Haytowitz D., Gebhardt S., and Prior R.L. Concentrations of proanthocyanidins in common foods and estimations of normal consumption. J Nutr 2004;134(3):613-617. doi:10.1093/jn/134.3.613
Han X., Shen T. and Lou H. Dietary polyphenols and their biological significance. Int J Mol Sci 2007;9:950-988. doi:10.3390/i8090950
Manach C., Scalbert A., Morand C., Rémésy C., and Jime´nez L. Polyphenols: food sources and bioavailability. Am J Clin Nutr 2004;79(5):727-747. doi:10.1093/ajcn/79.5.727
Nandakumar V., Singh T., and Katiyar S.K. Multi-targeted prevention and therapy of cancer by proanthocyanidins. Cancer Lett 2008;269(2):378-387. doi:10.1016/j.canlet.2008.03.049
Ottaviani J.I., Kwik-Uribe C., Keen C.L., and Schroeter H. Intake of dietary procyanidins does not contribute to the pool of circulating flavanols in humans. Am J Clin Nutr 2012;95:851-858. doi:10.3945/ajcn.111.028340
Tsao R. Chemistry and biochemistry of dietary polyphenols. Nutrients 2010;2:1231-1246. doi:10.3390/nu2121231
Wang Y.,Chung S., Song W.O., and Chun O.K. Estimation of daily proanthocyanidin intake and major food sources in the U.S. diet. J Nutr 2011;141(3):447-452. doi:10.3945/jn.110.133900
Flavonols are polyphenols belonging to the flavonoid family.
They are colorless molecules that accumulate mainly in the outer and aerial tissues, therefore skin and leaves, of fruit and vegetables, since their biosynthesis is stimulated by light, whereas they are virtually absent in the flesh.
Flavonols are the most common flavonoids in fruit and vegetables, where they are generally present in relatively low concentrations.
Due to their widespread in nature and human diet, they should be taken into consideration when the positive effect on health associated with fruit and vegetable consumption is examined.
Their effect is probably related to their ability to:
act as antioxidants;
act as anti-inflammatory agents;
act as anticancer factors;
regulate different cellular signaling pathways; an example is the action of quercetin, the most widespread flavonols, on the oxidative stress-induced MAPK activities.
Chemically, these molecules differ from many other flavonoids since they have a double bond between positions 2 and 3 and an oxygen (a ketone group) in position 4 of the C ring, like flavones from which, however, they differ in the presence of a hydroxyl group at the position 3. Therefore, flavonol skeleton is a 3-hydroxyflavone.
3-Hydroxyflavone
The 3-hydroxyl group can link a sugar, that is, it can be glycosylated.
Like many other flavonoids, most of them is found in fruit and vegetables, and in plant-derived foods, in glycosylated form. The sugar associated with flavonols is often glucose or rhamnose, but other sugars may also be involved, such as:
Flavonols are mainly represented by glycosides of:
quercetin;
kaempferol;
myricetin;
isorhamnetin.
Flavonols
The most ubiquitous compounds are glycosylated derivatives of quercetin and kaempferol; in nature, these two molecules have respectively about 280 and 350 different glycosidic combinations.
Finally, it should be underlined that sugar moiety influences flavonol bioavailability.
Food sources
The major sources in human diet are:
fruit;
vegetables;
beverages such as red wine and tea.
In human diet, the richest source are capers, which contain up to 490 mg/100 g fresh weight (FW), but they are also abundant in onions, leeks, broccoli, curly kale, berries, for example blueberries, grapes and some herbs and spices, for example dill weed (Anethum graveolens). In these sources, their content ranges between 10 and 100 mg/100 g FW.
Even cocoa, green tea, black tea, and red wine are good sources of flavonols. In wine, together with other polyphenols such as catechins, proanthocyanidins and low molecular weight polyphenols, they contribute to the astringency of the beverage.
Main flavonols in foods
The main flavonols in foods, listed in decreasing order of abundance, are quercetin, kaempferol, myricetin and ishoramnetin.
Quercetin
The richest sources of quercetin are capers, followed by onions, asparagus, lettuce and berries; in many other fruit and vegetables, it is present in smaller amounts, between 0.1 and 5 mg/100 g FW.
This flavonol is also present in cocoa and it could be one of its main protective agents against LDL oxidation.
Together with isoflavones, quercetin glycosides are the most well-absorbed polyphenols, followed by flavanones and catechins. Convesely, gallic acid derivatives of catechins are among the least well absorbed polyphenols, together with anthocyanins and proanthocyanidins.
Kaempferol
Typical dietary sources of kaempferol include vegetables, such as spinach, kale and endive, with concentrations between 0.1 and 27 mg/100 g FW, and some spices such as chives, fennel and tarragon, with concentrations between 6.5 and 19 mg/100 g FW.
Fruit is a poor source of the molecule, with content down to 0.1 mg/100 g FW.
Myricetin
Myricetin is the third most abundant flavonol. It is found in some spices, such as oregano, parsley, and fennel, with concentrations between 2 and 20 mg/100 g FW, but also in tea, 0.5-1.6 mg/100 ml, and red wine, 0-9.7 mg/100 ml.
In fruit, it is only found in high concentrations in berries, while in most other fruit and vegetables it is present in a content of less than 0.2 mg/100 g FW.
Isorhamnetin
A fourth flavonol, less abundant than the previous ones, is isorhamnetin. It is only present in some foods such as some spices: chives, 5.0-8.5 mg/100 g FW, fennel, 9.3 mg/100 g FW, tarragon, 5 mg/100 g FW.
In fruit and vegetables it is only present in almonds, with a concentration between 1.2 and 10.3 mg/100 g FW, pears and onions.
References
de la Rosa L.A., Alvarez-Parrilla E., Gonzàlez-Aguilar G.A. Fruit and vegetable phytochemicals: chemistry, nutritional value, and stability. 1th Edition. Wiley J. & Sons, Inc., Publication, 2010
Han X., Shen T. and Lou H. Dietary polyphenols and their biological significance. Int J Mol Sci 2007;9:950-988. doi:10.3390/i8090950
Manach C., Scalbert A., Morand C., Rémésy C., and Jime´nez L. Polyphenols: food sources and bioavailability. Am J Clin Nutr 2004;79(5):727-747. doi:10.1093/ajcn/79.5.727
Tsao R. Chemistry and biochemistry of dietary polyphenols. Nutrients 2010;2:1231-1246. doi:10.3390/nu2121231
Anthocyanins are a subgroup of flavonoids, therefore they are polyphenols, which give plants their distinctive colors.
They are water soluble pigments and are present in the vacuolar sap of the epidermal tissues of flowers and fruit. They are responsible for the colors of the most of the petals, fruits and vegetables, and of some varieties of cereals such as black rice. In fact, they impart red, pink and purple to blue colors to berries, red apples, red grapes, cherries, and of many other fruits, red lettuce, red cabbage, onions or eggplant, but also red wine.
Together with carotenoids, they are responsible for autumn leaf color and used commercially as food colours.
Finally, anthocyanins contribute to attract animals when a fruit is ready to eat or a flower is ready for pollination.
They are bioactive compounds found in plant foods that have a double interest for man:
the first one, a technological interest, due to their effects on the organoleptic characteristics of food products;
the other due to their healthy properties, being implicated in the protection against cardiovascular risk.
In fact:
in vitro, they have an antioxidant activity, due to their ability to delocalize electrons and form resonance structures, and a protective role against oxidation of low density lipoproteins (LDL);
like other polyphenols, such as catechins, proanthocyanidins and other uncolored flavonoids, they can regulate different signaling pathways involved in cell growth, differentiation and survival.
The basic chemical structure is flavylium cation (2-phenyl-1-benzopyrilium), which links hydroxyl (-OH) and/or methoxyl (-OCH3) groups, and one or more sugars.
The sugar-free molecule is called anthocyanidins.
Flavylium Cation
Depending on the number and position of hydroxyl and methoxyl groups, various anthocyanidins have been described, and of these, six are commonly found in vegetables and fruits:
pelargonidin
cyaniding
delphinidin
petunidin
peonidin
malvidin
Antocyanins
Anthocyanins, as most of the other flavonoids, are present in plants and plant foods in the form of glycosides, that is, linked to one or more sugar units.
The most common carbohydrates present in these natural pigments are:
The sugars are linked mainly to the C3 position as 3-monoglycosides, to the C3 and C5 positions as diglycosides, with the possible forms: 3-diglycosides, 3,5-diglycosides, and 3-diglycoside-5-monoglycosides. Glycosylations have been also found at C7, C3′ and C5′ positions.
The structure of these molecules is further complicated by the bond to the sugar unit of different acyl substituents such as:
aliphatic acids, such as acetic, malic, succinic and malonic acid;
cinnamic acids (aromatic substituents), such as sinapic, ferulic and p-coumaric acid;
finally, there are pigments with both aromatic and aliphatic substituents.
Furthermore, some anthocyanins have several acylated sugars in the molecule; these anthocyanins are sometimes called polyglycosides.
Depending on the type of hydroxylation, methoxylation and glycosylation patterns, and the different substituents linked to the sugar units, more than 500 different anthocyanins have been identified that are based on 31 anthocyanidins. Among these 31 monomers:
30 percent are from cyanidin;
22 percent are from delphinidin;
18 percent are from pelargonidin.
Methylated derivatives of cyanidin, delphinidin and pelargonidin, namely peonidin, malvidin, and petunidin, all together represent 20 percent of the anthocyanins.
Therefore, up to 90 percent of the most frequently encountered anthocyanins are related to delphinidin, pelargonidin, cyanidin, and their methylated derivatives.
Role of pH
The color of these molecules is influenced by the pH of the vacuole where they are stored, ranging in color from:
red, under very acidic conditions;
to purple-blue, in intermediate pH conditions;
until yellow-green, in alkaline conditions.
In addition to the pH, the color of these flavonoids can be affected by the degree of hydroxylation or methylation pattern of the A and B rings, and by glycosylation pattern.
Finally, the color of certain plant pigments result from complexes between anthocyanins, flavones and metal ions.
It should be noted that anthocyanins are often used as pH indicators thanks to the differences in chemical structure that occur in response to changes in pH.
References
de la Rosa L.A., Alvarez-Parrilla E., Gonzàlez-Aguilar G.A. Fruit and vegetable phytochemicals: chemistry, nutritional value, and stability. 1th Edition. Wiley J. & Sons, Inc., Publication, 2010
de Pascual-Teresa S., Moreno D.A. and García-Viguera C. Flavanols and anthocyanins in cardiovascular health: a review of current evidence. Int J Mol Sci 2010;11:1679-1703. doi:10.3390/ijms11041679
Escribano-Bailòn M.T., Santos-Buelga C., Rivas-Gonzalo J.C. Anthocyanins in cereals. J Chromatogr A 2004:1054;129-141. doi:10.1016/j.chroma.2004.08.152
Han X., Shen T. and Lou H. Dietary polyphenols and their biological significance. Int J Mol Sci 2007;9:950-988. doi:10.3390/i8090950
Manach C., Scalbert A., Morand C., Rémésy C., and Jime´nez L. Polyphenols: food sources and bioavailability. Am J Clin Nutr 2004;79(5):727-747. doi:10.1093/ajcn/79.5.727
Ottaviani J.I., Kwik-Uribe C., Keen C.L., and Schroeter H. Intake of dietary procyanidins does not contribute to the pool of circulating flavanols in humans. Am J Clin Nutr 2012;95:851-858. doi:10.3945/ajcn.111.028340
Tsao R. Chemistry and biochemistry of dietary polyphenols. Nutrients 2010;2:1231-1246. doi:10.3390/nu2121231
Proanthocyanidins or condensed tannins, also called pycnogenols and leukocyanidins, are polyphenolic compounds, in particular they are a flavonoid subgroup, widely distributed in the plant kingdom, second only to lignin as the most abundant phenol in nature.
They are present in high concentrations in various parts of the plants such as flowers, fruits, berries, seeds, for example in grape seeds, and bark, like pine bark.
Together with anthocyanins and their oxidation products, and catechins, they are the most abundant flavonoids in human diet and it has been suggested that they constitute a significant fraction of the polyphenols ingested in the Western diet.
Therefore, condensed tannins should be taken into consideration when the epidemiological association between the intake of polyphenols, especially flavonoids, and chronic diseases are examined.
Condensed tannins have a complex chemical structure being oligomers, from dimers to pentamers, or polymers, from six or more units up to 60, of catechins or flavanols, joined by carbon-carbon bonds.
(epi)afzelechin, and they are named propelargonidins;
(epi)gallocatechin, and they are named prodelphinidins.
Propelargonidins and prodelphinidins are less common in nature and in foods than procyanidins.
Depending on the bonds between monomers, proanthocyanidins have a:
B-type structure, if the polymerization occurs via carbon-carbon bond between the position 8 of the terminal unit and the 4 of the extender (or C4-C6);
A-type structure, less frequent, if monomers are doubly linked via an ether bond C2-O-C7 or C2-O-C5 plus a B-type bond.
Procyanidins
The most common dimers are B-type procyanidins, B1 to B8, formed by catechin or epicatechin; in B1, B2, B3 and B-4 dimers, the two flavanol units are joined by a C4-C8 bond; in B5, B6, B7 and B8 dimers the two units are joined by C4-C6 bond.
Procyanidins B1, B2, B3, and B4
Procyanidin C1 is a B-type trimer.
Procyanidin A-2 is an example of A-type procyanidin.
Intestinal absorption
Condensed tannins are poorly absorbed from the intestine. Together with anthocyanins and gallic acid ester derivatives of tea catechins, they are the least well-absorbed polyphenols.
It seems that low molecular weight oligomers (2-3 monomers) may be absorbed as such while polymers are not.
In the systemic circulation, dimers reach concentrations of two orders of magnitude lower than those of catechins.
It seems that condensed tannins with a degree of polymerization greater than three transit into the stomach and small intestine without significant modifications, and then, into the large intestine, they are catabolized by gut microbiota, which is part of the human microbiota, with production of phenylpropionic, phenilvaleric and phenylacetic acids. These degradation products have been suggested to be the major metabolites of proanthocyanidins in healthy humans.
Procyanidins and catechins
It had been proposed that the catabolism of procyanidins in the gastrointestinal tract lead to the release of monomeric catechins, thus indirectly contributing to their systemic pool in humans. In recent years, it has been shown that this does not happen because procyanidins do not significantly contribute to:
the concentration of catechin metabolites in the systemic circulation;
the total catechin metabolites excreted in the urine;
finally, they do not significantly affect plasma metabolite profile derived from catechol-O-methyltransferase activity.
Therefore, analyzing the potential health benefits associated with the intake of foods containing these phytochemicals, catechins and procyanidins should be considered distinct classes of related compounds.
References
de la Rosa L.A., Alvarez-Parrilla E., Gonzàlez-Aguilar G.A. Fruit and vegetable phytochemicals: chemistry, nutritional value, and stability. 1th Edition. Wiley J. & Sons, Inc., Publication, 2010
Gu L., Kelm M.A., Hammerstone J.F., Beecher G., Holden J., Haytowitz D., Gebhardt S., and Prior R.L. Concentrations of proanthocyanidins in common foods and estimations of normal consumption. J Nutr 2004;134(3):613-617. doi:10.1093/jn/134.3.613
Han X., Shen T. and Lou H. Dietary polyphenols and their biological significance. Int J Mol Sci 2007;9:950-988. doi:10.3390/i8090950
Manach C., Scalbert A., Morand C., Rémésy C., and Jime´nez L. Polyphenols: food sources and bioavailability. Am J Clin Nutr 2004;79(5):727-747. doi:10.1093/ajcn/79.5.727
Nandakumar V., Singh T., and Katiyar S.K. Multi-targeted prevention and therapy of cancer by proanthocyanidins. Cancer Lett 2008;269(2):378-387. doi:10.1016/j.canlet.2008.03.049
Ottaviani J.I., Kwik-Uribe C., Keen C.L., and Schroeter H. Intake of dietary procyanidins does not contribute to the pool of circulating flavanols in humans. Am J Clin Nutr 2012;95:851-858. doi:10.3945/ajcn.111.028340
Tsao R. Chemistry and biochemistry of dietary polyphenols. Nutrients 2010;2:1231-1246. doi:10.3390/nu2121231
Wang Y.,Chung S., Song W.O., and Chun O.K. Estimation of daily proanthocyanidin intake and major food sources in the U.S. diet. J Nutr 2011;141(3):447-452. doi:10.3945/jn.110.133900
Catechins or flavanols, with flavonols such as quercetin, and flavones such as luteolin, are a subgroup of flavonoids among the most widespread in nature.
Flavanols and proanthocyanidins, together with anthocyanins and their oxidation products, are the most abundant flavonoids in human diet.
Chemically they differ from many other flavonoids as:
they lack the double bond between positions 2 and 3 of the C ring;
they not have a keto group at position 4;
they have a hydroxyl group in position 3, and for this reason they are also called flavan-3-ols.
Basic Skeleton of Catechins
Another distinctive feature of flavan-3-ols is their ability to form oligomers, consisting of two to ten units, or polymers, consisting of from eleven or more units up to 60 units, called proanthocyanidins or condensed tannins.
Food sources
Flavanols commonly found in plant-derived food products are catechin, epicatechin, gallocatechin, epigallocatechin, and their gallic acid ester derivatives: catechin gallate, gallocatechin gallate, epicatechin gallate, and epigallocatechin gallate or EGCG.
Catechins
Flavanols present with higher frequency are catechin and epicatechin, which are also among the most common known flavonoids, and almost as popular as the related flavonol quercetin.
Cocoa and green tea are by far the richest sources in flavanols. In these foods the main flavonoids are catechin and epicatechin, but also their gallic acid ester derivatives, the gallocatechins. Cocoa is also a good source of epigallocatechin.
Gallic Acid Ester Derivatives of Catechins
However, they are also present in many fruits, especially in the skins of apples, blueberries (Vaccinium myrtillus) and grapes, in vegetables, red wine and beer, and peanuts.
As in many cases flavanols are present in the seeds or peels of fruits and vegetables, their intake may be limited by the fact that these parts are discarded during processing or while eaten.
Furthermore, in contrast to other flavonoids, catechins are not glycosylated in foods.
Proanthocyanidins, that is polymeric flavan-3-ols, are also commonly found in plant-derived food products. Their presence has been reported in the skin of peanuts and almonds, as in the berries.
Green and black tea
Green tea is an excellent source of flavonoids. The main flavonoids present in the leaves of the tea, like in cocoa beans, are catechin and epicatechin, monomeric flavanols, together with their gallate derivatives such as EGCG.
Epigallocatechin gallate is the most abundant catechin in green tea and it seems to have an important role in determining green tea benefits, as the reduction of:
vascular inflammation;
blood pressure;
concentration of oxidized LDLs.
Black tea, which is a fermented tea, contains fewer monomeric flavanols, as they are oxidized during fermentation of the leaves to more complex polyphenols such as theaflavins, specifically theaflavin digallate, theaflavin-3-gallate, and theaflavin-3′-gallate, which are all dimers, and thearubigins, which are polymers.
Theaflavins and thearubigins are present only in the tea. Their concentrations in brewed tea are between 50- and 100-folds lesser than in tea leaves.
It should be noted that tea epicatechins are remarkably stable to heat in acidic environment: at pH 5, only about 15% is degraded after seven hours in boiling water (therefore, adding lemon juice to brewed tea does not cause any reduction in their content).
Cocoa and cocoa products
Cocoa has the highest content of polyphenols and flavanols per serving, a concentration greater than those found in green tea and red wine. Most of the flavonoids present in cocoa beans and derived products, such as black chocolate, are catechin and epicatechin, monomeric flavanols, but also epigallocatechin, and their derivatives such as the gallocatechins; among polymers, proanthocyanidins are also important.
Fruits, vegetables, and legumes
Catechin and epicatechin are the main flavanols in fruits. They are found in many fruits in different concentrations, respectively, between 5-3 and 0.5-6 mg/100 g fresh weight.
On the contrary, gallocatechin, epicatechin gallate, epigallocatechin, and epigallocatechin gallate are present in various fruits such as red grapes, berries, apples, peaches and plums, but in very low concentrations, less than 1mg/100 g fresh weight.
Except for lentils and broad beans, few legumes and vegetables contain catechins, and in very low concentrations, less than 1.5 mg/100 g fresh weight.
References
de la Rosa L.A., Alvarez-Parrilla E., Gonzàlez-Aguilar G.A. Fruit and vegetable phytochemicals: chemistry, nutritional value, and stability. 1th Edition. Wiley J. & Sons, Inc., Publication, 2010
de Pascual-Teresa S., Moreno D.A. and García-Viguera C. Flavanols and anthocyanins in cardiovascular health: a review of current evidence. Int J Mol Sci 2010;11:1679-1703. doi:10.3390/ijms11041679
Han X., Shen T. and Lou H. Dietary polyphenols and their biological significance. Int J Mol Sci 2007;9:950-988. doi:10.3390/i8090950
Manach C., Scalbert A., Morand C., Rémésy C., and Jime´nez L. Polyphenols: food sources and bioavailability. Am J Clin Nutr 2004;79(5):727-747. doi:10.1093/ajcn/79.5.727
Tsao R. Chemistry and biochemistry of dietary polyphenols. Nutrients 2010;2:1231-1246. doi:10.3390/nu2121231
Flavonoids are the most abundant polyphenols in human diet, representing about 2/3 of all those ones ingested.
Like other phytochemicals, they are the products of secondary metabolism of plants and, currently, it is not possible to determine precisely their number, even if over 4000 have been identified.
In fruits and vegetables, they are usually found in the form of glycosides and sometimes as acylglycosides, while acylated, methylated and sulfate molecules are less frequent and in lower concentrations.
They are water-soluble and accumulate in cell vacuoles.
Their basic structure is a skeleton of diphenylpropane, i.e., two benzene rings linked by a three carbon chain that forms a pyran ring, namely, a heterocyclic ring containing oxygen, closed with the benzene ring A, which is called ring C. Therefore, their structure is also referred to as C6-C3-C6.
Basic Skeleton of Flavonoids
In most cases, B ring is attached to position 2 of C ring, but it can also bind in position 3 or 4. This, together with the structural features of the ring B and the patterns of glycosylation and hydroxylation of the three rings, makes the flavonoids one of the larger and more diversified groups of phytochemicals, so not only of polyphenols, in nature.
Their biological activities, for example they are potent antioxidants, depend both on the structural characteristics and the pattern of glycosylation.
Classification
They can be subdivided into different subclasses depending on the carbon of the C ring on which B ring is attached, and the degree of unsaturation and oxidation of the C ring.
Flavonoids in which B ring is linked in position 3 of the ring C are called isoflavones. Those in which B ring is linked in position 4, neoflavonoids, while those in which the B ring is linked in position 2 can be further subdivided into several subgroups on the basis of the structural features of the C ring. These subgroup are: flavones, flavonols, flavanones, flavanonols, flavanols or catechins and anthocyanins. Finally, flavonoids with open C ring are called chalcones.
Flavonoid Subclasses
Flavones
They have a double bond between positions 2 and 3 and a ketone in position 4 of the C ring. Most flavones of vegetables and fruits has a hydroxyl group in position 5 of the A ring, while the hydroxylation in other positions, for the most part in position 7 of the A ring or 3′ and 4′ of the B ring may vary according to the taxonomic classification of the particular vegetable or fruit.
Glycosylation occurs primarily on position 5 and 7, methylation and acylation on the hydroxyl groups of the B ring.
Some flavones, such as nobiletin and tangeretin, are polymethoxylated.
Flavonols
Compared to flavones, they have a hydroxyl group in position 3 of the C ring, which may also be glycosylated. Again, like flavones, flavonols are very diverse in methylation and hydroxylation patterns as well, and, considering the different glycosylation patterns, they are perhaps the most common and largest subgroup of flavonoids in fruits and vegetables. For example, quercetin is present in many plant foods.
Flavanones
Flavanones, also called dihydroflavones, have the C ring saturated. Therefore, unlike flavones, the double bond between positions 2 and 3 is saturated and this is the only structural difference between the two subgroups of flavonoids.
The flavanones can be multi-hydroxylated, and several hydroxyl groups can be glycosylated and/or methylated.
Some have unique patterns of substitution, for example, furanoflavanones, prenylated flavanones, pyranoflavanones or benzylated flavanones, giving a great number of substituted derivatives.
Over the past 15 years, the number of flavanones discovered is significantly increased.
Flavanonols
Flavanonols, also called dihydroflavonols, are the 3-hydroxy derivatives of flavanones; they are an highly diversified and multisubstituted subgroup.
Isoflavones
As anticipated, isoflavones are a subgroup of flavonoids in which the B ring is attached to position 3 of the C ring. They have structural similarities to estrogens, such as estradiol, and for this reason they are also called phytoestrogens.
Catechins
Catechins are also referred to flavan-3-ols as the hydroxyl group is almost always bound to position 3 of C ring; they are called flavanols as well.
They have two chirality centers in the molecule, on positions 2 and 3, then four possible diastereoisomers. Epicatechin is the isomer with the cis configuration and catechin is the one with the trans configuration. Each of these configurations has two stereoisomers, namely, (+)-epicatechin and (-)-epicatechin, (+)-catechin and (-)-catechin.
(+)-Catechin and (-)-epicatechin are the two isomers most often present in edible plants.
Another important feature of flavanols, particularly of catechin and epicatechin, is the ability to form polymers, called proanthocyanidins or condensed tannins. The name “proanthocyanidins” is due to the fact that an acid-catalyzed cleavage produces anthocyanidins. Proanthocyanidins typically contain 2 to 60 monomers of flavanols.
Monomeric and oligomeric flavanols, consisting of 2 to 7 monomers, are strong antioxidants.
Anthocyanidins
Chemically, anthocyanidins are flavylium cations and are generally present as chloride salts.
They are the only colored flavonoids, and, with carotenoids, impart color to plants. Moreover, they are used commercially as food colours.
Anthocyanins are glycosides of anthocyanidins. Sugar units are bound mostly to position 3 of the C ring and they are often conjugated with phenolic acids, such as ferulic acid.
The color of the anthocyanins depends on the pH and also by methylation or acylation at the hydroxyl groups on the A and B rings.
Chalcones
Chalcones and dihydrochalcones are flavonoids with open structure; they are classified as flavonoids because they have similar synthetic pathways.
References
de la Rosa L.A., Alvarez-Parrilla E., Gonzàlez-Aguilar G.A. Fruit and vegetable phytochemicals: chemistry, nutritional value, and stability. 1th Edition. Wiley J. & Sons, Inc., Publication, 2010
Han X., Shen T. and Lou H. Dietary polyphenols and their biological significance. Int J Mol Sci 2007;9:950-988. doi:10.3390/i8090950
Manach C., Scalbert A., Morand C., Rémésy C., and Jime´nez L. Polyphenols: food sources and bioavailability. Am J Clin Nutr 2004;79(5):727-747. doi:10.1093/ajcn/79.5.727
Panche A.N., Diwan A.D., and Chandra S.R. Flavonoids: an overview. J Nutr Sci. 2016;5:e47. doi:10.1017/jns.2016.41
Tsao R. Chemistry and biochemistry of dietary polyphenols. Nutrients 2010;2:1231-1246. doi:10.3390/nu2121231
Polyphenols are among the most important, and certainly the most numerous, phytochemicals present in the plant kingdom.
Currently, over 8,000 phenolic structures have been identified, of which more than 4,000 belonging to the class of flavonoids, and several hundred occur in edible plants.
However, it is thought that the total content of polyphenols in plants is underestimated as many of the phenolic compounds present in fruits, vegetables and derivatives have not yet been identified, escaping the methods and techniques of analysis used, and the composition in polyphenols for most fruits and some varieties of cereals is not yet known.
They are present in many edible plants, both for men and animals, and it is thought to be their presence, along with that of other molecules such as carotenoids, vitamin C or vitamin E, the responsible for the healthy effects of fruits and vegetables.
In the human diet, they are the most abundant natural antioxidants, and the main sources are fruits, vegetables, whole grains, but also other types of foods and beverages derived from them, such as red wine, rich in resveratrol, the extra virgin olive oil, rich in hydroxytyrosol, chocolate or tea, in particularly green tea, rich in epigallocatechin gallate or EGCG.
The term polyphenols refers to a wide variety of molecules that can be divided into many subclasses, subdivisions that can be made on the basis of their origin, biological function, or chemical structure.
Chemically, they are compounds with structural phenolic features, which can be associated with different organic acids and carbohydrates.
Ball-and-Stick Model of Phenol
In plants, the most part of them are linked to sugars, and therefore they are in the form of glycosides. Carbohydrates and organic acids can be bound in different positions on polyphenol skeletons.
Among polyphenols, there are simple molecules, such as phenolic acids, or complex structures such as proanthocyanidins, that are highly polymerized molecules.
Classification
They can be classified into different classes, according to the number of phenolic rings in their structure, the structural elements that bind these rings each others, and the substituents linked to the rings. Therefore, two main groups can then be identified: the flavonoid group and the non-flavonoid group.
Flavonoids share a structure formed by two aromatic rings, indicated as A and B, linked together by three carbon atoms forming an oxygenated heterocycle, the C ring. They can be further subdivided into six main subclasses, as a function of the type of heterocycle, the C ring, that is involved:
Variability of polyphenol content of plants and plant products
Although several classes of phenolic molecules, such as quercetin, a flavonol, are present in most plant foods, such as tea, wine, cereals, legumes, fruits, fruit juices, etc., other classes are found only in a particular type of food, for example flavanones in citrus, isoflavones in soya, phloridzin in apples, etc.
However, it is common that different types of polyphenols are in the same product. For example, apples contain flavanols, chlorogenic acid, hydroxycinnamic acids, glycosides of phloretin, glycosides of quercetin and anthocyanins.
The polyphenol composition may also be influenced by other parameters such as environmental factors, the degree of ripeness at harvest time, household or industrial processing, storage, and plant variety.
From currently available data, it seems that the fruits with the highest content of polyphenols are strawberries, lychees and grapes, and the vegetables are artichokes, parsley and brussels sprouts. Melons and avocados have the lowest concentrations.
References
de la Rosa L.A., Alvarez-Parrilla E., Gonzàlez-Aguilar G.A. Fruit and vegetable phytochemicals: chemistry, nutritional value, and stability. 1th Edition. Wiley J. & Sons, Inc., Publication, 2010
Han X., Shen T. and Lou H. Dietary polyphenols and their biological significance. Int J Mol Sci 2007;9:950-988. doi:10.3390/i8090950
Manach C., Scalbert A., Morand C., Rémésy C., and Jime´nez L. Polyphenols: food sources and bioavailability. Am J Clin Nutr 2004;79(5):727-747. doi:10.1093/ajcn/79.5.727
Tsao R. Chemistry and biochemistry of dietary polyphenols. Nutrients 2010;2:1231-1246. doi:10.3390/nu2121231
Carbohydrate ingestion can improve endurance capacity and performance.
The ingestion of different types of carbohydrates, which use different intestinal transporters, can:
increase total carbohydrate absorption;
increase exogenous carbohydrate oxidation;
and therefore improve performance.
Glucose and fructose
When a mixture of glucose and fructose is ingested, in the analyzed literature, respectively 1.2 and 0.6 g/min, ratio 2:1, for total carbohydrate intake rate to 1.8 g/min, there is less competition for intestinal absorption compared with the ingestion of an iso-energetic amount of glucose or fructose, two different intestinal transporters being involved. Furthermore, fructose absorption is stimulated by the presence of glucose.
increase the availability of exogenous carbohydrates in the bloodstream;
cause the higher exogenous carbohydrate oxidation rates in fructose plus glucose combination compared to high glucose intake alone.
The combined ingestion of glucose and fructose allows to obtain exogenous carbohydrate oxidation rate around 1,26 g/min, therefore, higher than the rate reported with glucose alone (1g/min), also in high concentration.
The observed difference, namely, +0,26 g/min, can be fully attributed to the oxidation of ingested fructose.
Sucrose and glucose
The ingestion of sucrose and glucose, in the same conditions of the ingestion of glucose and fructose, therefore, respectively 1.2 and 0.6 g/min, ratio 2:1, for total carbohydrate intake rate to 1.8 g/min, gives similar results.
Glucose, sucrose and fructose
Very high oxidation rates are found with a mixture of glucose, sucrose, and fructose, in the analyzed literature, respectively 1.2, 0.6 and 0.6 g/min, ratio 2:1:1, for total carbohydrate intake rate to 2.4 g/min; however, note the higher amounts of ingested carbohydrates.
Maltodextrin and fructose
High oxidation rates are also observed with combinations of maltodextrin and fructose, in the same conditions of the ingestion of glucose plus fructose, therefore, respectively 1.2 and 0.6 g/min, ratio 2:1, for total carbohydrate intake rate to 1.8 g/min.
Such high oxidation rates can be achieved with carbohydrates ingested in a beverage, in a gel or in a low-fat, low protein, low-fiber energy bar.
The best combination of carbohydrates ingested during exercise seems to be the mixture of maltodextrin and fructose in a 2:1 ratio, in a 5 percent solution, and in a dose around 80-90 g/h.
Oxidation of Ingested Carbohydrates
Why?
This mixture has the best ratio between amount of ingested carbohydrates and their oxidation rate and it means that smaller amounts of carbohydrates remain in the stomach or gut reducing the risk of gastrointestinal complication/discomfort during prolonged exercise.
A solution containing a combination of multiple transportable carbohydrates and a carbohydrate content not exceeding 5% optimizes gastric emptying rate and improves fluid delivery.
Example of a 5 percent carbohydrate solution containing around 80-90 g of maltodextrin and fructose in a 2:1 rate; ingestion time around 1 h.
1.5 L solution: 80 g of carbohydrates, including around 55 g of maltodextrin and around 25 of fructose.
1.8 L solution: 90 g of carbohydrates, including 60 g of maltodextrin and 30 of fructose.
Conclusion
During prolonged exercise, when high exogenous carbohydrate oxidation rates are needed, the ingestion of multiple transportable carbohydrates is preferred above that of large amounts of a single carbohydrate.
The best mixture seems to be maltodextrin and , in a 2:1 ratio, in a 5 percent concentration solution, and at ingestion rate of around 80-90 g/h.
References
Burke L.M., Hawley J.A., Wong S.H.S., & Jeukendrup A. Carbohydrates for training and competition. J Sport Sci 2011;29:Sup1,S17-S27. doi:10.1080/02640414.2011.585473
Jentjens R.L.P.G., Moseley L., Waring R.H., Harding L.K., and Jeukendrup A.E. Oxidation of combined ingestion of glucose and fructose during exercise. J Appl Physiol 2004:96;1277-1284. doi:10.1152/japplphysiol.00974.2003
Jentjens R.L.P.G., Venables M.C., and Jeukendrup A.E. Oxidation of exogenous glucose, sucrose, and maltose during prolonged cycling exercise. J Appl Physiol 2004:96;1285-1291. doi:10.1152/japplphysiol.01023.2003
Jeukendrup A.E. Carbohydrate feeding during exercise. Eur J Sport Sci 2008:2;77-86. doi:10.1080/17461390801918971
Jeukendrup A.E. Nutrition for endurance sports: marathon, triathlon, and road cycling. J Sport Sci 2011:29;sup1, S91-S99. doi:10.1080/02640414.2011.610348
Carotenoids are a class of fat-soluble pigments widely distributed in nature. They are yellow, orange, and red organic compounds composed of eight isoprene units and characterized by many conjugated double bonds. Their hydrocarbon chain can undergo several modifications that significantly influence their biological properties.[1]
Discovered in the first half of the 1800s, carotenoids are synthesized by all photosynthetic organisms, including plants, macroalgae, and microalgae, as well as by some non-photosynthetic organisms such as certain fungi, bacteria, and insects, for example pea aphids, some species of gall midges, and spider mites. In plants and microalgae, they are synthesized and accumulated in plastids.[2][3]
Together with polyphenols and glucosinolates, they form one of the major groups of phytochemicals.[4]
Over the course of evolution, thanks to their chemical and physical properties, carotenoids have proved extremely versatile, as they perform many functions in both plants and animals, among which their antioxidant activity is particularly important. In humans, some carotenoids also serve as vitamin A precursors.[5][6]
More than 750 different carotenoids have been identified. Over 100 have been found in fruits and vegetables, and about 40 are consumed in significant amounts by humans.[7][8]
Because of their colour, carotenoids are used as food additives.[9][10]
Summary: Key Points
Chemical nature: fat-soluble pigments (tetraterpenes) consisting of eight isoprene units with numerous conjugated double bonds.
Classification: divided into carotenes and xanthophylls.
Biological functions: essential for photosynthesis and cellular protection through antioxidant activity.
Human health: act as precursors of vitamin A, support visual function, and help prevent chronic diseases.
Sources and absorption: found in yellow-orange or dark green fruits and vegetables; transported in plasma by lipoproteins, with bioavailability dependent on dietary fat.
Carotenoids were discovered in the first half of the nineteenth century.
The first carotenoid to be isolated was β-carotene, in 1831, thanks to the work of the German pharmacist Heinrich Wilhelm Ferdinand Wackenroder, who named “carotene” the yellow pigment crystallized from carrot roots.[2]
Jöns Jacob Berzelius, considered one of the fathers of modern chemistry, named the yellow pigments extracted from autumn leaves “xanthophylls”, from the Greek xanthos (yellow) and phyllon (leaf).[11][12]
Mikhail Semyonovich Tsvet, a Russian botanist who invented chromatography in 1906, succeeded in separating leaf pigments, chlorophylls, carotenes, and xanthophylls, using column chromatography, and called the yellow-to-orange pigments carotenoids.[1]
Chemical structure
Carotenoids are a class of lipids characterized by a backbone composed of eight isoprene units arranged linearly. Therefore, they are terpenes, specifically tetraterpenes, and consist of 40 carbon atoms.[8]
The isoprene units are joined in a 1,5 positional relationship (i.e., head to tail), except in the middle of the hydrocarbon chain, where the relationship is 1,6 (i.e., tail to tail). This inversion results in a symmetrical molecule.[5]
Carotenoids are characterized by the presence of an extended double-bond system, 3 to 13 of which may be conjugated.[13]
Skeletal Formulas of Some Carotenoids
The hydrocarbon chain of carotenoids can undergo hydrogenation, dehydrogenation, introduction of oxygen atoms, cyclization of one or both ends to form an ionone ring, and esterification with fatty acids.[14] These modifications allow for the formation of many different structures, most of which can be described by the chemical formula C40H56On, with 0 ≤ n ≤ 6.[7]
Traditionally, carotenoids have common names related to the biological source from which they were originally extracted, such as β-carotene (from carrot) or astaxanthin (from lobster), although they can also be named using IUPAC nomenclature.[6][15]
Isomerism
Carotenoids contain many double bonds that can exhibit cis–transisomerism, also known as geometric isomerism. Although, in theory, their double bonds may adopt either a cis or a trans configuration, in nature the trans configuration prevails, as it is thermodynamically more stable due to lower steric hindrance between substituents.[5]
Rotation around single (σ) bonds also allows the formation of conformational isomers. When the double bonds are on the same side with respect to the sigma bond, namely cis relative to the single bond, the conformation is called the s-cis conformation. Conversely, when the double bonds lie on opposite sides, namely trans relative to the single bond, the conformation is called the s-trans conformation.[16]
In nature, acyclic carotenoids occur mainly in the s-trans conformation, as it has the least steric hindrance.[17] When the polyene chain ends with cyclic structures, rotation around the C6–C7 σ bond may lead to the formation of a 6-s-cis isomer, which is sterically less hindered and therefore energetically favored.[18]
It should also be noted that steric hindrance and the size of carotenoid molecules influence their ability to interact with enzymes and to form supramolecular structures.[19]
Most carotenoids possess either a chiral center or a chirality axis, which gives rise to optical isomers. In such cases, to provide an unambiguous name for the molecule, the RS system is used instead of the Fischer−Rosanoff convention, which applies only to carbohydrates and amino acids.[20]
Classification
Carotenoids can be classified according to the presence or absence of oxygen atoms or cyclic structures.[14]
Based on oxygen content, they are divided into xanthophylls and carotenes.
Carotenes, which are oxygen-free molecules, are composed only of carbon and hydrogen atoms and have the chemical formula C40H56. Examples include α-carotene, β-carotene, δ-carotene, ζ-carotene, phytoene, and lycopene.
Xanthophylls contain oxygen atoms and have the chemical formula C40H56On, with 1 ≤ n ≤6. They can be further subdivided into:
hydroxycarotenoids, which contain at least one hydroxyl group, such as α-cryptoxanthin, β-cryptoxanthin, zeaxanthin, and lutein;
epoxycarotenoids, which have at least one epoxy group, such as antheraxanthin, auroxanthin, and luteoxanthin;
ketocarotenoids, which contain one or more carbonyl groups, such as astaxanthin and canthaxanthin.[8]
Depending on the presence or absence of cyclic structures, carotenoids can be classified as cyclic or acyclic.
Cyclic carotenoids contain one or two cyclic structures and are shorter than acyclic carotenoids but exhibit greater steric hindrance. Examples include α-carotene, β-carotene, γ-carotene, and δ-carotene.
Acyclic carotenoids consist of a linear carbon chain. Examples include lycopene, ζ-carotene, phytoene, and phytofluene.
Finally, there are also uncommon or species-specific carotenoids, such as bixin, capsanthin, and capsorubin.[12]
Solubility
Carotenoids are hydrophobic molecules and therefore soluble in organic solvents, with their solubility varying according to the substituents present.[21] Owing to their hydrophobic nature, they are located within cell membranes. In most cases, xanthophylls have polar groups at the ends of the polyene chain, and when incorporated into lipid bilayers they orient themselves so that their polar groups interact with the polar regions of the membrane, thereby minimizing the system’s energy.[22]
Carotenoids can also access the aqueous environment when associated with proteins to which they bind non-covalently. In plasma, they are transported by lipoproteins.[23]
Colour
The conjugated double-bond system, acting as a chromophore, is responsible for the colour of carotenoids.[14] However, only carotenoids with at least seven conjugated double bonds are coloured; thus, phytofluene, which has five conjugated double bonds, and phytoene, which has three, are colourless.[24]
As the number of conjugated double bonds increases, the colour shifts from yellow to orange to red. For example, lutein, α-cryptoxanthin, and violaxanthin are yellow, α-carotene, β-carotene, and γ-carotene are orange, and lycopene is red.[1]
Role in plants
Carotenoids perform a variety of roles in plants.
They contribute to cell protection against oxidative damage, enhance light absorption, serve as precursors of phytohormones such as abscisic acid, and participate in signaling pathways.[5]
Together with chlorophylls and anthocyanins, a class of flavonoids, they also contribute to the colour of leaves, fruits, vegetables, and grains, a colour that attracts animals and promotes pollination and seed dispersal.[25][26]
Finally, carotenoids can act as repellent agents against phytophagous organisms and pathogens.[27]
Quenching of singlet oxygen
In organisms that carry out oxygenic photosynthesis, carotenoids contribute to protection against damage caused by excessive solar radiation.[28]
When the sunlight arriving at the photosystem II antenna complex exceeds the conversion capacity of the reaction centers, the excess energy may cause chlorophyll to remain in its excited state, which can lead to the formation of its triplet state. The excess energy can then be transferred from chlorophyll to molecular oxygen, resulting in the formation of singlet oxygen, a reactive oxygen species capable of damaging the photosynthetic apparatus and, more generally, nucleic acids, proteins, membrane unsaturated fatty acids, and enzyme cofactors.[29]
Carotenoids can prevent oxidative damage caused by singlet oxygen in two ways.
They can directly quench singlet oxygen. In this mechanism, the energy is transferred from singlet oxygen to the carotenoid; the oxygen returns to the triplet ground state, while the carotenoid reaches its triplet state and then releases the excess energy as heat. The capacity to quench singlet oxygen increases with the number of conjugated double bonds, reaching its maximum at nine or more. In vitro studies suggest that monocyclic carotenoids can quench singlet oxygen more efficiently than acyclic ones, and that the presence of carbonyl groups, as in astaxanthin, enhances antioxidant potential compared to carotenoids with hydroxyl groups, likely due to an extended system of conjugated double bonds. It appears that each carotenoid molecule can quench approximately 1,000 singlet oxygen molecules before undergoing degradation.[30]
Carotenoids can prevent the formation of singlet oxygen by absorbing the energy of excited chlorophyll and entering a triplet state themselves. Because the triplet state of carotenoids has a lower energy level than that required to form singlet oxygen, it decays spontaneously to the ground state.[31]
Free radical scavenging activity
Carotenoids are able to scavenge free radicals, such as hydroxyl, peroxyl, superoxide, and nitric oxide radicals. Their action can occur through four different mechanisms.[8][32]
Electron transfer
Carotenoids can donate an electron to a radical cation, forming a carotenoid radical cation while the radical becomes a stable molecule. The carotenoid radical cation can be regenerated to the parent carotenoid by other cellular antioxidants, such as vitamin E, vitamin C, and glutathione.[33]
Proton transfer
A proton may be transferred from the carotenoid to the radical species, which becomes a neutral molecule, while the carotenoid forms a radical anion.[34]
Addition reactions
Neutralization of free radicals can also occur via addition reactions, as in the case of hydroxyl and peroxyl radicals.[13]
Hydrogen atom transfer
A hydrogen atom can be transferred from the carotenoid to the reactive oxygen species, forming a resonance-stabilized neutral carotenoid radical.[19]
Light-harvesting role
Carotenoids are present in antenna complexes as accessory light-harvesting pigments, mainly associated with antenna proteins.[35]
Thanks to their system of conjugated double bonds, they are able to absorb sunlight in the 400–500 nm range, after which the absorbed energy is transferred to the reaction centers. The absorption spectra of individual carotenoids depend on the length of the conjugated system and the functional groups present.[17]
The main carotene involved in light harvesting is β-carotene, located in the core of photosystems I and II in all organisms that carry out oxygenic photosynthesis. Lutein, violaxanthin, neoxanthin, and zeaxanthin, the main xanthophylls in plants, are bound to the light-harvesting complexes.[36]
Food sources
Humans are not able to synthesize carotenoids. They obtain them from food and store them mainly in the liver and adipose tissue, but also in the lungs, kidneys, brain, and bones, where they perform several functions.[13]
Among all the carotenoids identified, about one hundred have been found in foods consumed by humans. However, within a single food item, there are usually one to six major carotenoids, together with others present only in trace or small amounts.[37]
Fruits and vegetables are the major sources of carotenoids in the human diet. Among vegetables, leafy greens are rich in β-carotene, the most abundant carotenoid in the human diet and in human tissues, and in lutein, followed by violaxanthin and neoxanthin. The carrot root is rich in β-carotene, pumpkin in α-carotene, tomato in lycopene, and peppers in capsanthin and capsorubin. Carotenoids in fruits are highly variable, and their composition often differs between unripe and ripe fruits. Moreover, most carotenoids present in ripe fruits are esterified with fatty acids, whereas fruits that remain green when ripe, such as kiwifruit, show limited or no esterification.[21]
Chicken eggs are also good sources of carotenoids, particularly lutein and zeaxanthin, because laying hens generally consume corn. These carotenoids are responsible for the yellow–orange colour of egg yolk.[38]
Finally, mollusks and crustaceans, together with fish, are major dietary sources of carotenoids produced by microalgae and rarely found in plants, such as astaxanthin, which accumulates in shrimp and contributes to the coloration of salmon.[39]
Food additives
Carotenoids used in the food industry as additives, unlike naturally occurring carotenoids, are relatively unstable. They are susceptible to oxygen and sunlight, auto-oxidation, and dispersion into food ingredients, which facilitates their degradation.[21] Furthermore, at body temperature and food-storage temperatures, added carotenoids are in crystalline form because of their high melting point; to overcome this issue, they are incorporated as oil-in-water emulsions.[40]
Thanks to their colouring power, they are used as colours in foods that lose part of their natural colour due to processing or storage, to standardize product appearance, as in beverages, fruit juices, or sausages, or to intensify colour and improve visual appeal.[41]
Carotenoids are also precursors of compounds responsible for the flavor and aroma of certain foods; therefore, they can be used as flavour enhancers.[42]
In addition, some carotenoids are vitamin A precursors and are used to fortify foods.[43]
It should also be noted that carotenoids, when added to foods, are not powerful antioxidants.[44]
Their most important role is to act as precursors of vitamin A, which regulates the expression of nearly 700 genes. Not all carotenoids have provitamin A activity; only those with an unsubstituted β-ionone ring do. The most significant is β-carotene which, having two unsubstituted β-ionone rings, can be converted into two molecules of vitamin A. α-Carotene and β-cryptoxanthin, each containing a single unsubstituted β-ionone ring, yield one molecule of vitamin A, and therefore have 50% of the provitamin A activity of β-carotene.[13]
The importance of provitamin A carotenoids is highlighted by the fact that vitamin A deficiency can lead to night blindness and xerophthalmia, delay the growth and regeneration of mucous membranes, increase mortality due to immunological dysfunctions during infectious diseases, and represents the leading cause of childhood blindness in developing countries.[46]
Carotenoids also contribute to human health through mechanisms unrelated to provitamin A activity, such as antioxidant and anti-inflammatory actions and photoprotection. Examples include the following.
Supplementation with lutein and zeaxanthin, two xanthophylls that accumulate in the macula lutea, has been associated with improved visual function and a reduced risk of progression of age-related macular degeneration. Lutein and zeaxanthin also appear to reduce the risk of cataracts and retinopathies, and lutein may have beneficial effects on cognitive functions.[47]
Among carotenes, the consumption of lycopene-rich foods has been associated with a reduced incidence of several types of cancer, such as prostate and stomach cancer, as well as a lower cardiovascular risk.[48]
Plasma carotenoids
α-Carotene, β-carotene, lycopene, lutein, β-cryptoxanthin, and zeaxanthin account for more than 90% of the carotenoids present in plasma.[49]
Plasma carotenoid concentrations depend on several factors, including cooking methods, dietary fat intake, and individual differences in lipid digestion and lipid absorption, processes in which bile salts play an essential role. Vitamin A status also influences plasma levels: individuals with low vitamin A stores may have higher conversion rates of provitamin A carotenoids, which can result in lower circulating concentrations.[50][51]
References
^ abc Maoka T. Carotenoids as natural functional pigments. J Nat Med 2020;74(1):1-16. doi:10.1007/s11418-019-01364-x
^ ab Sourkes T.L. The discovery and early history of carotene. Bull Hist Chem 2009;34(1):32-37.
^ Aizpuru A., González-Sánchez A. Traditional and new trend strategies to enhance pigment contents in microalgae. World J Microbiol Biotechnol 2024;40(9):272. doi:10.1007/s11274-024-04070-3
^ de la Rosa L.A., Alvarez-Parrilla E., Gonzàlez-Aguilar G.A. Fruit and vegetable phytochemicals: chemistry, nutritional value, and stability. 1st Edition. Wiley J. & Sons, 2010.
^ abcd Swapnil P., Meena M., Kumar Singh S., Praveen Dhuldhaj U., Harish, Marwal A. Vital roles of carotenoids in plants and humans to deteriorate stress with its structure, biosynthesis, metabolic engineering and functional aspects. Curr Plant Biol 2021;26: 100203. doi:10.1016/j.cpb.2021.100203
^ ab Crupi P., Faienza M.F., Naeem M.Y., Corbo F., Clodoveo M.L., Muraglia M. Overview of the potential beneficial effects of carotenoids on consumer health and well-being. Antioxidants (Basel) 2023;12(5):1069. doi:10.3390/antiox12051069
^ ab Desmarchelier C., Borel P. Overview of carotenoid bioavailability determinants: from dietary factors to host genetic variations. Trends Food Sci Technol 2017;69(Part B):270-280. doi:10.1016/j.tifs.2017.03.002
^ Gebhardt B., Sperl R., Carle R., Müller-Maatsch J. Assessing the sustainability of natural and artificial food colorants. J Clean Prod 2020;260;120884. doi:10.1016/j.jclepro.2020.120884
^ EFSA Food colours. Last reviewed date: 14 November 2025.
^ Olson J.A., Krinsky N.I. Introduction: the colorful, fascinating world of the carotenoids: important physiologic modulators. FASEB J 1995;9(15):1547-50. doi:10.1096/fasebj.9.15.8529833
^ ab Britton G., Liaaen-Jensen S., Pfander H. Carotenoids: Handbook. Basel: Birkhäuser; 2004. doi:10.1007/978-3-0348-7836-4
^ abcd Saini R.K., Prasad P., Lokesh V., Shang X., Shin J., Keum Y.S., Lee J.H. Carotenoids: dietary sources, extraction, encapsulation, bioavailability, and health benefits – A review of recent advancements. Antioxidants 2022;11(4):795. doi:10.3390/antiox11040795
^ abc Zia-Ul-Haq M., Dewanjee S., Riaz M. Carotenoids: structure and function in the human body. Springer; 2021. doi:10.1007/978-3-030-46459-2_1
^ Yabuzaki J. Carotenoids database: structures, chemical fingerprints and distribution among organisms. Database (Oxford) 2017;2017(1):bax004. doi:10.1093/database/bax004
^ Solomons T.W.G., Fryhle C.B., Snyder S.A. Solomons’ organic chemistry. 12th Edition. John Wiley & Sons Incorporated, 2017.
^ ab Telegina T.A., Vechtomova Y.L., Aybush A.V., Buglak A.A., Kritsky M.S. Isomerization of carotenoids in photosynthesis and metabolic adaptation. Biophys Rev 2023;15(5):887-906. doi:10.1007/s12551-023-01156-4
^ Britton G. Structure and properties of carotenoids in relation to function. FASEB J 1995;9(15):1551-8. doi:10.1096/fasebj.9.15.8529834
^ ab Polyakov N.E., Focsan A.L., Gao Y., Kispert L.D. The endless world of carotenoids-Structural, chemical and biological aspects of some rare carotenoids. Int J Mol Sci 2023;24(12):9885. doi:10.3390/ijms24129885
^ Prelog V., Helmchen G. Basic principles of the CIP‐system and proposals for a revision. Angew Chem 1982:21(8);567-583. doi:10.1002/anie.198205671
^ abc González-Peña M.A., Ortega-Regules A.E., Anaya de Parrodi C., Lozada-Ramírez J.D. Chemistry, occurrence, properties, applications, and encapsulation of carotenoids-A review. Plants (Basel) 2023;12(2):313. doi:10.3390/plants12020313
^ Gruszecki W.I., Strzałka K. Carotenoids as modulators of lipid membrane physical properties. Biochim Biophys Acta 2005;1740(2):108-15. doi:10.1016/j.bbadis.2004.11.015
^ Tyssandier V., Choubert G., Grolier P., Borel P. Carotenoids, mostly the xanthophylls, exchange between plasma lipoproteins. Int J Vitam Nutr Res 2002;72(5):300-8. doi:10.1024/0300-9831.72.5.300
^ Rodriguez-Amaya D.B., Esquivel P., Meléndez-Martínez A.J. Comprehensive update on carotenoid colorants from plants and microalgae: challenges and advances from research laboratories to industry. Foods 2023;12(22):4080. doi:10.3390/foods12224080
^ Archetti, M., Döring T.F., Hagen S.B., Hughes N.M., Leather S.R., Lee D.W., Lev-Yadun S., Manetas Y., Ougham H.J. Unravelling the evolution of autumn colours: an interdisciplinary approach. Trends Ecol Evol 2009;24(3):166-73. doi:10.1016/j.tree.2008.10.006
^ Cazzonelli C.I. Carotenoids in nature: insights from plants and beyond. Funct Plant Biol 2011;38(11):833-847.
^ Gómez-Sagasti M.T., López-Pozo M., Artetxe U., Becerril J.M., Hernández A., García-Plazaola J.I., Esteban R. Carotenoids and their derivatives: a “swiss army knife-like” multifunctional tool for fine-tuning plant-environment interactions. Environ Exp Bot 2023;207:105229. doi:10.1016/j.envexpbot.2023.105229
^ Havaux M. Carotenoids as membrane stabilizers in chloroplasts. Trends Plant Sci 1998;3(4):147-151. doi:10.1016/S1360-1385(98)01200-X
^ Triantaphylidès C., Havaux M. Singlet oxygen in plants: production, detoxification and signaling. Trends Plant Sci 2009;14(4):219-28. doi:10.1016/j.tplants.2009.01.008
^ Ramel F., Birtic S., Cuiné S., Triantaphylidès C., Ravanat J.L., Havaux M. Chemical quenching of singlet oxygen by carotenoids in plants. Plant Physiol 2012;158(3):1267-78. doi:10.1104/pp.111.182394
^ Pérez-Gálvez A., Viera I., Roca M. Carotenoids and chlorophylls as antioxidants. Antioxidants (Basel) 2020;9(6):505. doi:10.3390/antiox9060505
^ Krinsky N.I. Antioxidant functions of carotenoids. Free Radic Biol Med 1989;7(6):617-35. doi:10.1016/0891-5849(89)90143-3
^ Ribeiro D., Freitas M., Silva A.M.S., Carvalho F., Fernandes E. Antioxidant and pro-oxidant activities of carotenoids and their oxidation products. Food Chem Toxicol 2018;120:681-699. doi:10.1016/j.fct.2018.07.060
^ Focsan A.L., Kispert L.D. Radicals formed from proton loss of carotenoid radical cations: a special form of carotenoid neutral radical occurring in photoprotection. J Photochem Photobiol B 2017;166:148-157. doi:10.1016/j.jphotobiol.2016.11.015
^ Cogdell R.J., Gillbro T., Andersson P.O., Liu R.S.H., Asato A.E. Carotenoids as accessory light-harvesting pigments. Pure Appl Chem 1994:66(5):1041-1046. doi:10.1351/pac199466051041
^ Xu P., Chukhutsina V.U., Nawrocki W.J., Schansker G., Bielczynski L.W., Lu Y., Karcher D., Bock R., Croce R. Photosynthesis without β-carotene. eLife 2020;9:e58984. doi:10.7554/eLife.58984
^ Meléndez-Martínez A.J., Mandić A.I., Bantis F., et al. A comprehensive review on carotenoids in foods and feeds: status quo, applications, patents, and research needs. Crit Rev Food Sci Nutr 2022;62(8):1999-2049. doi:10.1080/10408398.2020.1867959
^ Ko E.Y., Saini R.K., Keum Y.S., An B.K. Age of laying hens significantly influences the content of nutritionally vital lipophilic compounds in eggs. Foods 2020;10(1):22. doi:10.3390/foods10010022
^ Galasso C., Corinaldesi C., Sansone C. Carotenoids from marine organisms: biological functions and industrial applications. Antioxidants (Basel) 2017;6(4):96. doi:10.3390/antiox6040096
^ Kirkhus B., Afseth N.K., Borge G.I.A., Grimsby S., Steppeler C., Krona A., Langton M. Increased release of carotenoids and delayed in vitro lipid digestion of high pressure homogenized tomato and pepper emulsions. Food Chem 2019;285:282-289. doi:10.1016/j.foodchem.2019.01.124
^ Mezzomo N., Ferreira S.R.S. Carotenoids functionality, sources, and processing by supercritical technology: a review. J Chem 2016;1:Article ID 3164312. doi:10.1155/2016/3164312
^ Meléndez-Martínez A.J., Esquivel P., Rodriguez-Amaya D.B. Comprehensive review on carotenoid composition: transformations during processing and storage of foods. Food Res Int 2023;169:112773. doi:10.1016/j.foodres.2023.112773
^ Hombali A.S., Solon J.A., Venkatesh B.T., Nair N.S., Peña-Rosas J.P. Fortification of staple foods with vitamin A for vitamin A deficiency. Cochrane Database Syst Rev 2019;5(5):CD010068. doi:10.1002/14651858.CD010068.pub2
^ Terao J. Revisiting carotenoids as dietary antioxidants for human health and disease prevention. Food Funct 2023;14:7799-7824. doi:10.1039/d3fo02330c
^ Eggersdorfer M., Wyss A. Carotenoids in human nutrition and health. Arch Biochem Biophys 2018;652:18-26. doi:10.1016/j.abb.2018.06.001
^ Hodge C., Taylor C. Vitamin A deficiency. [Updated 2023 Jan 2]. In: StatPearls [Internet]. Treasure Island (FL): StatPearls Publishing; 2025 Jan-. Available from: https://www.ncbi.nlm.nih.gov/books/NBK567744/
^ Mrowicka M., Mrowicki J., Kucharska E., Majsterek I. Lutein and zeaxanthin and their roles in age-related macular degeneration-neurodegenerative disease. Nutrients 2022;14(4):827. doi:10.3390/nu14040827
^ Khan U.M., Sevindik M., Zarrabi A., et al. Lycopene: food sources, biological activities, and human health benefits. Oxid Med Cell Longev 2021;2021:2713511. doi:10.1155/2021/2713511
^ Deming D.M., Erdman Jr J.W. Mammalian carotenoid absorption and metabolism. Pure Appl Chem 1999;71(12):2213-2223.
^ Burrows T.L., Williams R., Rollo M., Wood L., Garg M.L., Jensen M., Clare Collins C.E. Plasma carotenoid levels as biomarkers of dietary carotenoid consumption: a systematic review of the validation studies. J Nutr Intermed Metab 2015;2(1-2):15-64. doi:10.1016/j.jnim.2015.05.001
^ Böhm V., Lietz G., Olmedilla-Alonso B., et al. From carotenoid intake to carotenoid blood and tissue concentrations – implications for dietary intake recommendations. Nutr Rev 2021;79(5):544-573. doi:10.1093/nutrit/nuaa008
Carbohydrate loading is a good strategy to increase fuel stores in muscles before the start of the competition.
What does the muscle “eat” during endurance exercise?
Muscle “eats” carbohydrates, in the form of liver and muscle glycogen, carbohydrates ingested during the exercise or just before that, and fat.
During endurance exercise, the most likely contributors to fatigue are dehydration and carbohydrate depletion, especially of muscle and liver glycogen.
To prevent the “crisis” due to the depletion of muscle and liver carbohydrates, it is essential having high glycogen stores before the start of the activity.
What does affect glycogen stores?
The diet in the days before the competition.
The level of training (well-trained athletes synthesize more glycogen and have potentially higher stores, because they have more efficient enzymes).
The activity in the day of the competition and the days before (if muscle doesn’t work it doesn’t lose glycogen). Therefore, it is better to do light trainings in the days before the competition, not to deplete glycogen stores, and to take care of nutrition.
The “Swedish origin” of carbohydrate loading
Very high muscle glycogen levels, the so-called glycogen supercompensation, can improve performance, i.e. time to complete a predetermined distance, by 2-3% in the events lasting more than 90 minutes, compared with low to normal glycogen, while benefits seem to be little or absent when the duration of the event is less than 90 min.
Well-trained athletes can achieve glycogen supercompensation without the depletion phase prior to carbohydrate loading, the old technique discovered by two Swedish researchers, Saltin and Hermansen, in 1960s.
The researchers discovered that muscle glycogen concentration could be doubled in the six days before the competition following this diet:
three days of low carb menu (a nutritional plan very poor in carbohydrates, i.e. without pasta, rice, bread, potatoes, legumes, fruits etc.);
three days of high carbohydrate diet, the so-called carbohydrate loading (a nutritional plan very rich in carbohydrates).
This diet causes a lot of problems: the first three days are very hard and there may be symptoms similar to depression due to low glucose delivery to brain, and the benefits are few.
Moreover, with the current training techniques, the type and amount of work done, we can indeed obtain high levels of glycogen: above 2.5 g/kg of body weight.
The “corrent” carbohydrate loading
If we compete on Sunday, a possible training/nutritional plan to obtain supercompensation of glycogen stores can be the following:
Wednesday, namely four days before the competition, moderate training and then dinner without carbohydrates;
from Thursday on, namely the three days before the competition, hyperglucidic diet and light trainings.
Example of Carbohydrate Loading
The amount of dietary carbohydrates needed to recover glycogen stores or to promote glycogen loading depends on the duration and intensity of the training programme, and they span from 5 to 12 g/kg of body weight/d, depending on the athlete and his activity. With higher carbohydrate intake you can achieve higher glycogen stores but this does not always results in better performance. Moreover, it should be noted that glycogen storage is associated with weight gain due to water retention (approximately 3 g per gram of glycogen), and this may not be desirable in some sports.
References
Burke L.M., Hawley J.A., Wong S.H.S., & Jeukendrup A. Carbohydrates for training and competition. J Sport Sci 2011;29:Sup1,S17-S27. doi:10.1080/02640414.2011.585473
Hargreaves M., Hawley J.A., & Jeukendrup A.E. Pre-exercise carbohydrate and fat ingestion: effects on metabolism and performance. J Sport Sci 2004;22:31-38. doi10.1080/0264041031000140536
Jeukendrup A.E., C. Killer S.C. The myths surrounding pre-exercise carbohydrate feeding. Ann Nutr Metab 2010;57(suppl 2):18-25. doi:10.1159/000322698
Moseley L., Lancaster G.I, Jeukendrup A.E. Effects of timing of pre-exercise ingestion of carbohydrate on subsequent metabolism and cycling performance. Eur J Appl Physiol 2003;88:453-458. doi:10.1007/s00421-002-0728-8
“The acid-ash hypothesis posits that protein and grain foods, with a low potassium intake, produce a diet acid load, net acid excretion, increased urine calcium, and release of calcium from the skeleton, leading to osteoporosis.” (Fenton et al., 2009, see References).
Is it true?
Calcium, present in bones in form of carbonates and phosphates, represents a large reservoir of base in the body. In response to an acid load such as the high protein diets these salts are released into the circulation to bring about pH homeostasis. This calcium is lost in the urine and it has been estimated that the quantity lost with the such diet over time could be as high as almost 480 g over 20 years or almost half the skeletal mass of calcium!
Even these losses of calcium may be buffered by ingestion of foods that are alkali rich as fruit and vegetables, and on-line information promotes an alkaline diet for bone health as well as a number of books, a recent meta-analysis has shown that the causal association between osteoporotic bone disease and dietary acid load is not supported by evidence and there is no evidence that the alkaline diet is protective of bone health, but it is protective against the risk for kidney stones.
Note: it is possible that fruit and vegetables are beneficial to bone health through mechanisms other than via the acid-ash hypothesis.
What is the role of proteins?
Excess dietary proteins with high acid renal load may decrease bone density, if not buffered by ingestion of foods that are alkali rich, that is fruit and vegetables. However, an adequate protein intake is needed for the maintenance of bone integrity. Therefore, increasing the amount of fruit and vegetables may be necessary rather than reducing protein too much.
Therefore it is advisable to consume a normo-proteic diet rich in fruits and vegetables and poor in sodium, such as medieterranean diet, eating foods with a negative acid load together with foods with a positive acid load. Example: pasta plus vegetables or meats plus vegetables and fruits .
Food and Acid Load
Alkaline diet and muscle mass
As we age, there is a loss of muscle mass, which predispose to falls and fractures. A diet rich in potassium, obtained from fruits and vegetables, as well as a reduced acid load, results in preservation of muscle mass in older men and women.
Alkaline diet and growth hormone
In children, severe forms of metabolic acidosis are associated with low levels of growth hormone with resultant short stature. Its correction with potassium or bicarbonate citrate increases growth hormone significantly and improves growth.
In postmenopausal women, the use of enough potassium bicarbonate in the diet to neutralize the daily net acid load resulted in a significant increase in growth hormone and resultant osteocalcin.
Improving growth hormone levels may reduce cardiovascular risk factors, improve quality of life, body composition, and even memory and cognition.
Conclusion
Alkaline diet may result in a number of health benefits.
Increased fruits and vegetables would improve the potassium/sodium ratio and may benefit bone health, reduce muscle wasting, as well as mitigate other chronic diseases such as hypertension and strokes.
The increase in growth hormone may improve many outcomes from cardiovascular health to memory and cognition.
The increase in intracellular magnesium is another added benefit of the alkaline diet; for example, magnesium, required to activate vitamin D, would result in numerous added benefits in the vitamin D systems.
It should be noted that one of the first considerations in an alkaline diet, which includes more fruits and vegetables, is to know what type of soil they were grown in since this may significantly influence the mineral content and therefore their buffering capacity.
References
Fenton T.R., Lyon A.W., Eliasziw M., Tough S.C., Hanley D.A. Meta-analysis of the effect of the acid-ash hypothesis of osteoporosis on calcium balance. J Bone Miner Res 2009;24(11):1835-1840. doi:10.1359/jbmr.090515
Fenton T.R., Lyon A.W., Eliasziw M., Tough S.C., Hanley D.A. Phosphate decreases urine calcium and increases calcium balance: a meta-analysis of the osteoporosis acid-ash diet hypothesis. Nutr J 2009;8:41. doi:10.1186/1475-2891-8-41
Fenton T.R., Tough S.C., Lyon A.W., Eliasziw M., Hanley D.A. “Causal assessment of dietary acid load and bone disease: a systematic review and meta-analysis applying Hill’s epidemiologic criteria for causality.” Nutr J 2011;10:41. doi:10.1186/1475-2891-10-41
Schwalfenberg G.K. The alkaline diet: is there evidence that an alkaline pH diet benefits health? J Environ Public Health 2012; Article ID 727630. doi:10.1155/2012/727630
Life depends on appropriate pH levels around and in living organisms and cells.
We requires a tightly controlled pH level in our serum of about 7.4 to avoid metabolic acidosis and survive. As a comparison, in the past 100 years the pH of the ocean has dropped from 8.2 to 8.1 because of increasing carbon dioxide deposition with a negative impact on life in the ocean.
The pH Scale
Even the mineral content of the food we eat is considerable influenced by the pH of the soil in which plants are grown. The ideal pH of soil for the best overall availability of essential nutrients is between 6 and 7: an acidic soil below pH of 6 may have reduced magnesium and calcium, and soil above pH 7 may result in chemically unavailable zinc, iron, copper and manganese.
Metabolic acidosis and agricultural and industrial revolutions
In the human diet, there has been considerable change from the hunter gather civilization to the present in the pH and net acid load. With the agricultural revolution, in the last 10,000 years, and even more recently with industrialization, in the last 200 years, it has been seen:
an increase in sodium compared to potassium, as the ratio potassium/sodium has reversed from 10 to 1 to a ratio of 1 to 3 in the modern diet, and in chloride compared to bicarbonate;
This results in a diet that may induce metabolic acidosis which is mismatched to the genetically determined nutritional requirements.
Moreover, with aging, there is a gradual loss of renal acid-base regulatory function and a resultant increase in diet-induced metabolic acidosis.
Finally, a high protein low-carbohydrate diet with its increased acid load results in very little change in blood chemistry, and pH, but results in many changes in urinary chemistry: urinary calcium, undissociated uric acid, and phosphate are increased, while urinary magnesium, urinary citrate and pH are decreased.
All this increases the risk for kidney stones.
pH as a protective barrier
The human body has an amazing ability to maintain a steady pH in the blood, with the main compensatory mechanisms being renal and respiratory.
pH levels in the body vary considerably from one area to another. The highest acidity is found in the stomach (pH of 1.35 to 3.5), aiding digestion and protecting against opportunistic microbial organisms.
Skin is quite acidic (pH 4–6.5), providing an acid mantle as a protective barrier against microbial overgrowth. This is also seen in the vagina, where a pH of less than 4.7 helps prevent microbial overgrowth.
The urine have a variable pH from acid to alkaline depending on the need for balancing the internal environment.
Values and role of pH in some body fluids and tissues
Modified from: Schwalfenberg G.K.; see in References
References
Fenton T.R., Lyon A.W., Eliasziw M., Tough S.C., Hanley D.A. Meta-analysis of the effect of the acid-ash hypothesis of osteoporosis on calcium balance. J Bone Miner Res 2009;24(11):1835-1840. doi:10.1359/jbmr.090515
Fenton T.R., Lyon A.W., Eliasziw M., Tough S.C., Hanley D.A. Phosphate decreases urine calcium and increases calcium balance: a meta-analysis of the osteoporosis acid-ash diet hypothesis. Nutr J 2009;8:41. doi:10.1186/1475-2891-8-41
Fenton T.R., Tough S.C., Lyon A.W., Eliasziw M., Hanley D.A. Causal assessment of dietary acid load and bone disease: a systematic review and meta-analysis applying Hill’s epidemiologic criteria for causality. Nutr J 2011;10:41. doi:10.1186/1475-2891-10-41
Schwalfenberg G.K. The alkaline diet: is there evidence that an alkaline pH diet benefits health? J Environ Public Health 2012; Article ID 727630. doi:10.1155/2012/727630
One of the main functions of the liver is to participate in the maintaining of blood glucose levels within well defined range (in the healthy state before meals 60-100 mg/dL or 3.33-5.56 mmol/L). To do it the liver releases glucose into the bloodstream in:
fasting state;
between meals;
during physical activity.
Blood glucose levels and hepatic glucose 6-phosphatase
In the liver, glycogen is the storage form of glucose which is released from the molecule not as such, but in the phosphorylated form, i.e., with charge, the glucose 1-phosphate. This process is called glycogenolysis.
The phosphorylated molecule can’t freely diffuse from the cell, but in the liver it is present the enzyme glucose-6-phosphatase that hydrolyzes glucose 6-phosphate, produced from glucose 1-phosphate in the reaction catalyzed by phosphoglucomutase, to glucose (an irreversible dephosphorylation).
Then, glucose can diffuse from the hepatocyte, via a transporter into the plasma membrane called GLUT2, into the bloodstream to be delivered to extra-hepatic cells, in primis neurons and red blood cells for which it is the main, and for red blood cells the only energy source. Neurons, with the exception of those in some brain areas that can use only glucose as energy source, can derive energy from another source, the ketone bodies, which becomes predominant during periods of prolonged fasting.
The liver obtains most of the energy required from the oxidation of fatty acids, a class of lipids, and not from glucose.
Glucose-6-phosphatase is present also in the kidney and gut but not in the muscle and brain. Therefore in these tissues glucose-6-phosphate can’t be released from the cell.
Glucose 6-phosphatase plays an important role also in gluconeogenesis.
Glucose 6-phosphatase is present into the membrane of endoplasmic reticulum and the hydrolysis of glucose-6-phosphate occurs into its lumen; therefore this reaction is separated from the process of glycolysis. The presence of a specific transporter, the glucose 6-phosphate translocase, is required to transport the phosphorylated molecule from citosol into the lumen of endoplasmic reticulum. Although a glucose transporter is present into the membrane of endoplasmic reticulum, most of the released glucose is not transported back into the cytosol of the cell but is secreted into the bloodstream. Finally, an ion transporter transports back into the cytosol the inorganic phosphate released into the endoplasmic reticulum.
References
Nelson D.L., M. M. Cox M.M. Lehninger. Principles of biochemistry. 6th Edition. W.H. Freeman and Company, 2012
Roach P.J., Depaoli-Roach A.A., Hurley T.D and Tagliabracci V.C. Glycogen and its metabolism: some new developments and old themes. Biochem J 2012;441:763-787. doi:10.1042/BJ20111416
Stipanuk M.H., Caudill M.A. Biochemical, physiological, and molecular aspects of human nutrition. 3rd Edition. Elsevier health sciences, 2012
The international scientific literature is unanimous in setting the lower limit for the daily caloric intake to 1200 kcal for women and 1500 kcal for men (adults).
To make negative the daily caloric intake, and therefore lose body weight, but expecially lose body fat, evaluation of actual caloric needs of the subject will be alongside:
the correct distribution of meals during the day;
an increased physical activity, by which the negative balance can be achieved without major sacrifices during meals.
Daily Caloric Balance
This will make weight loss easier and protect from subsequent weight gains and yo-yo effect.
Ultimately, there must be a change in lifestyle.
So, the best strategy for losing body fat is not a drastic reduction in caloric intake, nor follow constrictive or “strange” diets, such as hcg diet plan, sacred heart diet, paleo diet, etc., that require to eliminate or greatly reduce the intake of certain macronutrients, mostly carbohydrates. Such conducts can be:
very stressful from psychological point of view;
not passable for long periods;
hazardous to health because of inevitable nutrient deficiencies.
Finally, they do not ensure that all the weight lost is only or almost only body fat and are often followed by substantial increases in body weight and/or by yo-yo effect.
Why?
Body fat and reduction of energy intake
An excessive reduction of energy intake means eating very little. This determines the risk, high, not to take adequate amounts of the various essential nutrients, that is, what we can’t synthesize, such as vitamins, certain amino acids, essential fatty acids, a class of lipids, and minerals, including, e.g., calcium and iron. This results in a depression of metabolism and hence a reduction in energy expenditure. Whether the reduction in energy intake is excessive, or even there are periods of fasting, it adds insult to injury because a proportion of free fatty mass will be lost. How?
Reduction in energy intake and role of carbohydrates
Glucose is the only energy source for red blood cells and some brain areas, while other brain areas can also derive energy from ketone bodies, which are a product of the metabolism of fatty acids.
At rest, brain extracts 10 percent of the glucose from the bloodstream, a significant amount, about 75 mg/min., considering that its weight is about 1.5 kg. To maintain a constant glycemia, and thus ensure a constant supply of glucose to tissues, we needs to take carbohydrates or alternatively amino acids..
In the case of a low or absent dietary intake of carbohydrates, whereas after about 18 hours liver glycogen, which releases glucose into circulation, depletes, body synthesizes de novo glucose from certain amino acids through a process called gluconeogenesis (actually this metabolic pathway is active even after a normal meal but increases its importance in fasting).
But what’s the main source of amino acids in the body when their dietary intake is low or absent? Endogenous proteins, and there is a hierarchy in their use that is before we consume the less important and only after the most important ones. For the first digestive enzymes, pepsin, chymotrypsin, elastase, carboxypeptidase and aminopeptidase, around 35-40 g, will be used. Successively, liver and pancreas slow down their synthesis activities for export proteins and unused amino acids are directed to gluconeogenesis. It’s clear that these are quite modest reserves of amino acids and it is the muscle that will undertake to provide the required amounts of amino acids that is proteolysis of muscle proteins begins.
Note: anyway, there is no absolute sequentiality in the degradation of several proteins, there is instead a plot in which, proceeding, some ways lose their importance and others will buy.
Therefore, to maintain constant glycemia the protein component of muscle is reduced, including skeletal muscle that is a tissue that represents a fairly good portion of the value of the basal metabolism and that, with exercise, can significantly increase its energy consumption: thus essential for weight loss and subsequent maintenance. It is as if the engine capacity was reduced.
One thing which we don’t think about is that heart is a muscle that may be subject to the same processes seen for skeletal muscle.
Ultimately make glucose from proteins, also food-borne, is like heat up the fire-place burning the furniture of the eighteenth century, amino acids, having available firewood, dietary carbohydrates.
Therefore, an adequate intake of carbohydrates with diet prevents excessive loss of proteins, namely, there is a saving effect of proteins played by carbohydrates.
Mammals, and therefore humans, can’t synthesize glucose from fats.
What goes in when carbohydrates goes out?
The elimination or substantial reduction in carbohydrate intake in the diet results in an increased intake of proteins, lipids, including cholesterol, because it will increase the intake of animal products, one of the main defects in hyperproteic diet. In the body there are no amino acids reserves, thus they are metabolized and, as a byproduct of their use, ammonia is formed and it’ll be eliminated as toxic.
For this reason high-protein diets imply an extra work for liver and kidneys and also for this they are not without potential health risks.
An increased fat intake often results into an increased intake of saturated fatty acids, trans fatty acids, and cholesterol, with all the consequences this may have on cardiovascular health.
What has been said so far should not induce to take large amounts of carbohydrates; this class of macronutrients should represent 55-60 percent of daily calories, fats 25-30 percent, primarily olive oil, and the remainder proteins: thus a composition in macronutrient that refers to prudent diet or mediterranean diet.
Body fat and the entry in a phase of famine/disease
A excessive reduction in caloric intake is registered by our defense mechanisms as an “entry” in a phase of famine/disease.
The abundance of food is a feature of our time, at least in industrialized countries, while our body evolved over hundreds of thousands of years during which there was no current abundance: so it’s been programmed to try to overcome with minimal damage periods of famine. If caloric intake is drastically reduced it mimics a famine: what body does is to lower consumption, lower the basal metabolism, that is, consumes less and therefore also not eating much we will not get great results. It is as if a machine is lowered the displacement, it’ll consume less (our body burns less body fat).
Yo-yo effect
Yo-yo effect or weight cycling, namely, repeated phases of loss and weight gain, appears related to excess weight and accumulation of fat in the abdomen.
Several studies suggest a link in women with:
Lastly, yo-yo effect is related to a greater easy to gain weight than those who are not subject to it. In this regard there should be emphasized that the weight cycling occurs over years, during which, aging, the rate of metabolism inevitably tends to decrease: this could make more difficult the subsequent losses.
References
Cereda E., Malavazos A.E., Caccialanza R., Rondanelli M., Fatati G. and Barichella M. Weight cycling is associated with body weight excess and abdominal fat accumulation: a cross-sectional study. Clin Nutr 2011;30(6):718-723. doi:10.1016/j.clnu.2011.06.009
Montani J-P., Viecelli A.K., Prévot A. & Dulloo A.G. Weight cycling during growth and beyond as a risk factor for later cardiovascular diseases: the ‘repeated overshoot’ theory. Int J Obes (Lond) 2006;30:S58-S66. doi:10.1038/sj.ijo.0803520
Ravussin E., Lillioja S., Knowler W.C., Christin L., Freymond D., Abbott W.G.H., Boyce V., Howard B.V., and Bogardus C. Reduced rate of energy expenditure as a risk factor for body-weight gain. N Engl J Med 1988;318:467-472. doi:10.1056/NEJM198802253180802
Sachiko T. St. Jeor S.T. St., Howard B.V., Prewitt T.E., Bovee V., Bazzarre T., Eckel T.H., for the AHA Nutrition Committee. Dietary Protein and Weight Reduction. A Statement for Healthcare Professionals From the Nutrition Committee of the Council on Nutrition, Physical Activity, and Metabolism of the American Heart Association. Circulation 2001;104:1869-1874. doi:10.1161/hc4001.096152
When excess calories are consumed from carbohydrates or proteins, such surplus is used to synthesize fatty acids and then triacylglycerols, while it doesn’t occur if the excess come from fats.
De novo fatty acid synthesis in plants and animals
De novofatty acid synthesis is largely similar among plants and animals. It occurs in chloroplasts of photosynthetic cells of higher plants, and in cytosol of animal cells by the concerted action of two enzymes: acetyl-CoA carboxylase (EC 6.4.1.2) and fatty acid synthase (EC 2.3.1.85).
Fatty acid synthase catalyzes a repeating four-step sequence by which the fatty acyl chain is extended by two carbons, at the carboxyl end, every each passage through the cycle; this four-step process is the same in all organisms.
In animals, the primary site for lipid metabolism is liver, not the adipose tissue. However, adipose tissue is a major organ system in which fatty acid synthesis occurs, though in humans it is less active than in many other animal species.
It should be noted that in certain plants, such as palm and coconut, chain termination occurs earlier than palmitic acid release: up to 90 percent of the fatty acids produced and then present in the oils of these plants are between 8 (caprylic acid) and 14 (myristic acid) carbons long (palmitic acid: 16 carbon atoms).
Synthesis of long chain saturated and unsaturated fatty acids
Palmitic acid is the commonest saturated fatty acid in plant and animal lipids. Generally it is not present in very large proportions because it may be undergo into several metabolic pathways.
In fact:
it is the precursor of stearic acid;
it may be desaturated to palmitoleic acid, the precursor of all fatty acids of omega-7 or n-7 family, in a reaction catalyzed by Δ9-desaturase (EC 1.14.19.1), an ubiquitous enzyme in both plant and animal kingdoms and the most active lipid enzyme in mammalian tissues, the same enzyme that catalyzes the desaturation of stearic acid to oleic acid. Note: Δ9-desaturase inserts double bounds in the 9-10 position of the fatty acid carbon chain, position numbered from the carboxyl end of the molecule, and:
if the substrate is palmitic acid, the double bond is inserted between n-7 and n-8 position of the chain, so producing palmitoleic acid, the founder of omega-7 series;
if the substrate is stearic acid, the double bond is inserted between n-9 and n-10 position of the chain and oleic acid will be produced.
It may be esterified into complex lipids.
Of course, in plants and animals there are fatty acids longer and/or more unsaturated than these just seen thanks to modification systems that catalyze reactions of fatty acid synthesis that are organism- tissue- and cell- specific.
For example, stearic acid may be:
elongated to arachidic acid, behenic acid and lignoceric acid, all saturated fatty acids, in reactions catalyzed by elongases. Again, chain elongation occurs, both in mitochondria and in the smooth endoplasmic reticulum, by the addition of two carbon atom units at a time at the carboxylic end of the fatty acid through the action of fatty acid elongation systems (particularly long and very long saturated fatty acids, from 18 to 24 carbon atoms, are synthesized only on cytosolic face of the smooth endoplasmic reticulum);
desaturated, as seen, to oleic acid, an omega-9 or n-9 fatty acid, in a reaction catalyzed by Δ9-desaturase.
Several researchers have postulated that the reason for which stearic acid does not concur to hypercholesterolemia is its rapid conversion to oleic acid.
Oleic acid is the start point for the synthesis of many other unsaturated fatty acids by reactions of elongation and/or desaturation.
In fact:
gadoleic acid, erucic acid and nervonic acid, all monounsaturated fatty acids. Saturated fatty acids, and unsaturated fatty acids of the omega-9 series, usually oleic acid (but also palmitoleic acid and other omega-7 fatty acids) are the only fatty acids produced de novo in mammal systems.
Thanks to the consecutive action of the enzymes Δ12-desaturase (1.14.19.6) and Δ15-desaturase (EC 1.14.19.25), that insert a double bond respectively in the 12-13 and 15-16 position of the carbon chain of the fatty acid, oleic acid is converted first to linoleic acid, founder of all the omega-6 polyunsaturated fatty acids, and then to alpha-linolenic acid, founder of all the omega-3 polyunsaturated fatty acids (omega-3 and omega-6 PUFA that will be produced from these precursors through repeating reactions of elongation and desaturation).
In the case of essential fatty acid (EFA) deficiency, oleic acid may be desaturated and elongated to omega-9 polyunsaturated fatty acids, with accumulation especially of Mead acid.
Omega-3 and omega-6 PUFA synthesis
Animal tissues can desaturate fatty acids in the 9-10 position of the chain, thanks to the presence of Δ9 desaturase; as previously seen, if the substrate of the reaction is palmitic acid, the double bond will appear between n-7 and n-8 position, with stearic acid between n-9 and n-10 position, so leading to formation respectively of palmitoleic acid and oleic acid.
Animals lack Δ12- and Δ15-desaturases, enzymes able to desaturate carbon carbon bonds beyond the 9-10 position of the chain. For these reason, they can’t produce de novo omega-3 and omega-6 PUFA (which have double bonds also beyond the 9-10 position), that are so essential fatty acids.
Δ12- and Δ15-desaturases are present in plants; though many land plants lack Δ15-desaturase, also called omega-3 desaturase, planktons and aquatic plants in colder water possess it and produce abundant amounts of the omega-3 fatty acids.
References
Akoh C.C. and Min D.B. “Food lipids: chemistry, nutrition, and biotechnology”. CRC Press Taylor & Francis Group, 2008 3th ed. 2008
Bender D.A. “Benders’ dictionary of nutrition and food technology”. 2006, 8th Edition. Woodhead Publishing. Oxford
Burr G.O. and Burr M.M. A new deficiency disease produced by the rigid exclusion of fat from the diet. Nutr Rev 1973;31(8):148-149. doi:10.1111/j.1753-4887.1973.tb06008.x
Chow Ching K. “Fatty acids in foods and their health implication”. 3rd Edition. CRC Press Taylor & Francis Group, 2008
Rosenthal M.D., Glew R.H. Mediacal biochemistry. Human metabolism in health and disease. John Wiley & Sons, Inc. 2009
Stipanuk M.H., Caudill M.A. Biochemical, physiological, and molecular aspects of human nutrition. 3rd Edition. Elsevier health sciences, 2012
Muscle glycogen is an important energy source for prolonged moderate to high intensity exercise, an importance that increases during high-intensity interval exercise, common in training session of swimmers, runners, rowers or in team-sport players, or during resistance exercise. For example, considering marathon, about 80% of energy needed comes from carbohydrate oxidation, for the most part skeletal muscle glycogen.
Fatigue and low muscle glycogen levels are closely correlated, but the underlying molecular mechanisms remain elusive. One hypothesis is that there is a minimum glycogen concentration that is “protected” and is not used during exercise, perhaps to ensure an energy reserve in case of need.
Due to the closely relationship between skeletal muscle glycogen depletion and fatigue, its re-synthesis rate during post-exercise is one of the most important factors in determining necessary recovery time.
Finally, the highly trained athlete has muscle glycogen stores potentially higher and is also able to synthesize it faster due to more efficient enzymes.
Glycogen Molecule: the Branched Structure, the Tiers, and Glycogenin
To synthesize glycogen it is necessary to ingest carbohydrates; but how many, which, when, and how often?
The two phases of muscle glycogen synthesis after exercise
In order to restore as quickly as possible muscle glycogen depots, it is useful to know that, as a result of training sessions that deplete muscle glycogen to values below 75 percent those at rest and not fasting, glycogen synthesis occurs in two phases.
To know and therefore take advantage of the biphasicity is important for those athletes who are engaged in more daily training sessions, or who otherwise have little time for recovery between a high intensity exercise and the subsequent one, less than 8 hours, in order to maximize glycogen synthesis and achieve the optimal performance during a second close exercise session.
The two phases are characterized by:
a different sensitivity to circulating insulin levels;
a different velocity.
The first phase
This phase, immediately following the end of an activity and lasting 30-60 minutes, is insulin-independent, i.e., glucose uptake by muscle cell as glycogen synthesis are independent from hormone action. It is characterized by an elevated rate of synthesis that however decreases rapidly if you do not take in carbohydrates: the maximum rate is in the first 30 minutes, then declines to about one fifth in 60 minutes, and to about one ninth in 120 minutes from the end of exercise.
How is it possible to take advantage of this first phase to replenish muscle glycogen stores as much as possible? By making sure that the greatest possible amount of glucose arrives to muscle in the phase immediately following to the end of exercise, best if done within the first 30 minutes.
What should one eat?
High glycemic index, but easy to digest and absorb, carbohydrates. Therefore, it is advisable to replace foods, even though of high glycemic index, that need some time for digestion and the subsequent absorption, with solutions/gel containing for example glucose and/or sucrose. These solutions ensure the maximal possible absorption rate and resupply of glucose to muscle because of they contain only glucose and are without fiber or anything else that could slow carbohydrate digestion and the following absorption of monosaccharides, that is, they are capable of producing high blood glucose levels in a relatively short time.
It is also possible to play on temperature and concentration of the solution to accelerate the gastric transit.
It should be further underlined that the use of these carbohydrate solutions is recommended only when the recovery time from a training/competition session causing significant depletion of muscle glycogen and the following one is short, less than 8 hours.
How many carbohydrates do you need?
Many studies has been conducted to find the ideal amount of carbohydrates to ingest.
If in post-exercise the athlete does not eat, glycogen synthesis rate is very low, while if he ingests adequate amounts of carbohydrates immediately after cessation of exercise, synthesis rate can reach a value over 20 times higher.
From the analysis of scientific literature, it seems reasonable to state that, as a result of training sessions that deplete muscle glycogen stores as seen above (<75 percent of those at rest and not fasting), the maximum synthesis rate is obtained by carbohydrate intake, with high glycemic index and high digestion and absorption rates, equal to about 1.2 g/kg of body weight/h for the next 4-5 hours from the end of exercise. In this way, the amount of glycogen produced is higher than 150 percent compared to the ingestion of 0.8 g/kg/h.
Because further increases, up to 1.6 g/kg/h, do not lead to further rise in glycogen synthesis rate, the carbohydrate amount equal to 1.2 g/kg/h can be considered optimum to maximize the resynthesis rate of muscle glycogen stores during post-exercise.
What is the optimal frequency of carbohydrate intake?
It was observed that if carbohydrates are ingested frequently, every 15-30 minutes, it seems there is a further stimulation of muscle glucose uptake as of muscle glycogen replenishment compared with ingestion at 2-hours intervals. Particularly, ingestions in the first post-exercise hours seem to optimize glycogen levels.
The second phase
The second phase begins from the end of the first, lasts until the start of the last meal before the next exercise, hence, from several hours to days, and is insulin-dependent i.e. muscle glucose uptake and glycogen synthesis are sensitive to circulating hormone levels.
Moreover, you observe a significant reduction in muscle glycogen synthesis rate: with adequate carbohydrate intake the synthesis rate is at a value of about 10-30 percent lower than that observed during the first phase.
This phase can last for several hours, but tends to be shorter if:
carbohydrate intake is high;
glycogen synthesis is more active;
muscle glycogen levels are increased.
In order to optimize the resynthesis rate of glycogen, experimental data indicate that meals with high glycemic index carbohydrates are more effective than those with low glycemic index carbohydrates; but if between a training/competition session and the subsequent one days and not hours spend, the evidences do not favor high glycemic index carbohydrates as compared to low glycemic index ones as long as an adequate amount is taken in.
Muscle glycogen synthesis rate and ingestion of carbohydrates and proteins
The combined ingestion of carbohydrates and proteins, or free insulinotropic amino acids, allows to obtain post-exercise glycogen synthesis rate that does not significantly differ from that obtained with larger amounts of carbohydrates alone. This could be an advantage for the athlete who may ingest smaller amount of carbohydrates, therefore reducing possible gastrointestinal complications commons during training/competition afterward to their great consumption.
From the analysis of scientific literature it seems reasonable to affirm that, after an exercise that depletes at least 75 percent of muscle glycogen stores, you can obtain a glycogen synthesis rate similar to that reached with 1.2 g/kg/h of carbohydrates alone (the maximum obtainable) with the coingestion of 0.8 g/kg/h of carbohydrates and 0.4 g/kg /h of proteins, maintaining the same frequency of ingestion, therefore every 15-30 minutes during the first 4-5 hours of post-exercise.
The two phases: molecular mechanisms
The biphasicity is consequence, in both phases, of an increase in:
glucose transport rate into cell;
the activity of glycogen synthase, the enzyme that catalyzes glycogen synthesis.
However, the molecular mechanisms underlying these changes are different. In the first phase, the increase in glucose transport rate, independent from insulin presence, is mediated by the translocation, induced by the contraction, of glucose transporters, called GLUT4, on the cytoplasmatic membrane of the muscle cell. In addition, the low glycogen levels also stimulate glucose transport as it is believed that a large portion of transporter-containing vesicles are bound to glycogen, and therefore they may become available when its levels are depleted. Finally, the low muscle glycogen levels stimulate glycogen synthase activity too: it has been demonstrated that these levels are a regulator of enzyme activity far more potent than insulin.
In the second phase, the increase in muscle glycogen synthesis is due to insulin action on glucose transporters and on glycogen synthase activity of muscle cell. This sensibility to the action of circulating insulin, that can persist up to 48 hours, depending on carbohydrate intake and the amount of resynthesized muscle glycogen, has attracted much attention: it is in fact possible, through appropriate nutritional intervention, to increase the secretion in order to improve glycogen synthesis itself, but also protein anabolism, reducing at the same time the protein-breakdown rate.
Glycogen synthesis rate and insulin
The coingestion of carbohydrates and proteins, or free amino acids, increases postprandial insulin secretion compared to carbohydrates alone. In some studies there was an increase in hormone secretion 2-3 times higher compared to carbohydrates alone).
It was speculated that, thanks to the higher circulating insulin concentrations, further increases in post-exercise glycogen synthesis rate could be obtained compared to those observed with carbohydrates alone, but in reality it does not seem so. In fact, if carbohydrate intake is increased to 1.2 g/kg/h plus 0.4 g/kg/h of proteins no further increases in glycogen synthesis rate are observed if compared to those obtained with the ingestion of carbohydrates alone in the same amount, 1,2 g/kg/h, that, as mentioned above, like the coingestion of 0,8 g/kg/h of carbohydrates and 0,4 g/kg/h of proteins, allows to attain the maximum achievable rate in post-exercise, or in isoenergetic quantities, that is, 1.6 g/kg.
Insulin and preferential carbohydrate storage
The greater circulating insulin levels reached with the coingestion of carbohydrates and proteins, or free amino acids, might stimulate the accumulation of ingested carbohydrates in tissues most sensitive to its action, such as liver and previously worked muscle, thus resulting in a more efficient storage, for the purposes of sport activity, of the same carbohydrates.
References
Beelen M., Burke L.M., Gibala M.J., van Loon J.C. Nutritional strategies to promote postexercise recovery. Int J Sport Nutr Exerc Metab 2010:20(6);515-532. doi:10.1123/ijsnem.20.6.515
Berardi J.M., Noreen E.E., Lemon P.W.R. Recovery from a cycling time trial is enhanced with carbohydrate-protein supplementation vs. isoenergetic carbohydrate supplementation. J Intern Soc Sports Nutrition 2008;5:24. doi:10.1186/1550-2783-5-24
Betts J., Williams C., Duffy K., Gunner F. The influence of carbohydrate and protein ingestion during recovery from prolonged exercise on subsequent endurance performance. J Sports Sciences 2007;25(13):1449-1460. doi:10.1080/02640410701213459
Howarth K.R., Moreau N.A., Phillips S.M., and Gibala M.J. Coingestion of protein with carbohydrate during recovery from endurance exercise stimulates skeletal muscle protein synthesis in humans. J Appl Physiol 2009:106;1394–1402. doi:10.1152/japplphysiol.90333.2008
Jentjens R., Jeukendrup A. E. Determinants of post-exercise glycogen synthesis during short-term recovery. Sports Medicine 2003:33(2);117-144. doi:10.2165/00007256-200333020-00004
Millard-Stafford M., Childers W.L., Conger S.A., Kampfer A.J., Rahnert J.A. Recovery nutrition: timing and composition after endurance exercise. Curr Sports Med Rep 2008;7(4):193-201. doi:10.1249/JSR.0b013e31817fc0fd
Price T.B., Rothman D.L., Taylor R., Avison M.J., Shulman G.I., Shulman R.G. Human muscle glycogen resynthesis after exercise: insulin-dependent and –independent phases. J App Physiol 1994:76(1);104–111. doi:10.1152/jappl.1994.76.1.104
Schweitzer G.G., Kearney M.L., Mittendorfer B. Muscle glycogen: where did you come from, where did you go? J Physiol 2017;595(9):2771-2772. doi:10.1113/JP273536
van Loon L.J.C., Saris W.H.M., Kruijshoop M., Wagenmakers A.J.M. Maximizing postexercise muscle glycogen synthesis: carbohydrate supplementation and the application of amino acid or protein hydrolysate mixtures. Am J Clin Nutr 2000;72: 106-111. doi:10.1093/ajcn/72.1.106
Omega-6 polyunsaturated fatty acids are the major polyunsaturated fatty acids or PUFA in the Western diet (about 90% of all of them in the diet), being components of most animal and vegetable fats.
Within the omega-6 family, linoleic acid is one of the most important and widespread fatty acids and the precursor of all omega-6 polyunsaturated fatty acids. It is produced de novo from oleic acid, an omega-9 fatty acid, only by plant in a reaction catalyzed by Δ12-desaturase, i.e. the enzyme that forms the omega-6 polyunsaturated fatty acid family from omega-9 one.
Δ12-desaturase catalyzes the insertion of the double bond between carbon atoms 6 and 7, numbered from the methyl end of the molecule.
Linoleic acid, together with alpha-linolenic acid, is a primary product of plant polyunsaturated fatty acids synthesis.
Omega-6 Polyunsaturated Fatty Acid Metabolism
Animals, lacking Δ12-desaturase, can’t synthesize it, and all the omega-6 polyunsaturated fatty acid family de novo, and they are obliged to obtain it from plant foodstuff and/or from animals that eat them; for this reason omega-6 polyunsaturated fatty acid are considered essential fatty acids, so called EFAs.
The essentiality of omega-6 polyunsaturated fatty acids, in particular just the essentiality of linoleic acid, was first reported in 1929 by Burr and Burr.
Omega-6 PUFA: from linoleic acid to arachidonic acid
Animals are able to elongate and desaturase dietary linoleic acid in a cascade of reactions to form very omega-6 polyunsaturated fatty acids.
Linoleic acid is first desaturated to gamma-linolenic acid, another important omega-6 fatty acid with significant physiologic effects, in the reaction catalyzed by Δ6-desaturase. It is thought that the rate of this reaction is limiting in certain conditions like in the elderly, under certain disease states and in premature infants; for this reason, and because it is found in relatively small amounts in the diet, few oils containing it, such as black currant, evening primrose, and borage oils, have attracted attention.
In turn gamma-linolenic acid may be elongated to dihomo-gamma-linolenic acid by an elongase. The enzyme catalyzes the addition of two carbon atoms from glucose metabolism to lengthen the fatty acid chain that may be further desaturated in a very limited amount to arachidonic acid, in a reaction catalyzed by another rate limiting enzyme, Δ5-desaturase.
Arachidonic acid can be elongated and desaturated to adrenic acid.
It should be noted that polyunsaturated fatty acids in the omega-6 family, and in any other n-families, can be interconverted by enzymatic processes only within the same family, not among families.
C-20 polyunsaturated fatty acids belonging to omega-6 and omega-3 polyunsaturated fatty acids are the precursors of eicosanoids (prostaglandins, prostacyclin, thromboxanes, and leukotrienes), powerful, short-acting, local hormones.
While the deprivation of omega-3 polyunsaturated fatty acids causes dysfunction in a wide range of behavioral and physiological modalities, the omission in the diet of omega-6 polyunsaturated fatty acids results in manifest systemic dysfunction.
In plant seed oils omega-6 fatty acids with chain length longer than 18 carbons are present only in trace while arachidonic acid is found in all animal tissues and animal-based food products.
References
Akoh C.C. and Min D.B. “Food lipids: chemistry, nutrition, and biotechnology” 3th ed. 2008
Aron H. Uber den Nahvert (On the nutritional value). Biochem Z. 1918;92:211–233 (German)
Bender D.A. “Benders’ dictionary of nutrition and food technology”. 2006, 8th Edition. Woodhead Publishing. Oxford
Bergstroem S., Danielsson H., Klenberg D. and Samuelsson B. The enzymatic conversion of essential fatty acids into prostaglandins. J Biol Chem 1964;239:PC4006-PC4008.
Burr G.O. and Burr M.M. A new deficiency disease produced by the rigid exclusion of fat from the diet. Nutr Rev 1973;31(8):148-149. doi:10.1111/j.1753-4887.1973.tb06008.x
Chow Ching K. “Fatty acids in foods and their health implication” 3th ed. 2008
Rosenthal M.D., Glew R.H. Mediacal biochemistry. Human metabolism in health and disease. John Wiley & Sons, Inc. 2009
Stipanuk M.H., Caudill M.A. Biochemical, physiological, and molecular aspects of human nutrition. 3rd Edition. Elsevier health sciences, 2012
Van D., Beerthuis R.K., Nugteren D.H. and Vonkeman H. Enzymatic conversion of all-cis-polyunsaturated fatty acids into prostaglandins. Nature 1964;203:839-841
Omega-3 polyunsaturated fatty acids or omega-3 PUFAs or omega-3 fatty acids are unsaturated fatty acids, hence lipids, that have a double bond three carbons from the methyl end of the carbon chain.[3]
eicosapentaenoic acid (EPA) or 20:5n-3, with 20 carbon atoms and 5 double bonds;
docosahexaenoic acid (DHA) or 22:6n-3, that, with 22 carbon atoms and 6 double bonds, is the most complex.
EPA and DHA are termed long-chain polyunsaturated fatty acids (LC-PUFAs).
Mammals cannot synthesize linoleic acid or LA and alpha-linolenic acid, the precursors to omega-6 polyunsaturated fatty acids and omega-3 PUFAs, respectively, due to the lack of two desaturases: delta-12 desaturase (EC 1.14.19.6) and delta-15 desaturase or omega-3 desaturase or fatty acid desaturase 3 (EC 1-14.19.13).[9] Such desaturases insert double bonds at positions 6 and 3 from the methyl end of the molecule, respectively. Linoleic acid and alpha-linolenic acid are therefore essential fatty acids.[34]
Humans and many other animals can produce, from dietary ALA, all the other omega-3 polyunsaturated fatty acids. Then, such omega-3 PUFAs become essential in the absence of dietary ALA, and for this reason they are termed conditionally essential fatty acids.[9]
EPA and DHA are important structural components of cell membranes, where they are mainly found, especially in muscle and nerve tissues.[35] Conversely, many other fatty acids are stored mainly in adipose tissue triglycerides.
DHA is the main component of cell membrane phospholipids of neural tissues of vertebrates, including photoreceptor of the retina, where it performs important functions.[22][26][29][32] In addition to their structural functions, omega-3 PUFAs are substrates for the production of bioactive lipid mediators with anti-inflammatory action, such as eicosanoids, maresins, resolvins, and protectins.[10][21]
Omega-3 polyunsaturated fatty acids are essential in neurological development of the fetus, and their intake during pregnancy is especially important in the third trimester of pregnancy, when significant brain growth occurs.[8] In the course of life their intake has been associated with a reduction in the risk of developing many chronic diseases, particularly cardiovascular diseases.[1][27][33]
The major dietary sources for humans are fishery products, especially those obtained from cold waters.[3][9][36]
Alpha-linolenic acid is produced from linoleic acid, an omega-6 PUFAs, in the plastids of phytoplankton and vascular terrestrial plants, where delta-15 desaturase inserts a double bond between carbon 3 and 4 from the methyl end of LA.[3][9]
In turn, ALA undergoes desaturation reactions, catalyzed by delta-5 desaturase (EC 1.14.19.44) and delta-6 desaturase (EC 1.14.19.3), elongation reactions, catalyzed by elongase 5 (EC 2.3.1.199) and elongase 5 and/or by elongase 2 (EC 2.3.1.199), and a limited beta-oxidation in peroxisomes, to produce DHA.[6][8]
Note that vascular terrestrial plants do not have the ability to synthesize long chain omega-3 PUFA, such as EPA and DHA.[23]
Omega-3 Fatty Acid Metabolism
The enzymes that catalyze the conversion of ALA to DHA are shared with the synthetic pathways leading to the synthesis of omega-6, omega-7 and omega-9 PUFAs.[9]
Omega-3 PUFAs appear to be the preferred substrates for delta-5 desaturase and delta-6 desaturase. However, because in many Western diets there is a high intake of linoleic acid relative to alpha-linolenic acid intake, the omega-6 pathway would be preferred over the other pathways.[38] This could be one of the explanations for the low conversion rate of alpha-linolenic acid into the other omega-3 PUFAs, although the synthesis of arachidonic acid (ARA) from linoleic acid seems to be very low, too.
Note that both the omega-3 and omega-6 families inhibit the synthesis of omega-9 polyunsaturated fatty acids.
Omega-3 biosynthesis in humans
Humans, like many other animals, can convert alpha-linolenic acid to docosahexaenoic acid, a metabolic pathway found mainly in the liver and cerebral microcirculation of the hematoencephalic barrier, but also in the cerebral endothelium and astrocytes.[18] It is common opinion that humans, like other terrestrial animals, have a limited capacity to synthesize LC-PUFAs, and therefore need an adequate intake of EPA and DHA from food.[7]
It has been shown that the yield of the synthesis decreases along the pathway: the rate of conversion of alpha-linolenic acid to eicosapentaenoic acid is low, and the limiting factor seems to be the activity of delta-6 desaturase, and the rate of conversion to docosahexaenoic acid is extremely low.[7] However recent studies have demonstrated the existence of a marked polymorphism in the fatty acid desaturase (FADS) gene cluster, especially for the contiguous genes FADS1 and FADS2 coding for delta-5 desaturase and delta-6 desaturase, respectively, which are present on chromosome 11q12.2.[6]
By analyzing genome-wide sequencing data from Bronze Age individuals and present-day Europeans, a comprehensive overview was obtained of the changes in allele frequency of FADS genes.[25]
In European populations, the transition from a hunter-gatherer society to an agricultural society would have resulted in an increase in the intake of linoleic acid and alpha-linolenic acid, and a reduction in the intake of EPA and ARA. Natural selection would then have favored the haplotype associated with the increase in the expression of FADS1 and the decrease in the expression of FADS2.[6]
This pattern is opposite to that found in the Greenlander Inuit, where it is hypothesized that natural selection would have favored alleles associated with a decrease in the rate of conversion of linoleic acid and alpha-linolenic acid into LC-PUFAs, in order to compensate for their relatively high dietary intake in such population.[13]
Do other animals need EPA and DHA?
Organisms lacking delta-15 desaturase cannot synthesize alpha-linolenic acid and hence the other omega-3 PUFAs, and, if needed, must obtain it from dietary sources. However, many animals do not need to get EPA and DHA from diet.
Terrestrial herbivorous vertebrates satisfy their need for long chain omega-3 polyunsaturated fatty acids by synthesizing them from alpha-linolenic acid obtained from the green parts of plants.[19]
And there are animals that do not need EPA and DHA, and practically do not have them. These include terrestrial insects, that have very low levels of EPA. In such animals, EPA is synthesized from dietary alpha-linolenic acid and used for eicosanoid production.[16]
Conversely, aquatic insects have high levels of EPA, whereas DHA is practically absent.[31]
Some classes of phytoplankton, such as Cryptophyceae and Dinophyceae, are very rich in EPA and DHA, whereas Bacillariophyceae or diatoms are very rich in EPA. In general, microalgae are the primary producers of EPA and DHA, and then, aquatic ecosystems are the main source of omega-3 LC-PUFAs in the biosphere.[2][28] EPA and DHA are then transferred from these microalgae along the food chain, from invertebrates to fish, and from fish to terrestrial animals, including humans. So, from microalgae to humans.[16]
Benefits for humans
Omega-3 polyunsaturated fatty acids are essential components of a healthy and balanced diet.[36] They are needed throughout development, starting from fetal life, and are associated with health improvements and reduced risk of disease.[8][26]
Indeed, many epidemiological studies have associated high intake of EPA and DHA with a lower cardiovascular mortality, especially for cardiac diseases, than predicted, probably due to the improvements in many risk factors such as plasma levels of triglycerides, HDL-cholesterol, C-reactive protein, blood pressure, both systolic and diastolic, and heart rate.[1][27]
EPA and DHA have also been shown to be useful in the treatment of diseases such as rheumatoid arthritis, and could be useful in the treatment of other inflammatory conditions such as asthma, psoriasis or inflammatory bowel disease, due to their ability to modulate many aspects of the inflammatory processes.[33]
Conversely, LC-PUFAs seem to have little or no effects on measures of glucose metabolism, such as insulin, insulin resistance, fasting glucose, and glycated haemoglobin, or on type 2 diabetes.[5]
Omega-3/omega-6 ratio
Epidemiological studies suggest that the consumption of a diet with a low omega-3/omega-6 ratio has had a negative impact on human health, contributing to the development, together with other risk factors such as sedentary life and smoking, of the main classes of diseases.[8]
Indeed, a lower incidence of cancer, autoimmunity and coronary heart disease has been observed in populations whose diet has a high omega-3/omega-6 ratio, such as Eskimos and Japanese, populations with a high fish consumption.[20][37]
Despite these evidences, Western diet has become rich in saturated fatty acids and omega-6 polyunsaturated fatty acids, and poor in omega-3 polyunsaturated fatty acids, with an omega-3/omega-6 ratio between 1:10 and 1:20, then, far from the recommended ratio of 1:5.[33]
The low value of the omega-3/omega-6 ratio is due to several factors, some of which are listed below.
Although wild plant foods are generally high in omega-3 PUFAs, crops high in omega-6 PUFAs have been much more successful in industrial agriculture than those high in omega-3 PUFAs.[3]
Low consumption of fishery products and fish oils.[33]
The high consumption of animals raised on corn-based feed, such as chickens, cattle, and pigs. Added to this is the fact that the omega-3 PUFA content of some farmed fish species is lower than that of their wild counterparts.[9]
The high consumption of oils rich in omega-6 PUFAs and poor in omega-3 PUFAs, such as safflower, sunflower, soybeans and corn oils.[4]
Note: there is no evidence that the omega-3/omega-6 ratio is important for prevention and treatment of type 2
diabetes mellitus.[5]
Effects at the molecular level of EPA and DHA
In recent years, the molecular mechanisms underlying the functional effects attributed to omega-3 polyunsaturated fatty acids, especially to EPA and DHA, are being clarified, and most of these require their incorporation into membrane phospholipids.[23]
Omega-3 PUFAs are structural components of cell membranes where they play an essential role in regulating fluidity.[35] Due to this effect, omega-3, especially EPA and DHA, can modulate cellular responses that depend upon membrane protein functions. This is particularly important in the eye, where DHA allows for optimal activity of rhodopsin, a photoreceptor protein.[29] The effect on membrane fluidity is essential for animals living in cold water, as EPA and DHA also have an antifreeze function.
EPA and DHA can modify the formation of lipid raft, microdomains with a specific lipid composition that act as platforms for receptor activities and the initiation of intracellular signaling pathways. By modifying lipid raft formation, they affect intracellular signaling pathways in different cell types, such as neurons, immune system cells, and cancer cells. In this way, EPA and DHA can modulate the activation of transcription factors, such as NF-κB, PPARs and SREBPs, and so the corresponding gene expression patterns. This is central to their role in controlling adipocyte differentiation, the metabolism of fatty acids and triacylglycerols, and inflammation.[8]
ARA, EPA, and DHA are substrates for the synthesis of bioactive lipid mediators, such as eicosanoids, that are involved in the regulation of inflammation, immunity, platelet aggregation, renal function, and smooth muscle contraction.[21]
Eicosanoids produced from arachidonic acid, that is the major substrate for their synthesis, have important physiological roles, but an excessive production has been associated with numerous disease processes.[8] The increase in EPA and DHA content in membrane phospholipids is paralleled by a reduction in ARA content and associated with a decreased production of lipid mediators form ARA and an increased production of lipid mediators from the two omega-3. Moreover, among the molecules derived from EPA and DHA, there are eicosanoids analogous to those produced from ARA, but with lower activity, resolvins, and, from DHA, protectins and maresins. These molecules appear to be responsible for many of the immune-modulating and anti-inflammatory actions attributed to the omega-3 polyunsaturated fatty acids EPA and DHA.[10]
EPA and DHA can also play a role in the non-esterified form, acting directly through receptors coupled to G proteins, modulating their activity.[30]
Finally, they can reduce the intestinal absorption of omega-6 PUFAs, and, at the enzymatic level, competitively inhibit cyclooxygenase-1 or COX-1 (EC 1.14.99.1) and lipoxygenases, and compete with omega-6 PUFAs for acyltransferases.[3]
Major sources of EPA and DHA for humans
In general, fish and aquatic invertebrates, such as molluscs and crustaceans, are the major sources of EPA and DHA for humans.[3][9][36] These animals can get EPA and DHA from food, namely, from phytoplankton, or synthesize them from alpha-linolenic acid.[16] Moreover, DHA is present in high concentrations in many fish oils, too, especially those from coldwater fish. However, it should be underscored that such oils are also high in saturated fatty acids.[24]
For those who do not eat fishery products, good sources of omega-3 LC-PUFAs are the liver of terrestrial animals and several birds of the order Passeriformes.[14][15]
Regarding the recommended intake of omega-3 polyunsaturated fatty acids, it is not yet clear what it is. The following table shows the values suggested by Food and Agriculture Organization (FAO) of the United Nations and the European Food Safety Authority (EFSA).[11][12]
Recommended daily intake of omega-3 polyunsaturated fatty acids by population subgroup (FAO and EFSA)
Organization
Subgroup
Recommendation
FAO
Adult males and non-pregnant or non-lactating adult females
Minimum of 250 mg EPA + DHA daily
Pregnant or lactating females
Minimum of 300 mg EPA + DHA daily of which at least 200 mg should be DHA
Children aged 2-4 years
100-150 mg EPA + DHA daily
Children aged 4-6 years
150-200 mg EPA + DHA daily
Children aged 6-10 years
200-250 mg EPA + DHA daily
EFSA
Adult males and non-pregnant adult females
Adequate intake is 250 mg EPA + DHA daily
Pregnant females
An additional 100-200 mg DHA daily
Infants and children aged 6 months to 2 years
100 mg DHA daily
Children aged 2-18 years
‘‘Consistent with adults’’
Omega-3 and culinary treatments
As omega-3 polyunsaturated fatty acids are particularly susceptible to oxidation due to heating, cooking and other culinary treatments could reduce their content.[3] However, this is only partially true. In food, EPA and DHA are not in free form but mainly esterified into membrane phospholipids and, in such form, are much less susceptible to oxidation.[9]
Considering the content of EPA and DHA, to express it as a percentage of the total fatty acids instead of as absolute content, namely, mg/g wet weight, leads to erroneous conclusions. For example, a fatty fish like salmon has a high EPA + DHA content, ~8 mg/g wet weight, and expressed as a percentage of the total fatty acids ~20 percent; conversely Atlantic code has a low EPA + DHA content, ~3 mg/g of wet weight, but, if expressed as a percentage of the total fatty acids ~40 percent. Atlantic code has a high percentage of EPA + DHA because is a lean fish, whereas in fatty fish EPA + DHA content is diluted by the high fatty acid content of the adipose tissue of the animal.[17]
And when EPA + DHA content is expressed in mg/g of product, no decrease in LC-PUFAs content is observed following most common culinary treatments.[16]
References
^ ab AbuMweis S., Jew S., Tayyem R. Agraib L. Eicosapentaenoic acid and docosahexaenoic acid containing supplements modulate risk factors for cardiovascular disease: a meta-analysis of randomised placebo-control human clinical. J Hum Nutr Diet 2018;31(1):67-84. doi:10.1111/jhn.12493
^ Ahlgren G., Lundstedt L., Brett M., Forsberg C. Lipid composition and food quality of some freshwater phytoplankton for cladoceran zooplankters. J Plankton Res 1990;12(4):809-18. doi:10.1093/plankt/12.4.809
^ abcdefg Akoh C.C. and Min D.B. Food lipids: chemistry, nutrition, and biotechnology. 3th ed. 2008
^ Blasbalg T.L., Hibbeln J.R., Ramsden C.E., Majchrzak S..F, Rawlings R.R. Changes in consumption of omega-3 and omega-6 fatty acids in the United States during the 20th century. Am J Clin Nutr 2011;93(5):950-62. doi:10.3945/ajcn.110.006643
^ ab Brown T.J., Brainard J., Song F., Wang X., Abdelhamid A., Hooper L. Omega-3, omega-6, and total dietary polyunsaturated fat for prevention and treatment of type 2 diabetes mellitus: systematic review and meta-analysis of randomised controlled trials. BMJ 2019;366:l4697. doi:10.1136/bmj.l4697
^ abc Buckley M.T., Racimo F., Allentoft M.E., et al. Selection in Europeans on fatty acid desaturases associated with dietary changes. Mol Biol Evol 2017;34(6):1307-1318. doi:10.1093/molbev/msx103
^ ab Burdge G.C., Wootton S.A. Conversion of α-linolenic acid to eicosapentaenoic, docosapentaenoic and docosahexaenoic acids in young women. Br J Nutr 2002;88(4):411-420. doi:10.1079/BJN2002689
^ abcdef Calder P.C. Very long-chain n-3 fatty acids and human health: fact, fiction and the future. Proc Nutr Soc 2018 77(1):52-72. doi:10.1017/S0029665117003950
^ abcdefgh Chow Ching K. Fatty acids in foods and their health implication. 3th ed. 2008
^ ab Duvall M.G., Levy B.D. DHA- and EPA-derived resolvins, protectins, and maresins in airway inflammation. Eur J Pharmacol 2016;785:144-155. doi:10.1016/j.ejphar.2015.11.001
^ EFSA Panel on Dietetic Products, Nutrition, and Allergies (NDA). Scientific opinion on dietary reference values for fats, including saturated fatty acids, polyunsaturated fatty acids, monounsaturated fatty acids, trans fatty acids, and cholesterol. 2010. doi:10.2903/j.efsa.2010.1461
^ FAO. Global recommendations for EPA and DHA intake (As of 30 June 2014)
^ Fumagalli M., Moltke I., Grarup N., Racimo F., Bjerregaard P., Jørgensen M.E., Korneliussen T.S., Gerbault P., Skotte L., Linneberg A., Christensen C., Brandslund I., Jørgensen T., Huerta-Sánchez E., Schmidt E.B., Pedersen O., Hansen T., Albrechtsen A., Nielsen R.. Greenlandic Inuit show genetic signatures of diet and climate adaptation. Science 2015;349(6254):1343-7. doi:10.1126/science.aab2319
^ Gladyshev M.I., Makhutova O.N., Gubanenko G.A., Rechkina E.A., Kalachova G.S., Sushchik N.N. Livers of terrestrial production animals as a source of long-chain polyunsaturated fatty acids for humans: an alternative to fish? Eur J Lipid Sci Technol 2015;117:1417-1421. doi:10.1002/ejlt.201400449
^ Gladyshev M.I., Popova O.N., Makhutova O.N., Zinchenko T.D., Golovatyuk L.V., Yurchenko Y.A., Kalachova G.S., Krylov A.V., Sushchik N.N. Comparison of fatty acid compositions in birds feeding in aquatic and terrestrial ecosystems. Contemp Probl Ecol 2016;9:503-513. doi:10.1134/S1995425516040065
^ abcd Gladyshev M.I. and Sushchik N.N. Long-chain omega-3 polyunsaturated fatty acids in natural ecosystems and the human diet: assumptions and challenges. Biomolecules 2019;9(9):485. doi:10.3390/biom9090485
^ Gladyshev M.I., Sushchik N.N., Tolomeev A.P., Dgebuadze Y.Y. Meta-analysis of factors associated with omega-3 fatty acid contents of wild fish. Rev Fish Biol Fish 2018;28,:277-299. doi:10.1007/s11160-017-9511-0
^ Kim H-Y. Novel metabolism of docosahexaenoic acid in neural cells. J Biol Chem 2007;282(26):18661-18665. doi:10.1074/jbc.R700015200
^ Kouba M., Mourot J. A review of nutritional effects on fat composition of animal products with special emphasis on n-3 polyunsaturated fatty acids. Biochimie 2011;93(1):13-7. doi:10.1016/j.biochi.2010.02.027
^ Kromann N., Green A. Epidemiological studies in the Upernavik district, Greenland. Incidence of some chronic diseases 1950-1974. Acta Med Scand 1980;208(5):401-6. doi:10.1111/j.0954-6820.1980.tb01221.x
^ Lauritzen L., Hansen H.S., Jørgensen M.H., Michaelsen K.F. The essentiality of long chain n-3 fatty acids in relation to development and function of the brain and retina. Prog Lipid Res 2001;40(1-2):1-94. doi:10.1016/s0163-7827(00)00017-5
^ ab Lee J.M., Lee H., Kang S. and Park W.J. Fatty acid desaturases, polyunsaturated fatty acid regulation, and biotechnological advances. Nutrients 2016;8(1):23. doi:10.3390/nu8010023
^ Mason R.P., Sherratt S.C.R. Omega-3 fatty acid fish oil dietary supplements contain saturated fats and oxidized lipids that may interfere with their intended biological benefits. Biochem Biophys Res Commun 2017;483(1):425-429. doi:10.1016/j.bbrc.2016.12.127
^ Mathieson I., Lazaridis I., Rohland N., Mallick S., Patterson N., Roodenberg S.A., Harney E., Stewardson K., Fernandes D., Novak M., et al. Genome-wide patterns of selection in 230 ancient Eurasians. Nature 2015;528:499-503. doi:10.1038/nature16152
^ ab McCann J.C., Ames B.N. Is docosahexaenoic acid, an n-3 long-chain polyunsaturated fatty acid, required for development of normal brain function? An overview of evidence from cognitive and behavioral tests in humans and animals. Am J Clin Nutr 2005;82(2):281-95. doi:10.1093/ajcn.82.2.281
^ ab Mensink R.P., Zock P.L., Kester A.D., Katan M.B. Effects of dietary fatty acids and carbohydrates on the ratio of serum total to HDL cholesterol and on serum lipids and apolipoproteins: a meta-analysis of 60 controlled trials. Am J Clin Nutr 2003;77(5):1146-55. doi:10.1093/ajcn/77.5.1146
^ Muller-Navarra D.C. Biochemical versus mineral limitation in Daphnia. Limnol Oceanogr 1995;40:1209-1214. doi:10.4319/lo.1995.40.7.1209
^ ab Niu S.L., Mitchell D.C., Lim S.Y., Wen Z.M., Kim H.Y., Salem N. Jr, Litman B.J. Reduced G protein-coupled signaling efficiency in retinal rod outer segments in response to n-3 fatty acid deficiency. J Biol Chem 2004;279(30):31098-104. doi:10.1074/jbc.M404376200
^ Oh D.Y., Talukdar S., Bae E.J., Imamura T., Morinaga H., Fan WQ, Li P., Lu W.J., Watkins S.M., Olefsky J.M. GPR120 is an omega-3 fatty acid receptor mediating potent anti-inflammatory and insulin-sensitizing effects. Cell 2010 142(5):687-698. doi:10.1016/j.cell.2010.07.041
^ Popova O.N., Haritonov A.Y., Sushchik N.N., Makhutova O.N., Kalachova G.S., Kolmakova A.A., Gladyshev M.I. Export of aquatic productivity, including highly unsaturated fatty acids, to terrestrial ecosystems via Odonata. Sci Total Environ 2017;581-582:40-48. doi:10.1016/j.scitotenv.2017.01.017
^ Salem N. Jr, Litman B., Kim H.Y., Gawrisch K. Mechanisms of action of docosahexaenoic acid in the nervous system. Lipids 2001;36(9):945-59. doi:10.1007/s11745-001-0805-6
^ abcd Simopoulos A.P. The importance of the omega-6/omega-3 fatty acid ratio in cardiovascular disease and other chronic diseases. Exp Biol Med 2008;233(6):6746-88. doi:10.1016/S0753-3322(02)00253-6
^ Smith W., Mukhopadhyay R. Essential fatty acids: the work of George and Mildred Burr. J Biol Chem 2012;287(42):35439-35441. doi:10.1074/jbc.O112.000005
^ ab Stubbs C.D., Smith A.D. The modification of mammalian membrane polyunsaturated fatty acid composition in relation to membrane fluidity and function. Biochim Biophys Acta 1984;779(1):89-137. doi:10.1016/0304-4157(84)90005-4
^ abc Tocher D.R., Betancor M.B., Sprague M., Olsen R.E., Napier J.A. Omega-3 long-chain polyunsaturated fatty acids, EPA and DHA: bridging the gap between supply and demand. Nutrients 2019;11(1):89. doi:10.3390/nu11010089
^ Yano K., MacLean C.J., Reed D.M., Shimizu Y., Sasaki H., Kodama K., Kato H., Kagan A. A comparison of the 12-year mortality and predictive factors of coronary heart disease among Japanese men in Japan and Hawaii. Am J Epidemiol 1988;127(3):476-87. doi:10.1093/oxfordjournals.aje.a114824
^ Williams C.M., Burdge G. Long-chain n-3 PUFA: plant v. marine sources. Proc Nutr Soc 2006;65(1):42-50. doi:10.1079/pns2005473
Animals cannot synthesize the two fatty acids due to the lack of delta-12 desaturase (E.C. 1.14.19.6) and delta-15 desaturase (EC 1.14.19.25).[1][9][15] These enzymes introduce cis double bonds beyond carbon 9, and are present in plants and some microorganisms such as some bacteria, fungi and molds.[10]
Delta-12 desaturase catalyzes the synthesis of linoleic acid from oleic acid, by introducing a double bond at delta-12 position, namely, between carbons 6 and 7 from the methyl end of the fatty acid.[15]
Delta-15 desaturase or omega-3 desaturase or fatty acid desaturase 3 catalyzes the synthesis of alpha-linolenic acid from linoleic acid by introducing a double bond at delta-15 position, namely, between carbons 3 and 4 from the methyl end of the fatty acid. The enzyme is only present in the plastids and in the endoplasmic reticulum of phytoplankton and vascular terrestrial plants.[1][9]
Synthesis of EFAs
Linoleic acid and alpha-linolenic acid are the precursors to omega-6 polyunsaturated fatty acids and omega-3 polyunsaturated fatty acids. In the absence of dietary EFAs, a rather rare condition, the other omega-3 and omega-6 fatty acids become essential, too. For this reason, these lipids are defined by some as conditionally essential fatty acids.[9]
It should be pointed out that all essential fatty acids are polyunsaturated fatty acids, but not all polyunsaturated fatty acids are essential, such as those belonging to the omega-7 and omega-9 families.
The first evidence of the existence of essential fatty acids dates back to 1918, when Hans Aron suggested that dietary fat could be essential for the healthy growth of animals and that, in addition to their caloric contribution, there was a inherent nutritive value due to the presence of certain lipid molecules.[2]
In 1927, Herbert M. Evans and George Oswald Burr demonstrated that, despite the addition of vitamins A, D, and E to the diet, a deficiency of fat severely affected both growth and reproduction of experimental animals. Therefore, they suggested the presence of an essential substance in the fat that they called vitamin F.[11]
Eleven years after Aron work, in 1929, Burr and his wife Mildred Lawson hypothesized that warm-blooded animals were not able to synthesize appreciable amounts of certain fatty acids.[7] One year later, they discovered that linoleic acid was essential for animals, and it was they who coined the term essential fatty acid.[8][19]
However, EFA deficiency in humans was first described by Arild Hansen only in 1958, in infants fed a milk-based formula lacking them.[14]
And in 1964, thanks to the research of Van Dorp and Bergstroem, one of their biological functions was discovered: being the precursors for the synthesis of prostaglandins.[3][21]
Role
Essential fatty acids play important biological functions.
Linoleic acid and alpha-linolenic acid can be used as an energy source through beta-oxidation.[22]
Linoleic acid and alpha-linolenic acid are the precursors to omega-6 polyunsaturated fatty acids and omega-3 polyunsaturated fatty acids. Indeed, many animals, including humans, can synthesize, although with variable efficiency, the other omega-3 and omega-6 polyunsaturated fatty acids, for example arachidonic acid, eicosapentaenoic acid, and docosahexaenoic acid.[5][6][18]
Essential fatty acids are structural components of cellular membranes, modulating, for example, their fluidity.[20][22]
They are essential in the skin, especially linoleic acid in sphingolipids of the stratum corneum, where they contribute to the formation of the barrier against water loss.[23]
They have a crucial role in the prevention of many diseases, particularly coronary heart disease.[12][16]
Food sources
Linoleic acid is the most abundant polyunsaturated fatty acid in the Western diet, and accounts for 85-90 percent of dietary omega-6 polyunsaturated fatty acids.[13] The richest dietary sources are vegetable oils and seeds of many plants.[4]
Linoleic acid content (mg/g) in main food sources for humans
Food sources
Linoleic acid
Safflower oil
~ 740
Sunflower oil
~ 600
Soybean oil
~ 530
Corn oil
~ 500
Cottonseed oil
~ 480
Walnuts
~ 340
Brazil nuts
~ 250
Peanut oil
~ 240
Rapeseed oil
~ 190
Peanuts
~ 140
Flaxseed oil
~ 135
Linoleic acid is present in fair amounts also in animal products such as chicken eggs or lard, because it is present in their feed.[9]
It should be noted that some of the major sources of linoleic acid, such as walnuts, flaxseed oil, soybean oil, and rapeseed oil are also high in alpha-linolenic acid.[17]
Some of the richest dietary sources of alpha-linolenic acid are flaxseed oil, ~ 550 mg/g, rapeseed oil, ~ 85 mg/g, and soybean oil, ~ 75 mg/g. Other foods rich in alpha-linolenic acid include nuts, ~ 70 mg/g, and soybeans, ~ 10 mg/g.[1]
References
^ abc Akoh C.C. and Min D.B. Food lipids: chemistry, nutrition, and biotechnology. 3th Edition. CRC Press, Taylor & Francis Group, 2008
^ Aron H. Uber den Nahrwert. Biochem Z 1918; 92: 211-33
^ Bergstroem S., Danielsson H., Klenberg D., Samuelsson B. The enzymatic conversion of essential fatty acids into prostaglandins. J Biol Chem 1964;239:PC4006-8. doi:10.1016/S0021-9258(18)91234-2
^ Blasbalg T. L., Hibbeln J. R., Ramsden C. E., Majchrzak S. F. & Rawlings R. R. Changes in consumption of omega-3 and omega-6 fatty acids in the United States during the 20th century. Am J Clin Nutr 2011;93(5):950-962. doi:10.3945/ajcn.110.006643
^ Burdge G.C, Jones A.E, Wootton S.A. Eicosapentaenoic and docosapentaenoic acids are the principal products of α-linolenic acid metabolism in young men. Br J Nutr 2002;88(4):355-364. doi:10.1079/BJN2002662
^ Burdge G.C., Wootton S.A. Conversion of α-linolenic acid to eicosapentaenoic, docosapentaenoic and docosahexaenoic acids in young women. Br J Nutr 2002;88(4):411-420. doi:10.1079/BJN2002689
^ Burr G. and Burr M. A new deficiency disease produced by the rigid exclusion of fat from the diet. J Biol Chem 1929;82:345-367. doi:10.1016/S0021-9258(20)78281-5
^ Burr G.O., Burr M.M., Miller E.S. On the fatty acids essential in nutrition. III. J Biol Chem 1932;97(1):1-9. doi:10.1016/S0021-9258(18)76213-3
^ abcd Chow Ching K. Fatty acids in foods and their health implication. 3th Edition. CRC Press, Taylor & Francis Group, 2008
^ Das U.N. Essential fatty acids: biochemistry, physiology and pathology. Biotechnol J 2006;1;420-439. doi:10.1002/biot.200600012
^ Evans H. M. and G. O. Burr. A new dietary deficiency with highly purified diets. III. The beneficial effect of fat in the diet. Proc Soc Exp Biol Med 1928;25:390-397. doi:10.3181/00379727-25-3867
^ Farvid M.S., Ding M., Pan A., Sun Q., Chiuve S.E., Steffen L.M., Willett W.C., Hu F.B. Dietary linoleic acid and risk of coronary heart disease: a systematic review and meta-analysis of prospective cohort studies. Circulation 2014;130:1568-1578. doi:10.1161/CIRCULATIONAHA.114.010236
^ Guyenet S.J., Carlson S.E. Increase in adipose tissue linoleic acid of US adults in the last half century. Adv Nutr 2015;6(6):660-664. doi:https://DOI.org/10.3945/an.115.009944
^ Hansen A.E., Haggard M.E., Boelsche A.N., Adam D.J., Wiese H.F. Essential fatty acids in infant nutrition. III. Clinical manifestations of linoleic acid deficiency. J Nutr 1958;66(4):565-76. doi:10.1093/jn/66.4.565
^ ab Malcicka M., Visser B., Ellers J. An evolutionary perspective on linoleic acid synthesis in animals. Evol Biol 2018;45:15-26. doi:10.1007/s11692-017-9436-5
^ Mensink R.P., Zock P.L., Kester A.D., Katan M.B. Effects of dietary fatty acids and carbohydrates on the ratio of serum total to HDL cholesterol and on serum lipids and apolipoproteins: a meta-analysis of 60 controlled trials. Am J Clin Nutr 2003;77(5):1146-55. doi:10.1093/ajcn/77.5.1146
^ Rajaram S. Health benefits of plant-derived α-linolenic acid. Am J Clin Nutr 2014;100 Suppl 1:443S-8S. doi:10.3945/ajcn.113.071514
^ Rett B.S., Whelan J. Increasing dietary linoleic acid does not increase tissue arachidonic acid content in adults consuming Western-type diets: a systematic review. Nutr Metab (Lond) 2011;8:36. doi:10.1186/1743-7075-8-36
^ Smith W., Mukhopadhyay R. Essential fatty acids: the work of George and Mildred Burr. J Biol Chem 2012;287(42):35439-35441. doi:10.1074/jbc.O112.000005
^ Stubbs C.D., Smith A.D. The modification of mammalian membrane polyunsaturated fatty acid composition in relation to membrane fluidity and function. Biochim Biophys Acta 1984;779(1):89-137. doi:10.1016/0304-4157(84)90005-4
^ Van Dorp D.A., Beerthuis R.K., Nugteren D.H. and Vonkeman H. Enzymatic conversion of all-cis-polyunsaturated fatty acids into prostaglandins. Nature 1964;203:839-841. doi:10.1038/203839a0
^ ab Whelan J. and Fritsche K. Linoleic acid. Adv Nutr 2013;4(3): 311-312. doi:10.3945/an.113.003772
^ Ziboh V.A. Prostaglandins, leukotrienes, and hydroxy fatty acids in epidermis. Semin Dermatol 1992;11(2):114-20
Invert sugar, also known as inverted sugar, is sucrose partially or totally cleaved into fructose and glucose and, apart from the chemical process used, the obtained solution has the same amount of the two carbohydrates.
Moreover, according to the product, not cleaved sucrose may also be present.
Invert sugar production
The breakdown of sucrose may happen in a reaction catalyzed by enzymes, such as:
sucrase-isomaltase (EC 3.2.1.48), actives at our own intestinal level where it is involved in carbohydrate digestion;
invertase, an enzyme secreted by honeybees into the honey and used industrially to obtain invert sugar.
Another process applies acid action, as it happens partly in our own stomach and as it happened in the old times, and still happens, at home-made and industrial level. Sulfuric and hydrochloric acids was used, heating the solution with caution for some time; in fact the reaction is as fast as the solution is acid, regardless of the type of acid used, and as higher the temperature is. The acidity is then reduced or neutralized with alkaline substances, as soda or sodium bicarbonate.
A chemical process as described occurs when acid foods are prepared; i.e. in the preparation of jams and marmalades, where both conditions of acidity, naturally, and high temperatures, by heating, are present. The situation is analogous when fruit juices are sweetened with sucrose.
The reaction develops at room temperature as well, obviously more slowly.
What is the practical outcome of that?
It means that, during storage, also sweets and acid foods, even those just seen, go towards a slow reaction of inversion of contained/residue sucrose, with consequent modification of the sweetness, since invert sugar at low temperatures is sweeter (due to the presence of fructose), and assumption of a different taste profile.
Properties and uses
It is principally utilized in confectionery and ice-cream industries thanks to some peculiar characteristics.
It has an higher affinity for water (hydrophilicity) than sucrose (see fructose) therefore it keeps food more humid: e.g. cakes made with invert sugar dry up less easily.
It avoids or slows down crystal formation (dextrose and fructose form less crystals than sucrose), property useful in confectionery industries for icings and coverage.
It has a lower freezing point.
It increases, just a bit, the sweetness of the product in which it has been added, as it is sweeter than an equal amount of sucrose (the sweetness of fructose depends on the temperature in which it is present).
It may take part to Maillard reaction (sucrose can’t do it) thus contributing to the color and taste of several bakery products.
It should be noted that honey, lacking in sucrose, has a fructose and glucose composition almost equal to that of 100% invert sugar (fructose is slightly more abundant than glucose). So, diluted honey, better if not much aromatic, may replace industrial invert sugar.
References
Belitz .H.-D., Grosch W., Schieberle P. “Food Chemistry” 4th ed. Springer, 2009
Bender D.A. “Benders’ Dictionary of Nutrition and Food Technology”. 8th Edition. Woodhead Publishing. Oxford, 2006
Jordan S. Commercial invert sugar. Ind Eng Chem 1924;16(3):307-310. doi:10.1021/ie50171a037
Stipanuk M.H., Caudill M.A. Biochemical, physiological, and molecular aspects of human nutrition. 3rd Edition. Elsevier health sciences, 2012
Biochemistry and Metabolism
Utilizziamo cookie tecnici necessari per il funzionamento del sito. Vorremmo anche utilizzare, ma con il tuo consenso, cookie diversi da quelli tecnici, quali cookie analitici non equiparabili ai cookie tecnici, cookie di marketing e di terze parti, al fine di analisi, di miglioramento della tua esperienza di navigazione, presentare specifici annunci pubblicitari.
Puoi esprimere il consenso all’utilizzo di tali cookie cliccando sul tasto “Accetto tutti i cookie” oppure selezionando le tue preferenze cliccando sull’apposito tasto.
Cliccando su “Rifiuta” verranno installati solo i cookie tecnici o questi equiparabili.
Potrai revocare il tuo consenso in qualsiasi momento.
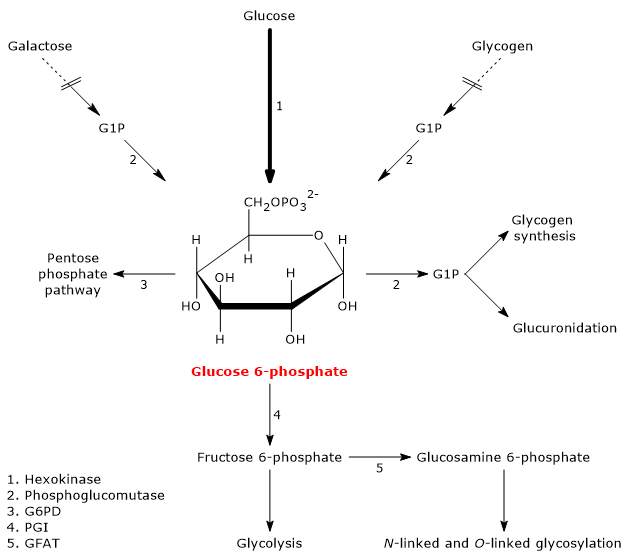
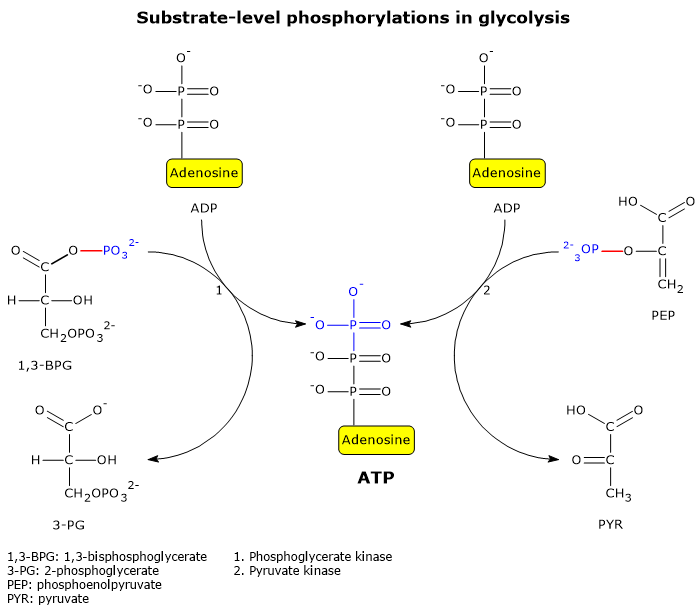 These reactions are catalyzed by phosphoglycerate kinase (EC 2.7.2.3) and pyruvate kinase (EC 2.7.1.40).
These reactions are catalyzed by phosphoglycerate kinase (EC 2.7.2.3) and pyruvate kinase (EC 2.7.1.40).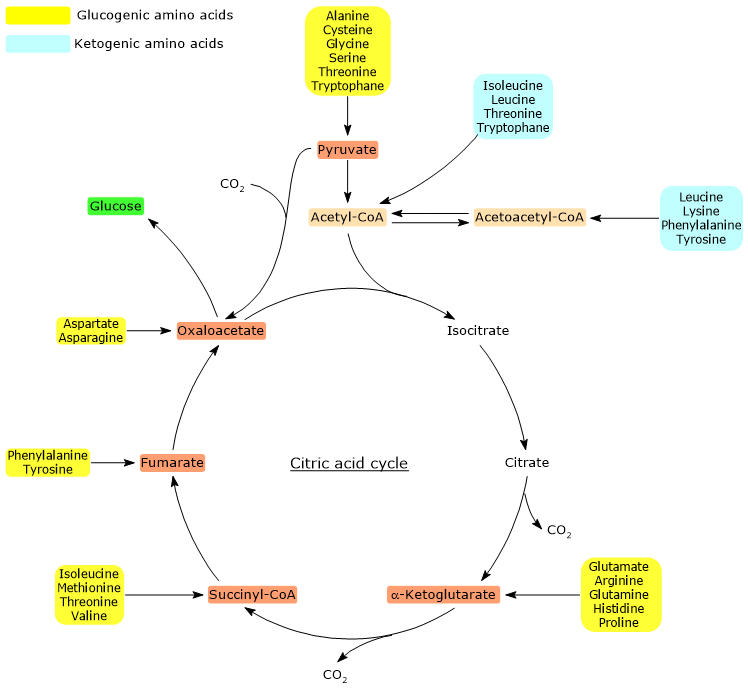
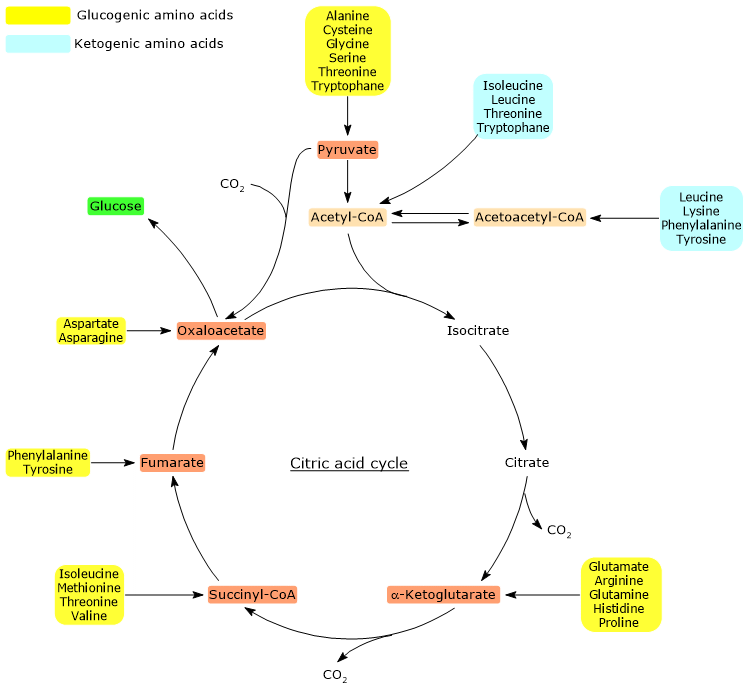
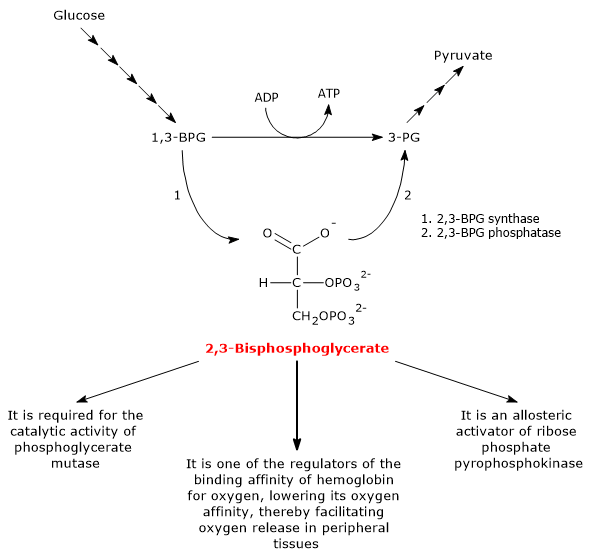
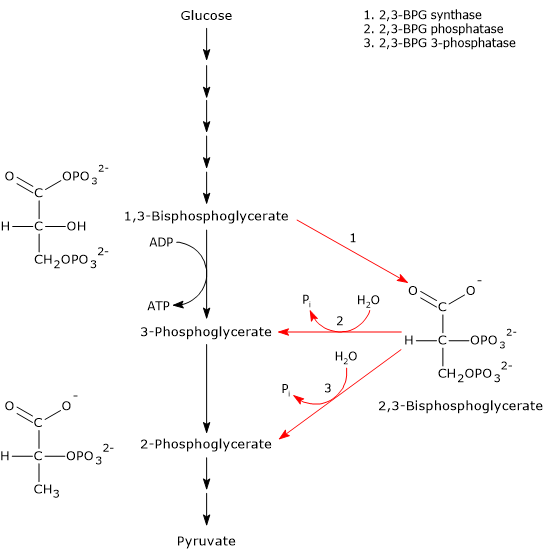
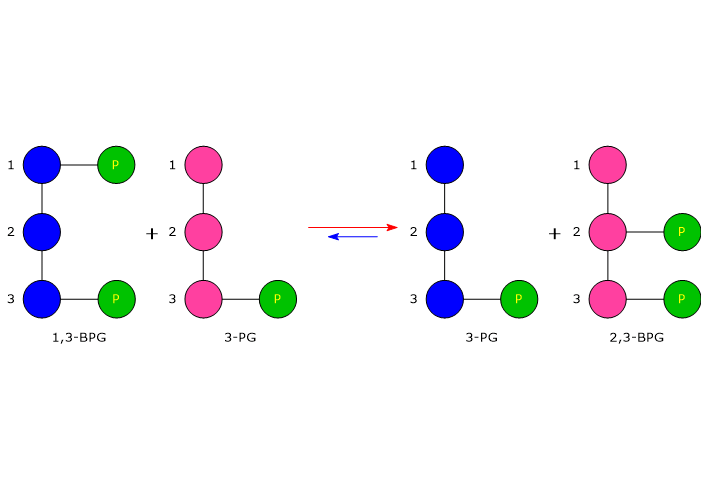 In the second step, the phosphatase activity of bisphosphoglycerate mutase catalyzes the synthesis of 3-phosphoglycerate, a glycolytic intermediate, following the hydrolysis of the phosphate group at position C-2 of 2,3-BPG. The 3-phosphoglycerate produced can then re-enter the glycolytic pathway at the reaction catalyzed by phosphoglycerate mutase, i.e., the eighth step of the pathway.
In the second step, the phosphatase activity of bisphosphoglycerate mutase catalyzes the synthesis of 3-phosphoglycerate, a glycolytic intermediate, following the hydrolysis of the phosphate group at position C-2 of 2,3-BPG. The 3-phosphoglycerate produced can then re-enter the glycolytic pathway at the reaction catalyzed by phosphoglycerate mutase, i.e., the eighth step of the pathway.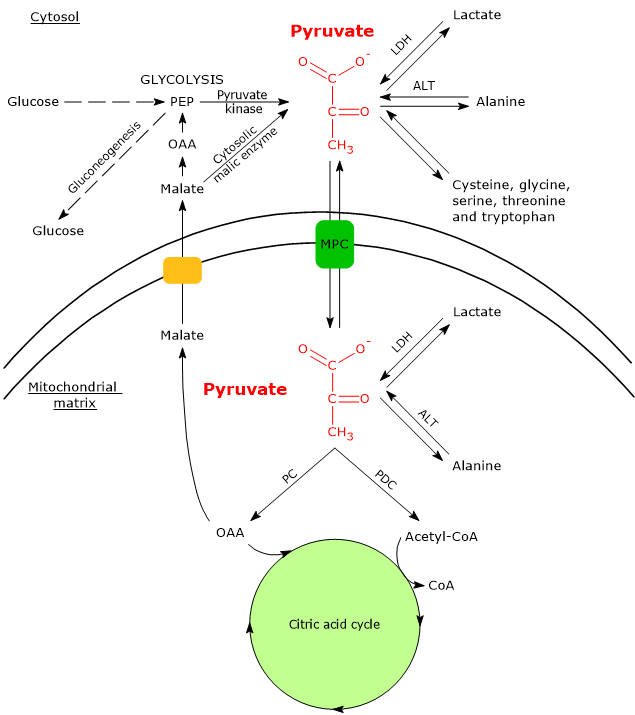
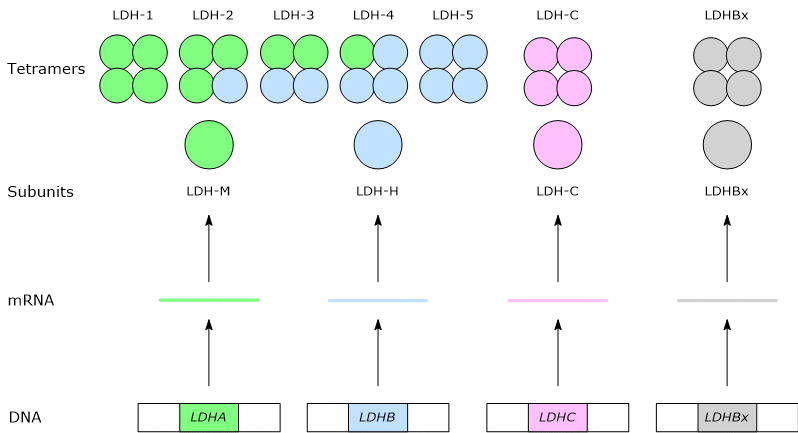
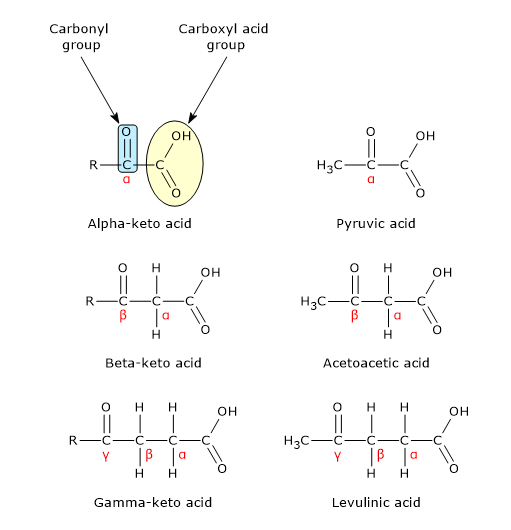
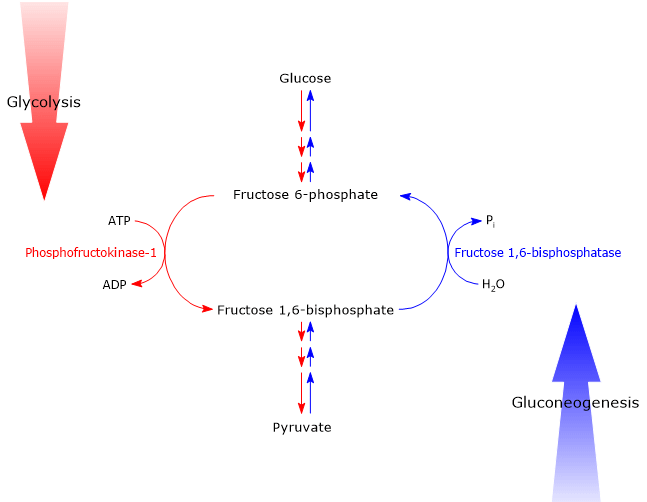
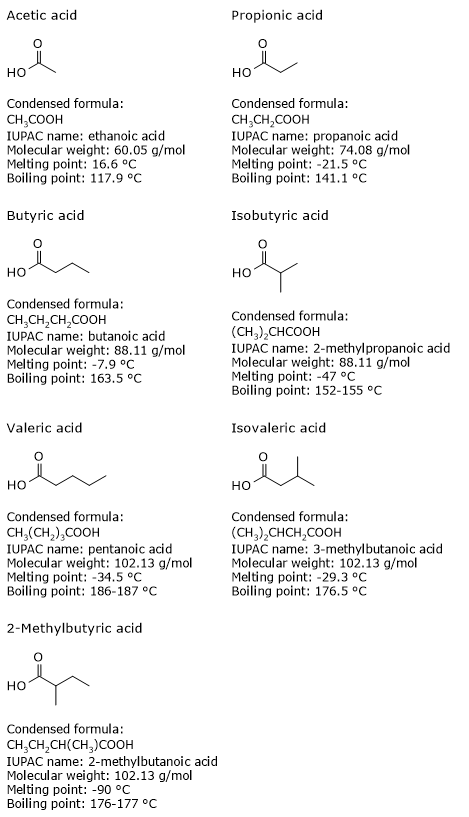
 Age-related risk is a function of variables such as weight gain, low physical activity, excessive use of salt, fats and
Age-related risk is a function of variables such as weight gain, low physical activity, excessive use of salt, fats and 

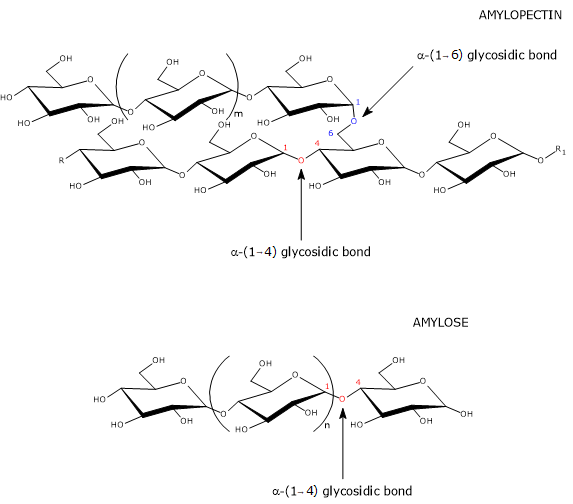
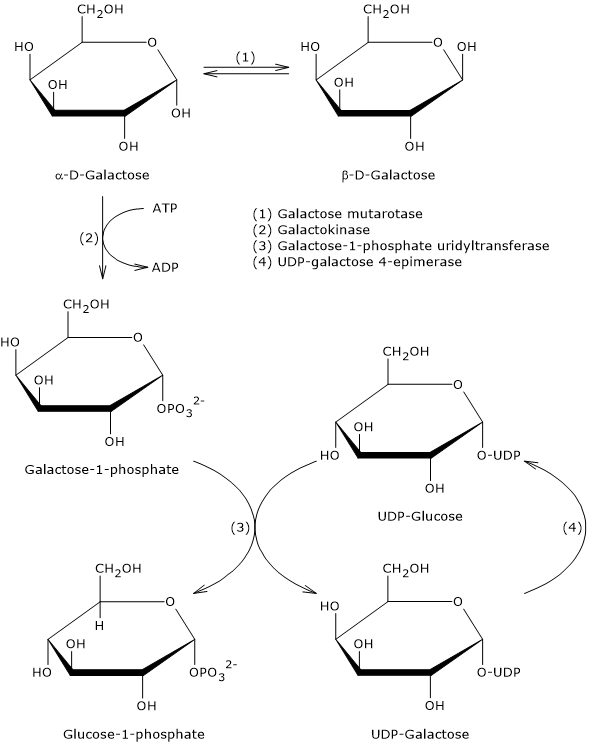
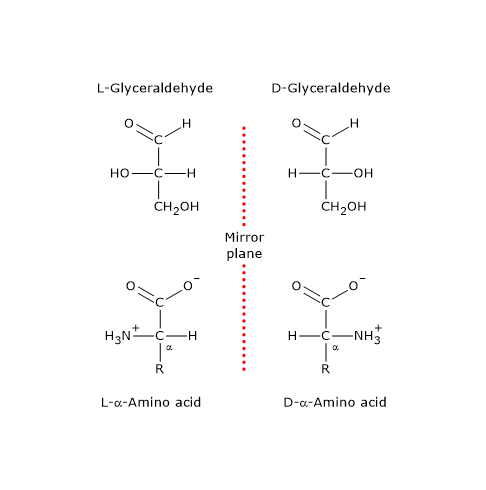
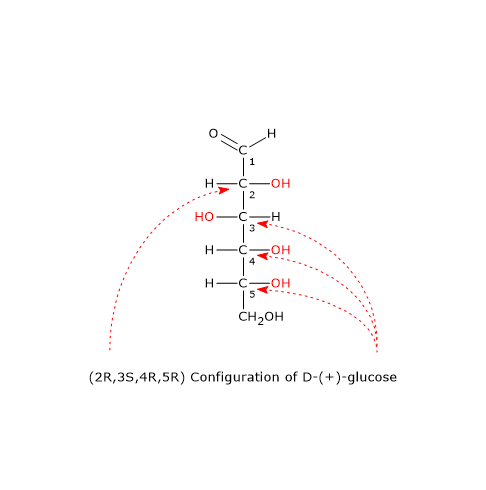
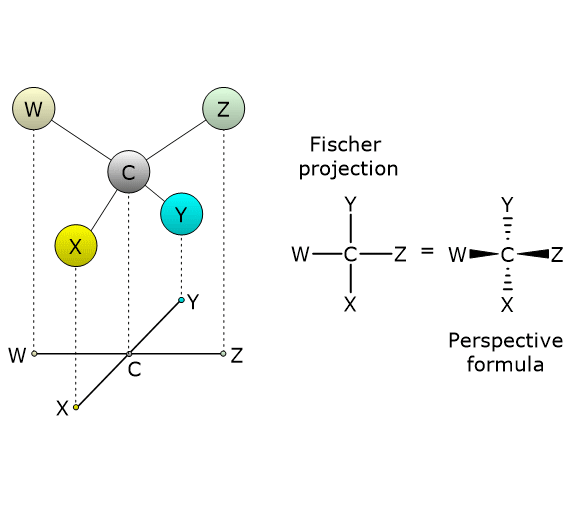
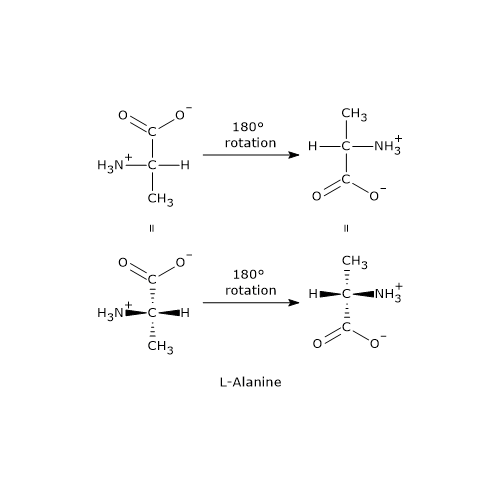
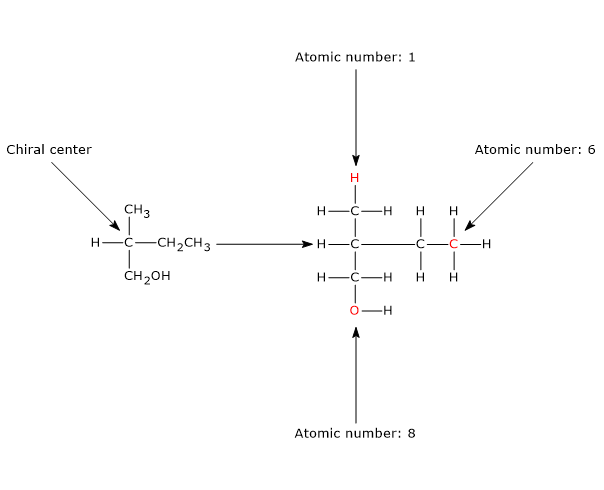
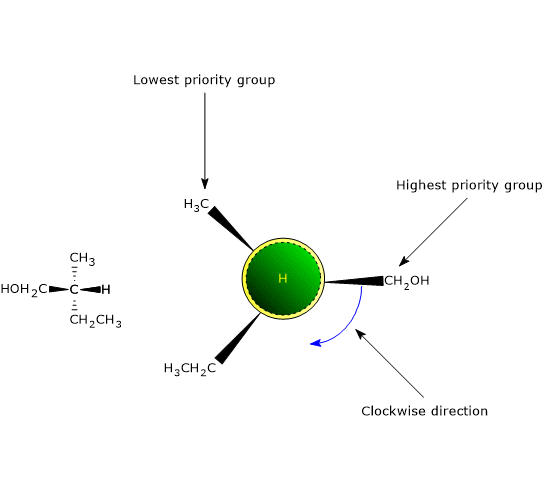
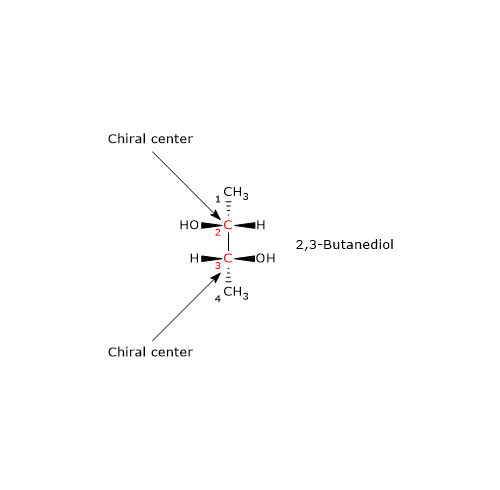
 In such cases, chirality results from the presence of an axis of chirality rather than a center. This form of chirality is known as axial chirality.
In such cases, chirality results from the presence of an axis of chirality rather than a center. This form of chirality is known as axial chirality.
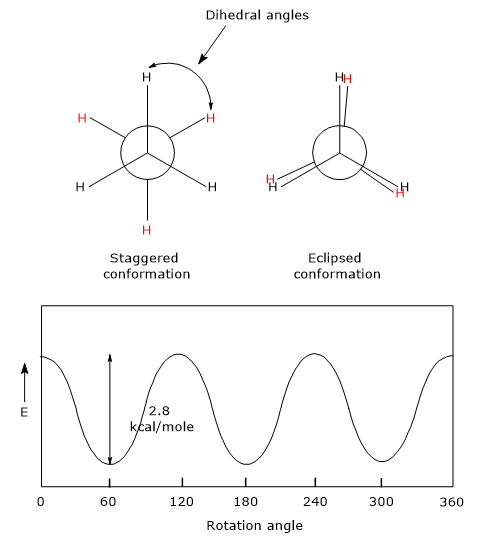
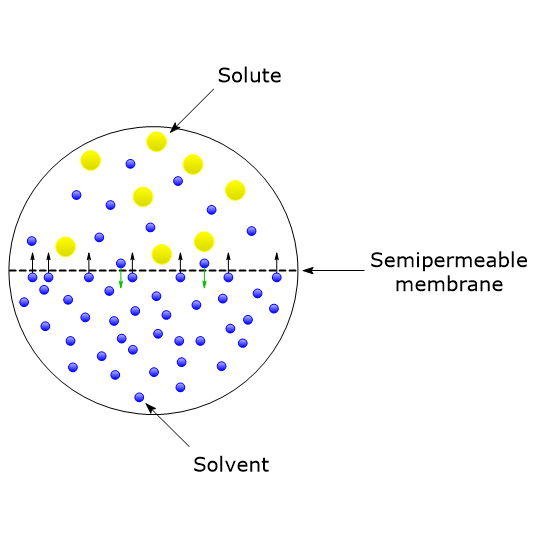
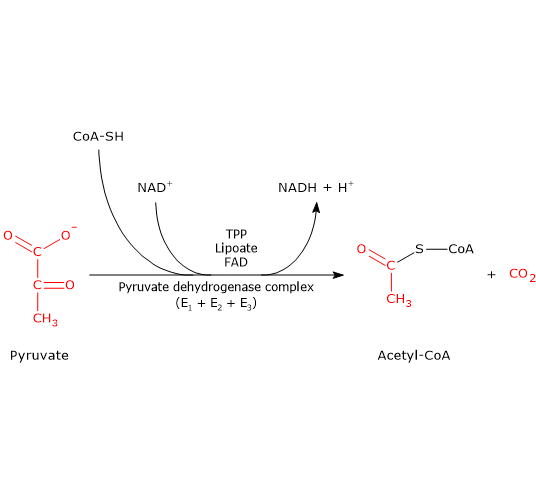
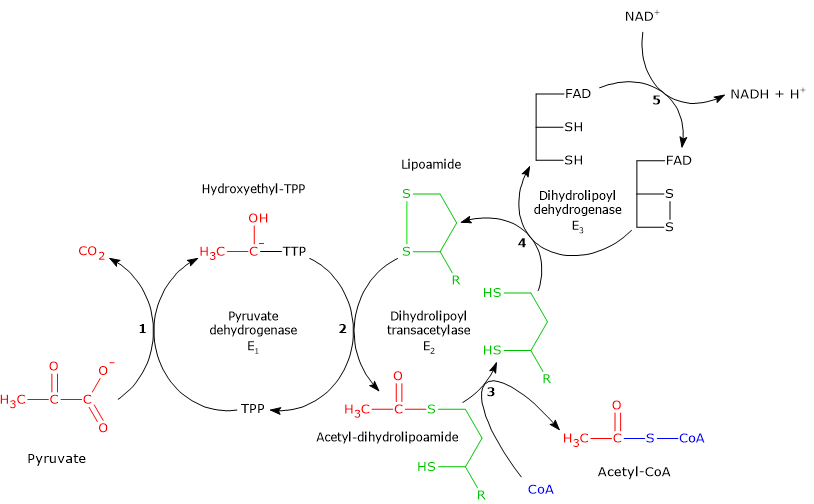
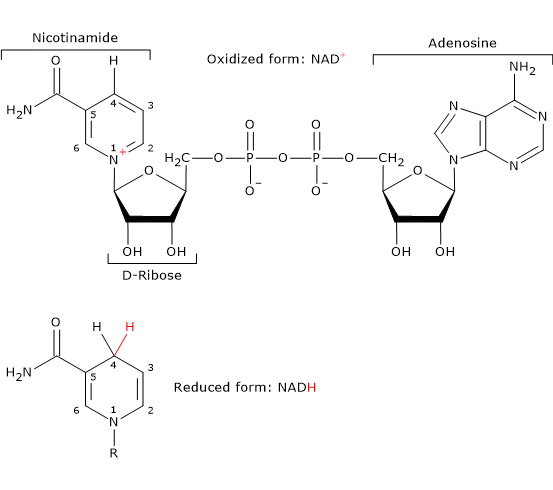
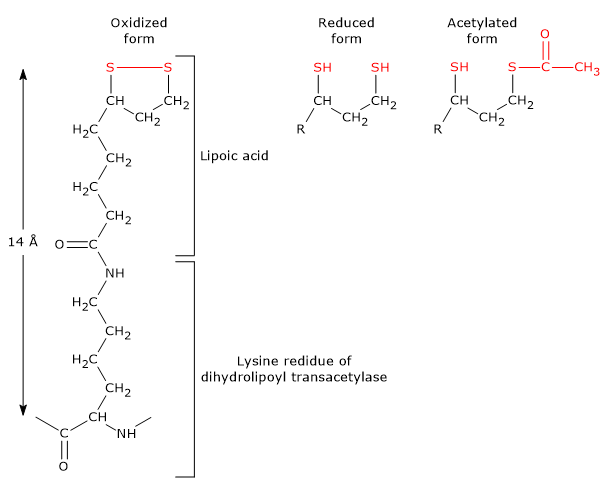
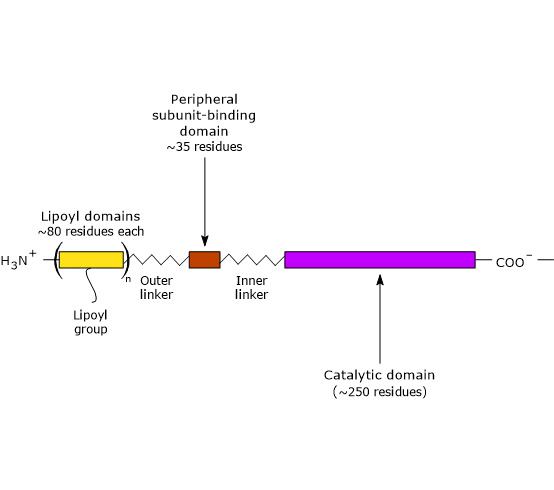
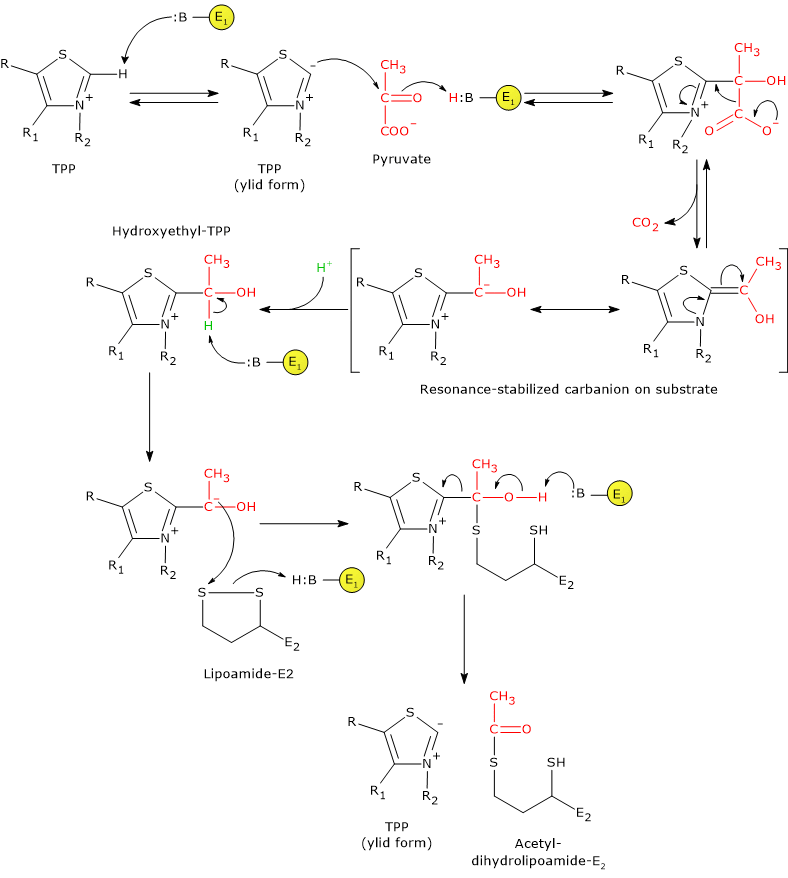
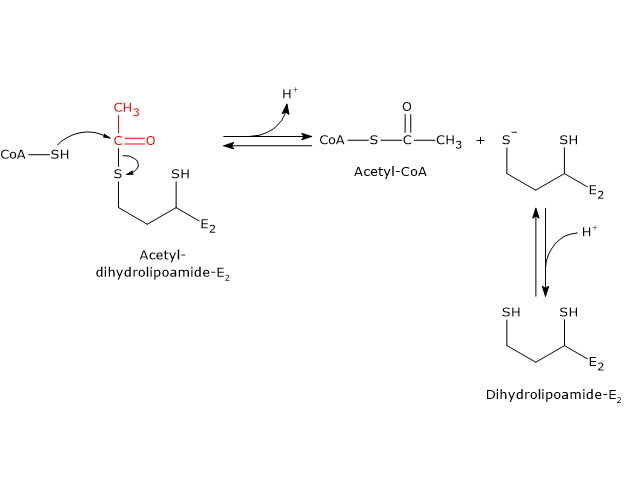
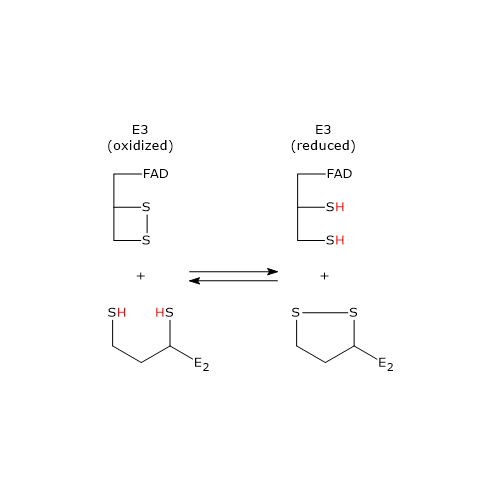
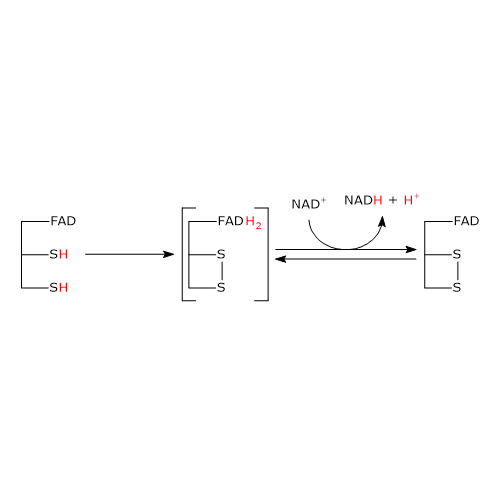
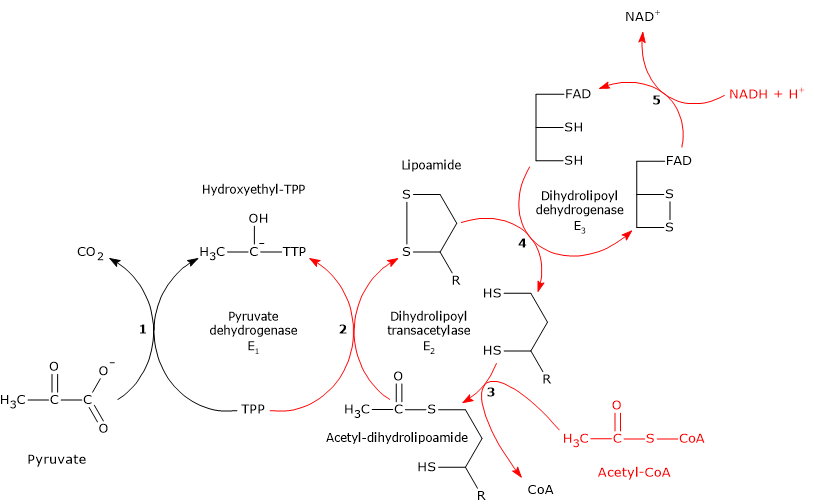
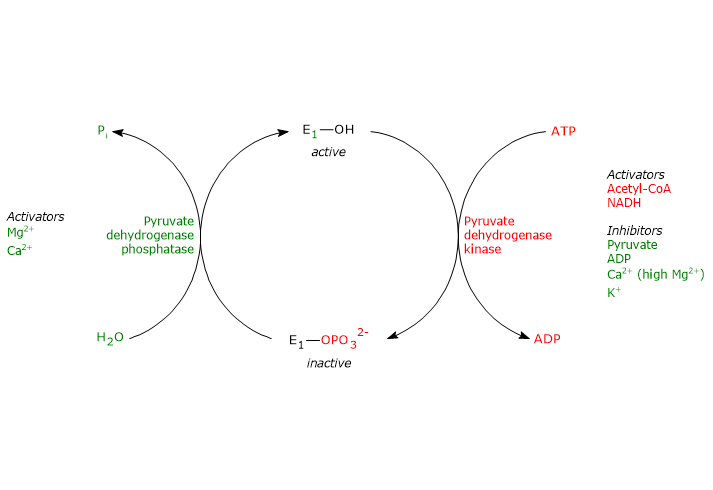
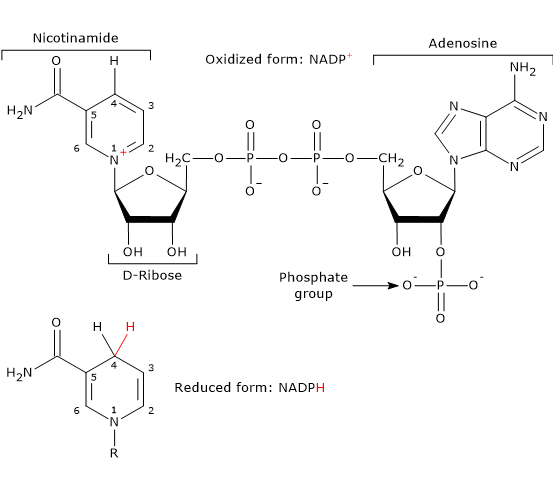
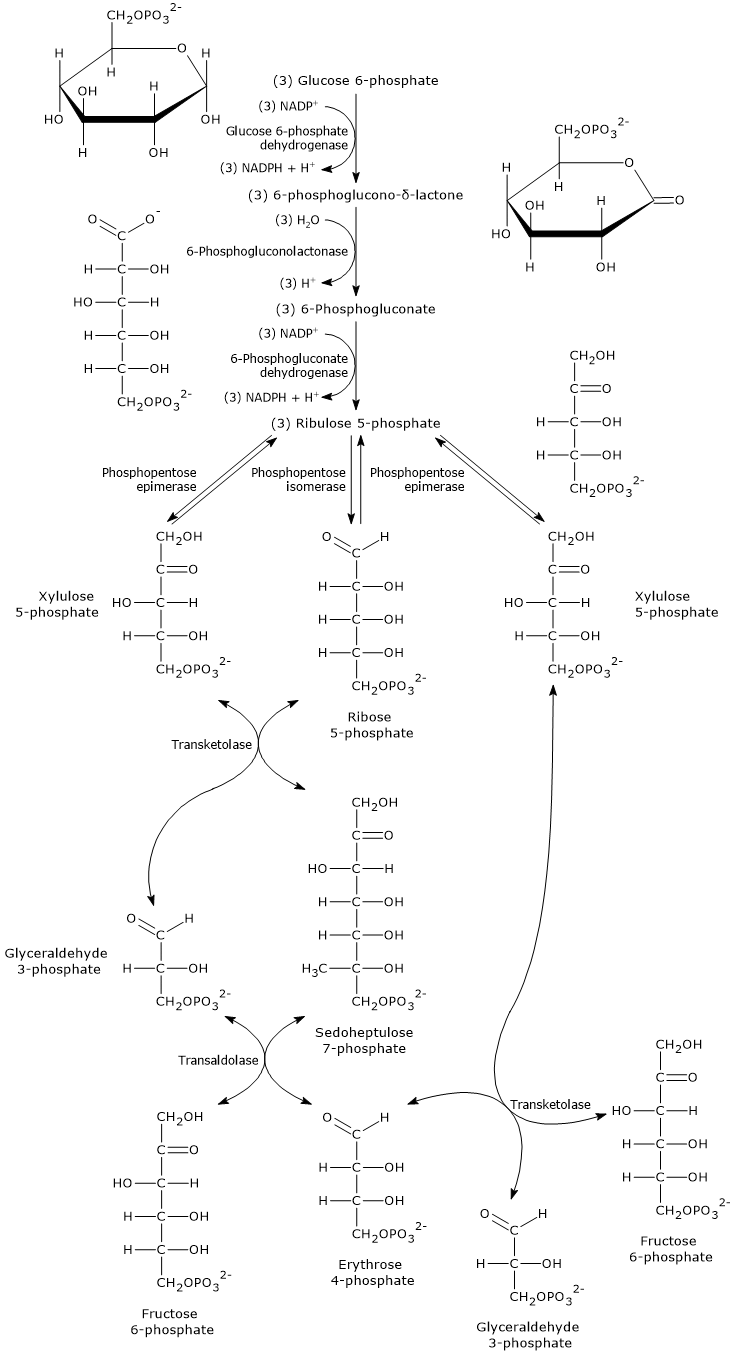
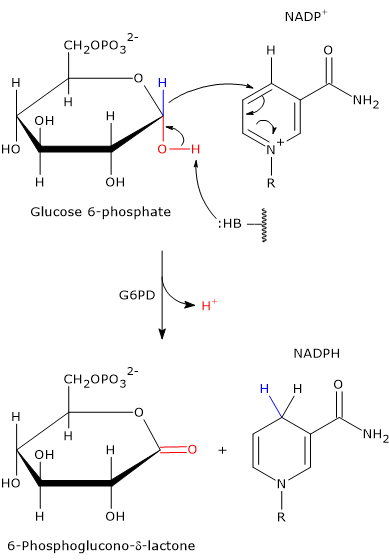
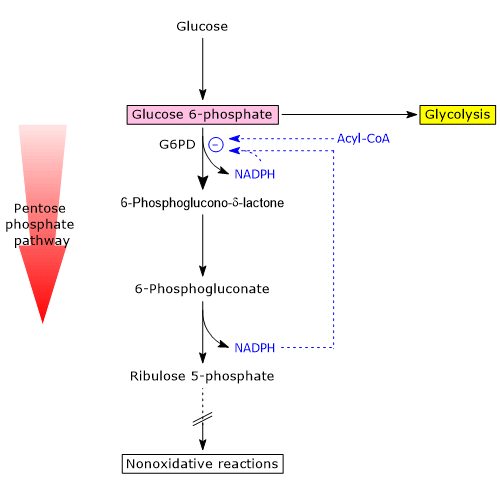
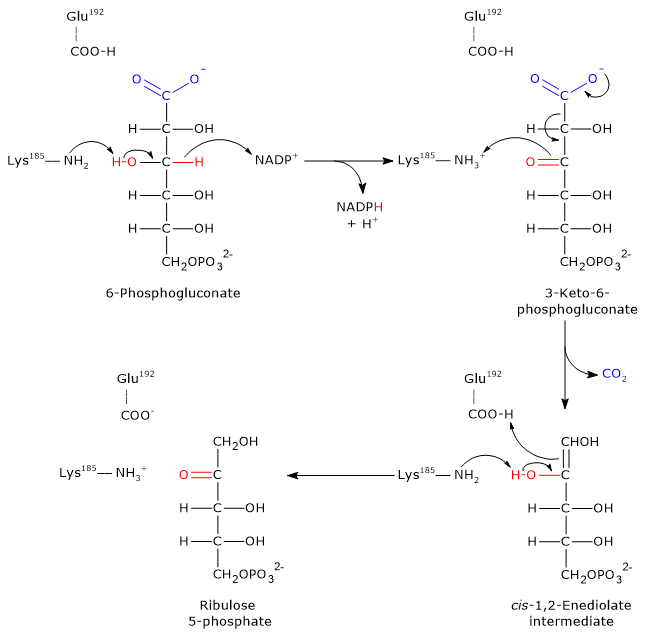
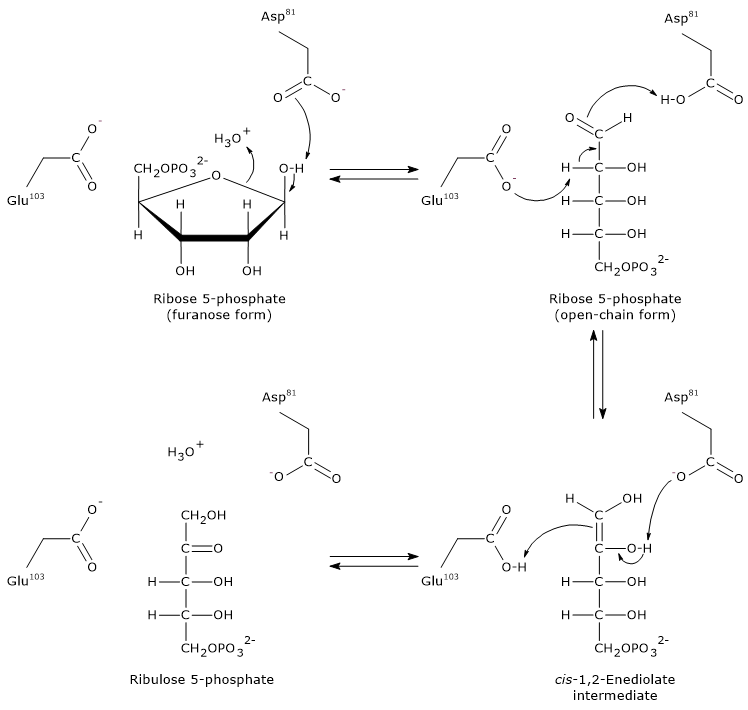
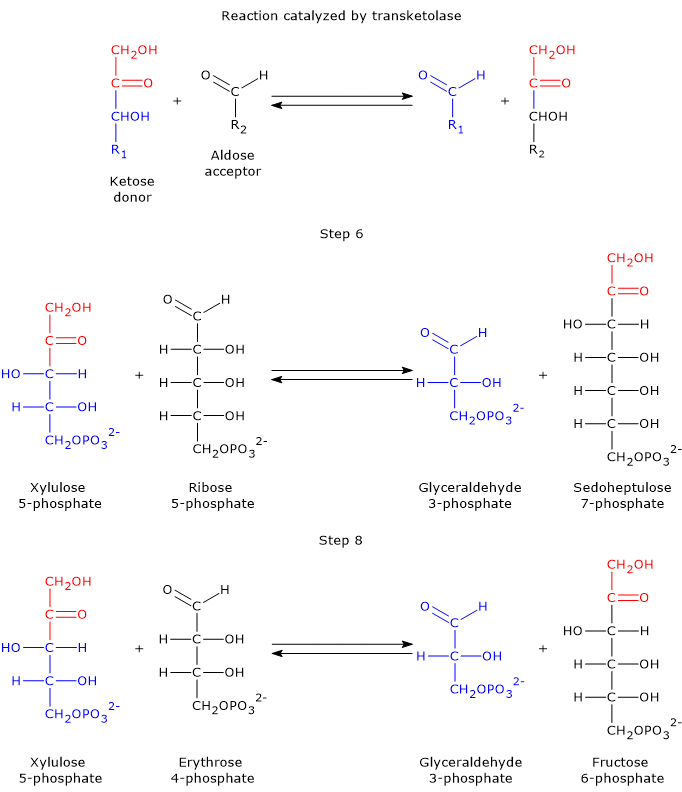
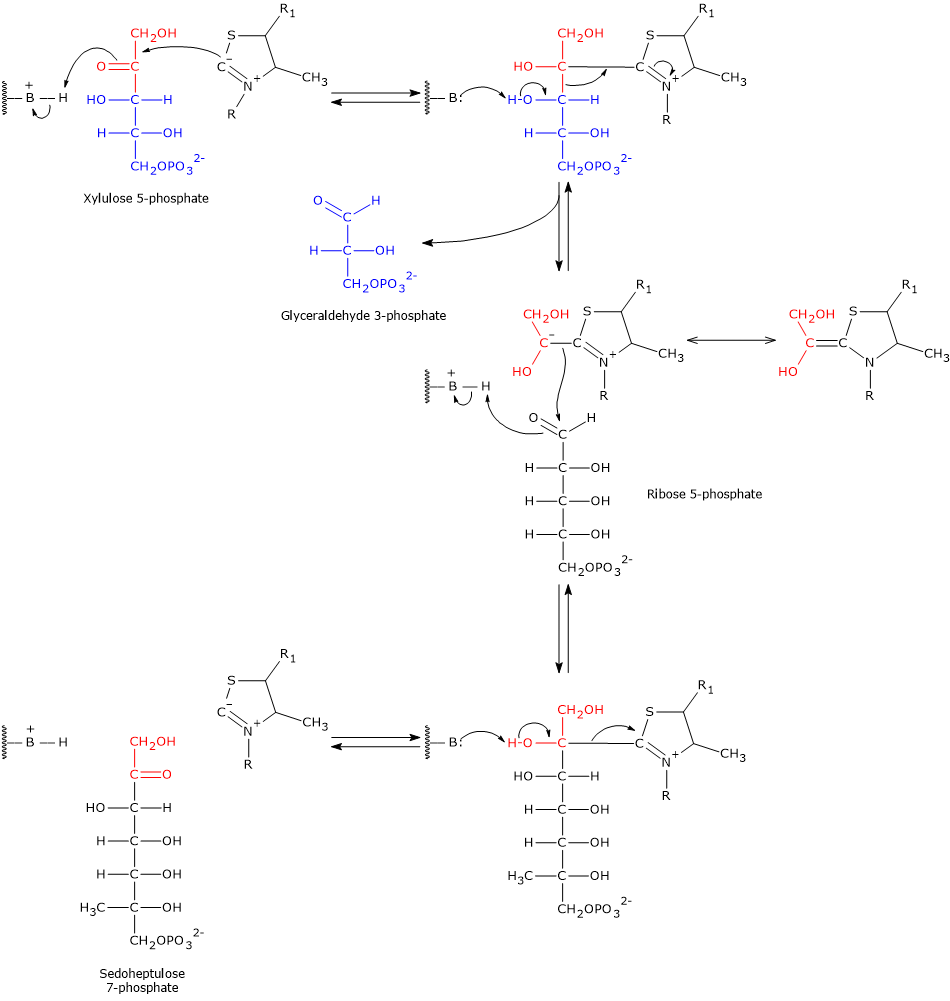
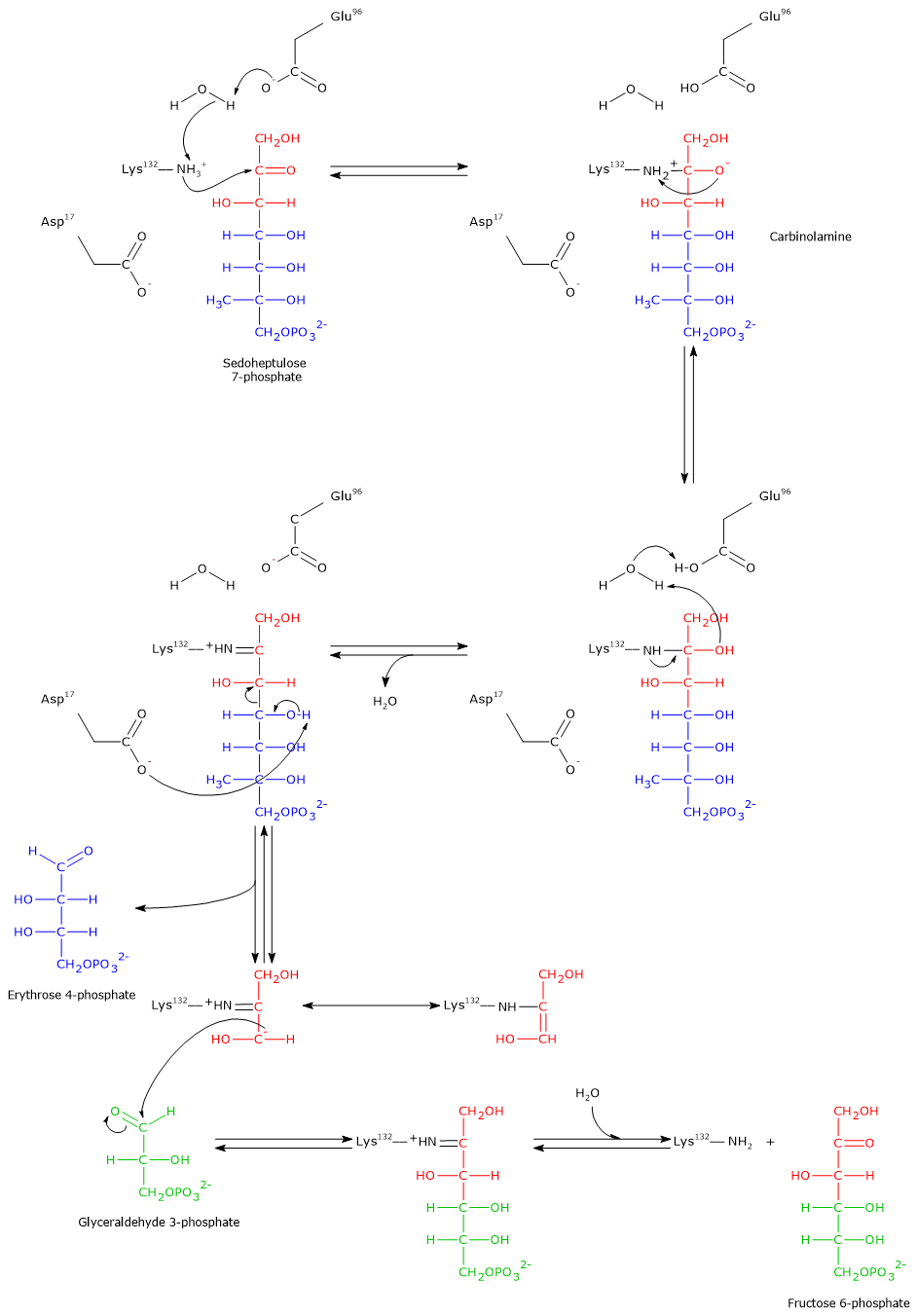
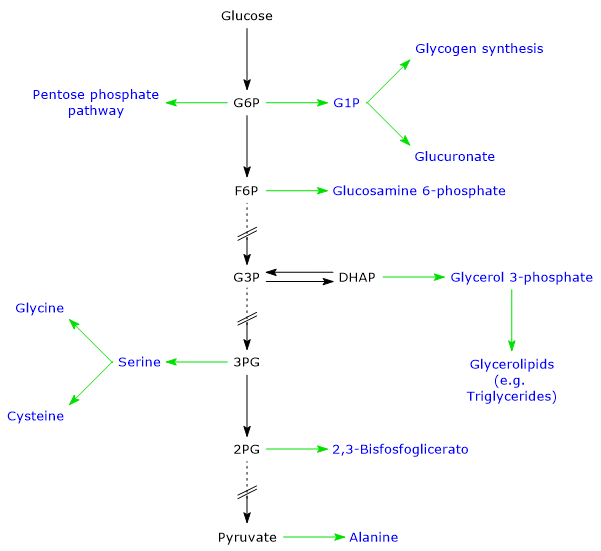
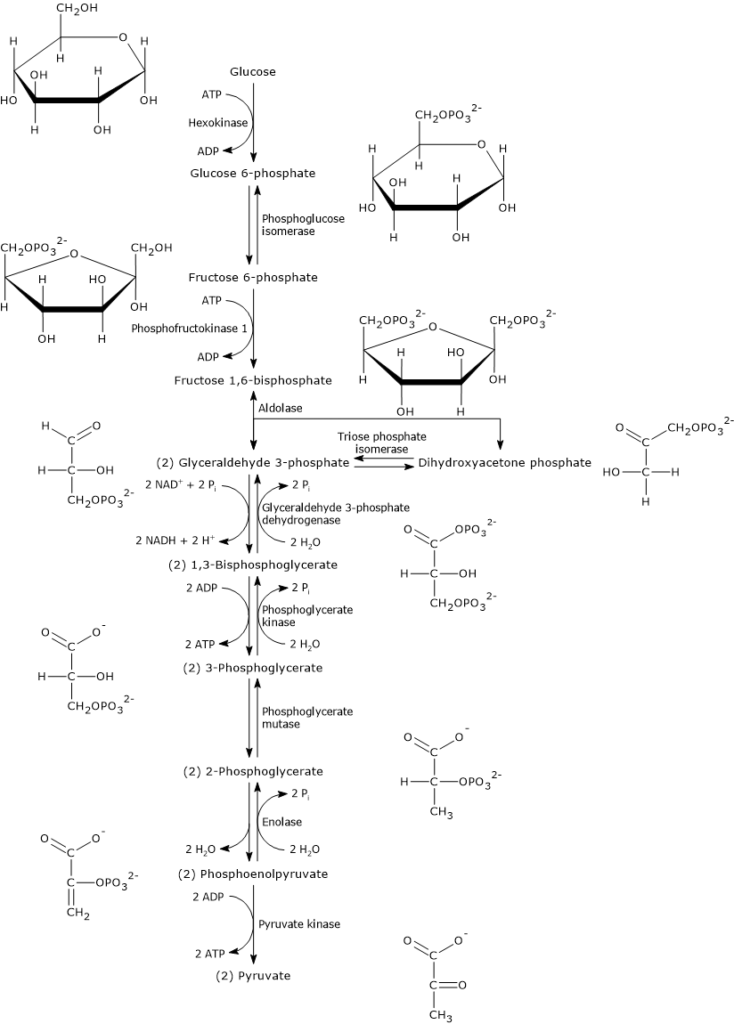
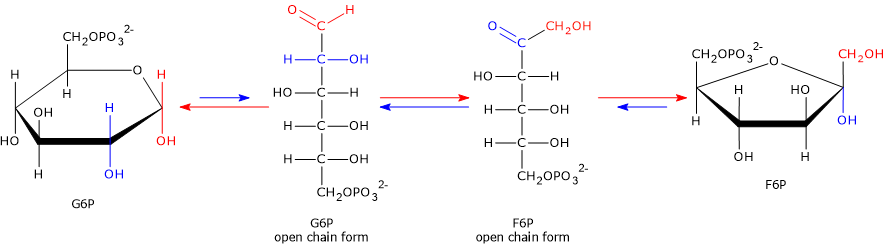
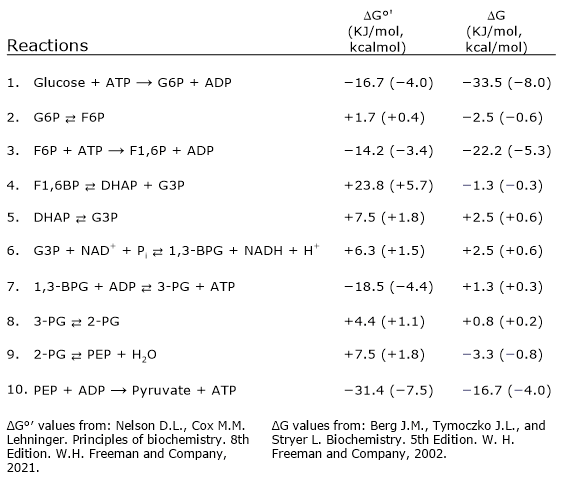
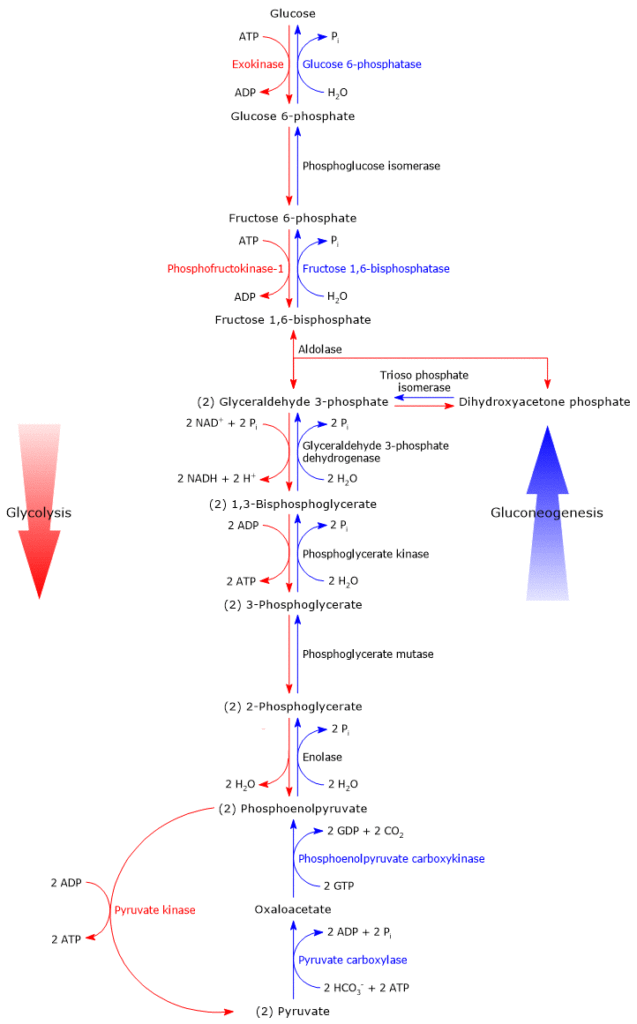
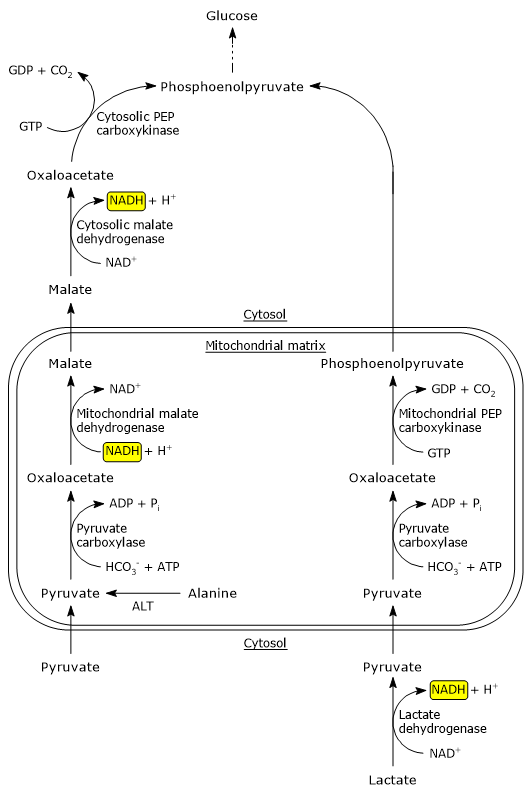
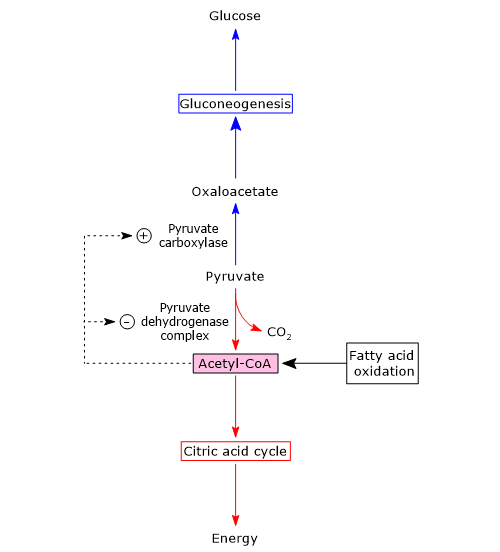
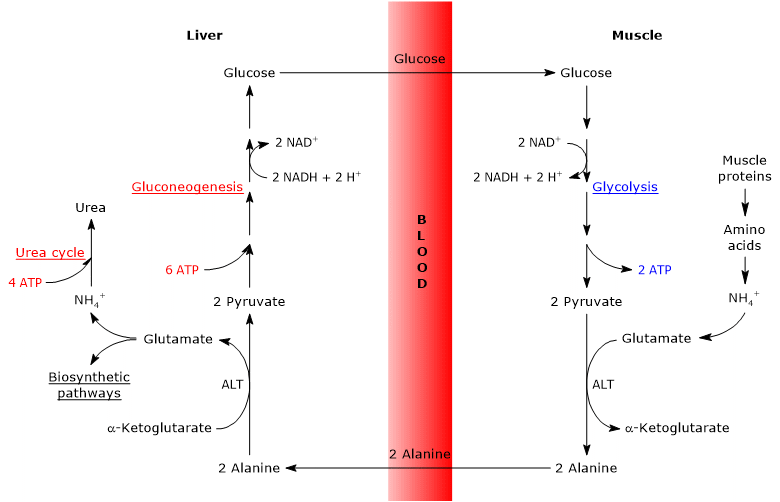
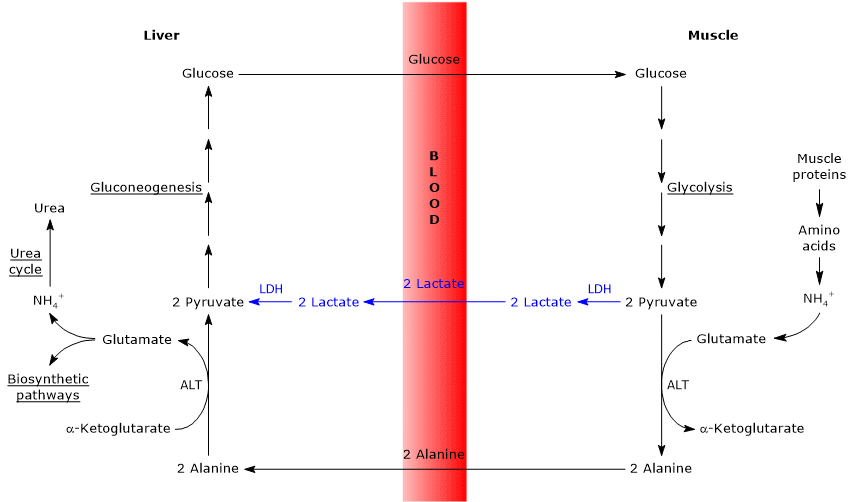
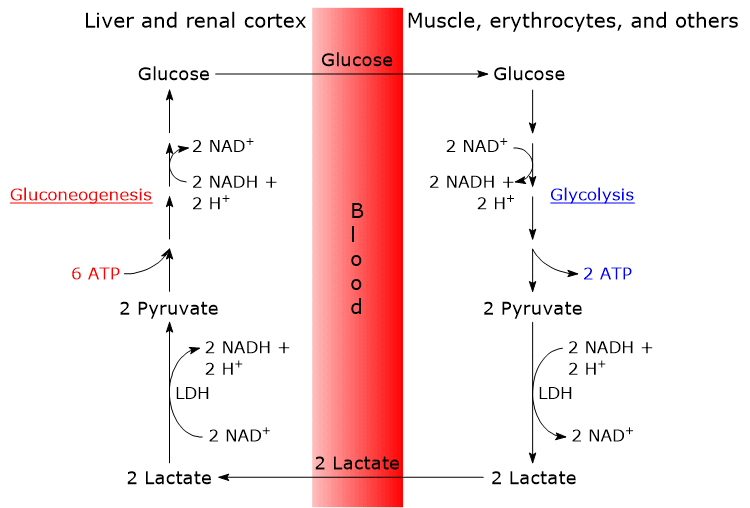
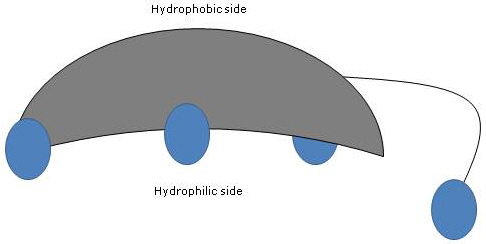
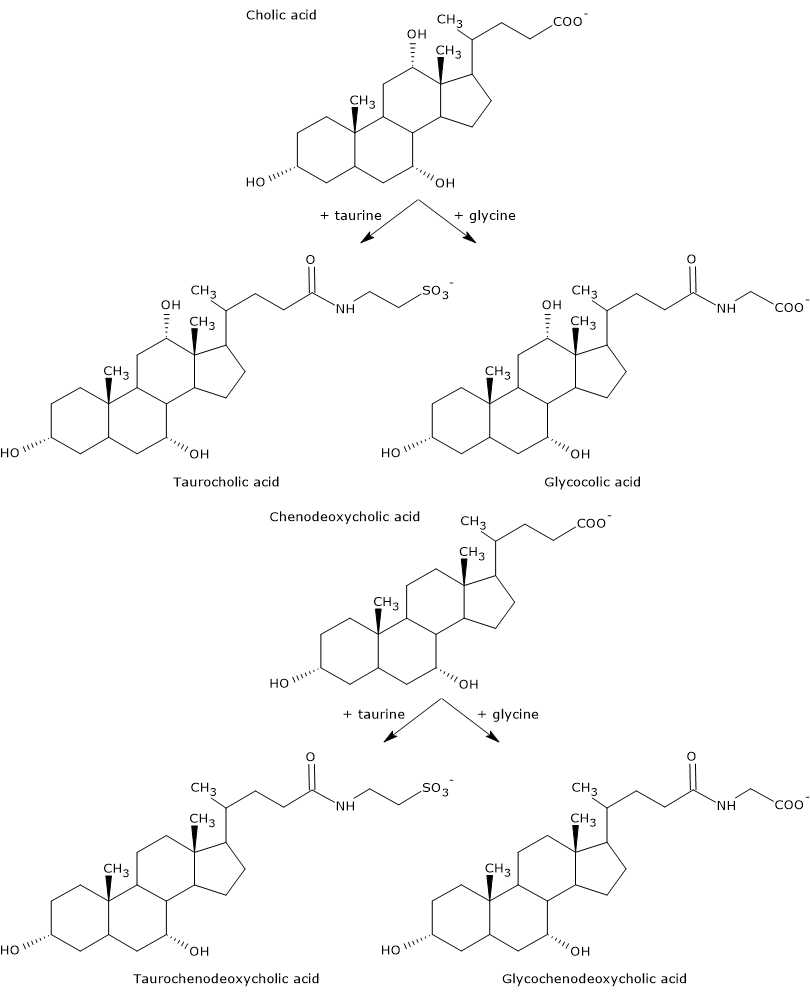
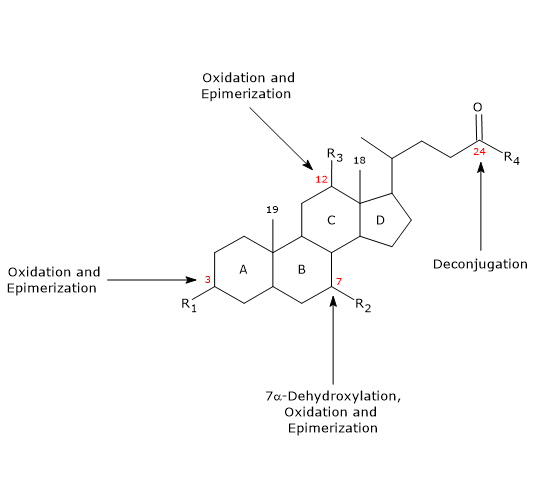
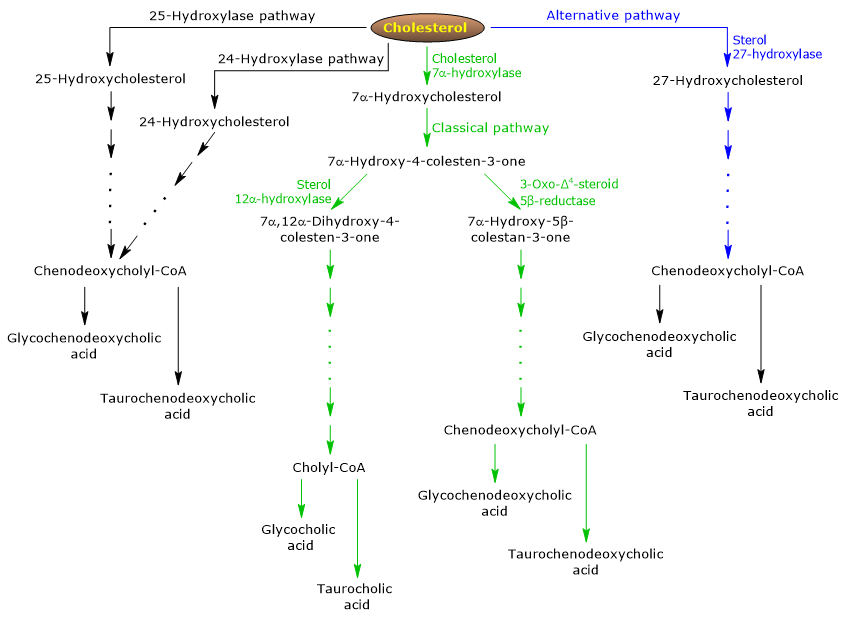
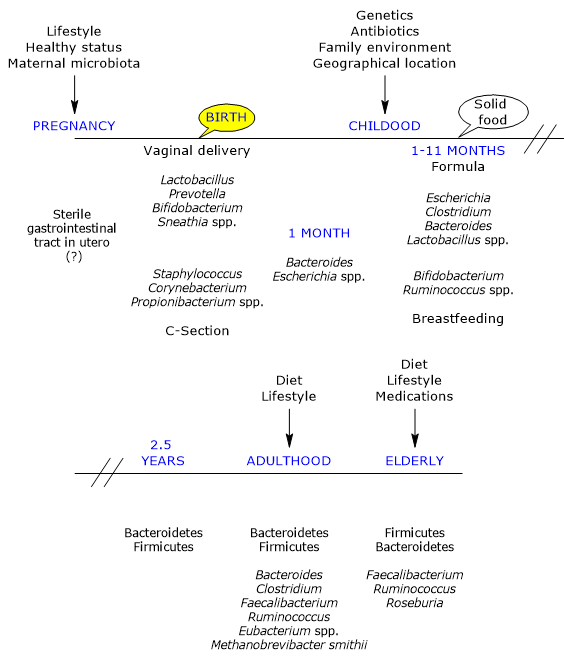
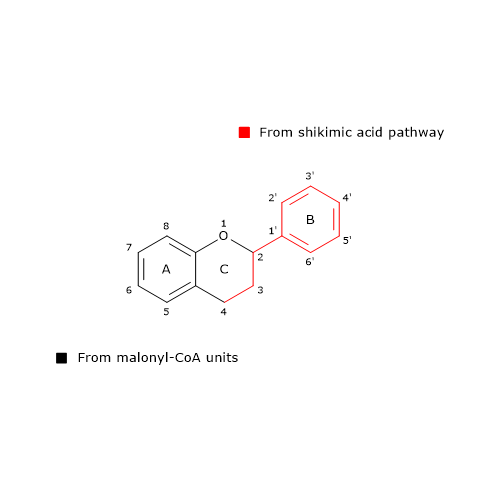
 Below we will analyze the energy expenditure of runners engaged in workouts on various distances, the amounts of
Below we will analyze the energy expenditure of runners engaged in workouts on various distances, the amounts of 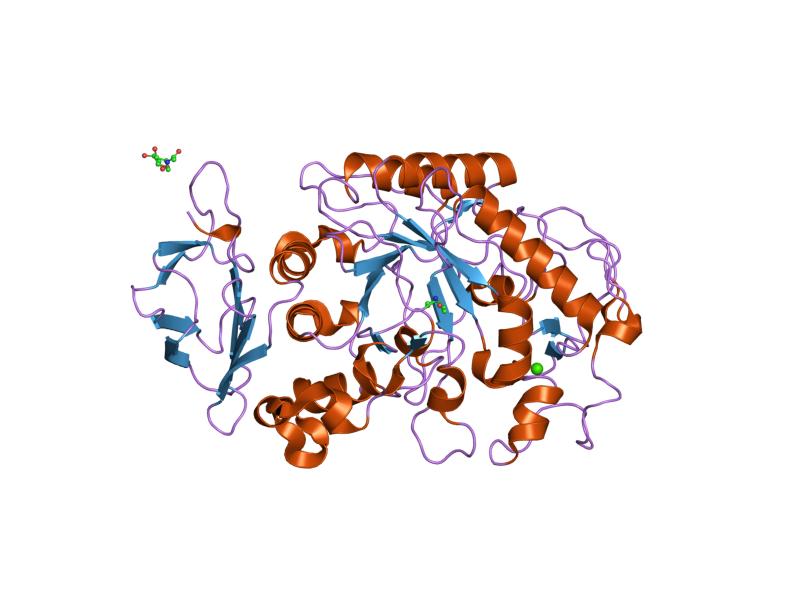
 The consumption limited to these quantities must be obtained by intake of drinks with low ethanol content, preferably at meals (drinking even lightly to moderately outside of meals increases the probability to have hypertension). This means no more than 680 ml or 24 oz of regular beer or 280 ml or 10 oz of wine (12% ethanol), especially in hypertension; for women and thinner subjects consumption should be halved1.
The consumption limited to these quantities must be obtained by intake of drinks with low ethanol content, preferably at meals (drinking even lightly to moderately outside of meals increases the probability to have hypertension). This means no more than 680 ml or 24 oz of regular beer or 280 ml or 10 oz of wine (12% ethanol), especially in hypertension; for women and thinner subjects consumption should be halved1.
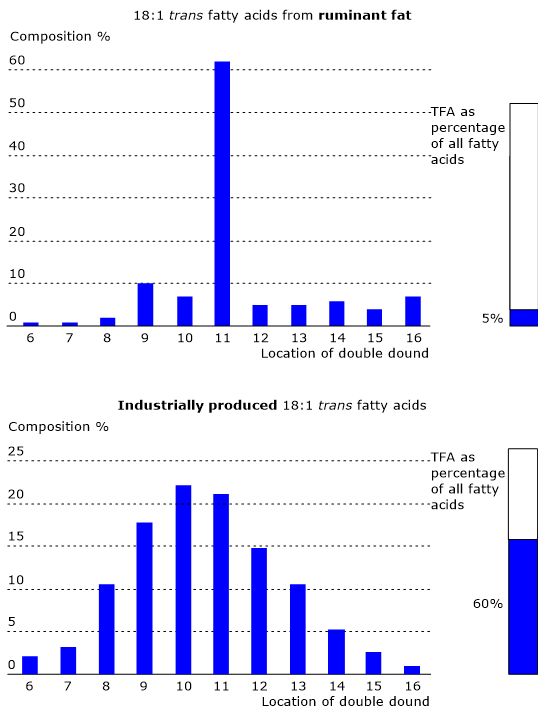
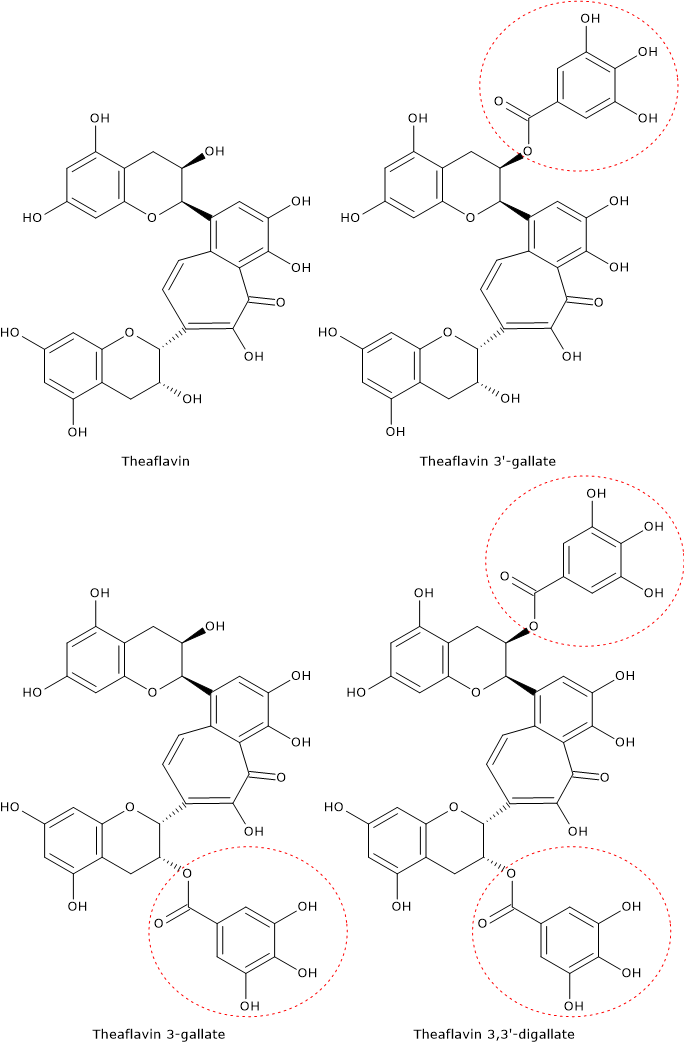
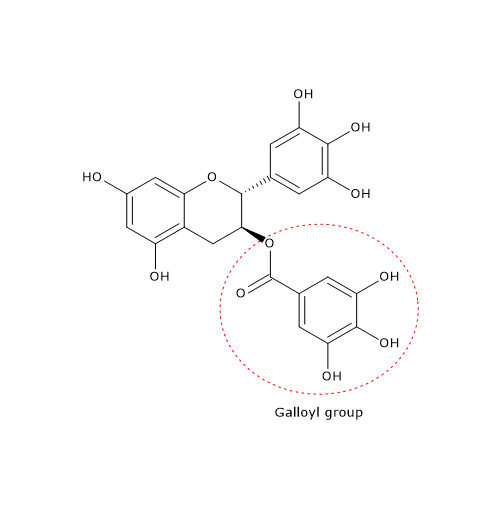

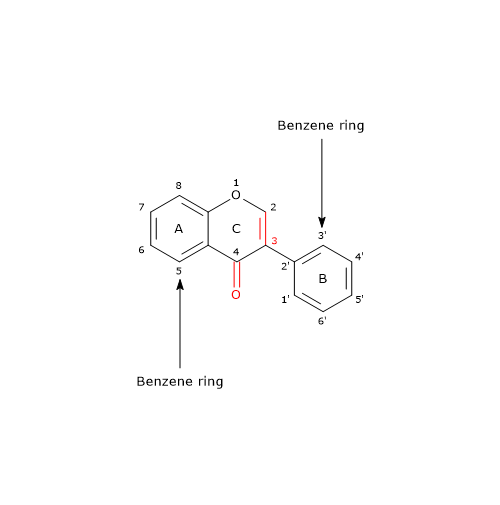
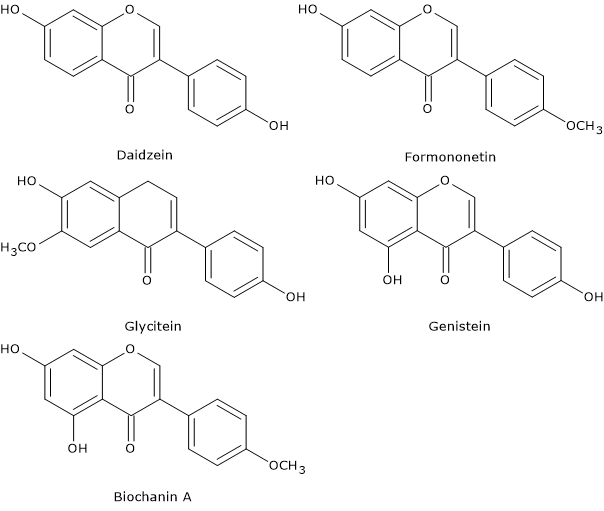
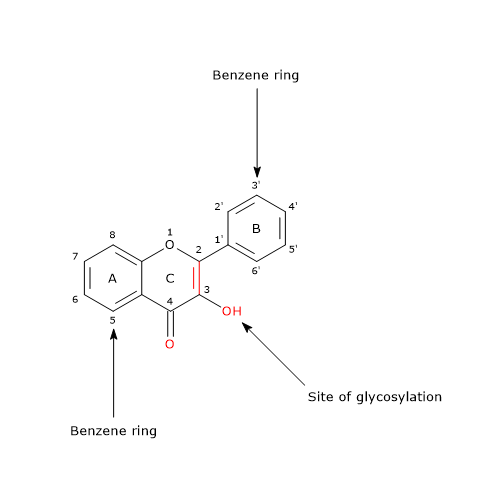
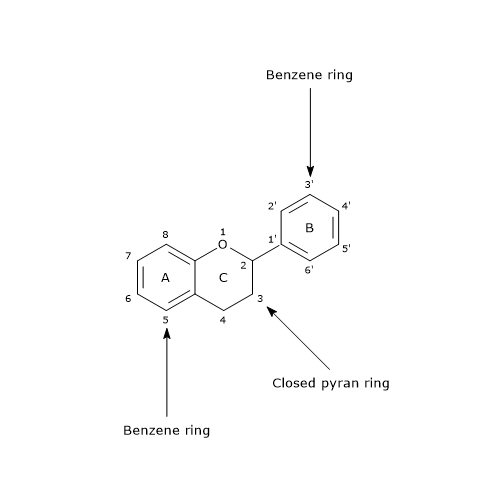
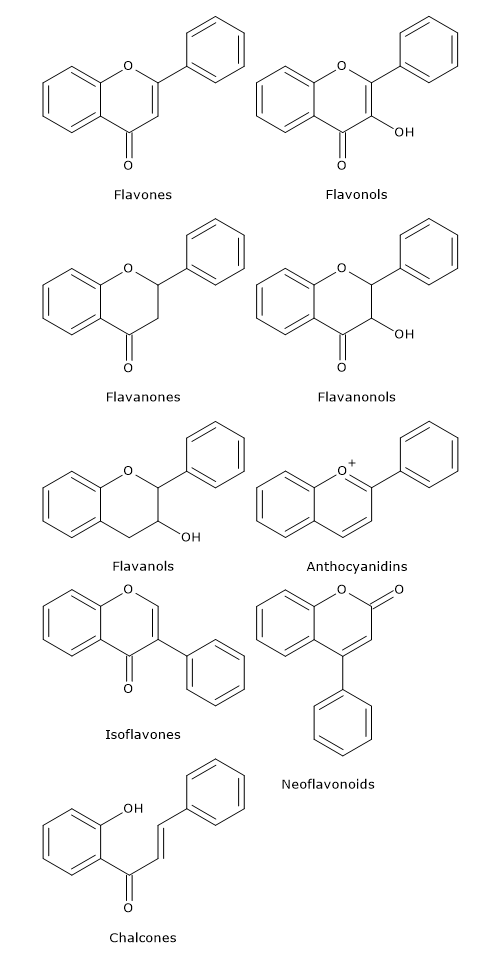
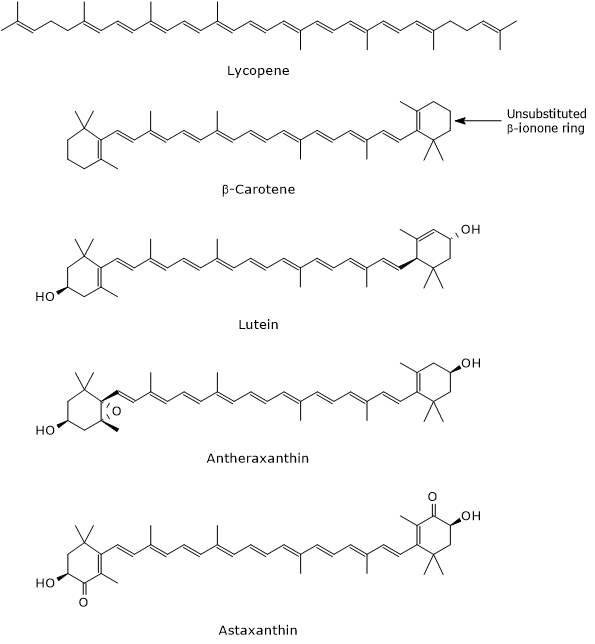

 Then, glucose can diffuse from the hepatocyte, via a transporter into the plasma membrane called GLUT2, into the bloodstream to be delivered to extra-hepatic cells, in primis neurons and red blood cells for which it is the main, and for red blood cells the only energy source. Neurons, with the exception of those in some brain areas that can use only glucose as energy source, can derive energy from another source, the ketone bodies, which becomes predominant during periods of prolonged fasting.
Then, glucose can diffuse from the hepatocyte, via a transporter into the plasma membrane called GLUT2, into the bloodstream to be delivered to extra-hepatic cells, in primis neurons and red blood cells for which it is the main, and for red blood cells the only energy source. Neurons, with the exception of those in some brain areas that can use only glucose as energy source, can derive energy from another source, the ketone bodies, which becomes predominant during periods of prolonged fasting.